GANLecture2 Conditional GAN
Contional GAN
解读 这篇论文中的Conditional GAN和原生GAN在结构上没有太大差别,时间也是紧随着原生GAN出来的,它的思想应该后续很多GAN网络的基础。简单来说,原生的GAN是无监督的,包括之前一篇介绍的DCGAN,输出是完全随机的,比如在人脸上训练好的网络,最后生成什么样的人脸是完全没办法控制的,所以在这篇文章中,作者在输入的时候加入了条件(类别标签或者其他模态的信息),比如在MNIST训练好的网络,可以指定生成某一个具体数字的图像,这就成了有监督的GAN。同时,在文章中,作者还使用网络进行了图像自动标注。
Conditional,意思是条件,所以 Conditional GAN 的意思就是有条件的GAN。Conditional GAN 可以让 GAN 产生的结果符合一定的条件,即可以通过人为改变输入的向量(记不记得我们让生成器生成结果需要输入一个低维向量),控制最终输出的结果。
这种网络与普通 GAN 的区别在于输入加入了一个额外的 condition(比如在 text-to-image 任务中的描述文本),并且在训练的时候使得输出的结果拟合这个 condition。
所以现在判别器不仅要对生成结果的质量打分,还要对结果与输入 condition 的符合程度打分。
判别器应该判别两类错误,
一类是 标签与生成结果匹配,但是图像效果不够好,这样子应该给低分
另一类是 标签与生成结果不匹配,这样子也应该给低分
只有 标签与生成结果匹配,并且图像效果足够好,才能给高分
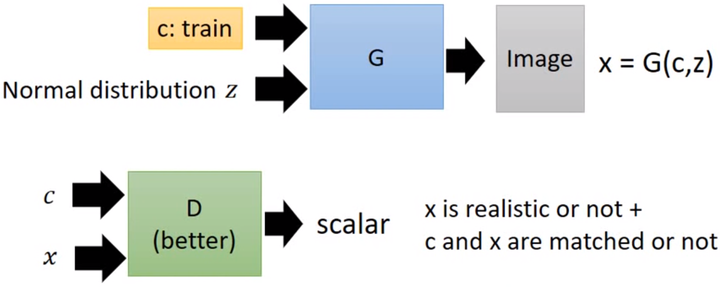
算法图

上面公式,如果是正确的c和x的pair就给他高分,如果是c配上生成的模糊结果就给他低分,如果c配上真实数据但是标签不匹配,也要给他低分
网络结构
可以看到,和原始GAN一样,整体还是基于多层感知器。在原生GAN中,判别器的输入是训练样本x,生成器的的输入是噪声z,在conditional GAN中,生成器和判别器的输入都多了一个y,这个y就是那个条件。以手写字符数据集MNIST为例,这时候x代表图片向量,y代表图片类别对应的label(one-hot表示的0~9)。
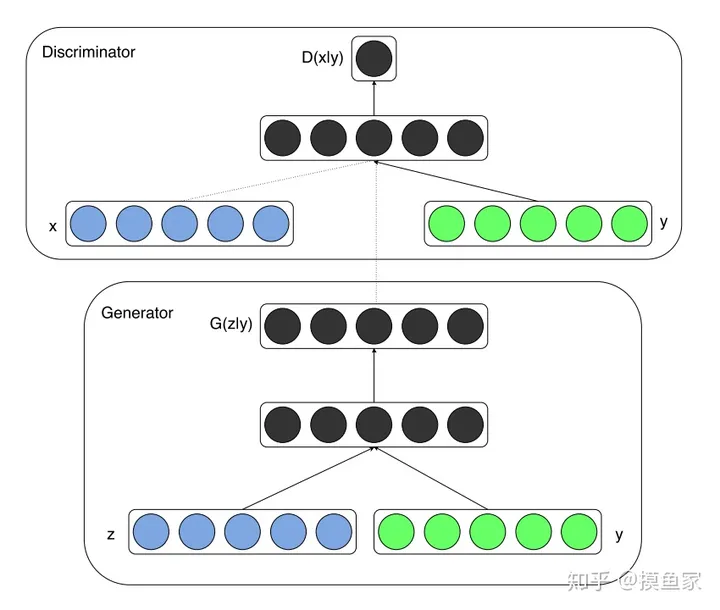
对于判别器D,训练的时候,输入的时候把训练样本x(或G产生的样本)和y同时输入,在第一个hidden layer后合并,最后的输出是在y的条件下训练样本x(或G产生的样本)是真样本的概率,然后反向优化。
对于生成器G,输入是噪声z和y,经过感知器最终输出产生的标签y对应的图片,然后把生成的图片和y送入判别器,进而反向优化。
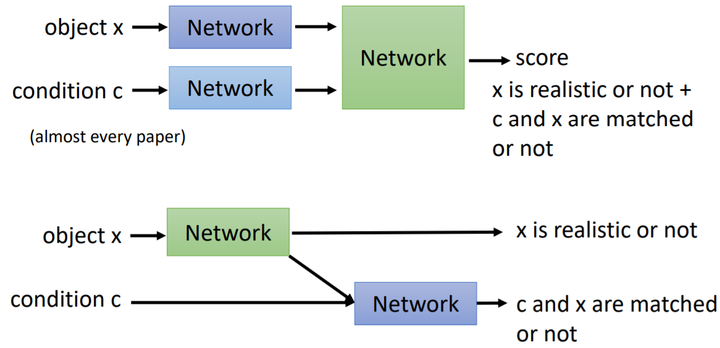
Conditional GAN 的判别器有两种常见架构,前者更为常用,但李宏毅老师认为后者更加合理,它用两个神经网络分别对输出结果的质量以及条件符合程度独立进行判别。
Stack Gan
主要思想:
目的,生成高清细节的现实图片
做法: 分为两个模块,两级任务,第一级关注于大体轮廓和颜色。第二级关注细节生成

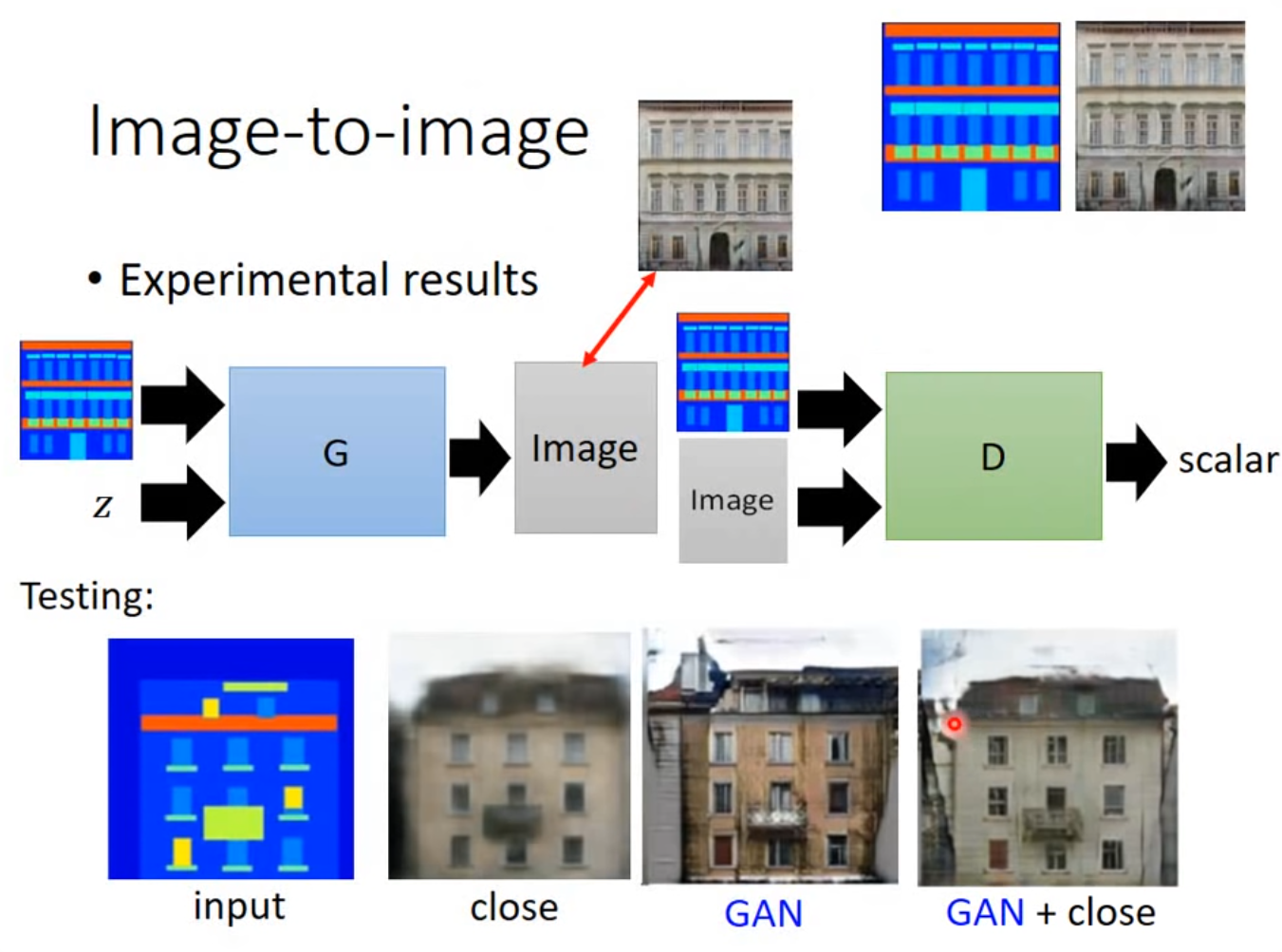
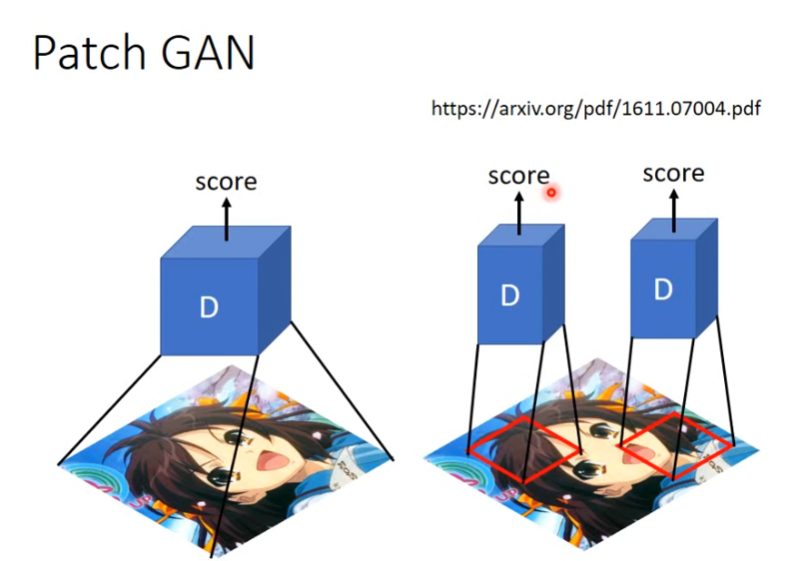
Image to Image Contional GAN—— Patch GAN
重新设计了 discrimator ,用来检查像素,像素的大小是一个超参数
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2022/01/11/GANLecture2-Conditional-GAN/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)