图像生成
本质的上的共同目标
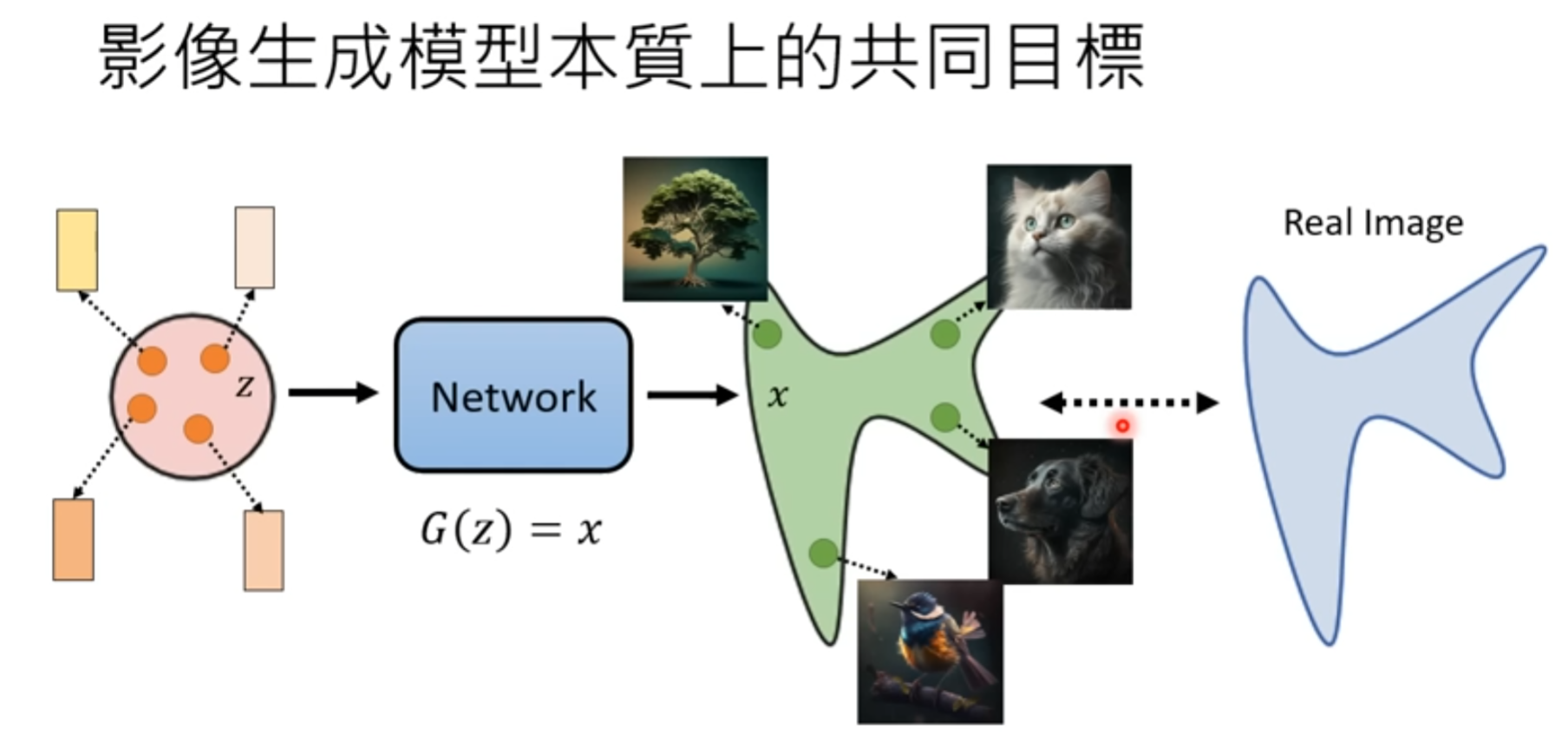
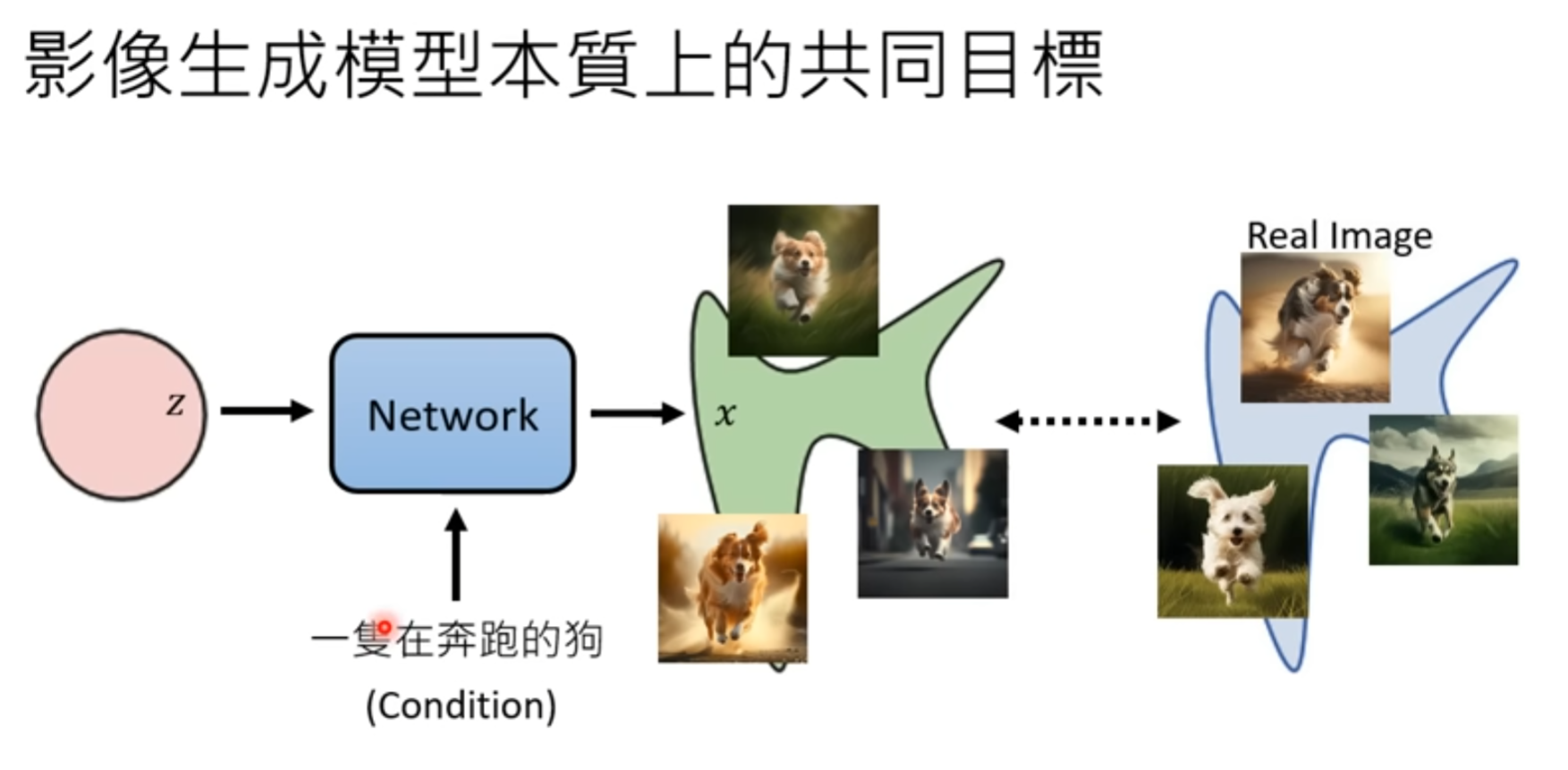
常见的图像生成模型
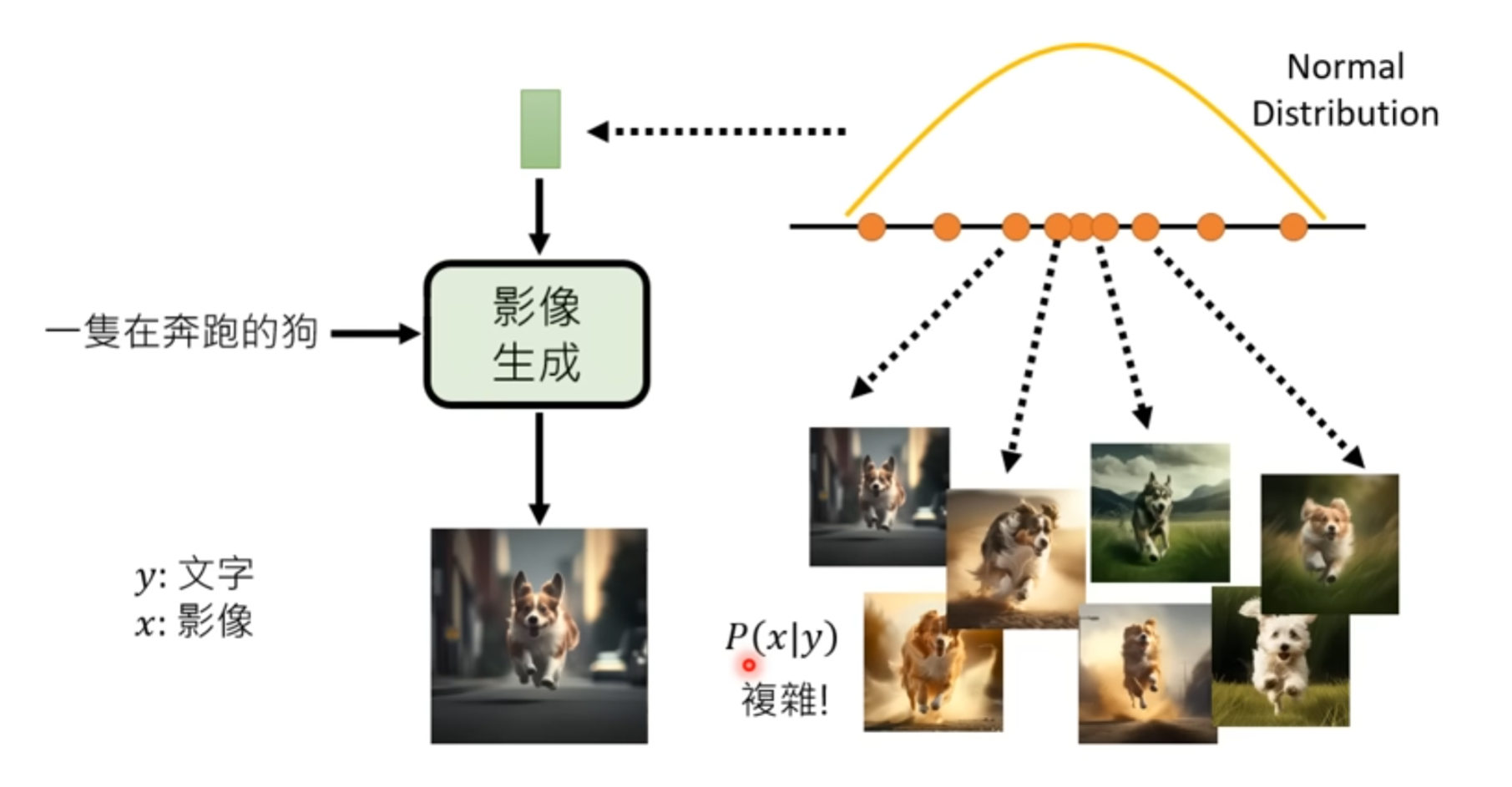
影响生成模型就是根据一个Normal Distribution 对应得到影响
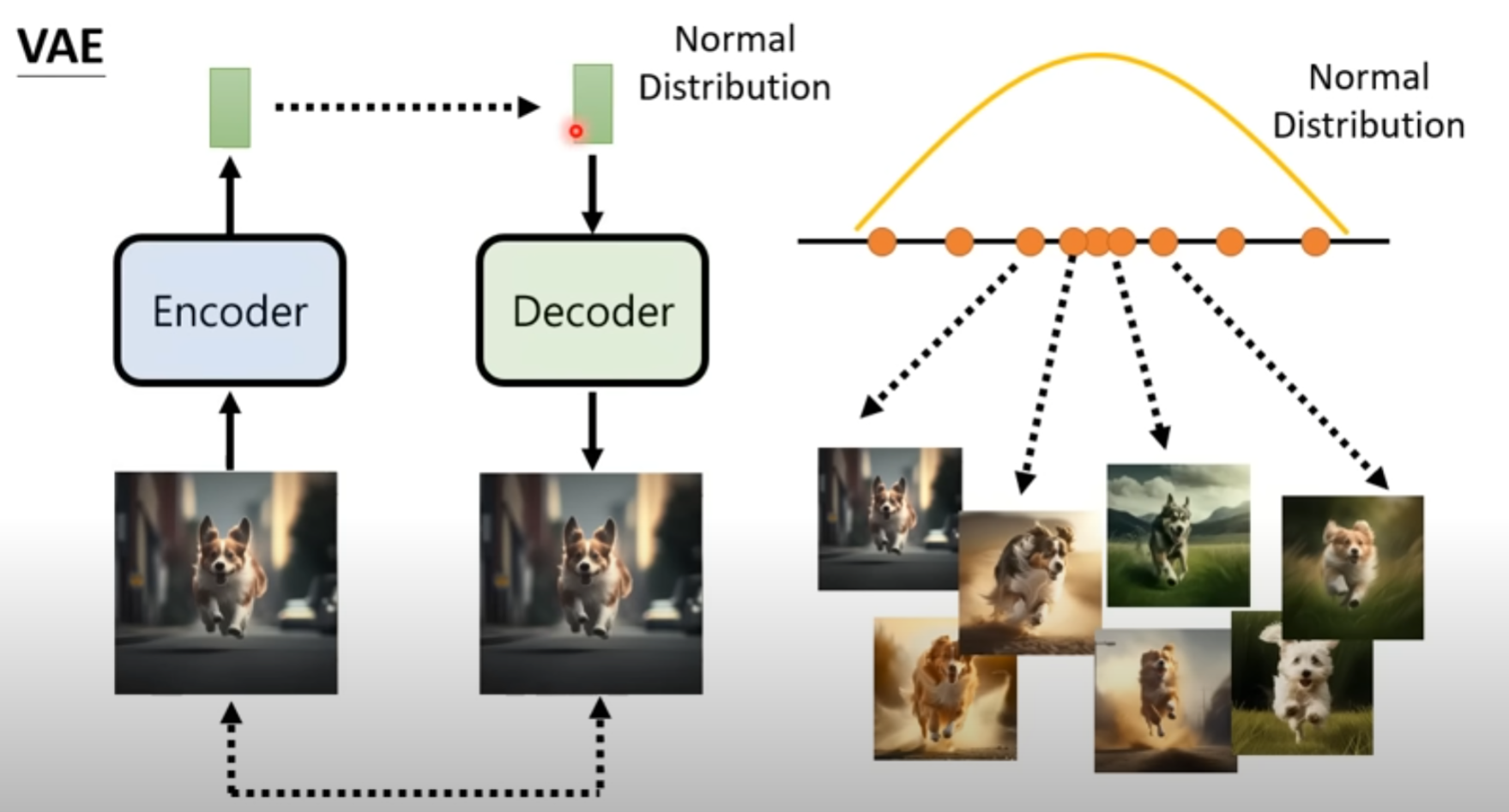
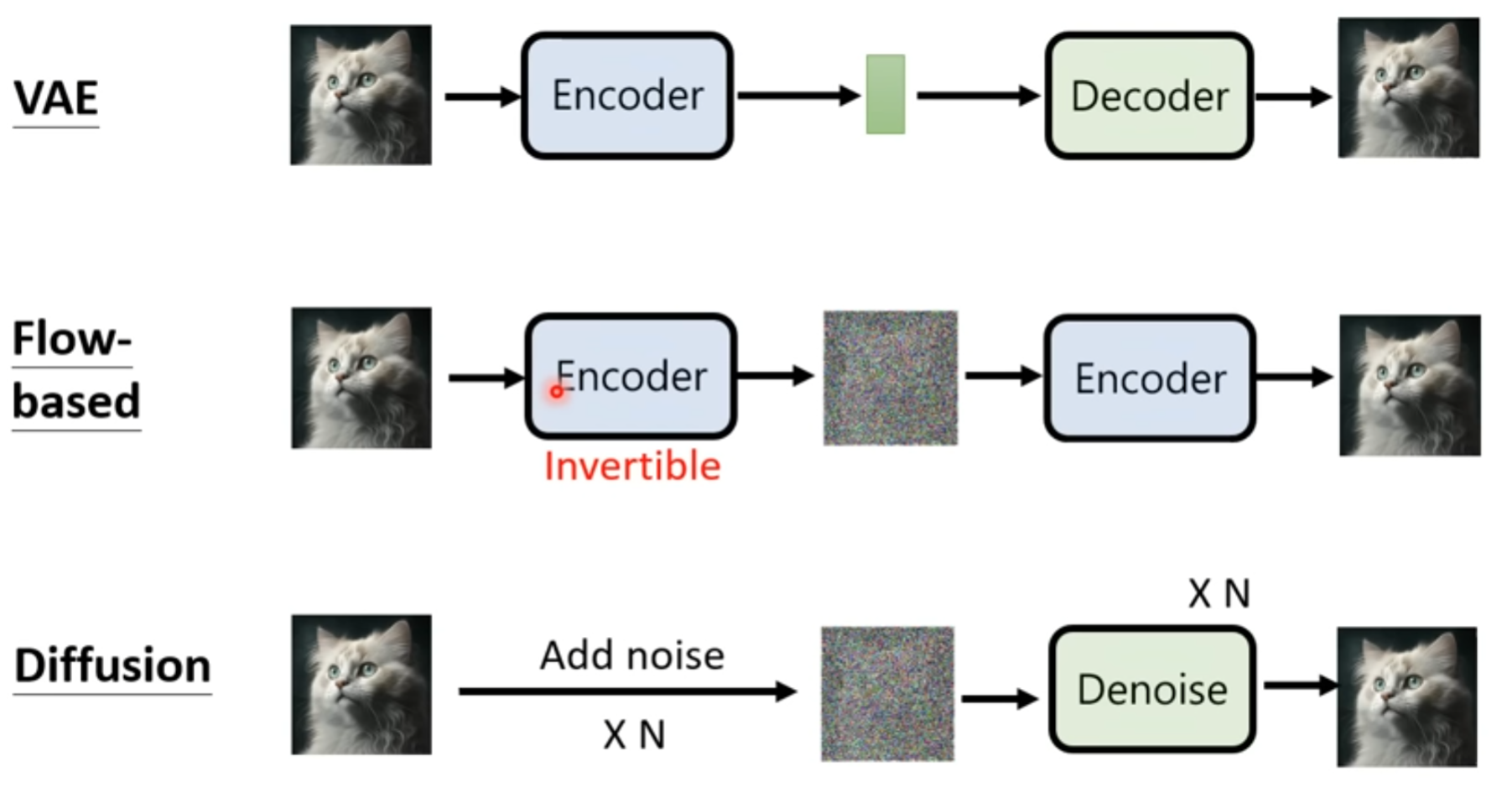
VAE
decoder 就是学习这个对应关系
encoder 是将图片生成code
然后把decoder和encoder 对应起来,使得输入和输出对应
注意,这样并不能保证,所以要强制中间产生的code的分布要像一个 Normal Distribution
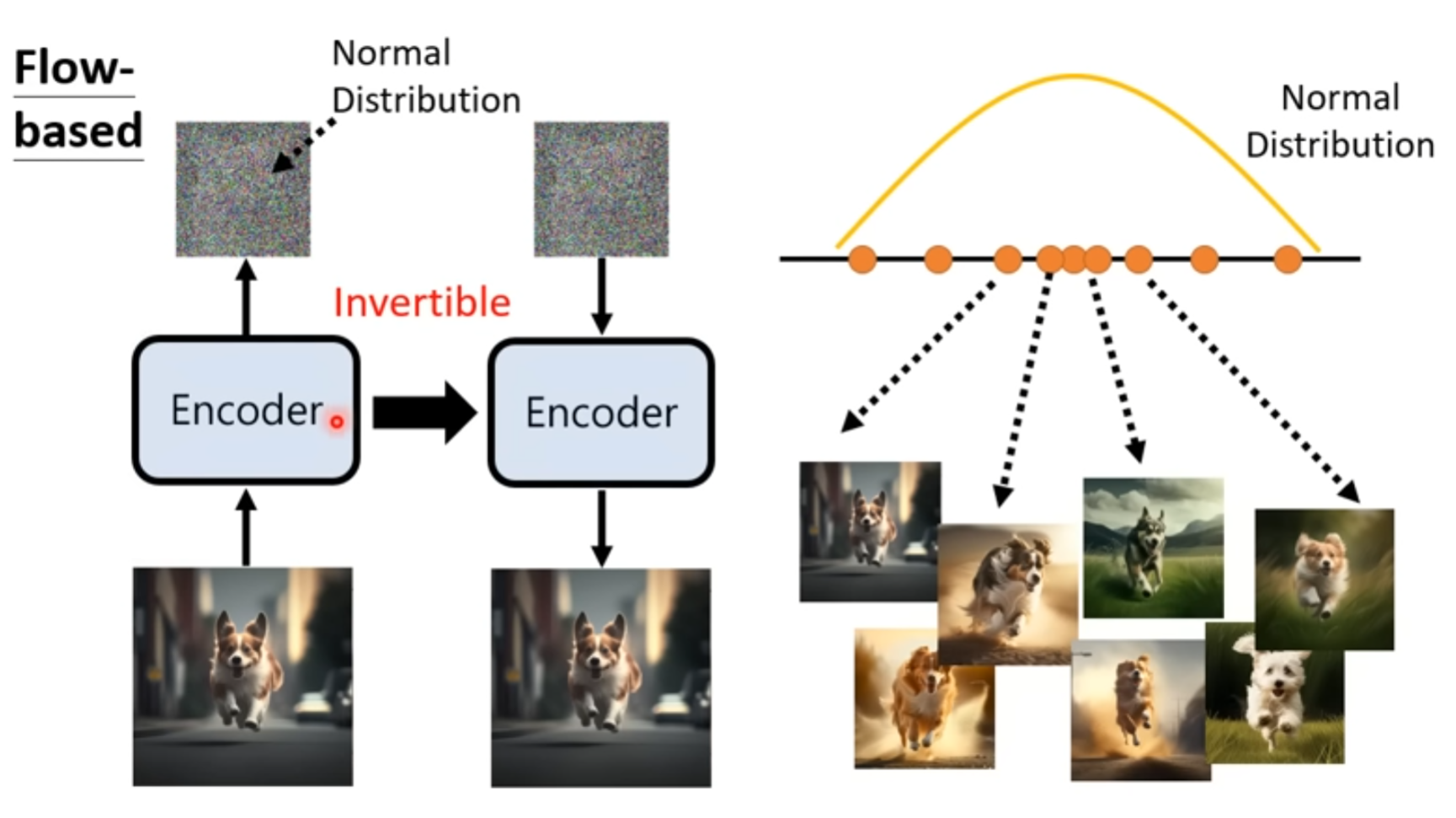
Flow-based
先得到一个encoder ,使得图片对应的code一个 Normal Distribution
然后限制这个encoder是可逆的,
这里限制encoder是可逆的
并且图片和code维度应该是一致的,因为要保证可逆关系
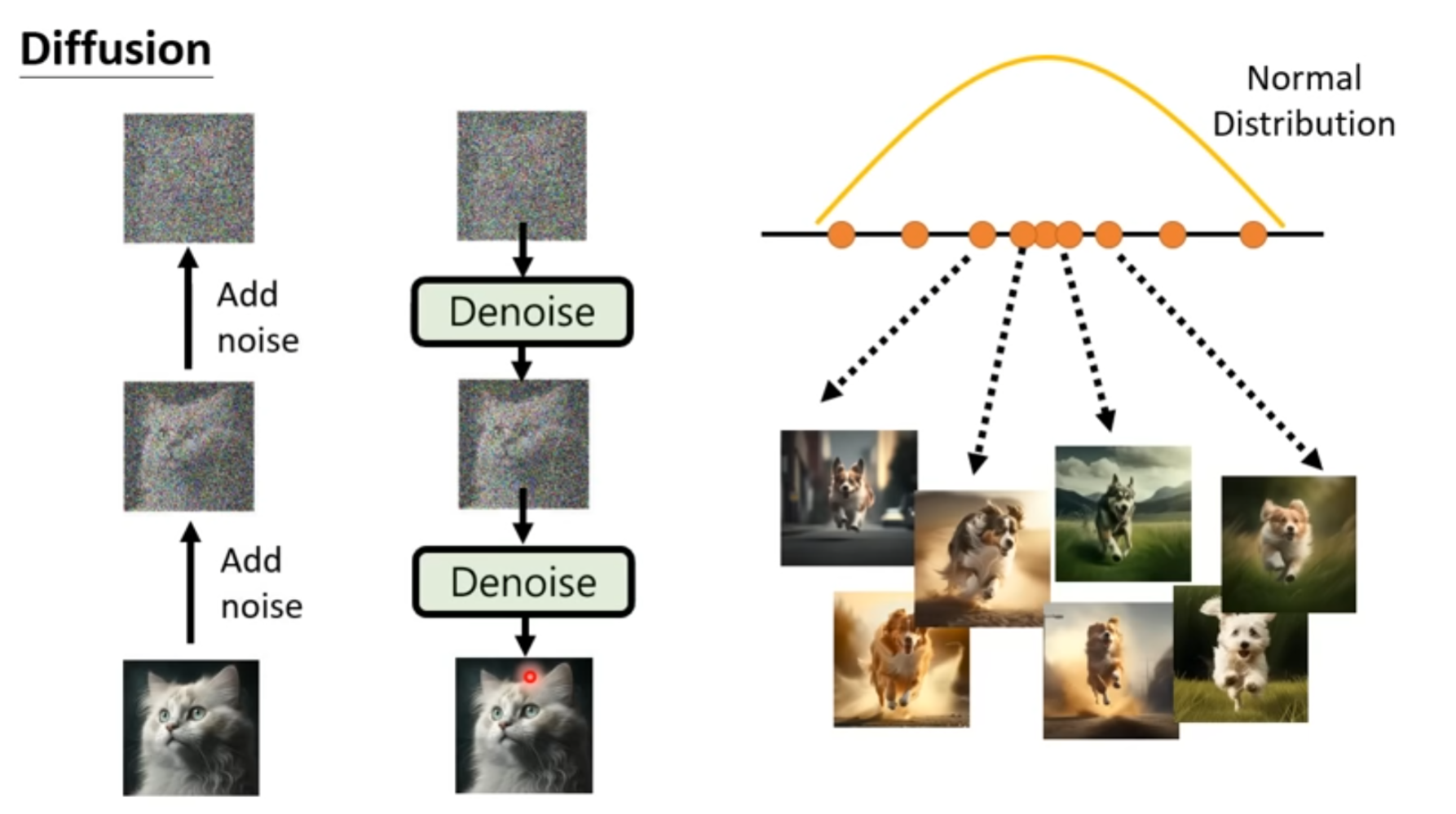
Diffusion Model
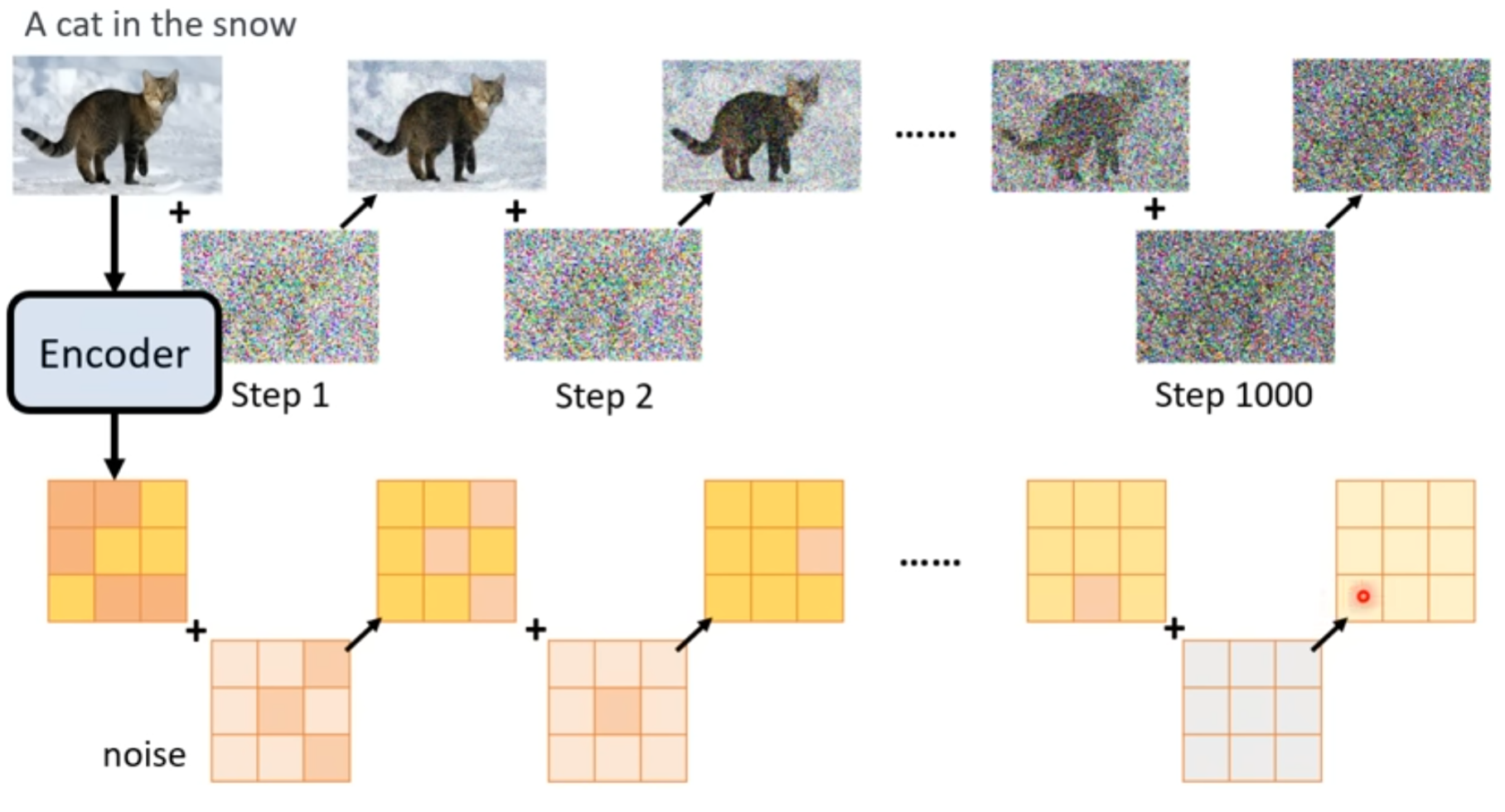
把一张图片一直加noise,直到得到一个和 normal distribution差不多的结果
生图片就是逆过程,学习一个denoise的model,从带有noise的结果还原图片
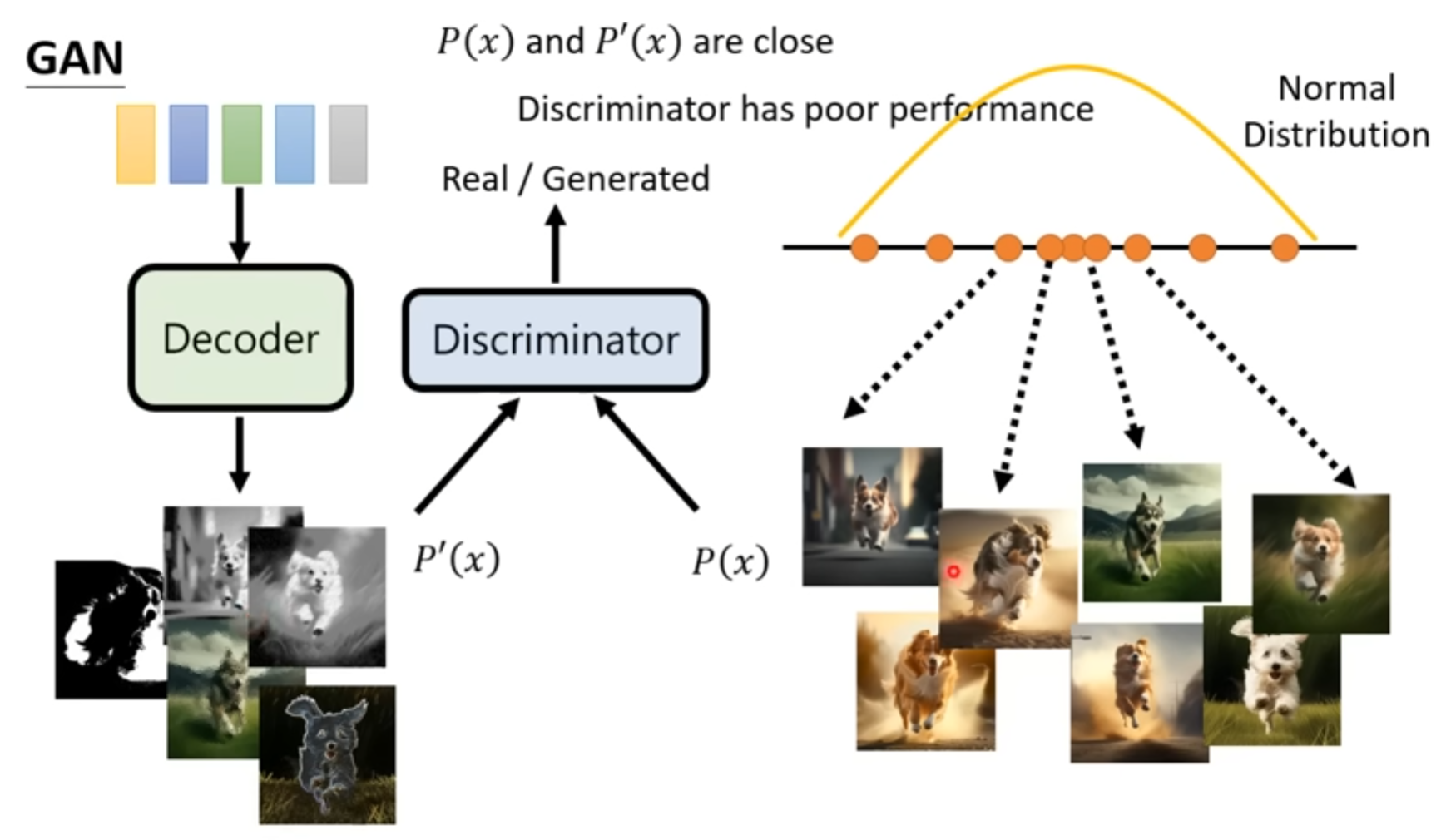
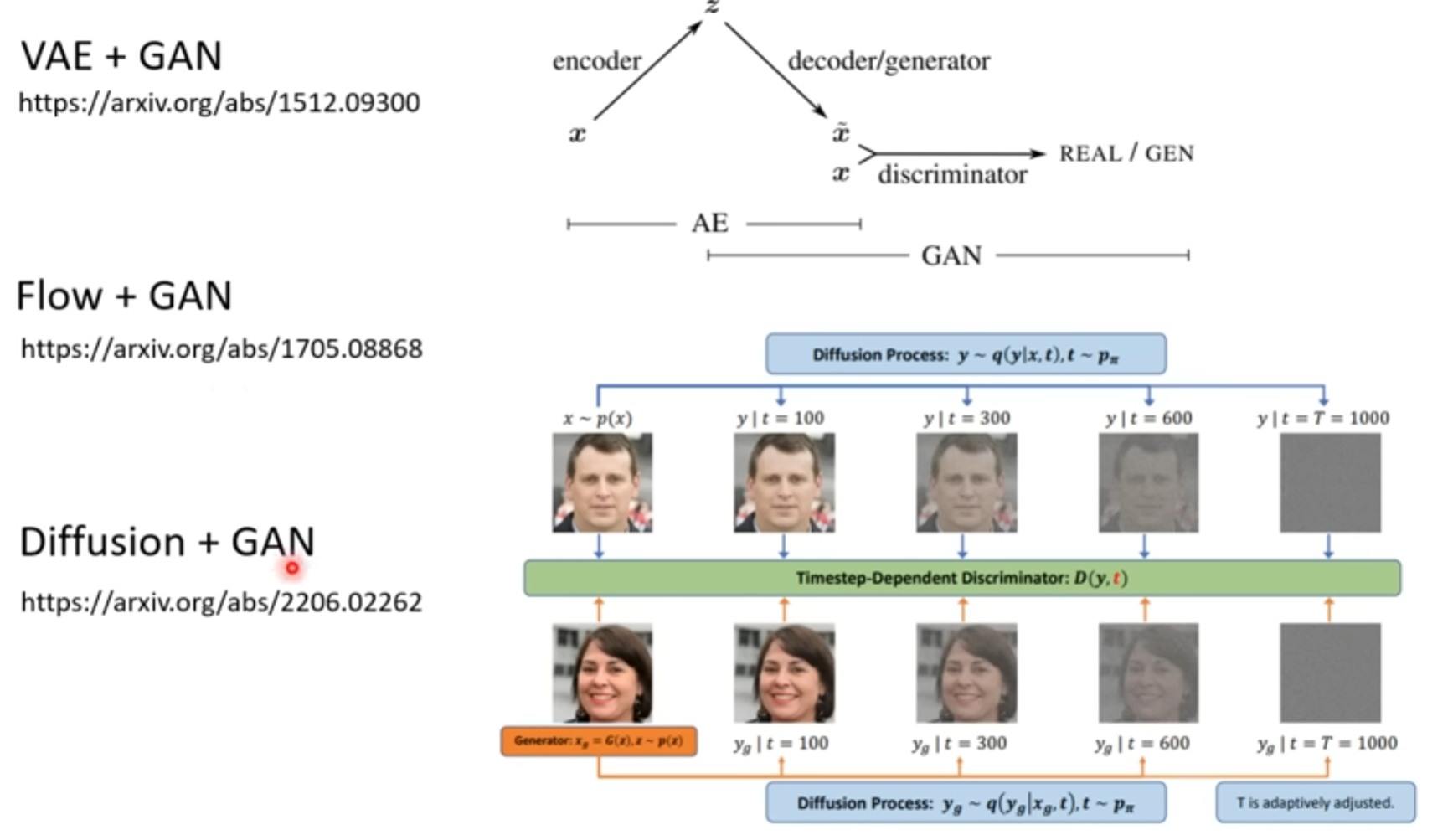
GAN
只学习一个decoder,从Normal的噪声输入得到图片
然后学习一个 discriminator,用来分辨生成图片和真实图片
差异
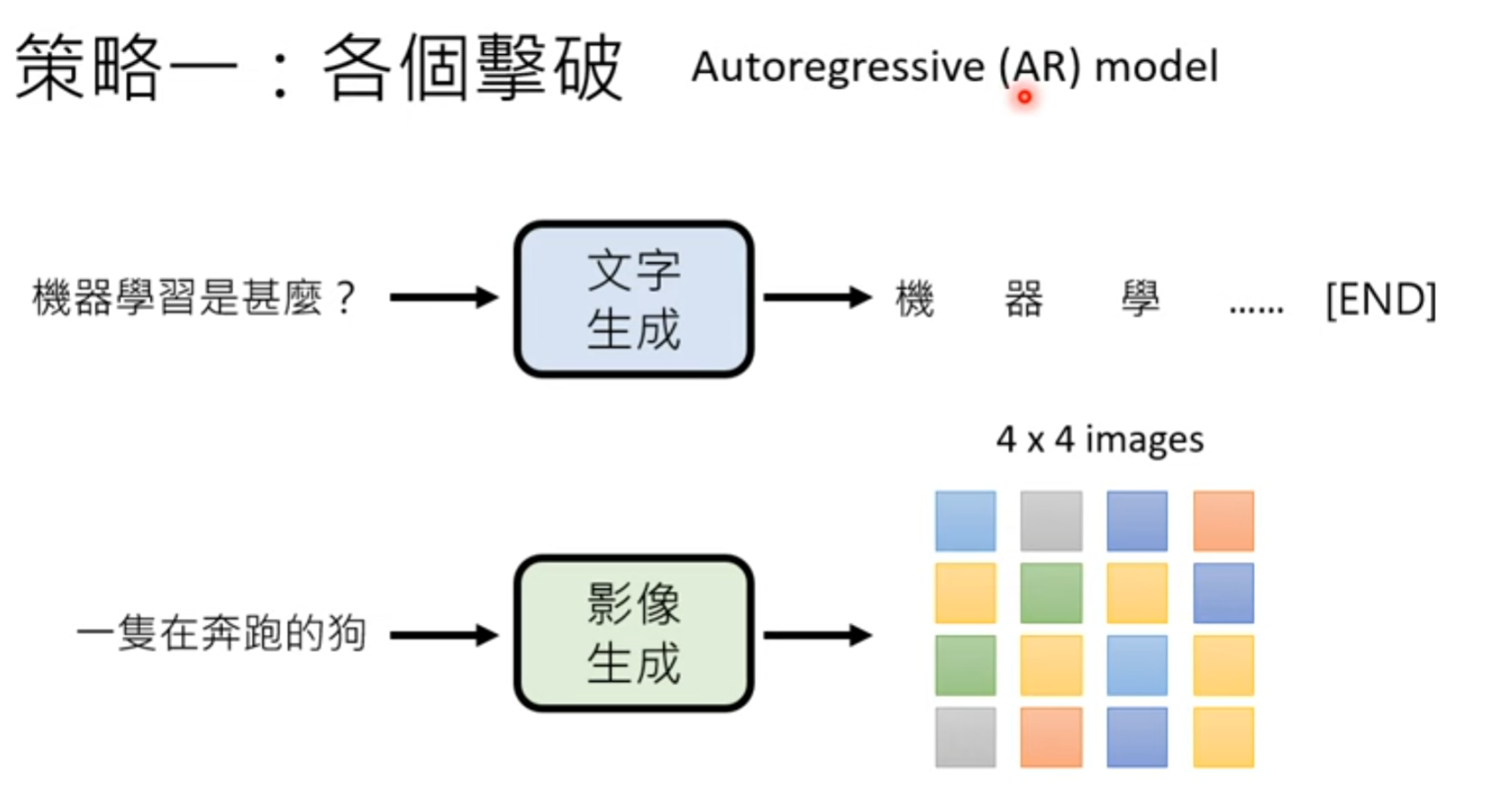
生成式学习 两种策略
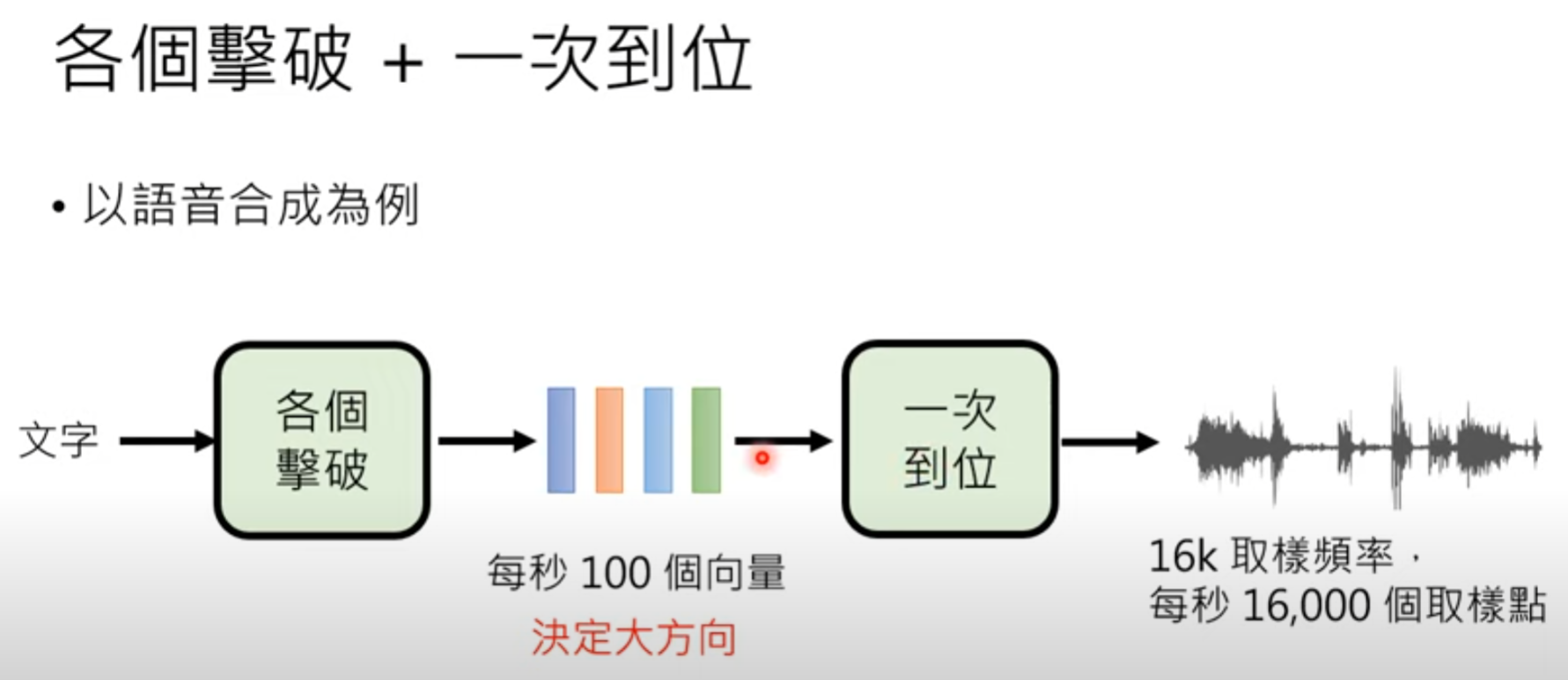
策略一 各个击破 autoregressive AR Model
文字 一个一个token
图像 一个一个像素
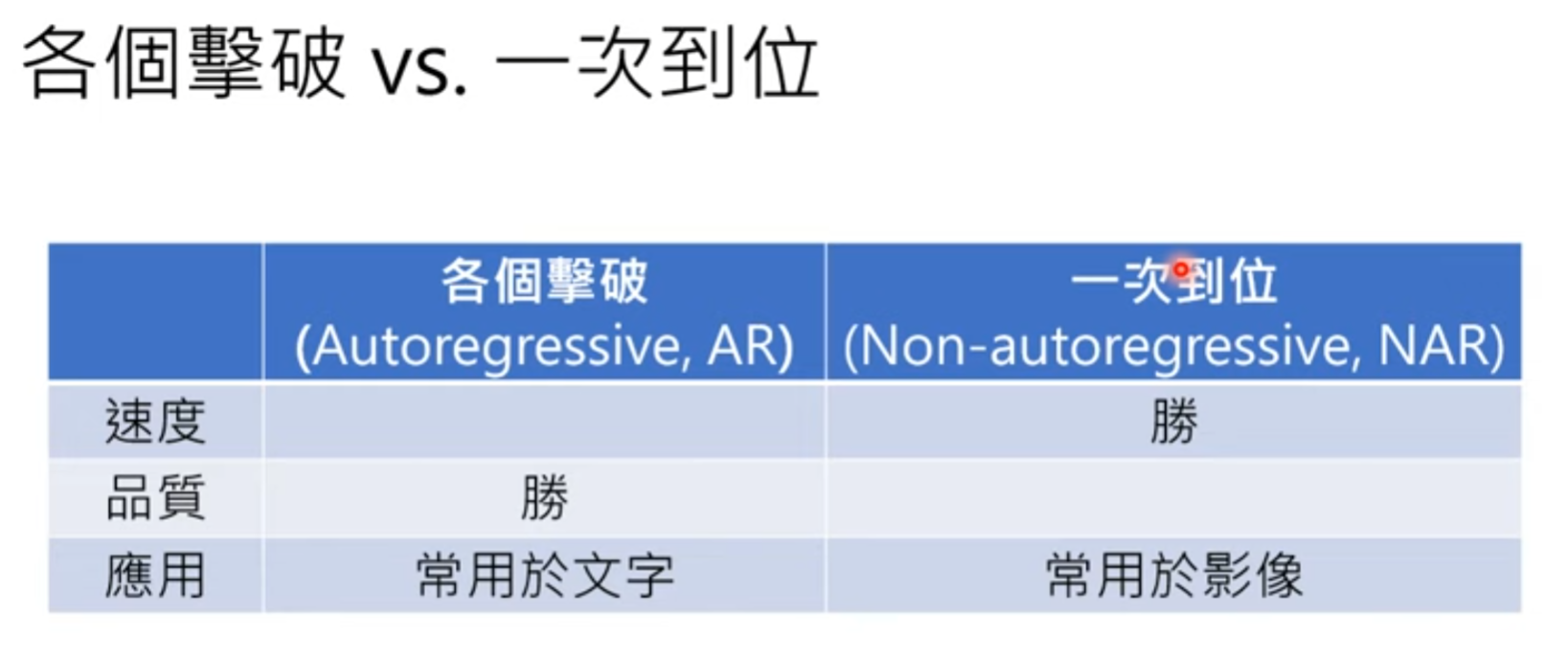
策略二 一次到位 Non- autoregressive NAR model
文字生成,怎么直到输出答案的长度呢
一 固定长度,把无效的去掉
二现决定长度
区别
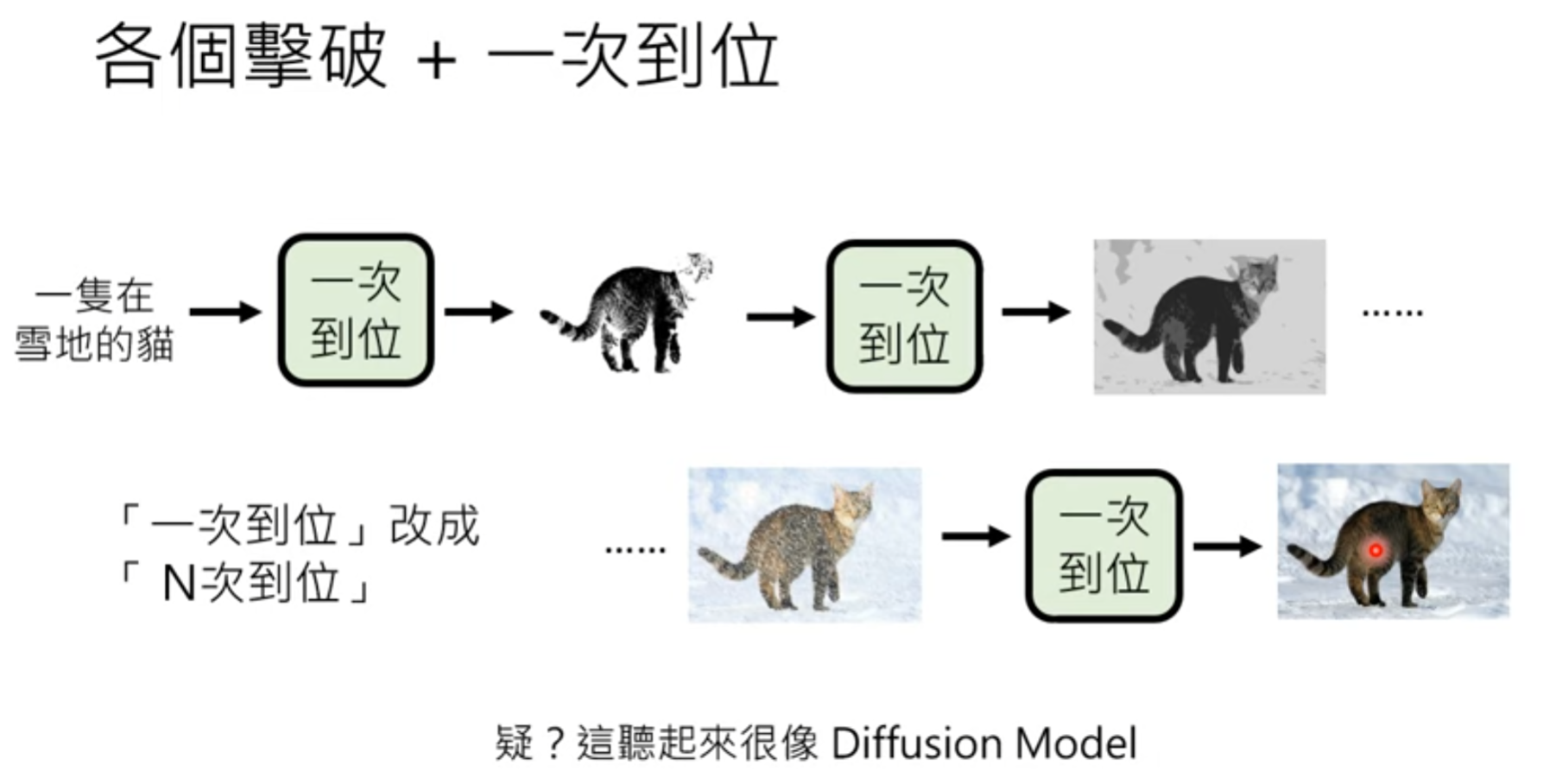
结合
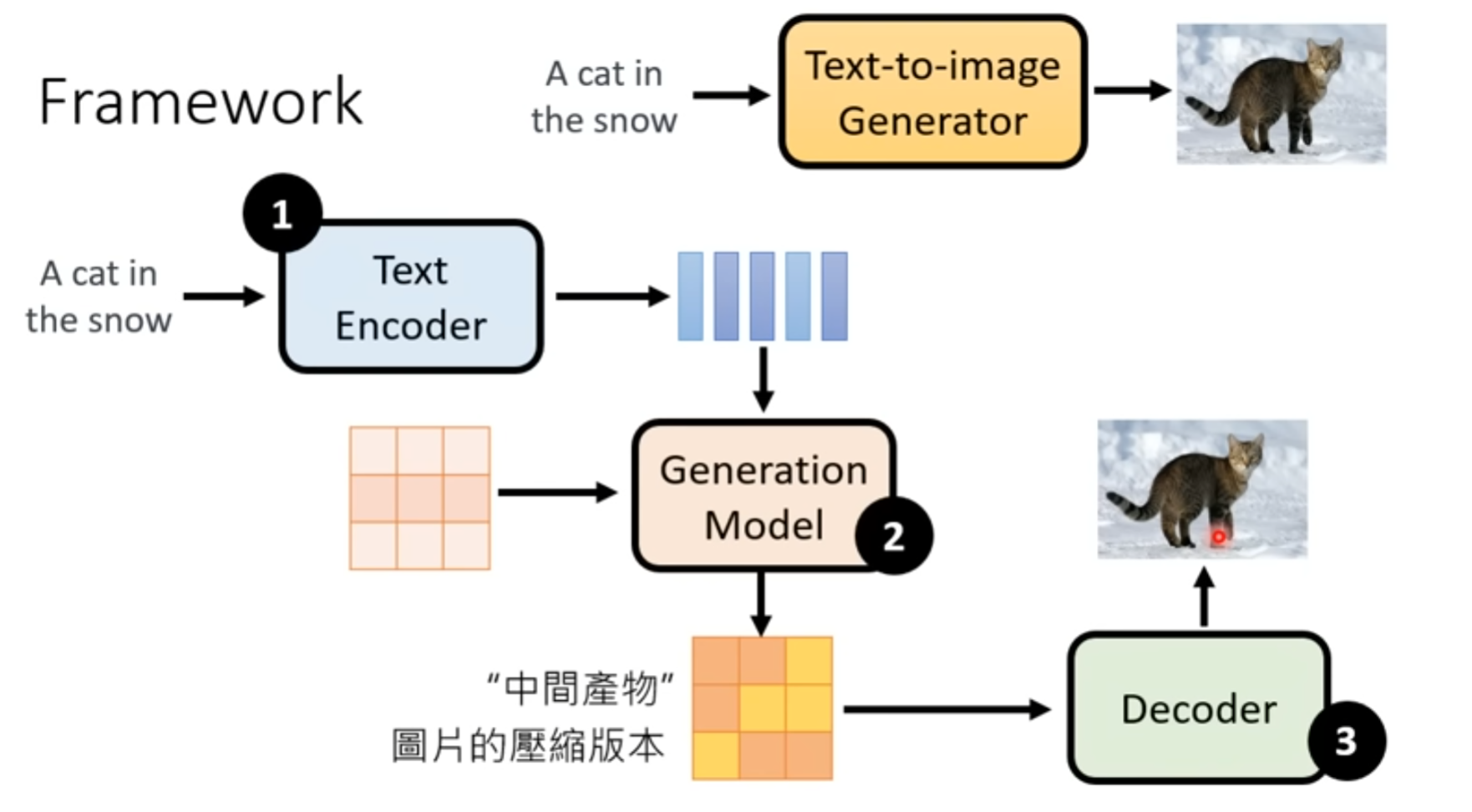
文字生成图片 模型框架
例子
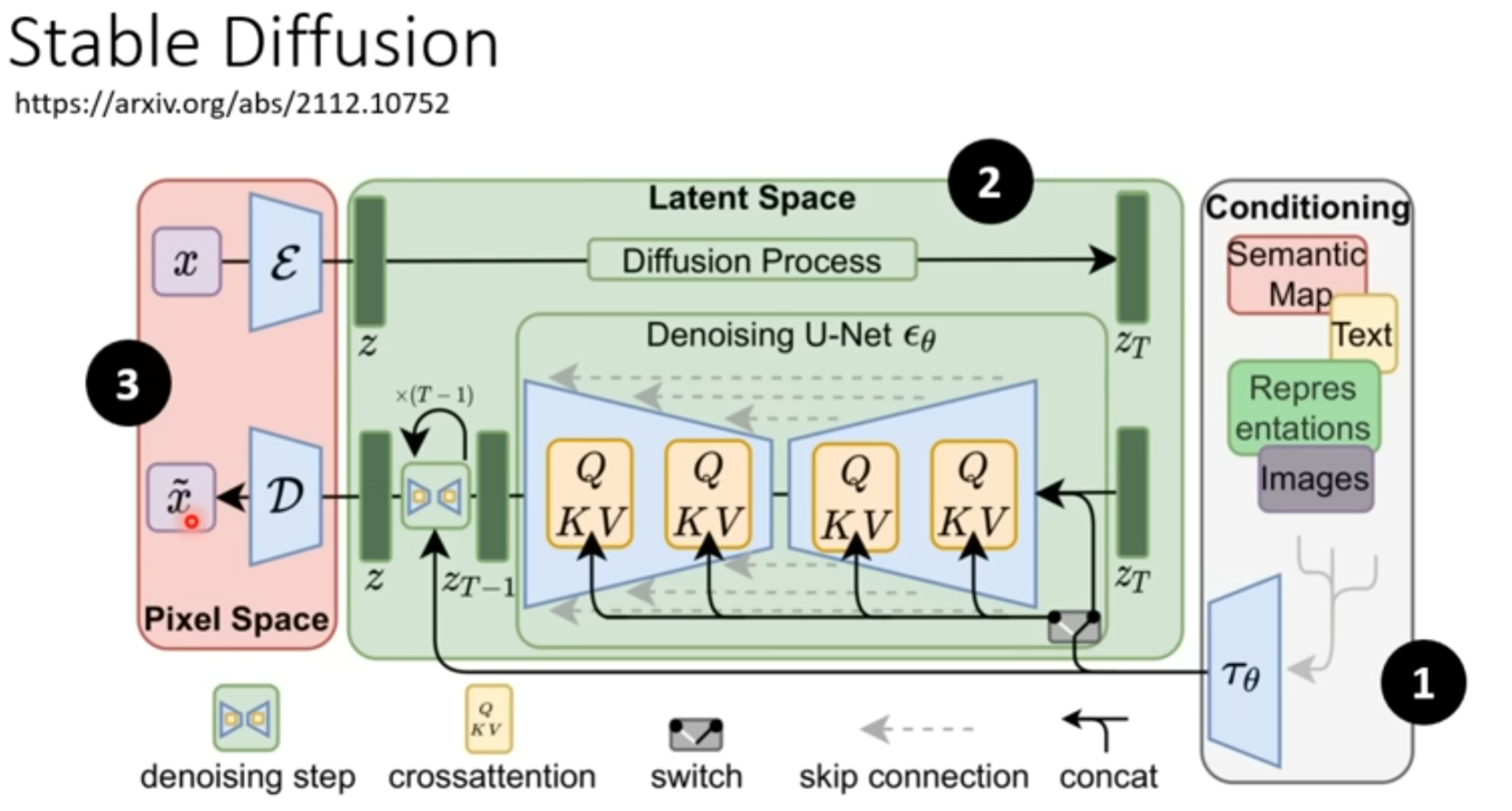
例子1 Stable Diffusion
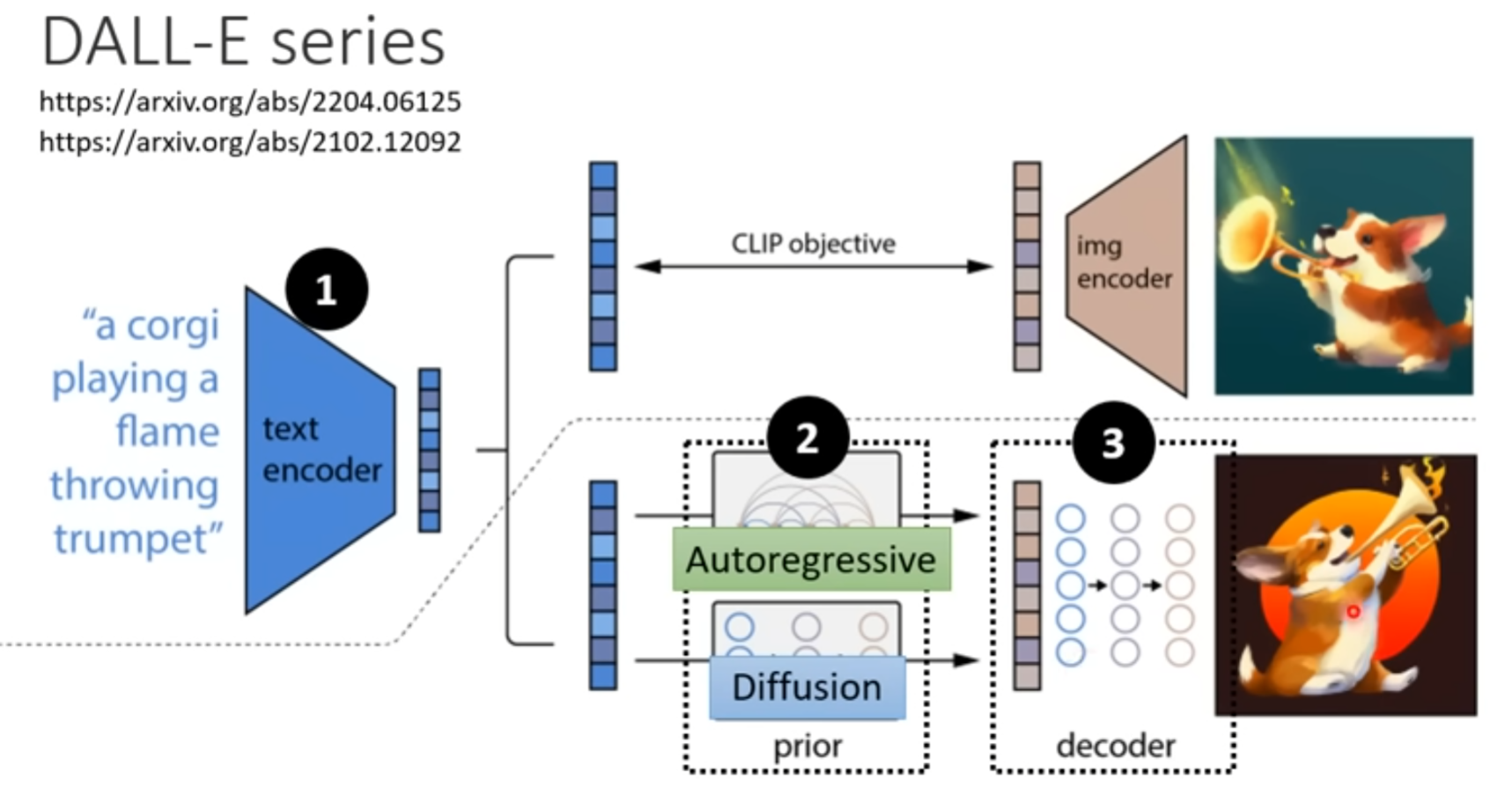
例子2 DALL-E series
例子3 Imagen
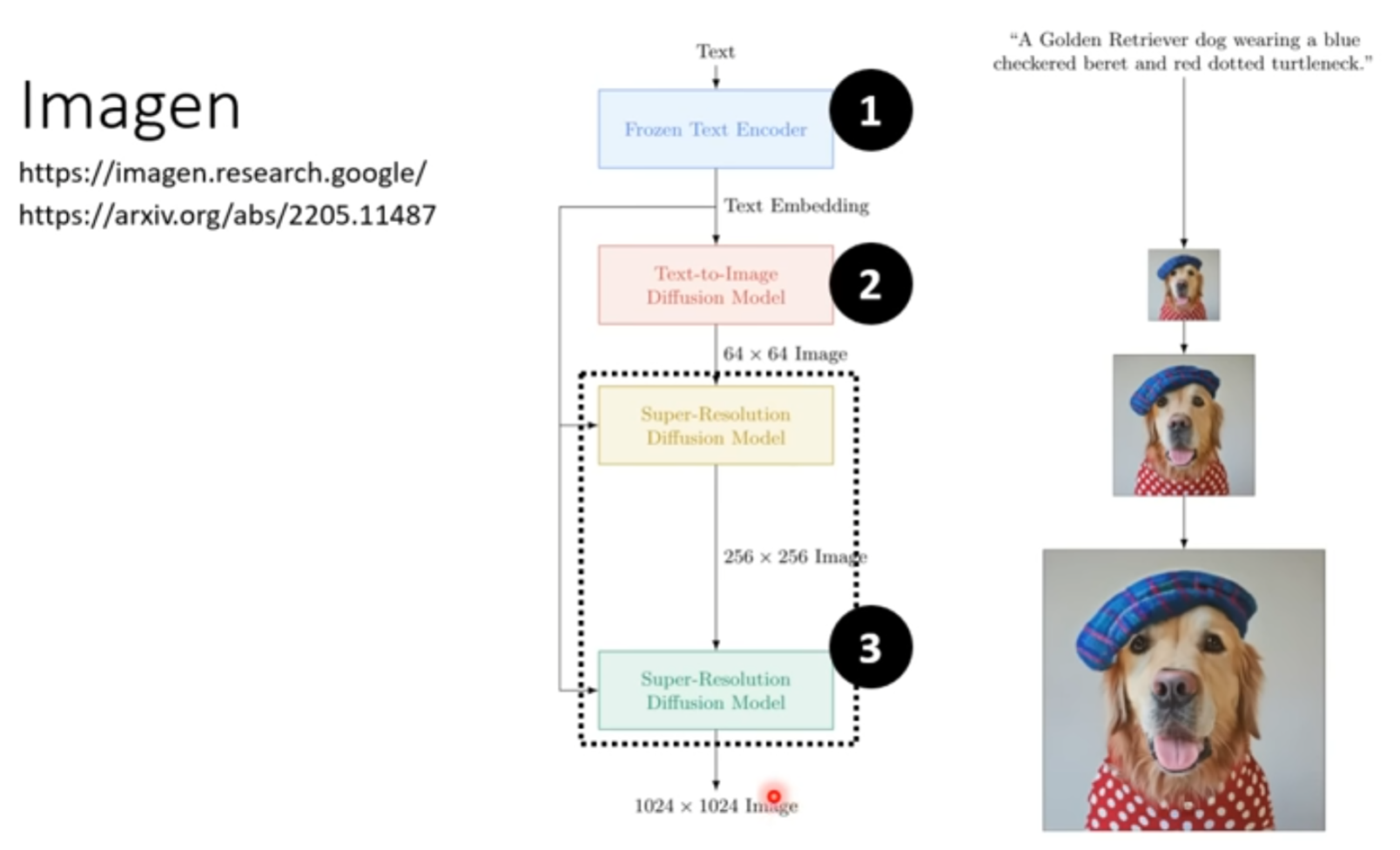
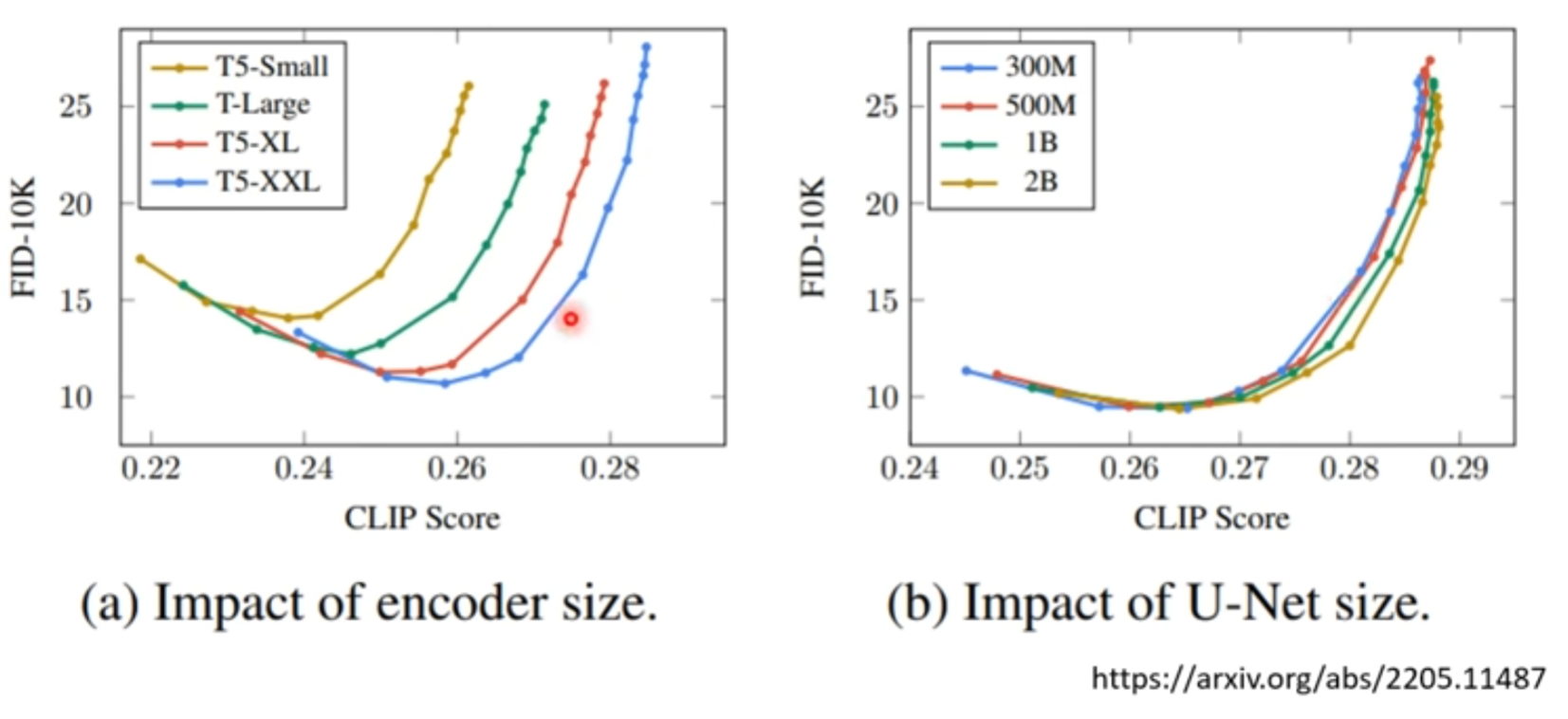
1 文字的 encoder
对结果影响很大
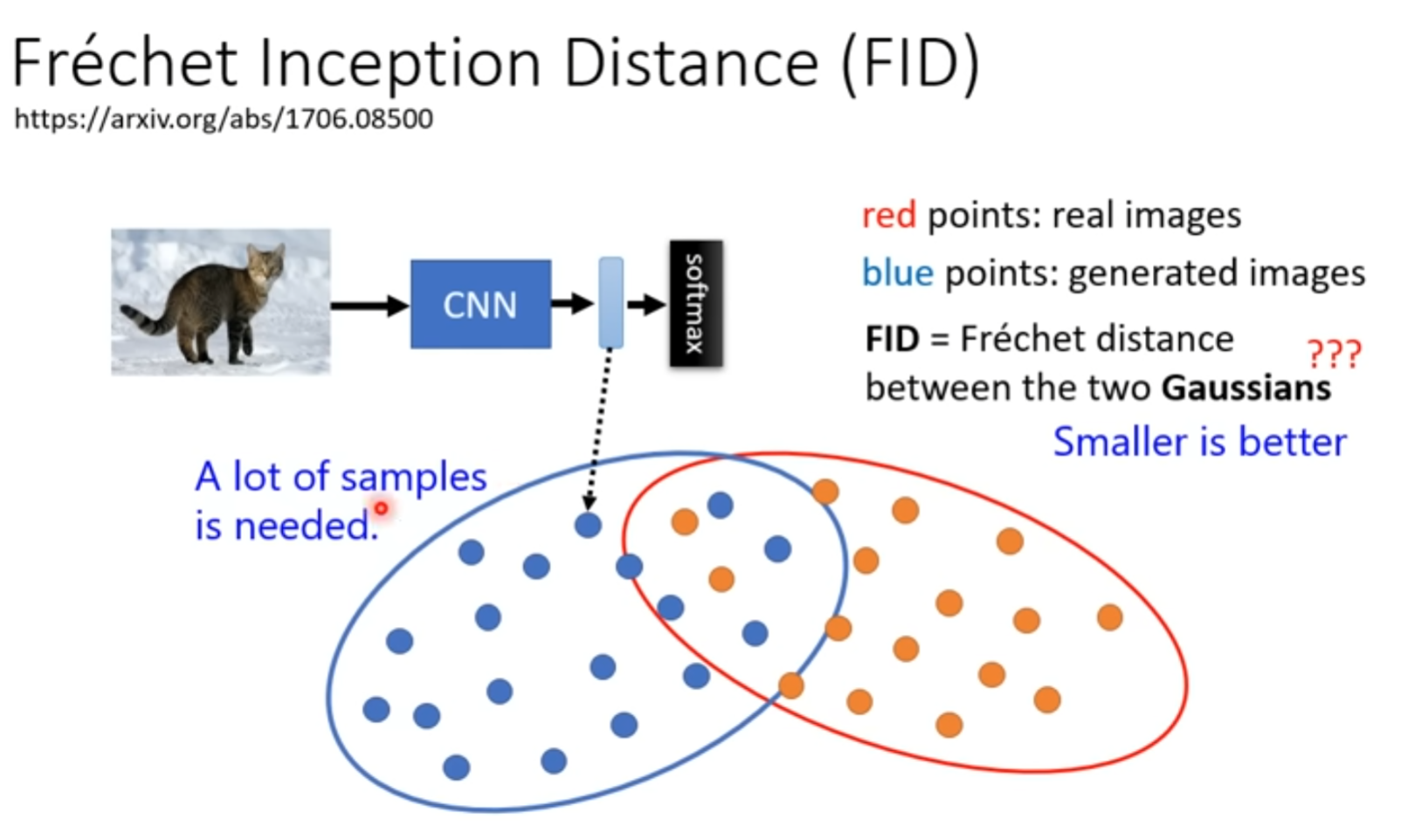
FID 衡量图像生成效果
有一个图片分配的model,
然后 生成图片和真实图片的距离
假设两组都是 高斯分布 ,然后计算 Frechet distance
距离越小越好
问题,需要大量的结果才能衡量FID
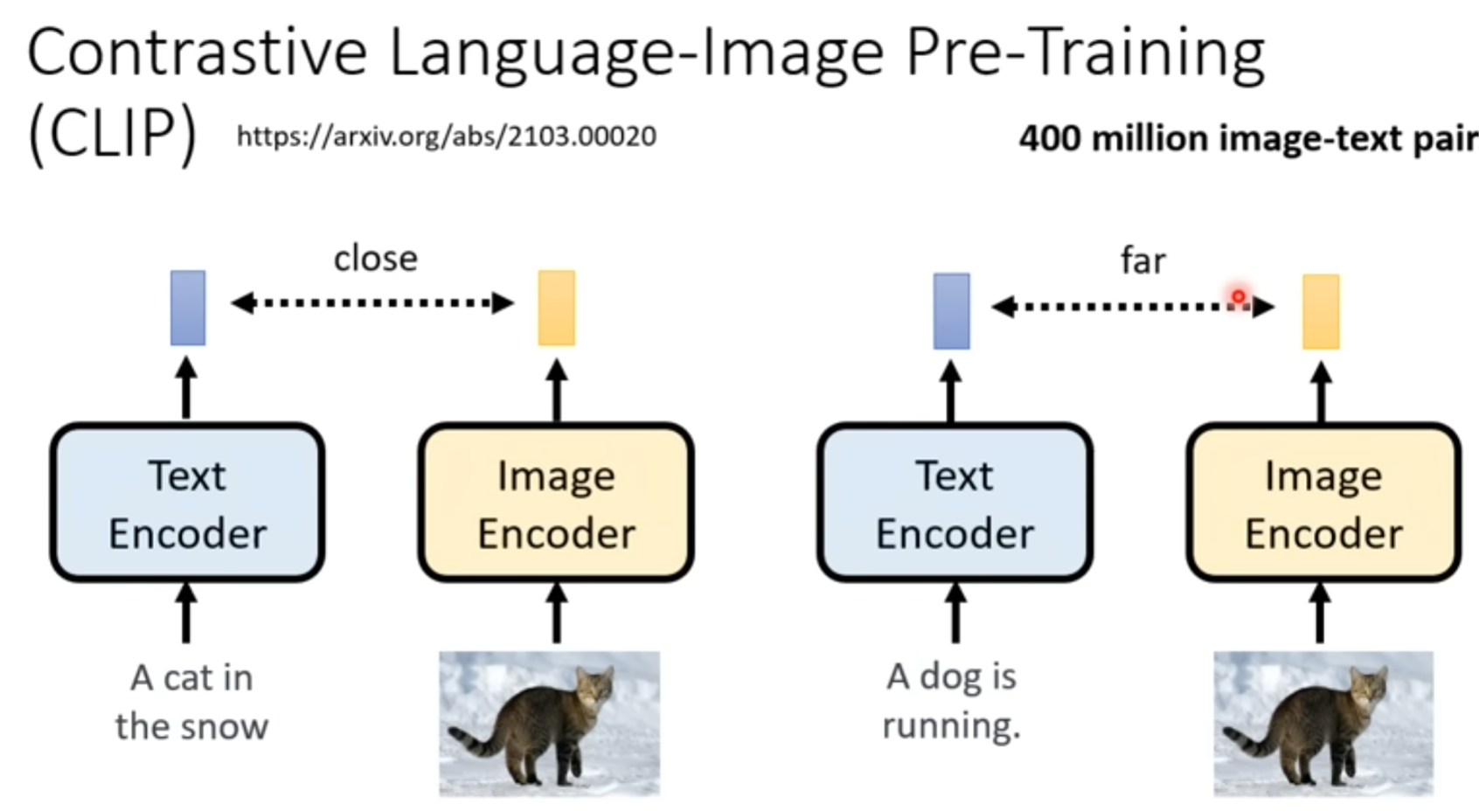
CLIP 4
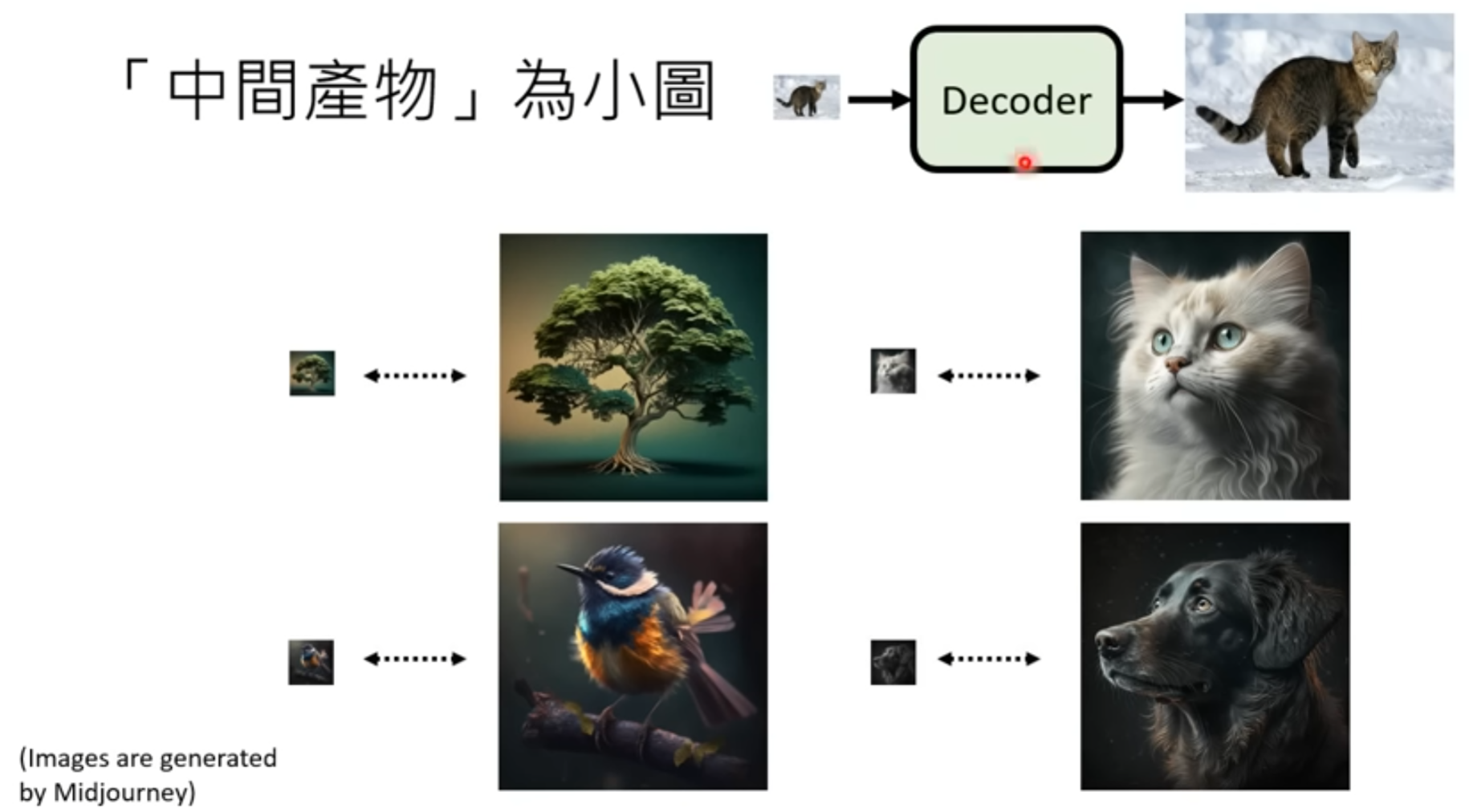
2 decoder
1 如果中间产物是小图,decoder将小图变成大图
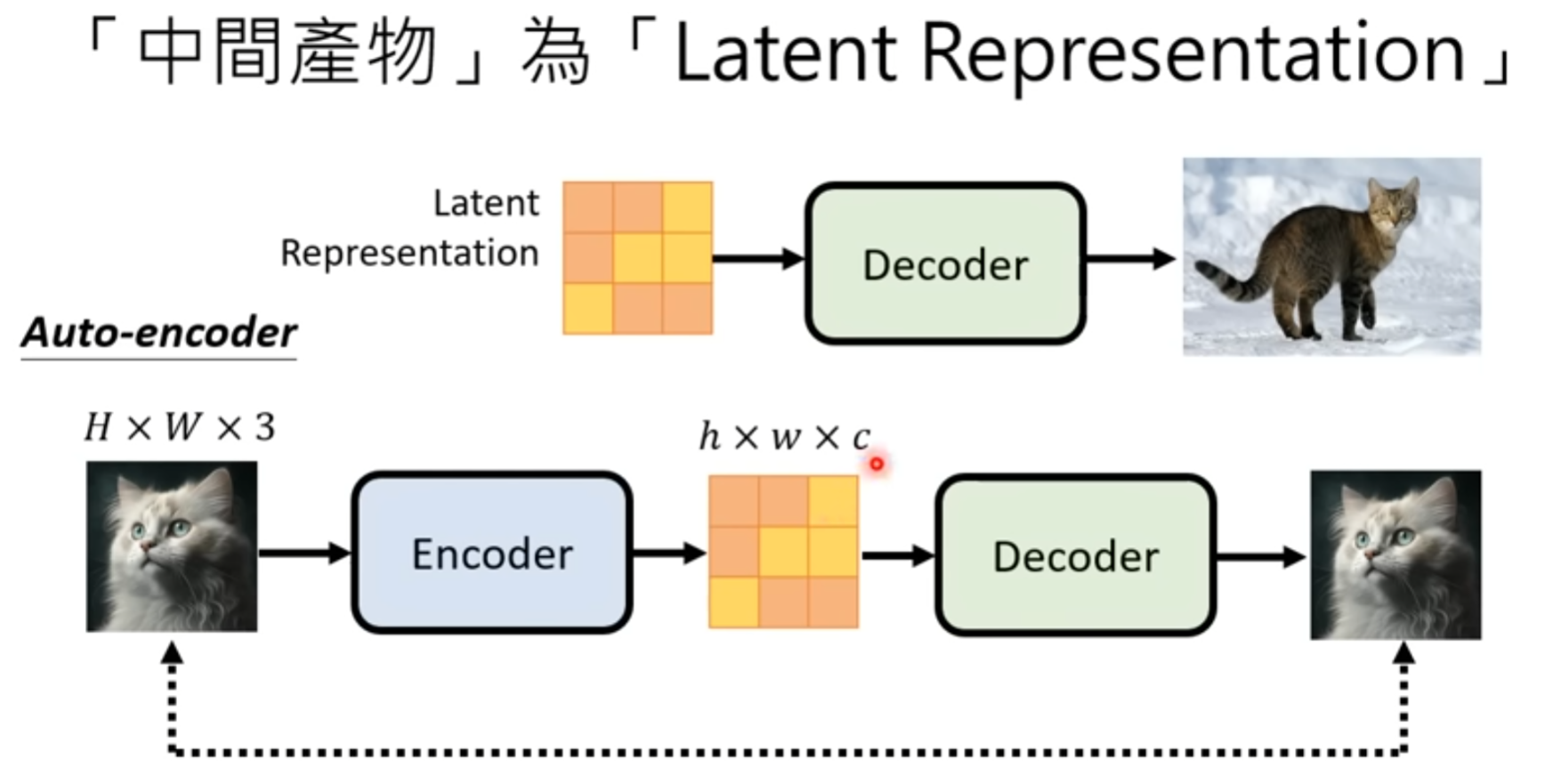
2 如果中间是latent Representation,那就训练一个auto encoder
3 Generation model
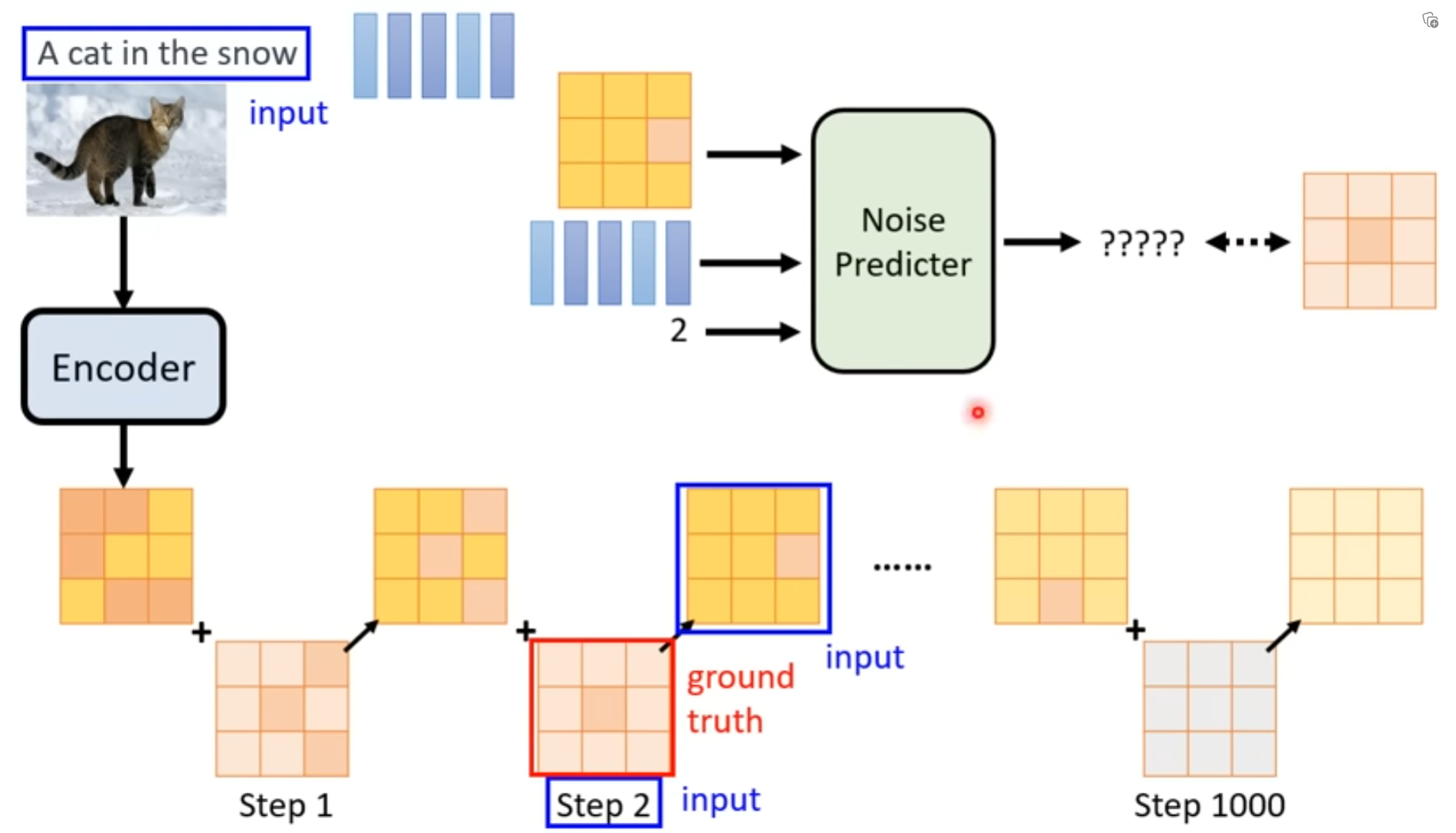
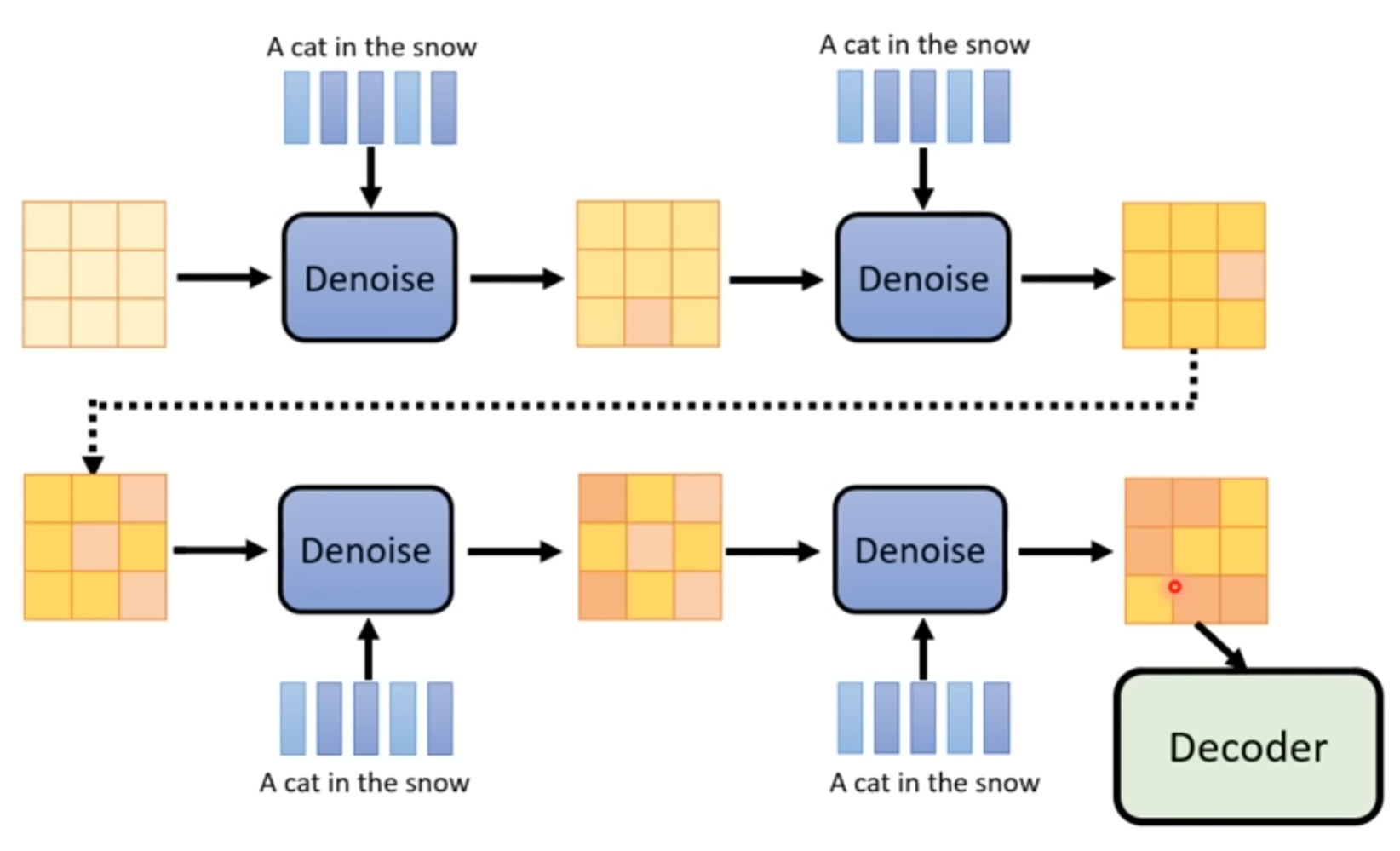
数学推导
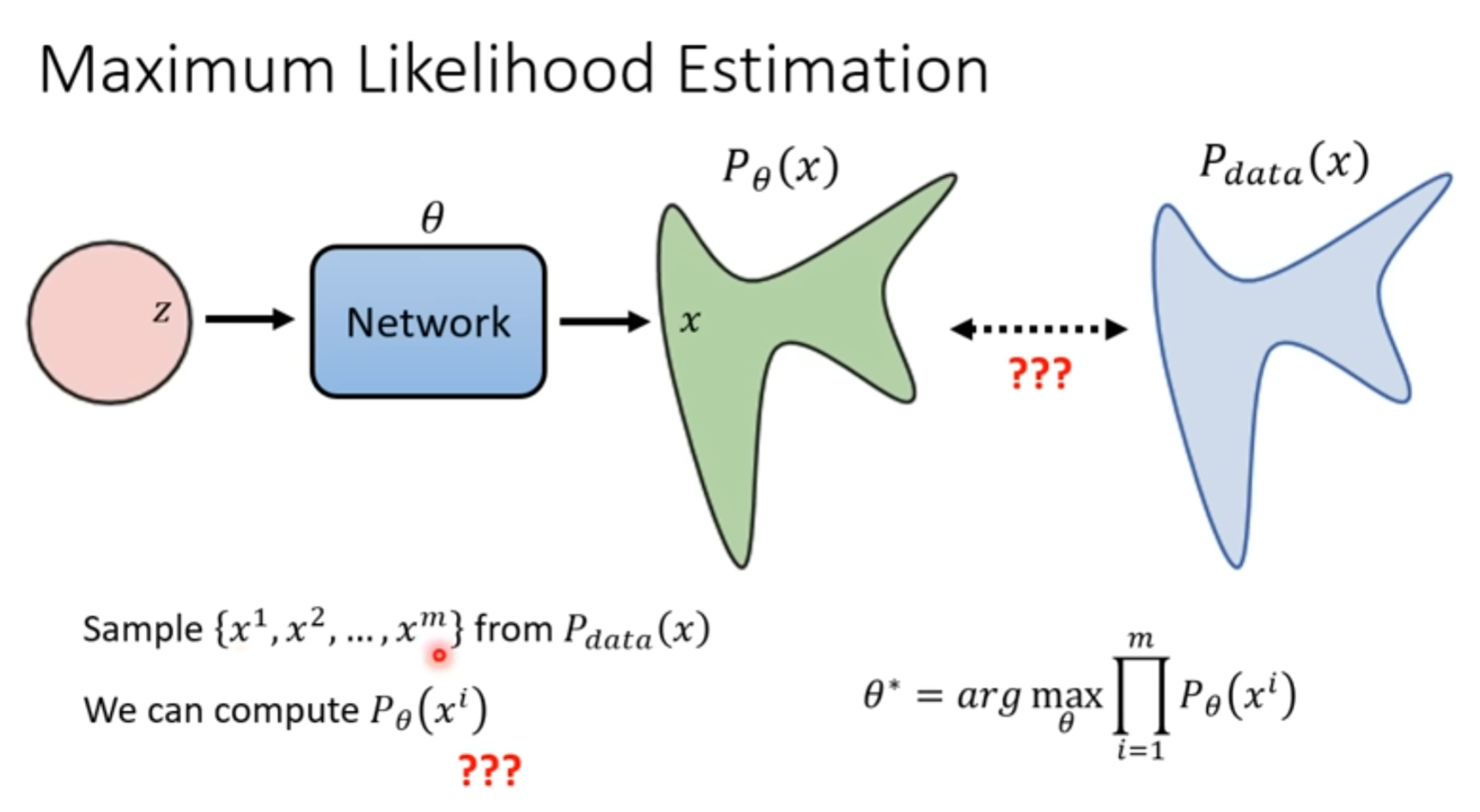
目标
找到一个$\theta$ ,让sample的样本在生成得到的概率分布$P_\theta$中越大越好,(这其实等价于让分布$P_\theta$和$P_{data}$越接近越好)

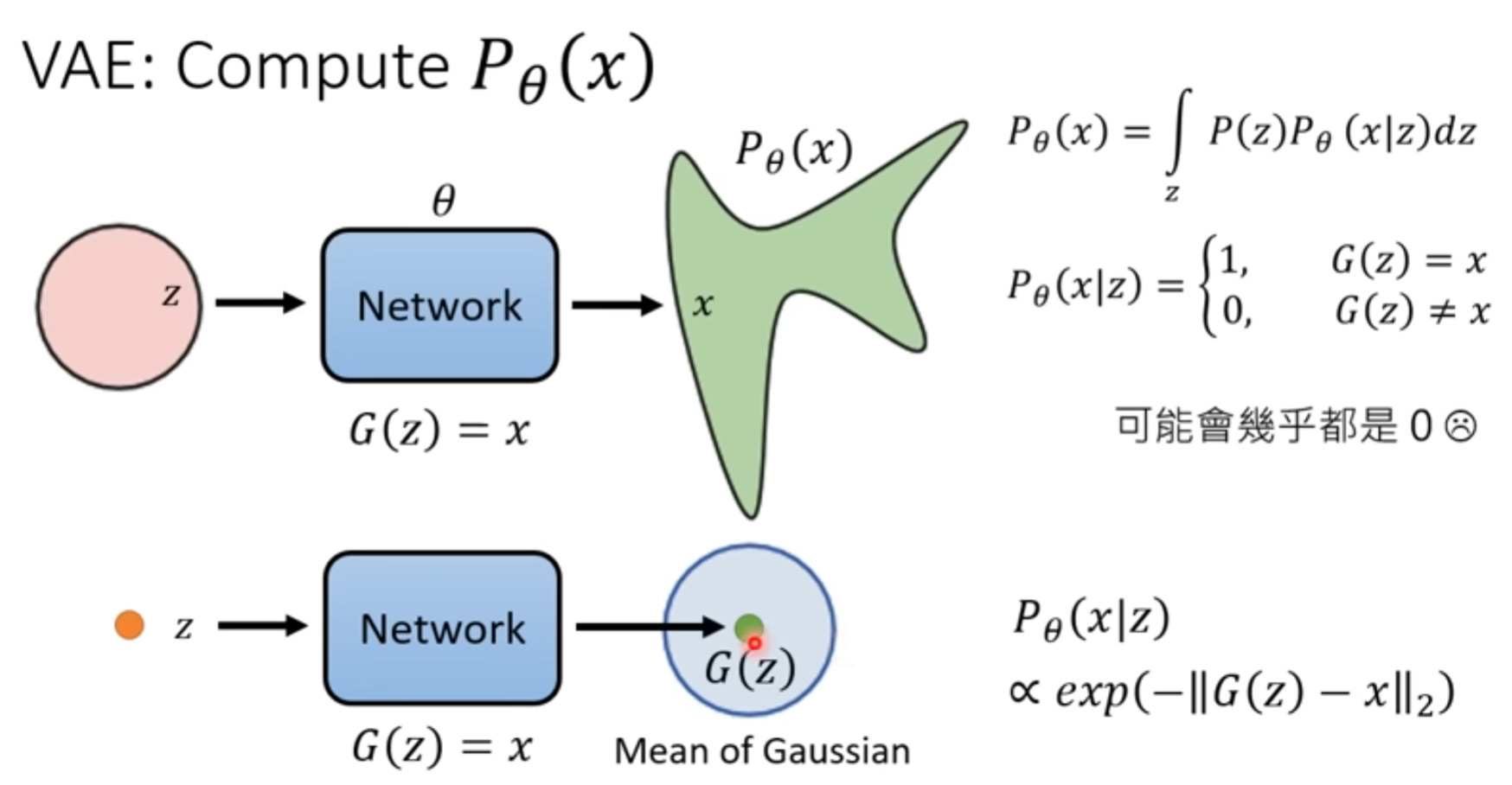
VAE
认定生成的分布是一个 高斯分布
VAE 下界

DDPM
把这个结果也想象成 高斯分布
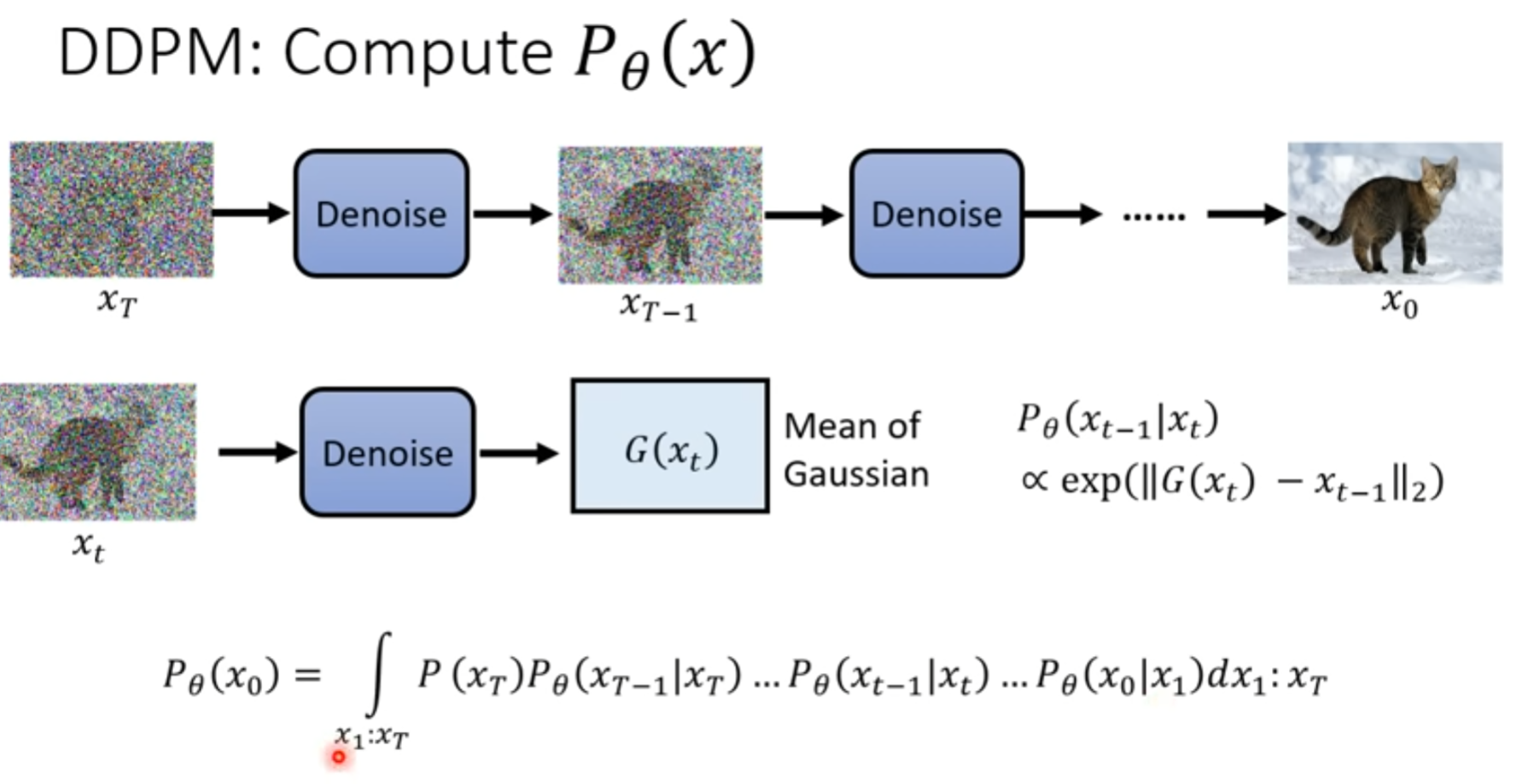

如何直接计算出来
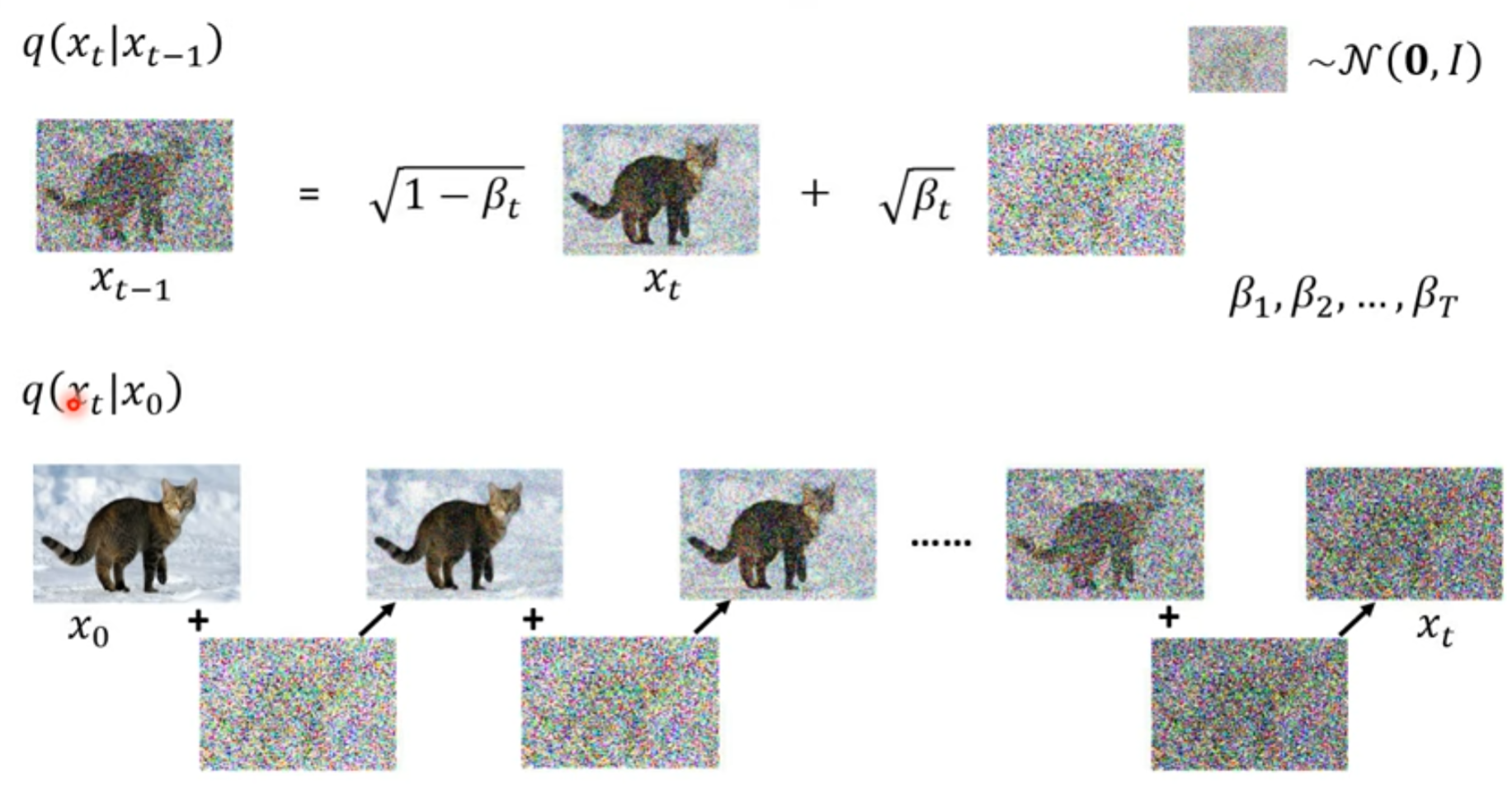
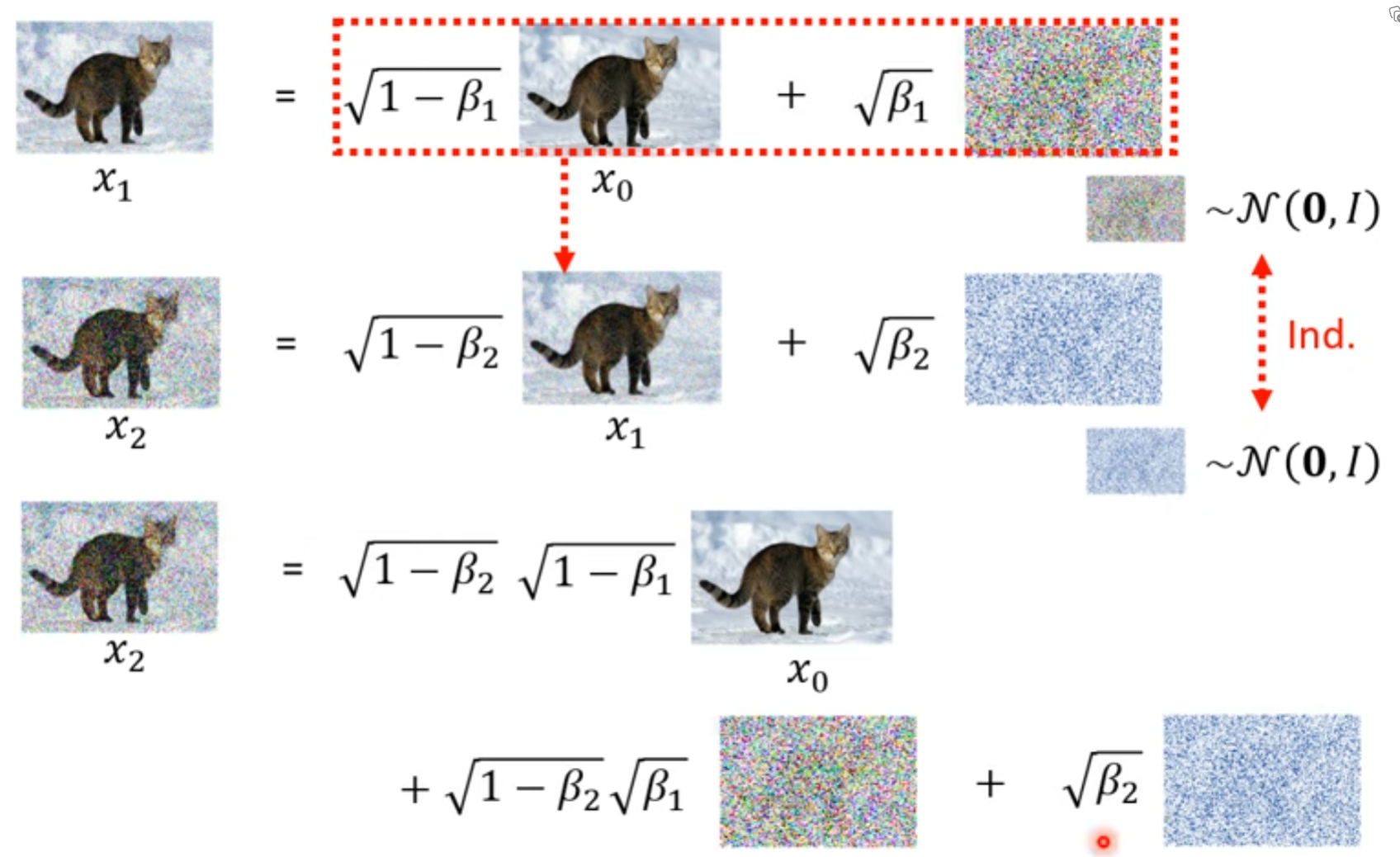

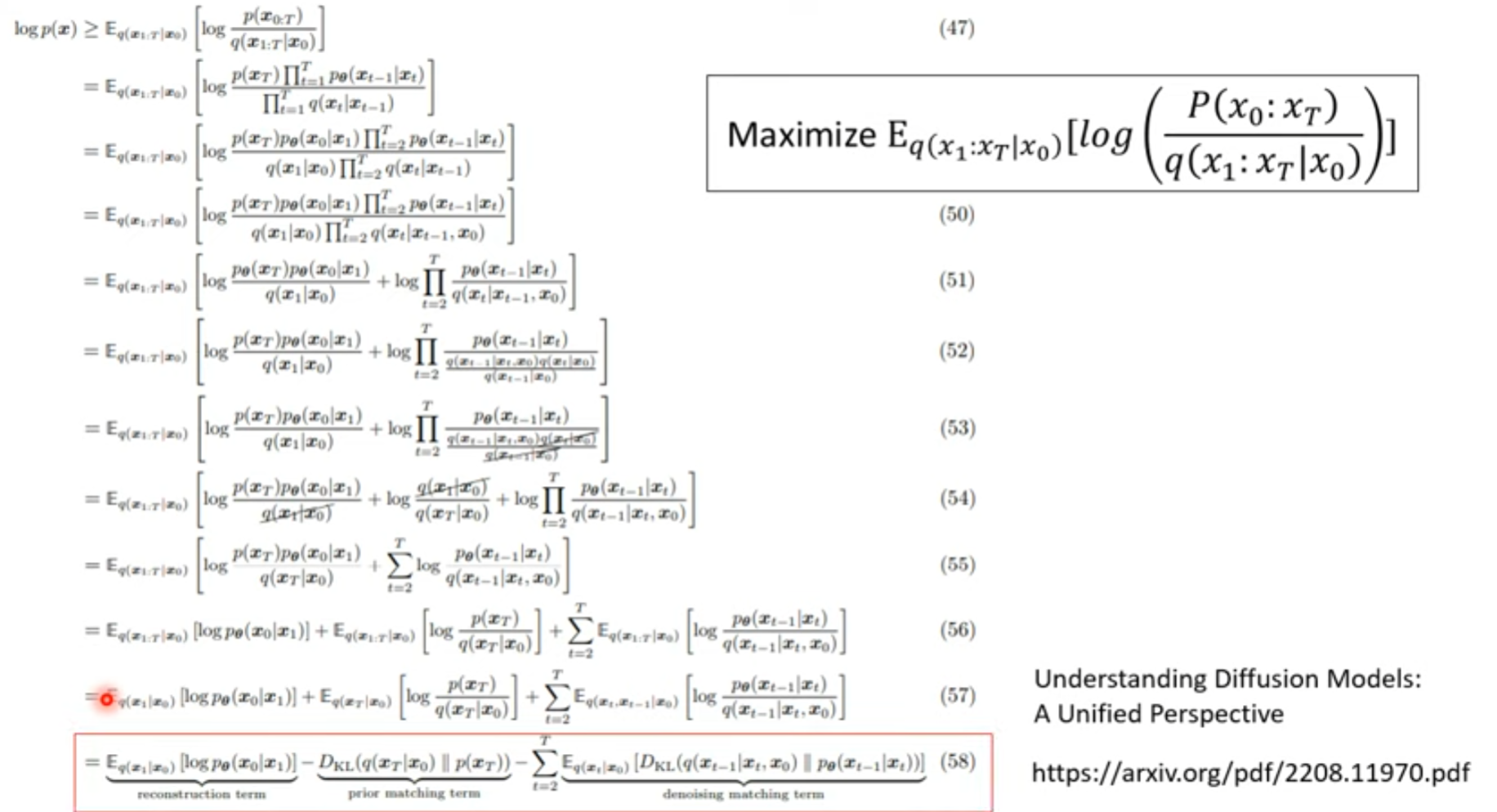
如何最小化

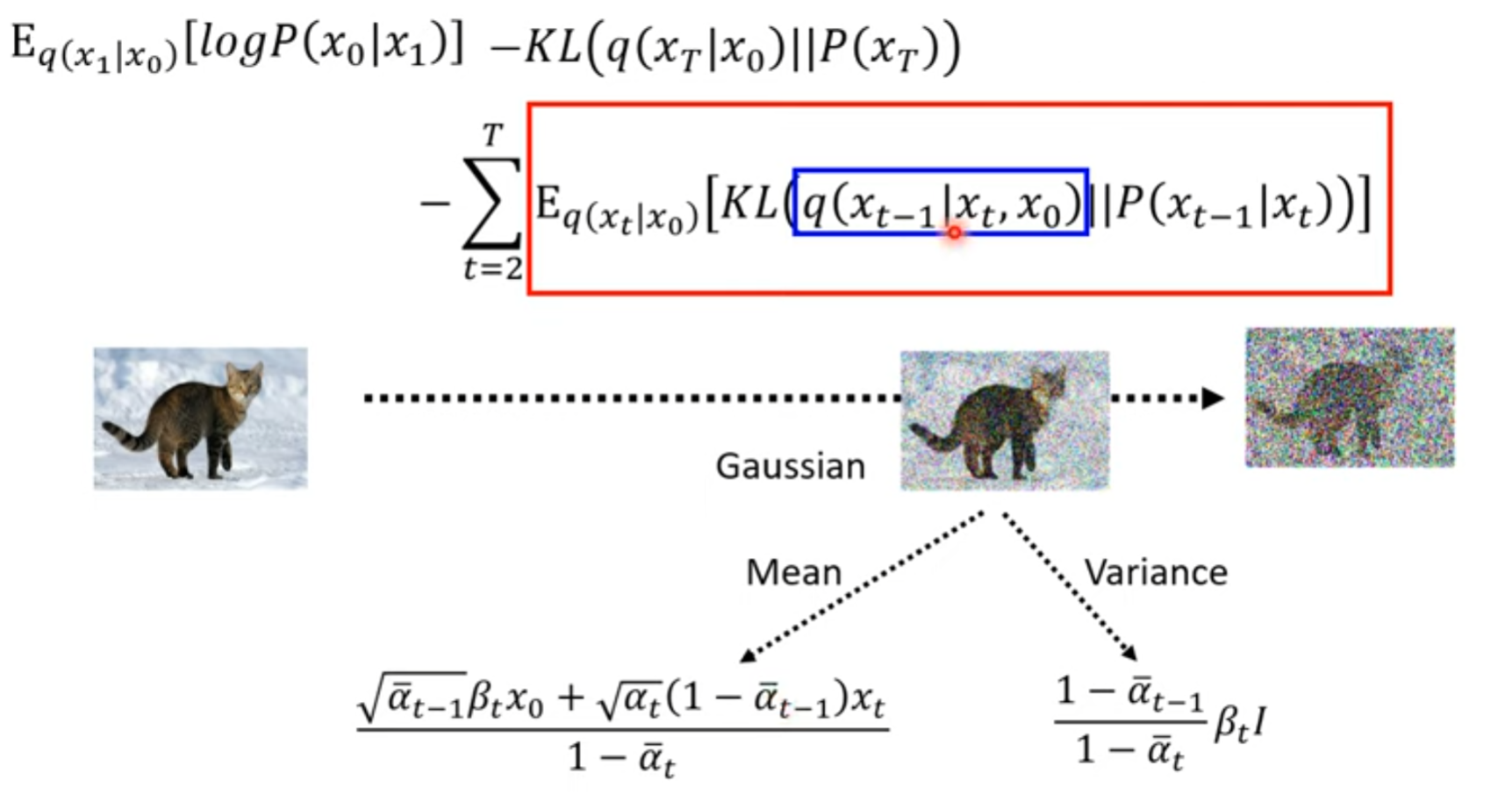
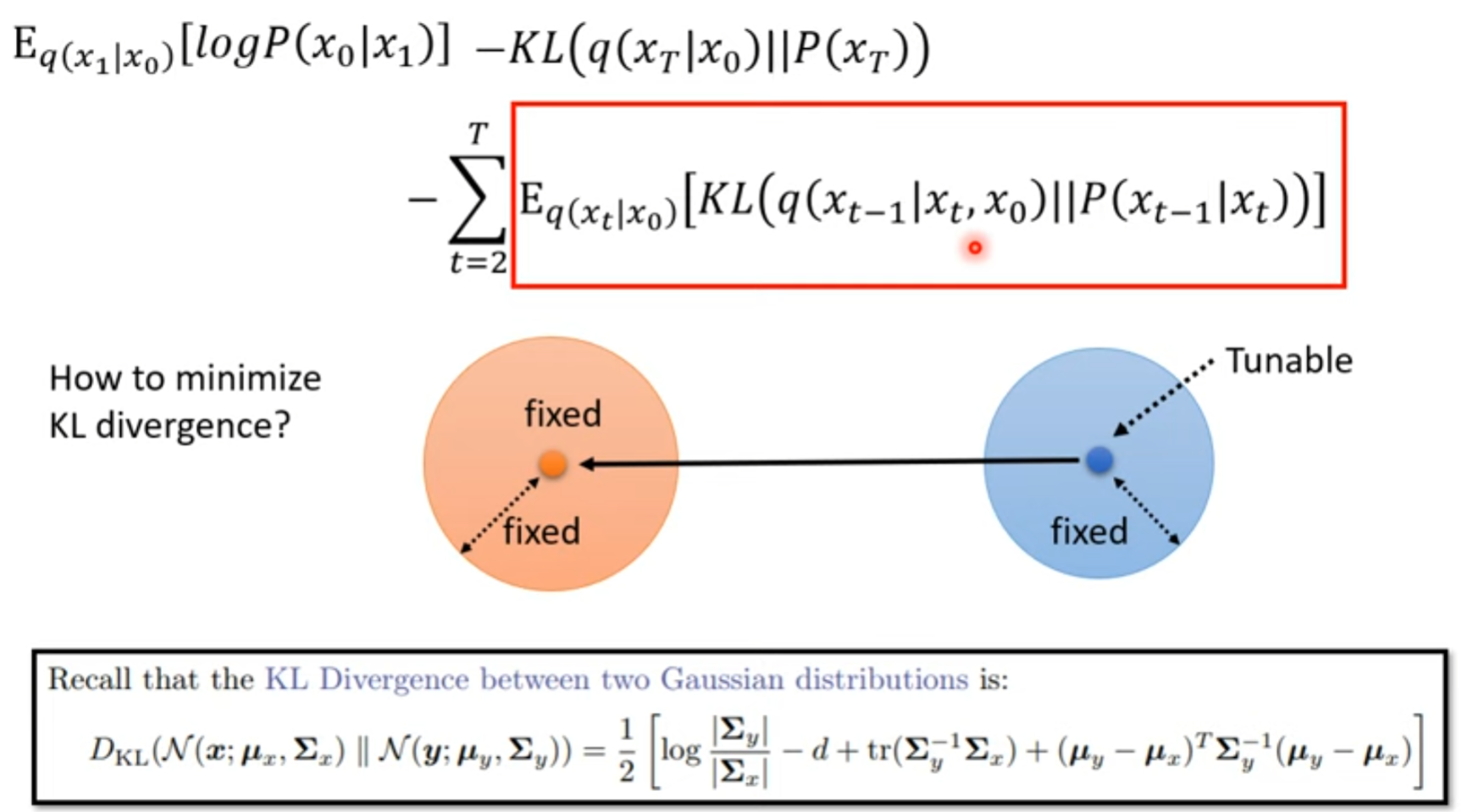
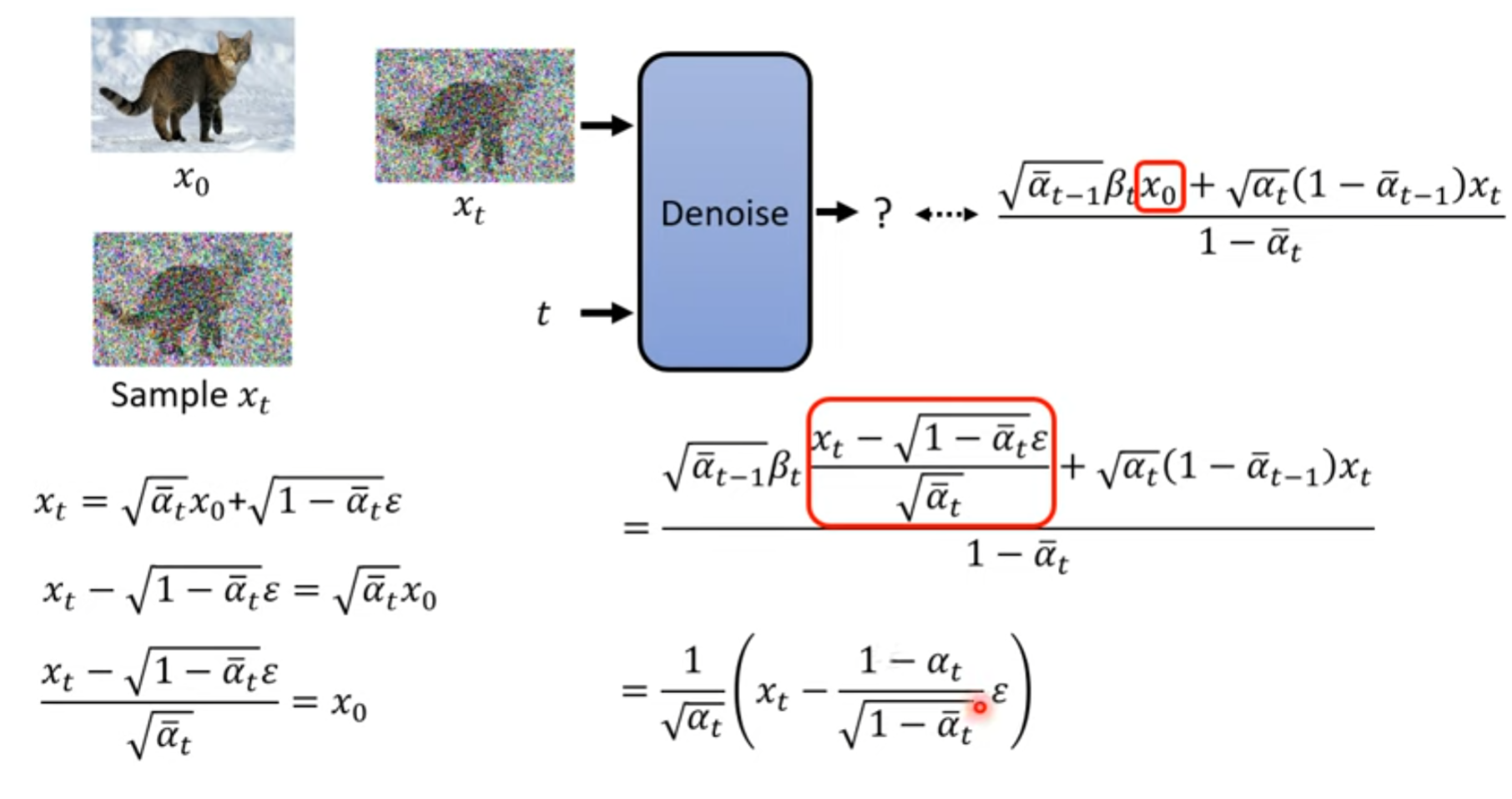
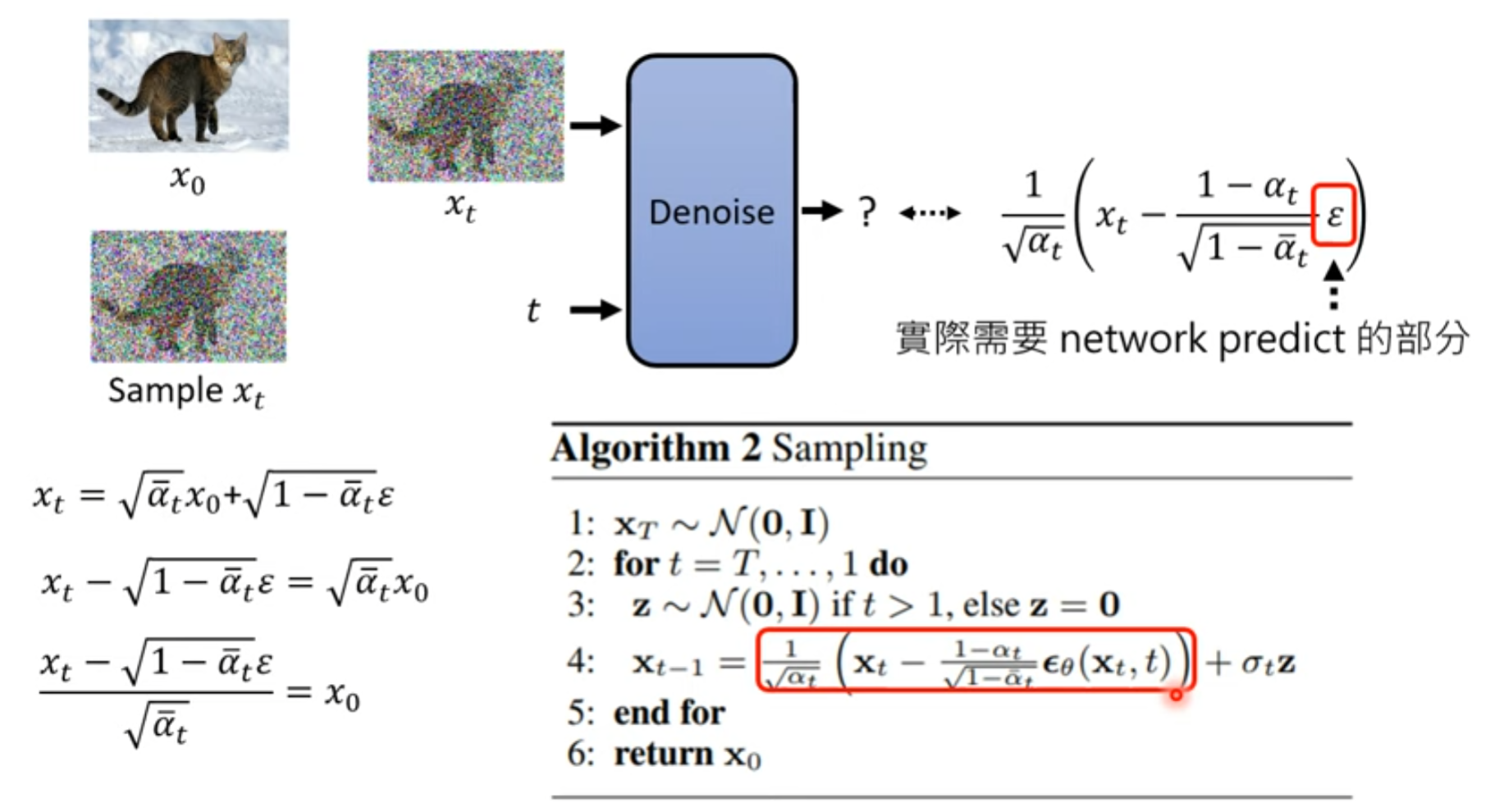
Denoise的目标
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2023/09/01/Generativa-AI-01-Introduction/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)