李宏毅视频1 ——从Generator和Discrimator角度来看待GAN
| [了解生成对抗网络 (GAN) | 作者:约瑟夫·罗卡 | 迈向数据科学 (towardsdatascience.com)]( |
Generator
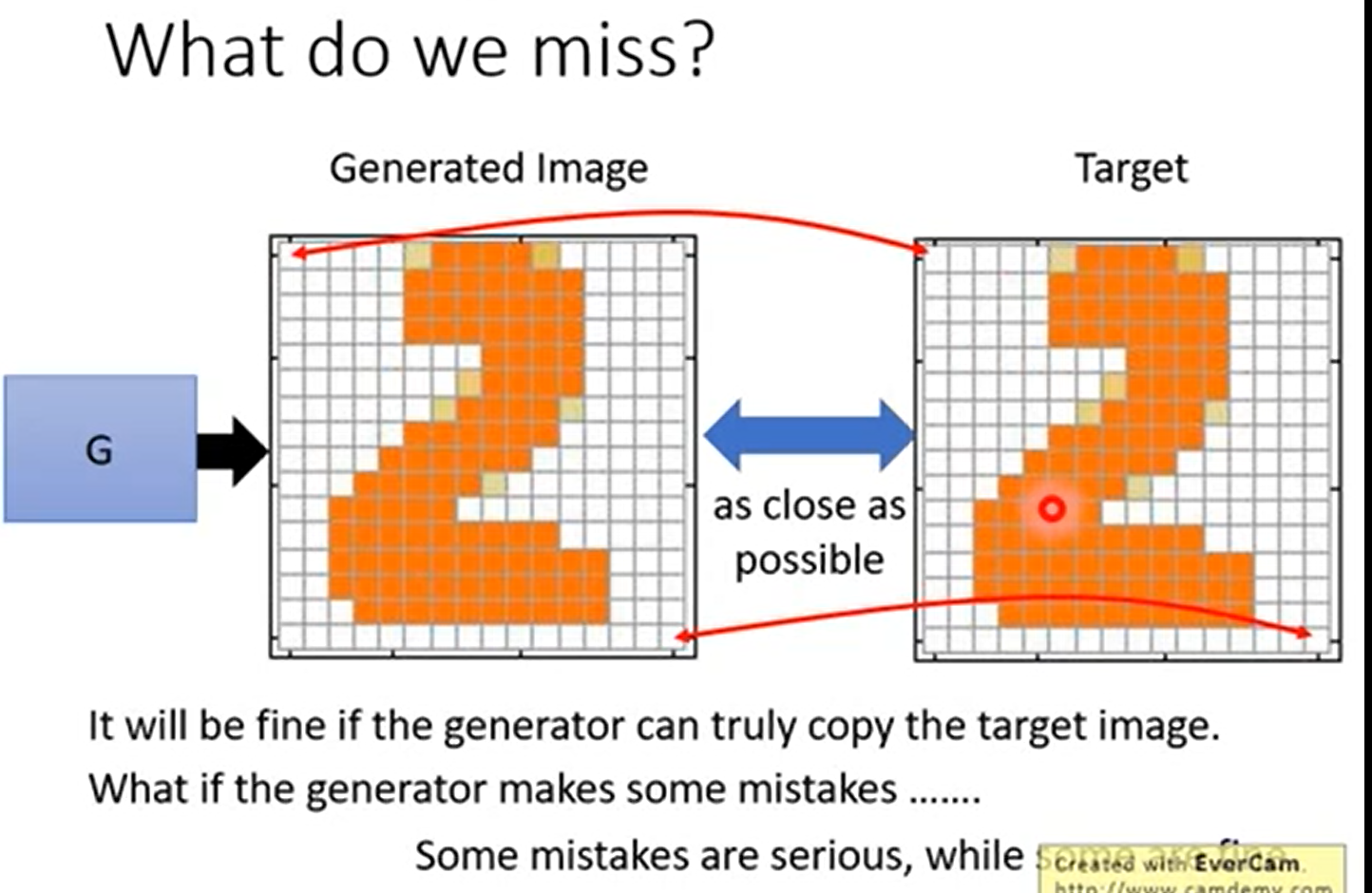
Generator的目标就是让自己生成的结果(伪造结果)和目标结果(真实样本)越接近越好,如果是能够完全一致copy,那是没有问题的。但是我们知道完全一致是很难的,生成器难免会犯错误。那么就要取舍了,我们可能容易接受一类错误而不能容许另一类错误。举例来说

站在机器的角度,上面两张图片只有一个像素错误,下面却有6个像素错误,如果按着数值计算,上面的结果是好的。
但是实际上站在我们人的角度,我们反而更认同下面是好的。更像是人手写的。
缺点
问题就是,不能单纯只让我们的生成结果和目标结果一致,其实组成部分componet之间的关系也是重要的,但是在机器学习训练过程中,并不会关注到这种结构关系
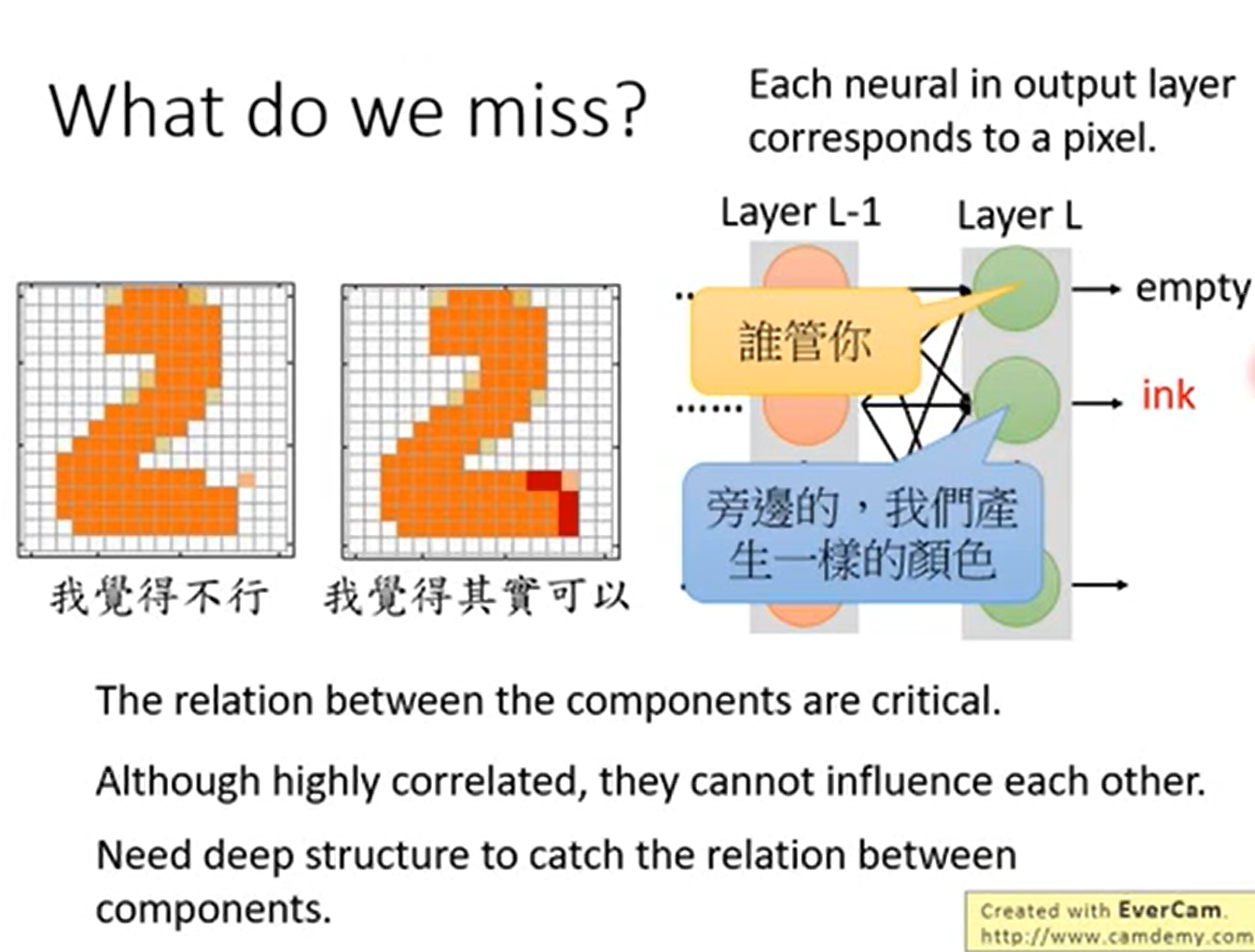
例如,假设Layer L就是最后一层,我们观察到每一个结点对一个产生的像素,结点彼此之间是不关联的。
其实也有组成部分,那就是再加几层Layer,这样就能够将结点信息组合起来。
Discriminator
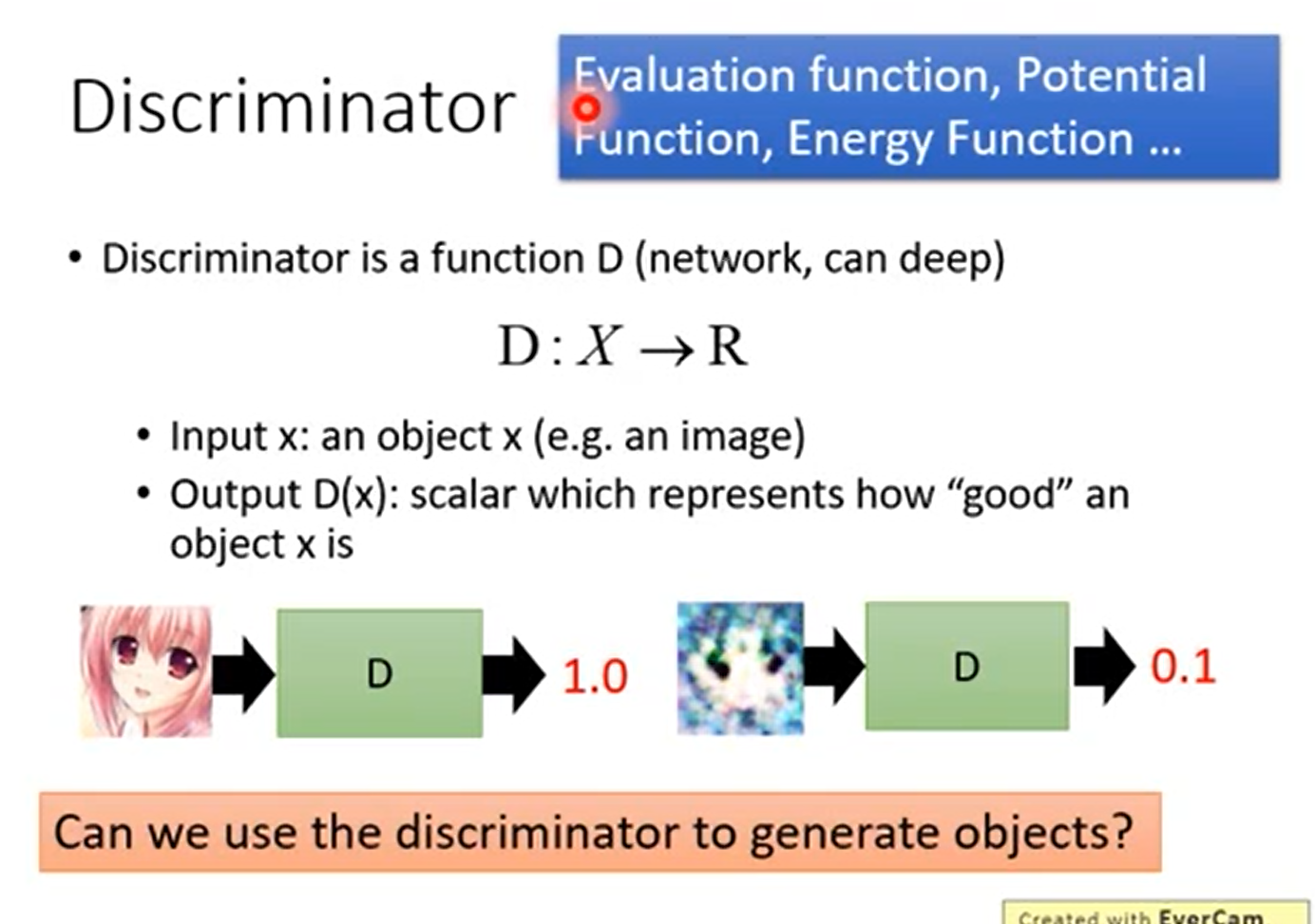
问,Can Discriminator generate? Discriminator 可不可以用来做生成
Discrimator 就是一个函数,输入一个图片,输出一个评分
优点

discriminator 做的是评价,在生成的时候是从底向上的,我们只关注到每个Component组成部分,而不容易注意到各部分之间的联系。但是在评价的时候我们是根据生成的样本与目标进行比较的,就能够关注到这种联系,也就是我们是从顶向下,站在整体的角度来看待的。
那么怎么用Discriminator来做生成呢?
假设我们已经有一个很好的的Discriminator,可以很好地鉴别,那么怎么拿这个Discriminator来做生成呢?
——穷举所有的样本,看哪个样本会得到较高的分数,那个得到高分的就是生成的结果。我们先不考虑穷举,假设有一个算法是能够做的穷举所有的样本,然后对每一个样本给出评价的。
我们假设Discriminator能够按着上面的描述进行生成,新的问题就是如何训练Discriminator?
简单来说,我们训练Discriminator就是给它好的样本,让它给出高分;给它差的样本,让它给出低分。问题是,我们手上只有好的样本,这时候就是说只有好的例子。所以我们需要找到negative的样本,还得是效果比较好的negative的样本。那么怎么产生这些好的negative的样本呢?

事实上,我们需要有一个比较好的Discriminator来分辨出比较好的negative的样本,这就产生了,鸡生蛋,蛋生鸡的问题,我们要有好的negative的样本来训练Discriminator,我们要有好的Discriminator才能帮我们找出好的negative的样本。
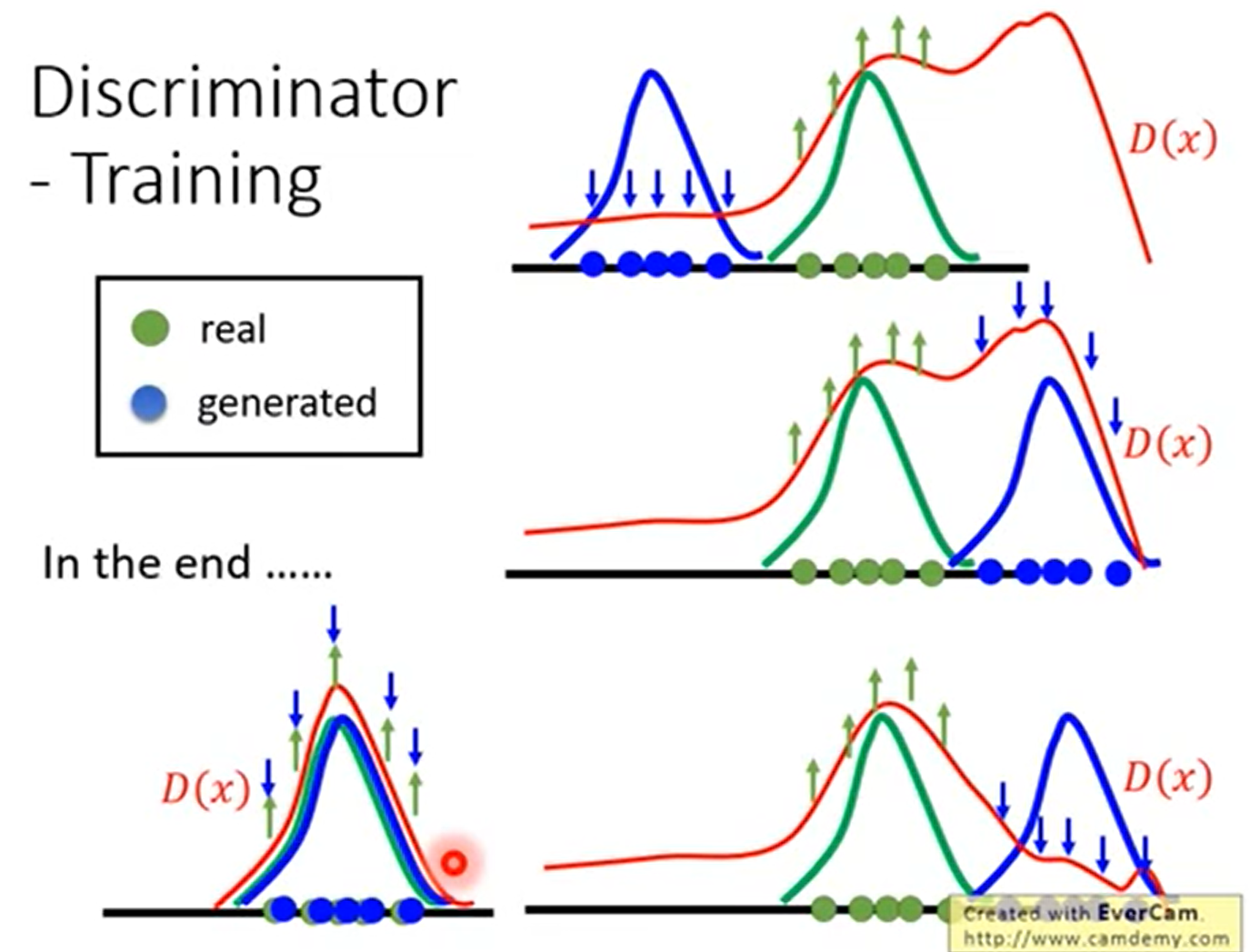
怎么来解决这个问题呢?使用迭代的方法

我们首先用真实样本和伪造样本进行训练,得到一个Discriminator,
然后解$arg \ max_{x\in X} D(x)$,找出那些评分较高的伪造样本(有些类似于找到自己的弱点),下一次用伪造样本进行迭代
过去使用Discriminator作为生成器的工作:
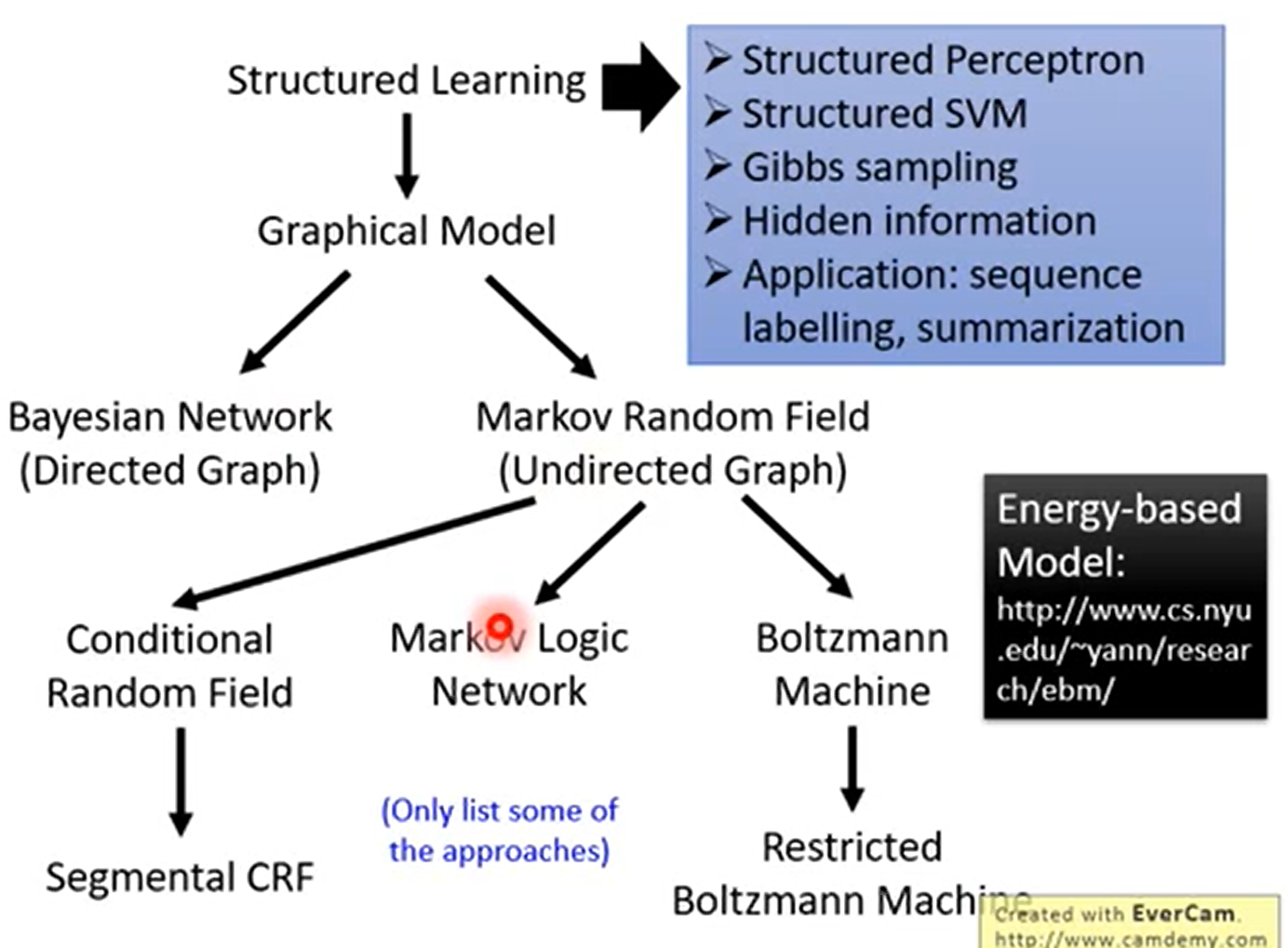
Generator 与 Discriminator的区别

GAN:Generator+ Discriminator


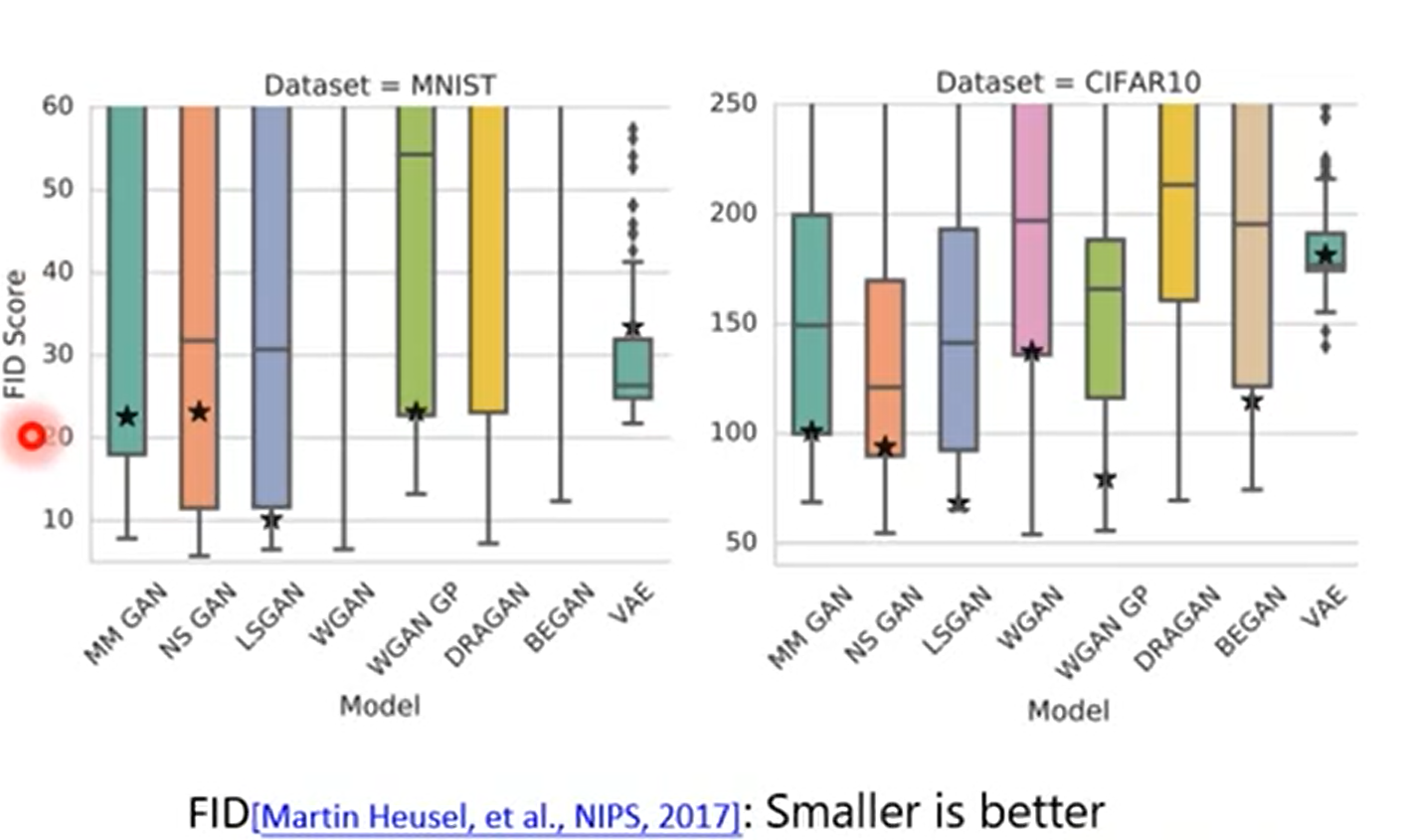
GAN Algorithm
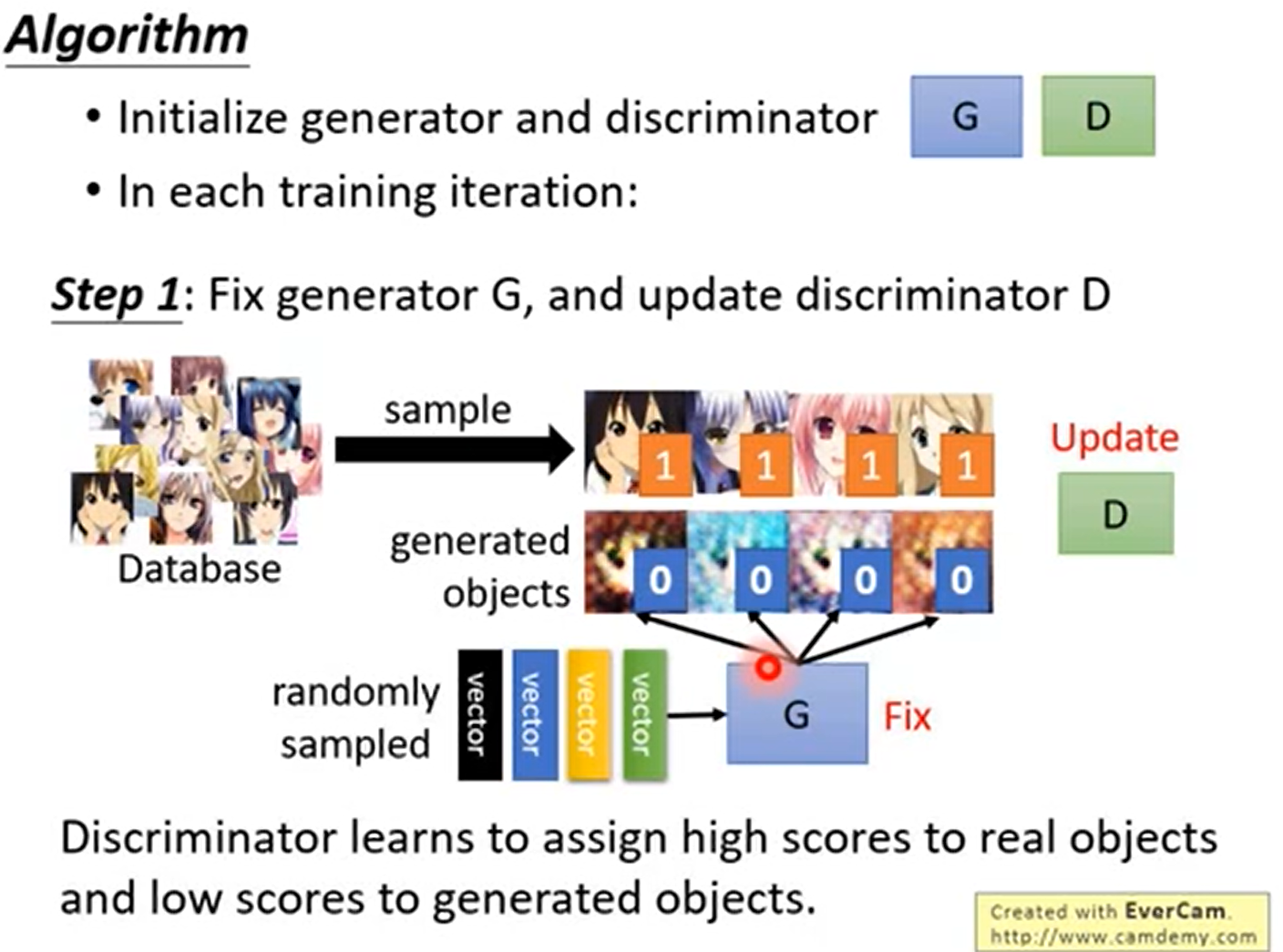
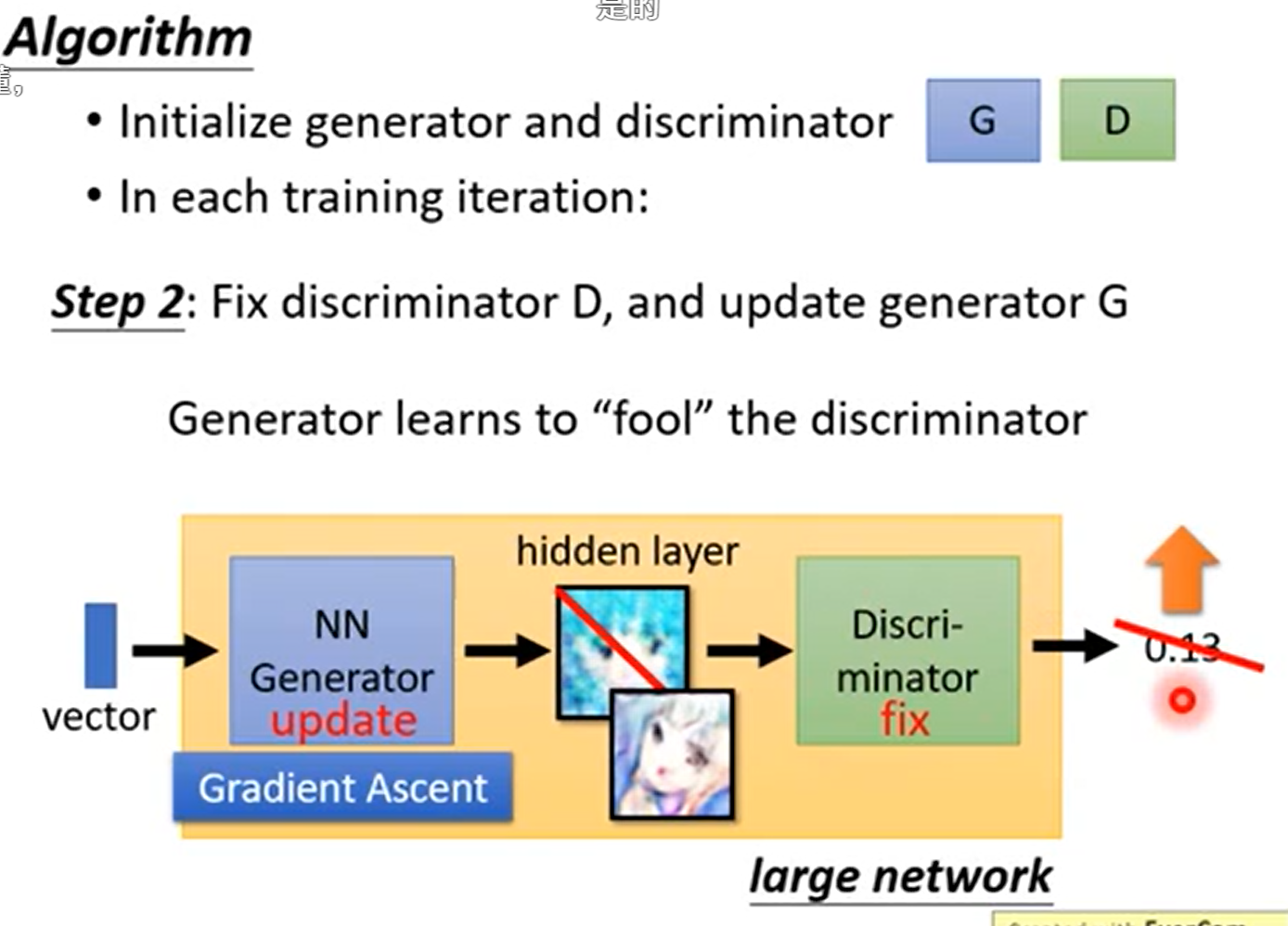
Auto Encoder
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2021/11/15/Introduction-to-GAN/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)