VAE
代码实现
https://colab.research.google.com/github/zuti666/generative-models/blob/master/VAE.ipynb
| [了解变分自动编码器 (VAE) | 作者:约瑟夫·罗卡 | 迈向数据科学 (towardsdatascience.com)](https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73) |
论文
[1312.6114] Auto-Encoding Variational Bayes (arxiv.org)
自编码器 AE (Auto-encoder) & 变分自动编码器VAE(Variational Auto-encoder)
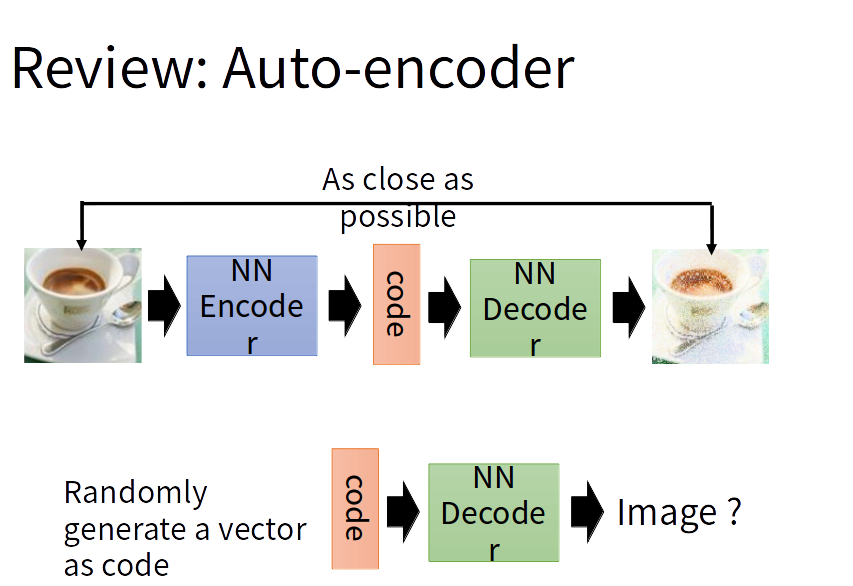
学习编码解码过程,然后任意输入一个向量作为code通过解码器生成一张图片。
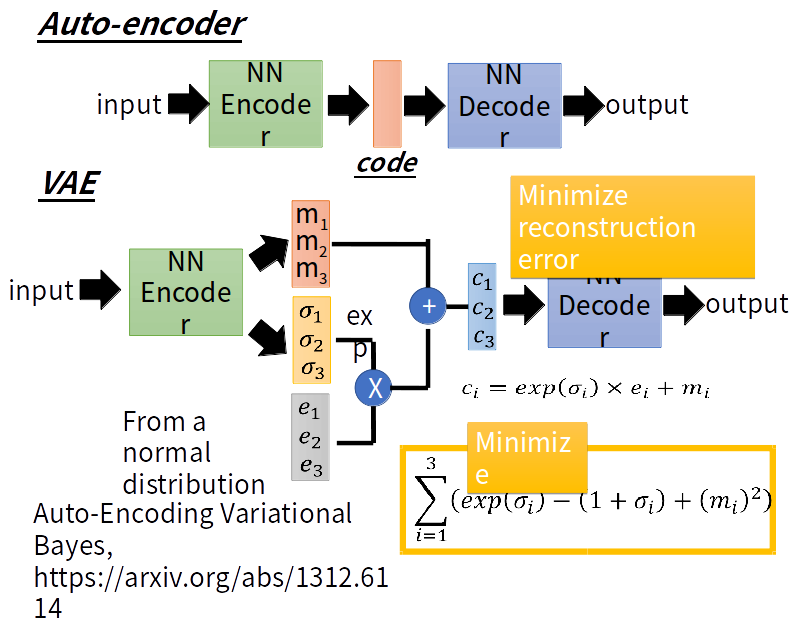
VAE与AE的不同之处是:VAE的encoder产生与noise作用后输入到decoder
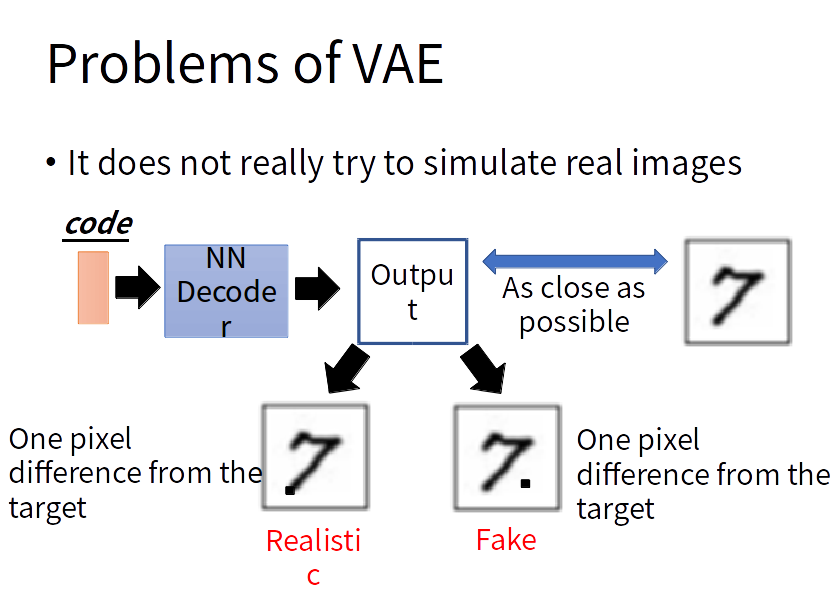
VAE的问题:VAE的decoder的输出与某一张越接近越好,但是对于机器来说并没有学会自己产生realistic的image。它只会模仿产生的图片和database里面的越像越好,而不会产生新的图片。
Why VAE?
intuitive reason:
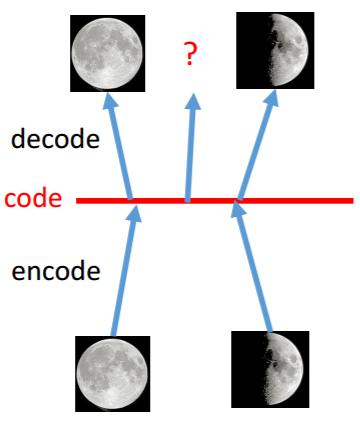
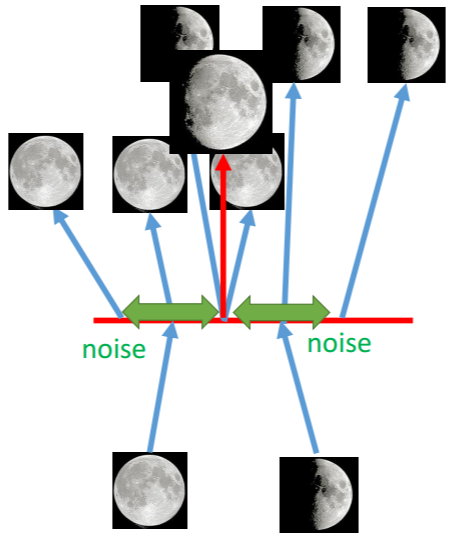
AE的过程 VAE的过程
这时给定满月与弦月之间的code,AE会得到什么?可能得到一个根本就不是月亮的东西。对于VAE,满月的code在一个noise的影响下仍然需要恢复为满月,弦月的code在一个noise的影响下仍然需要恢复为弦月。那么交集部分应该即为满月有为弦月,但是只能输出一张图像,所以可能会输出一张介于满月、弦月的月像,所以可能会得到一张比AE有意义的图像。再看VAE的流程图。m为原来的code(original code)。c为加了noise的code(Code with noise)。noise的方差是自动学习来的。那如果让机器自己学,那肯定希望方差是0好了,即变为了AE,这时重构误差(reconstruction error)就是最小的。所以要强迫方差不可以太小,设定一个限制:
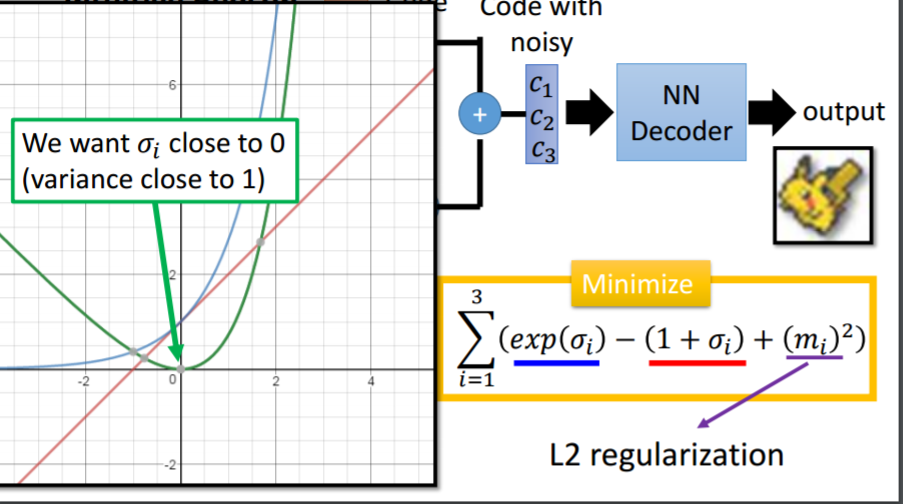
加上这个最小化限制以后,方差就接近于1,不会出现方差为0了。L2正则化减少过拟合,不会learn出太trivial的solution。以上是直观的理解。下面是理论理解:
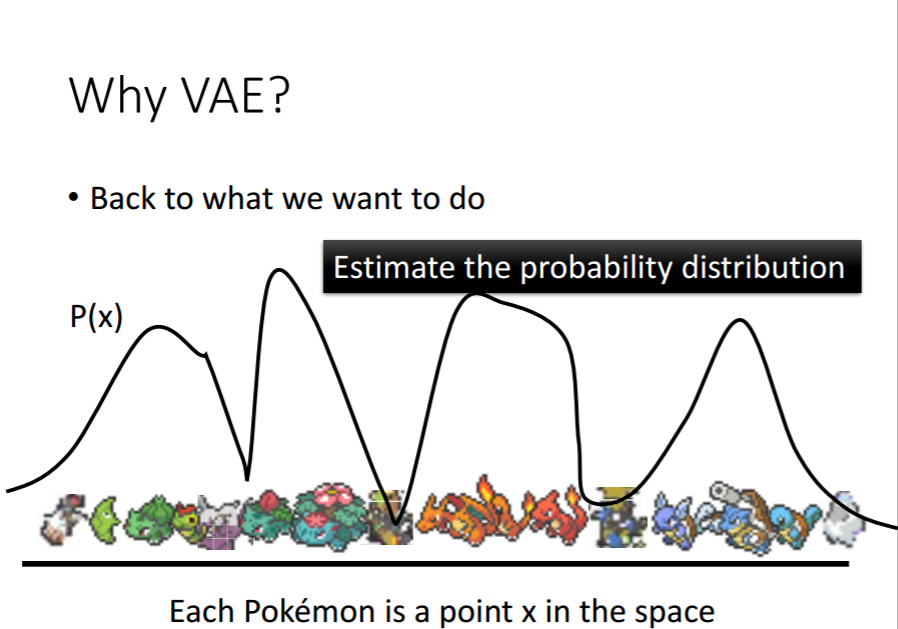
假设P(x)为像Pokemon的概率,那么越像Pokemon,这个概率越大,否则概率越低。那如果我们可以estimate出这个分布也就结束了,那怎么estimate这个高维空间上的机率分布p(x)呢(注意x是一个vector,如果知道了p(x)的样子,就可以根据p(x)sample出一张图)?可以用高斯混合模型(gaussian mixture model)。
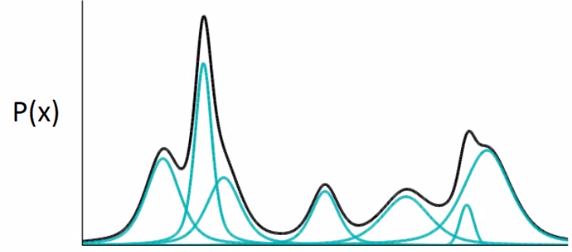
高斯混合模型
现在假设共有100个gaussian,那么这100个gaussian每个都有一个weight。要做的是根据每个gaussian的weight来决定先从哪个gaussian来sample data,然后再从你决定的那个gaussian来simple data。看下图: m为整数代表第几个gaussian。第m个gaussian服从高斯分布的参数为(μm, Σm)。所以P(x)为所有高斯的综合:
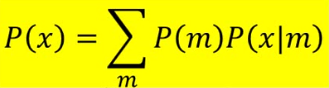
参数解释:
P(m)为第m个高斯的weight。
| P(x | m)为有了这个高斯之后sample出x的几率。 |
z~N(0, I)是从一个normal distribution里面sample出来的。 z是一个vector,每个dimension代表你要sample东西的某种特质。根据z你可以决定高斯的(μ, Σ)。高斯混合中有几个高斯就有几个mean和variance:
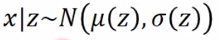
但是z是连续的,mean和variance是无穷多的,那么怎么给定一个z找到mean和variance呢?假设mean和variance都来自于一个function。那P(x)是怎样产生的呢?如下图:为方便假设z为一维,每个点都可能被sample到,只是中间可能性更大:
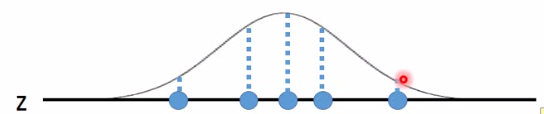
当你在z上sample出一个点后,它会对应于一个gaussian:
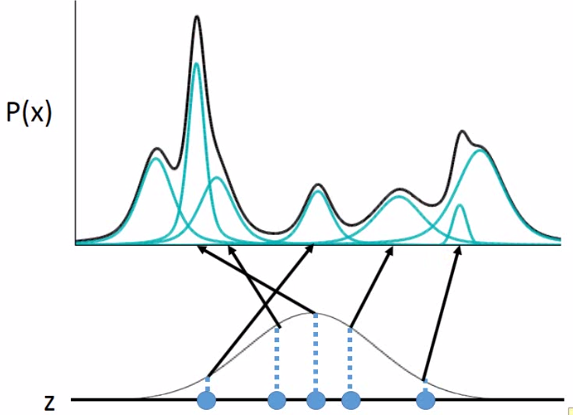
关键:至于哪个点对应到哪个gaussian呢,是由某个function所决定的。所以当你的高斯混合中的高斯是从一个normal distribution 产生的,那么就是相当于有无穷多的gaussian。一般可能高斯混合有512个高斯,那现在就可有无穷多的gaussian。那么又咋知道每个z对应到什么样的mean和variance呢?即这个function是咋样呢?我们知道NN就是一个function。这个function就是:

给定一个z输出两个vector,代表mean个variance。即这个function(NN)可以告诉我们在z上每个点对应到x的高斯混合上的mean合variance是多少。
那现在P(x)的样子就变了:
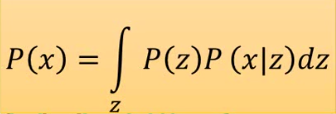
那z也不一定是gaussian,可以是任何东西。不用担心z的选择会影响P(x)的分布。因为NN的作用是很强大的。
| 所以现在问题很明朗:z为normal distribution, x | z ~N( μ(z), σ(z) ), μ(z)和 σ(z)是待去估计。那么就最大似然估计:x代表一个image:现在手上已经有的data(image),希望有一组mean和sigma的function可以让现在已有的data的P(x)取log后的和最大: |

所以就是要调整NN的参数来最大化似然函数:
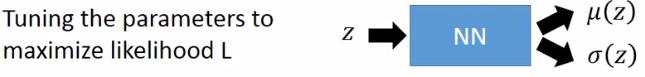
Decoder
| 然后我们需要另一个分布 q(z | x): 给定x,输出z上的分布的mean和variance: |
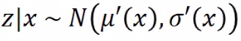
即这里也有一个function(NN),给定一个x输出z的一个mean和variance:

Encoder
公式推导:
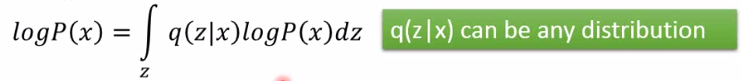
| 这里q(z | x)可以是任何一个分布,所以积分仍不变。恒等推导如下: |


| 这样就找到了一个下界称为Lb 。之前只要找P(x | z),现在还要找q(z | x)来maximizing Lb。 |
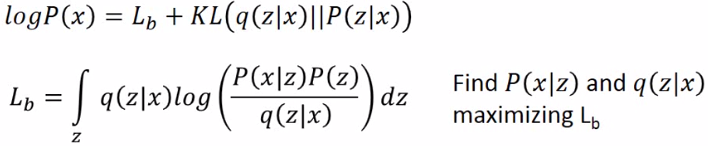
| q(z | x)和p(z | x)将会越来越相近。 |
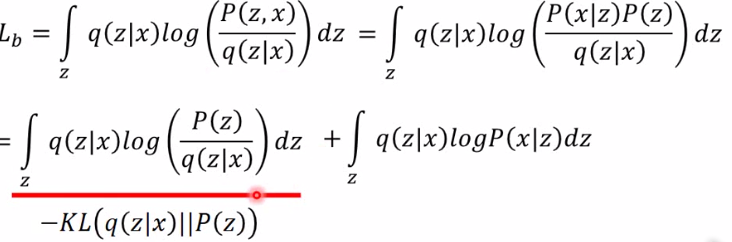
| 即最小化KL(q(z | x) | P(z)) |
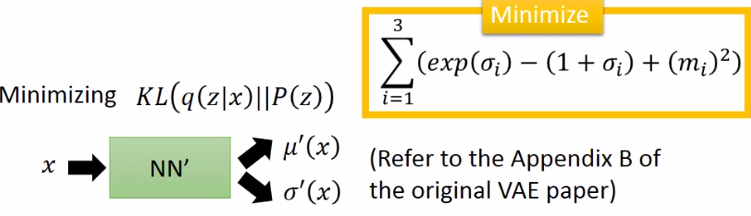
怎么最大似然呢?使得mean正好等于x:这也就是auto-encoder做的事情:

Contional GAN
论文
Learning Structured Output Representation using Deep Conditional Generative Models (neurips.cc)
主要思想

公式
\(KL(q_{\phi}(\text{z}|\text{x,y})||p_{\theta}(\text{z}|\text{x,y})) & =& \mathbb{E}_{q_{\phi}(\text{z}|\text{x,y})} \log \frac{q_{\phi}(\text{z}|\text{x,y})}{p_{\theta}(\text{z}|\text{x,y})} \\ &=& \mathbb{E}_{q_{\phi}(\text{z}|\text{x,y})} \log \frac{q_{\phi}(\text{z}|\text{x,y}) p_{\theta}(\text{x}|\text{y})}{p_{\theta}(\text{z}|\text{x,y}) p_{\theta}(\text{x}|\text{y})} \\ &=& \mathbb{E}_{q_{\phi}(\text{z}|\text{x,y})} \log \frac{q_{\phi}(\text{z}|\text{x,y}) p_{\theta}(\text{x}|\text{y})}{p_{\theta}(\text{x,z}|\text{y})} \\ &=& KL(q_{\phi}(\text{z}|\text{x,y}) || p_{\theta}(\text{x,z}|\text{y})) + \log p_{\theta}(\text{x}|\text{y}))\) 公式
\(\begin{aligned} & K L\left[q_\phi(z \mid x, y) \| p_\theta(z \mid x, y)\right] \\ &= \mathbb{E}_{q_{\phi}({z}|{x,y})} \log \frac{q_{\phi}({z}|{x,y})}{p_{\theta}({z}|{x,y})}\\ & =\int q_\phi(z \mid x, y) \log \frac{q_\phi(z \mid x, y)}{p_\theta(z \mid x, y)} d \phi \\ &=\int q_\phi(z \mid x, y) \log \frac{q_\phi(z \mid x, y) p_\theta(y \mid x) p_\theta(x)}{p_\theta(z, x, y)} d \phi \end{aligned}\) 展开 : \(\begin{aligned} & =\int q_\phi(z \mid x, y) \log _\phi(z \mid x, y) d \phi \\ &+\int q_\phi(z \mid x, y) \operatorname{logp}_\theta(y \mid x) d \phi \\ &+ \int q_\phi(z \mid x, y) \log _\theta(x) d \phi \\ & -\int q_\phi(z \mid x, y) \log _\theta(z, x, y) d \phi \end{aligned}\) 其中,第二项 : \(\int q_\phi(z \mid x, y) \log p_\theta(y \mid x) d \phi=\log _\theta(y \mid x)\) 其余三项合并,原式 \(K L\left[q_\phi(z \mid x, y)|| p_\theta(z \mid x, y)\right]=\log p_\theta(y \mid x)+\int q_\phi(z \mid x, y) \log \frac{q_\phi(z \mid x, y)}{p_\theta(y \mid x, z) p_\theta(z \mid x)} d \phi\) 由于左侧 $K L \geq 0$ ,因此: \(\begin{aligned} & \log p_\theta(y \mid x) \geq-\int q_\phi(z \mid x, y) \log \frac{q_\phi(z \mid x, y)}{p_\theta(y \mid x, z) p_\theta(z \mid x)} d \phi \\ & =\mathbb{E}_{q_\phi(z \mid x, y)}\left[\log p_\theta(y \mid x, z)+\log p_\theta(z \mid x)-q_\phi(z \mid x, y)\right] d \phi \\ & =\mathbb{E}_{q_\phi(z \mid x, y)}\left[\log _\theta(y \mid x, z)\right]-\mathbb{E}_{q_\phi(z \mid x, y)}\left[\log q_\phi(z \mid x, y)-\log p_\theta(z \mid x)\right] \\ & =\mathbb{E}_{q_\phi(z \mid x, y)}\left[\operatorname{logp}_\theta(y \mid x, z)\right]-K L\left[q_\phi(z \mid x, y)|| p_\theta(z \mid x)\right] \end{aligned}\) 左侧 $\operatorname{logp}\theta(y \mid x)$ 是基于条件 $x$ 的后验概率,右侧是条件VAE的ELBO: \(E L B O=\mathbb{E}_{q_\phi(z \mid x, y)}\left[\log _\theta(y \mid x, z)\right]-K L\left[q_\phi(z \mid x, y)|| p_\theta(z \mid x)\right]\) 第一项是对隐变量 $z \sim p\phi(z \mid x, y)$ 的期望下的极大似然估计,第二项是 $q_\phi$ 与先验的KL约束。同 样,第一项也要通过采样来估计,具体而言: \(\widetilde{\mathcal{L}}_{\mathrm{CVAE}}(\mathbf{x}, \mathbf{y} ; \theta, \phi)=-K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}, \mathbf{y}) \| p_\theta(\mathbf{z} \mid \mathbf{x})\right)+\frac{1}{L} \sum_{l=1}^L \log p_\theta\left(\mathbf{y} \mid \mathbf{x}, \mathbf{z}^{(l)}\right)\)
网络架构
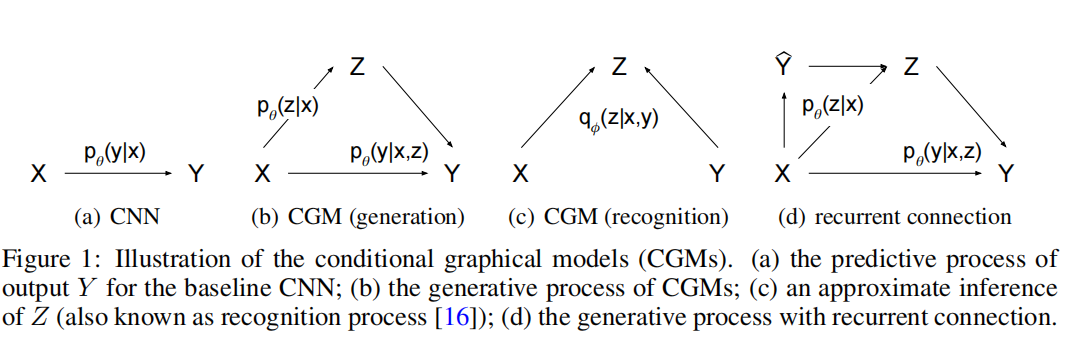
在网络结构方面,包括3个部分:
- Recognition 网络 : $q_\phi(z \mid x, y)$ ,如下图(c)
- 先验网络 $p_\theta(z \mid x)$ ,如下图(b)
- Decoder网络 : $p_\theta(y \mid x, z)$ ,如下图(b)
- 图(d)是是一种特殊的设计,将对输出的最初预测$\hat{y}$也作为条件,并在迭代中更新该条件。结果表明这种设计能够在一定程度上提升效果。
以下是一些经典的VAE改进方法,它们通过不同的思想和技术对标准VAE进行改进:
Conditional VAE (CVAE):
- 思想:
- CVAE是对标准VAE的一种扩展,它允许在生成样本时引入条件信息。这意味着你可以控制生成样本的特性,例如生成特定类别的图像。
- 改进:
- 引入了条件信息,将条件信息与输入数据一起输入到编码器和解码器中。
- 在训练过程中,损失函数不仅包括重构损失和KL散度损失,还包括条件信息的损失,以确保生成样本与给定条件一致。
- 应用:
- 在图像生成中,CVAE可以生成具有指定特征的图像,如生成特定数字的手写数字图像。
#
- 思想:
Denoising VAE (DVAE):
论文
[1511.06406] Denoising Criterion for Variational Auto-Encoding Framework (arxiv.org)
主要思想
- 思想:
- DVAE的核心思想是通过在输入数据中引入噪声来提高模型的鲁棒性和泛化能力。这种噪声有助于模型学习更健壮的数据表示。
- 改进:
- 在输入数据中添加噪声,通常是高斯噪声。
- 在损失函数中引入附加项,鼓励模型还原干净的数据而不是噪声数据。
- 应用:
- DVAE在处理包含噪声或不完整数据的情况下表现良好,如图像去噪或图像修复。
公式


训练过程

Adversarial Variational Bayes (AVB):
论文
主要思想
- Adversarial Variational Bayes (Adversarial VAE):
- 思想:
- Adversarial VAE结合了VAE和生成对抗网络(GAN)的思想。它试图通过引入GAN的判别器来提高生成样本的质量和多样性。
- 改进:
- 引入了判别器网络,它评估生成样本的真实性。
- 在损失函数中包括对抗性损失,鼓励生成样本欺骗判别器。
- 应用:
- Adversarial VAE在生成高质量和多样性的图像方面表现出色,尤其在生成逼真的人脸图像方面。
- 思想:
公式
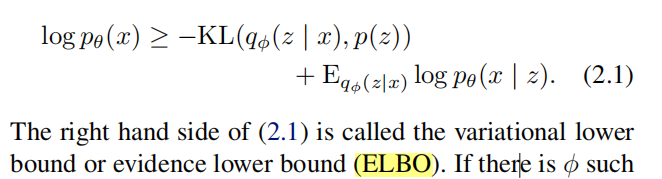
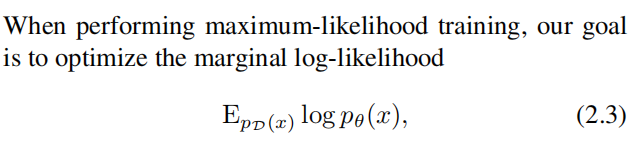


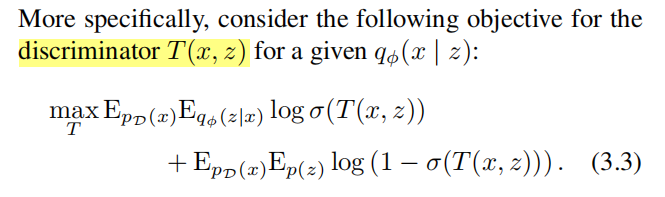
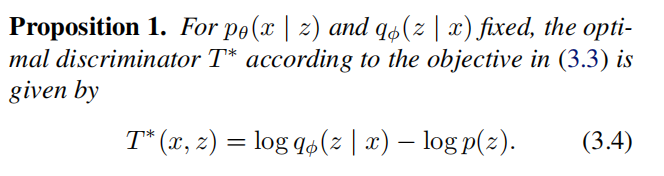


算法

1Adversarial Autoencoders (AAE):
论文
[1511.05644] Adversarial Autoencoders (arxiv.org)
主要思想
Adversarial Autoencoders (AAE):
- 思想:
- AAE将自动编码器与生成对抗网络相结合,以生成更逼真的潜在表示,并且不依赖于KL散度。
- 改进:
- 引入判别器网络,它评估潜在表示的真实性。
- 通过对抗性训练,鼓励潜在表示更接近标准正态分布。
- 应用:
- AAE用于学习更具信息量的潜在表示,适用于生成图像和特征学习任务。
这些改进方法扩展了标准的VAE模型,使其更适应不同类型的数据和应用场景。它们的思想和技术可以根据具体问题的需求来选择,以提高生成模型的性能和效果。这些方法代表了深度生成模型领域的一些最新进展,为生成模型的研究提供了丰富的思路和方向。
GAN说白了就是对抗,VAE就是一种Autoencoders,而本文的AAE就是将对抗的思想融入到Autoencoders中来。如下图所示:
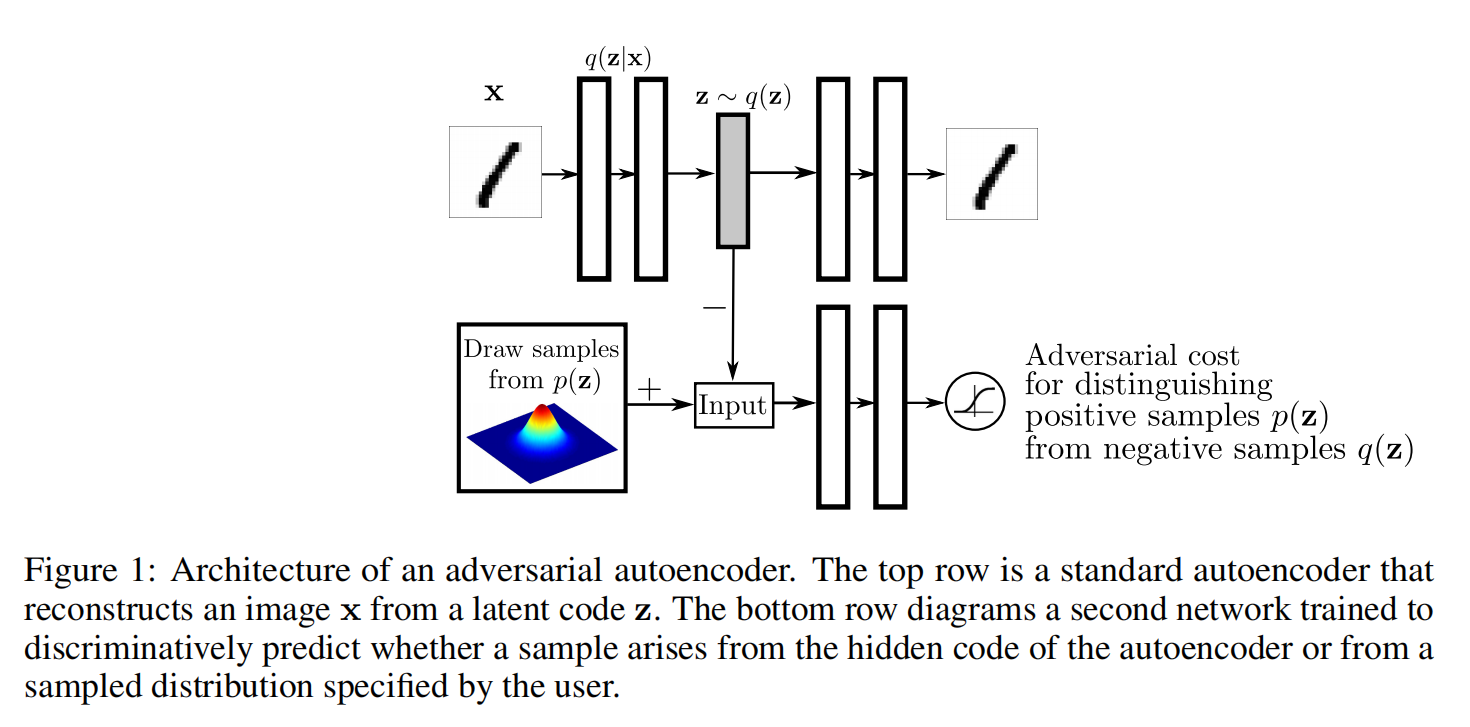
这个图大概的意思是:上半部分就是AE,我们都知道AE需要把一个真实分布映射成隐层的z,AAE就是在z这里动手脚,(如图下半部分所示)在此加上对抗思想来优化这个z。
上图中可以明确地看出,这个模型不像原来的GAN一样生成出一些样本,然后和真实数据比较,梯度反向传播从而渐渐优化模型;这个模型操作的是隐层的z,通过调整z来达到得到想要的生成的效果。真实样本可以是不连续的(普通GAN无法训练优化),但是z却是连续的,我们可以做到通过微调z来生成更加真实的样本。也就是说AAE完美避开了GAN无法生成离散样本的问题。
过图可以看出这是一个AE框架,包括encoder、中间编码层和decoder。我们让中间编码层的q(z)去匹配一个p(z),怎么做到呢?此时对抗思想就出场了,见下图:
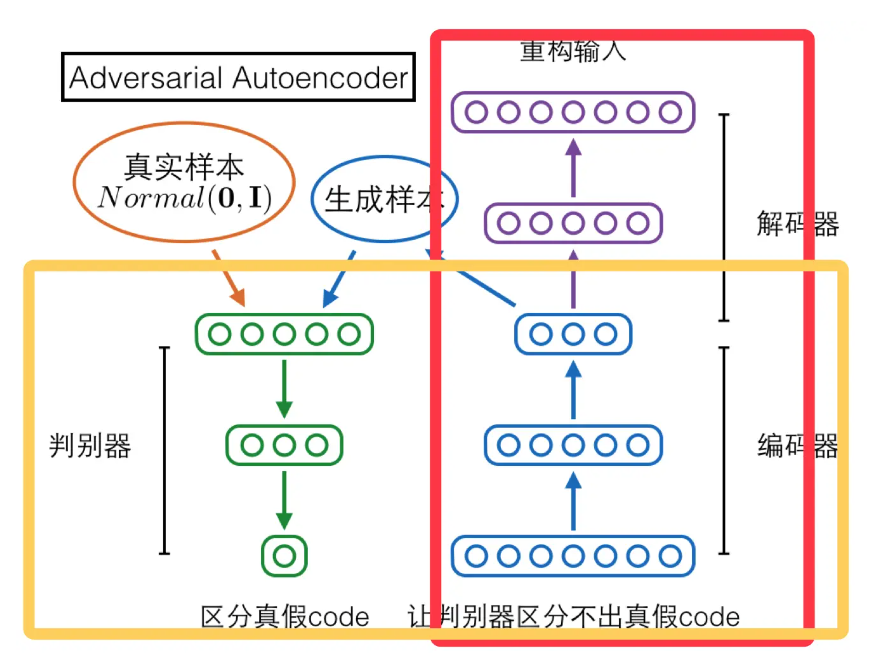
红框中与“AE简易说明图”中的内容类似,就是一个AE,对抗思想的引入在于黄框中的内容,AE的encoder部分,作为GAN中的generator,生成样本,也就是编码层中的编码,与黄框左边部分的真实样本,一个符合p(z)分布的样本混在一起让discriminator进行辨别,从而使discriminator与作为generator的encoder部分不断优化,并且在对抗的同时,AE也在最小化reconstruction error,最终可以生成更好的样本。
| 文中列出了三种q(z | x)的选择,包括确定性函数,高斯后验和通用近似后验,其中使用确定性函数,它的q(z)只是和真实数据分布有关,其他两种的q(z)除了与真实分布有关,还与这两种方式中的某些随机性有关。不同的选择在训练过程中会有细微的差别,但是文中提到,他们使用不同的方式会得到类似的结果。 |
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2023/09/11/Geneerative-AI-02-VAE/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)