Diffusion Model
Difusion Model
| [Understanding Diffusion Probabilistic Models (DPMs) | by Joseph Rocca | Towards Data Science](https://towardsdatascience.com/understanding-diffusion-probabilistic-models-dpms-1940329d6048) |
文字生成图片 模型框架
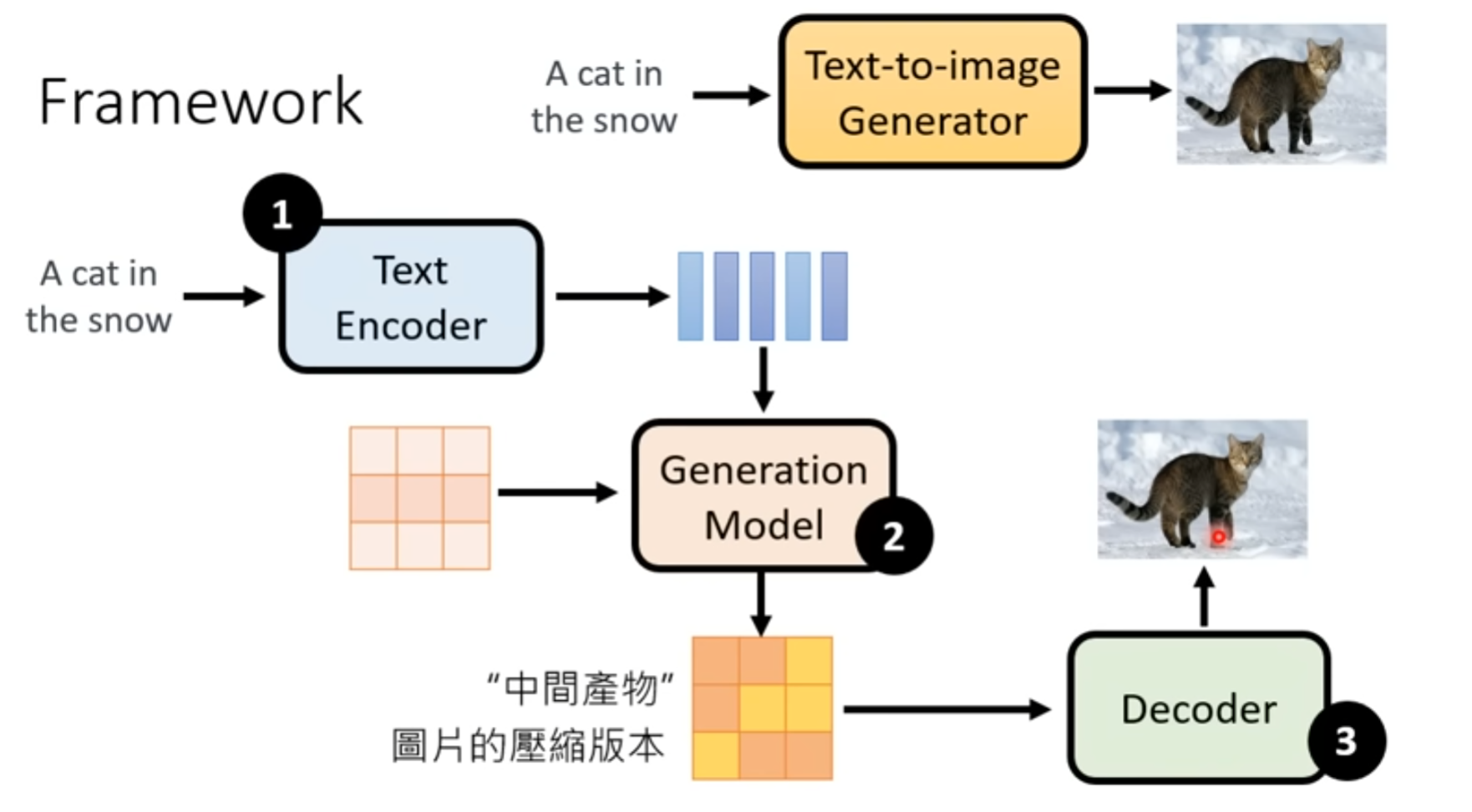
例子
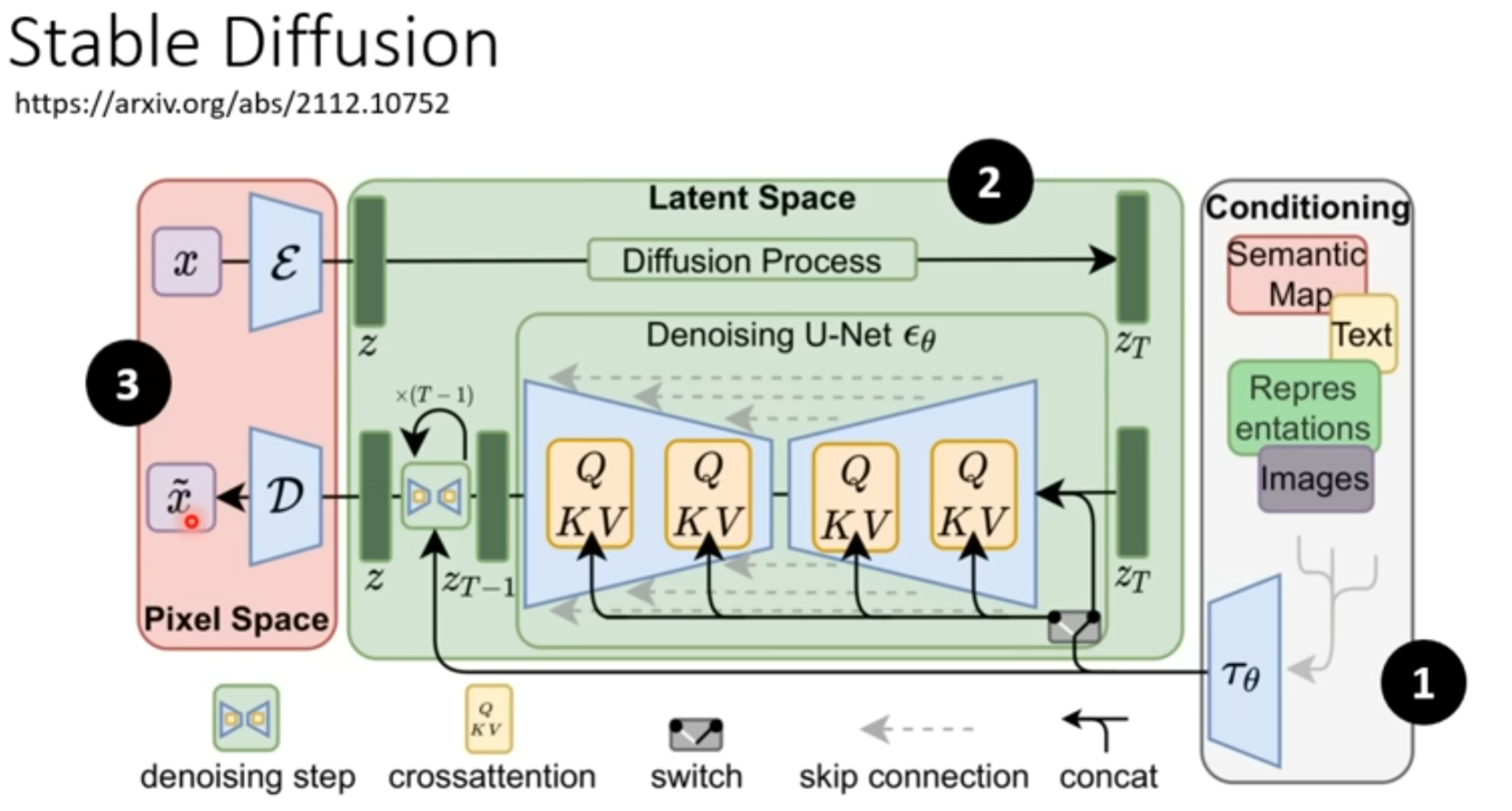
例子1 Stable Diffusion
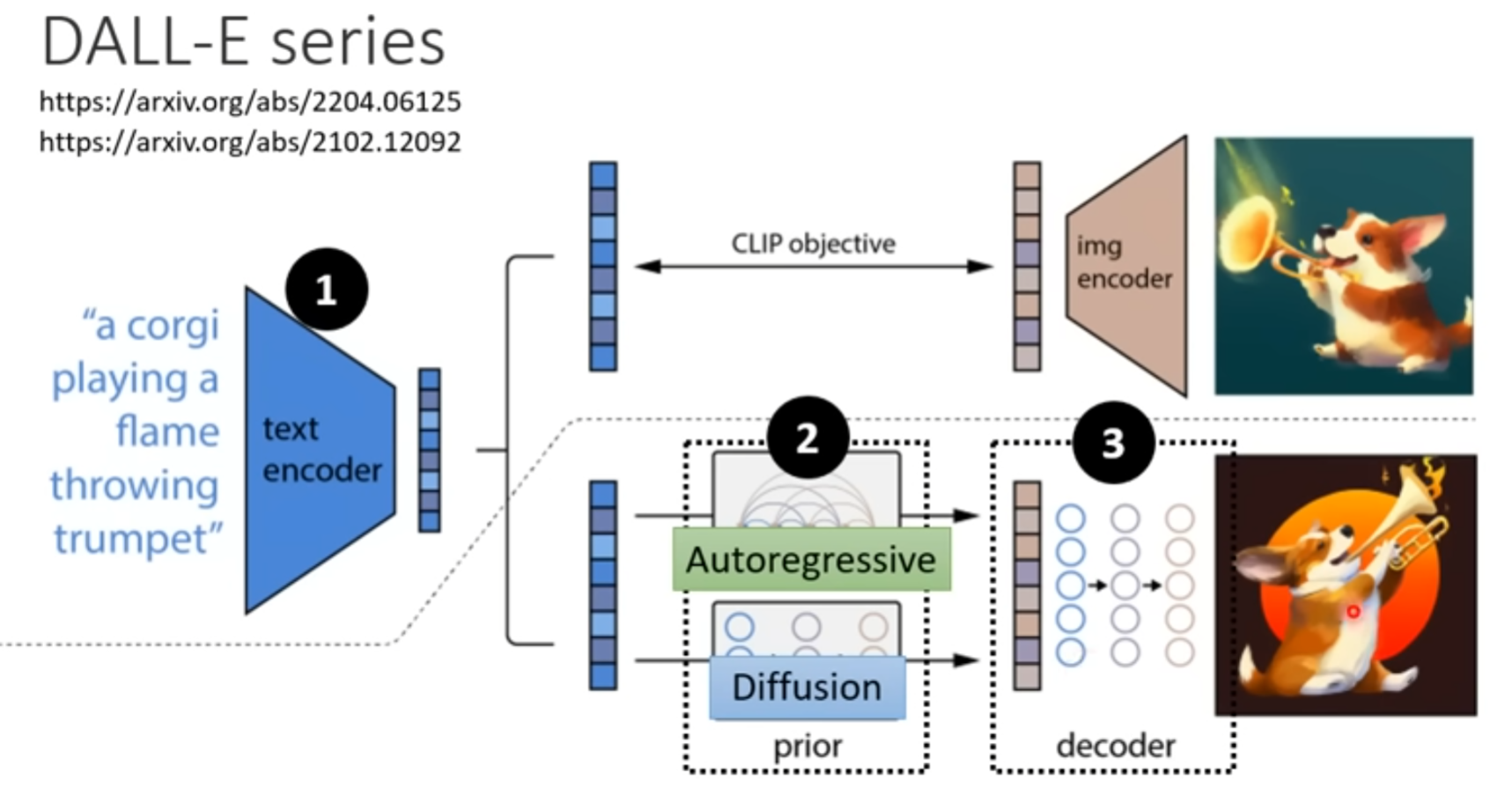
例子2 DALL-E series
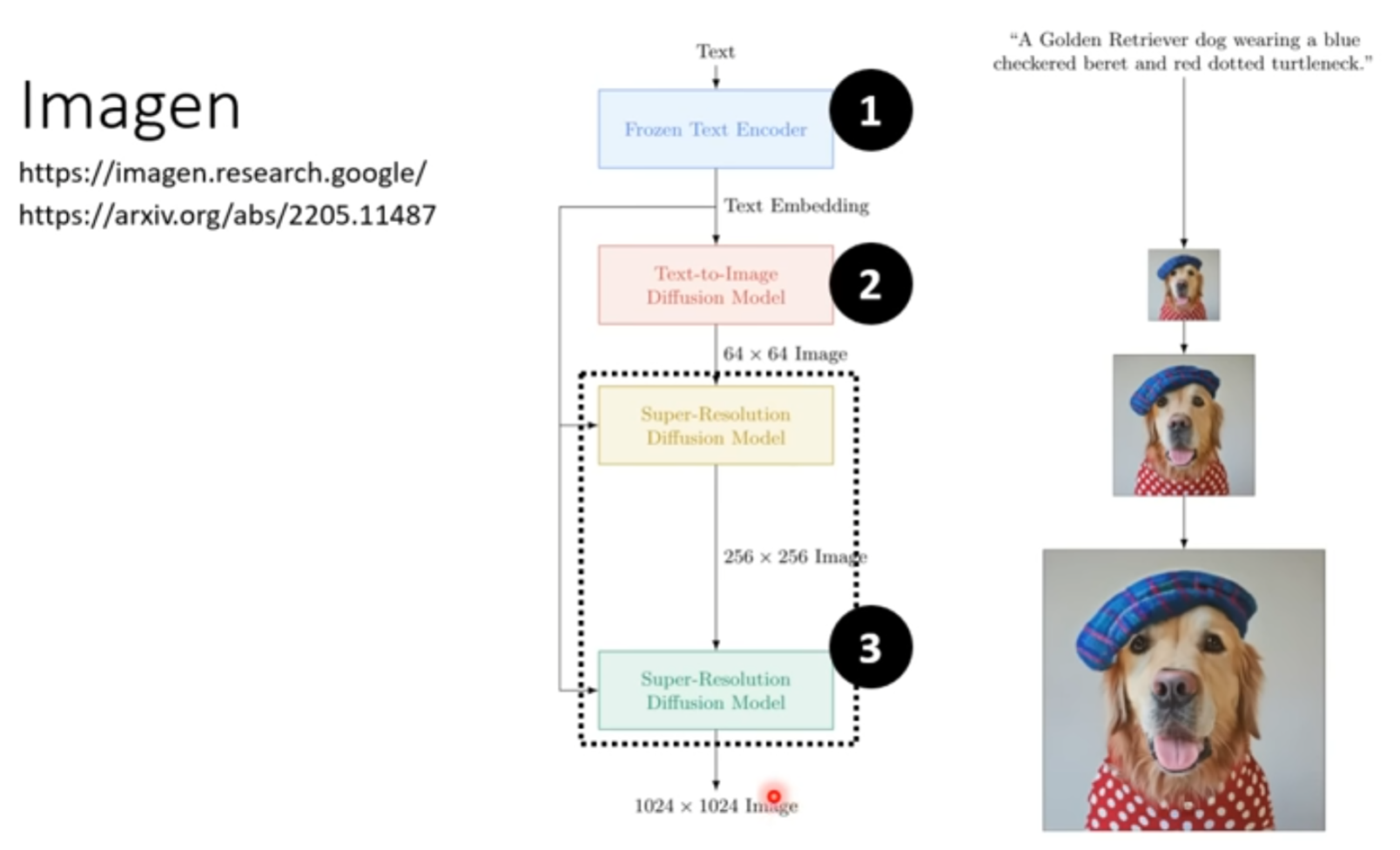
例子3 Imagen
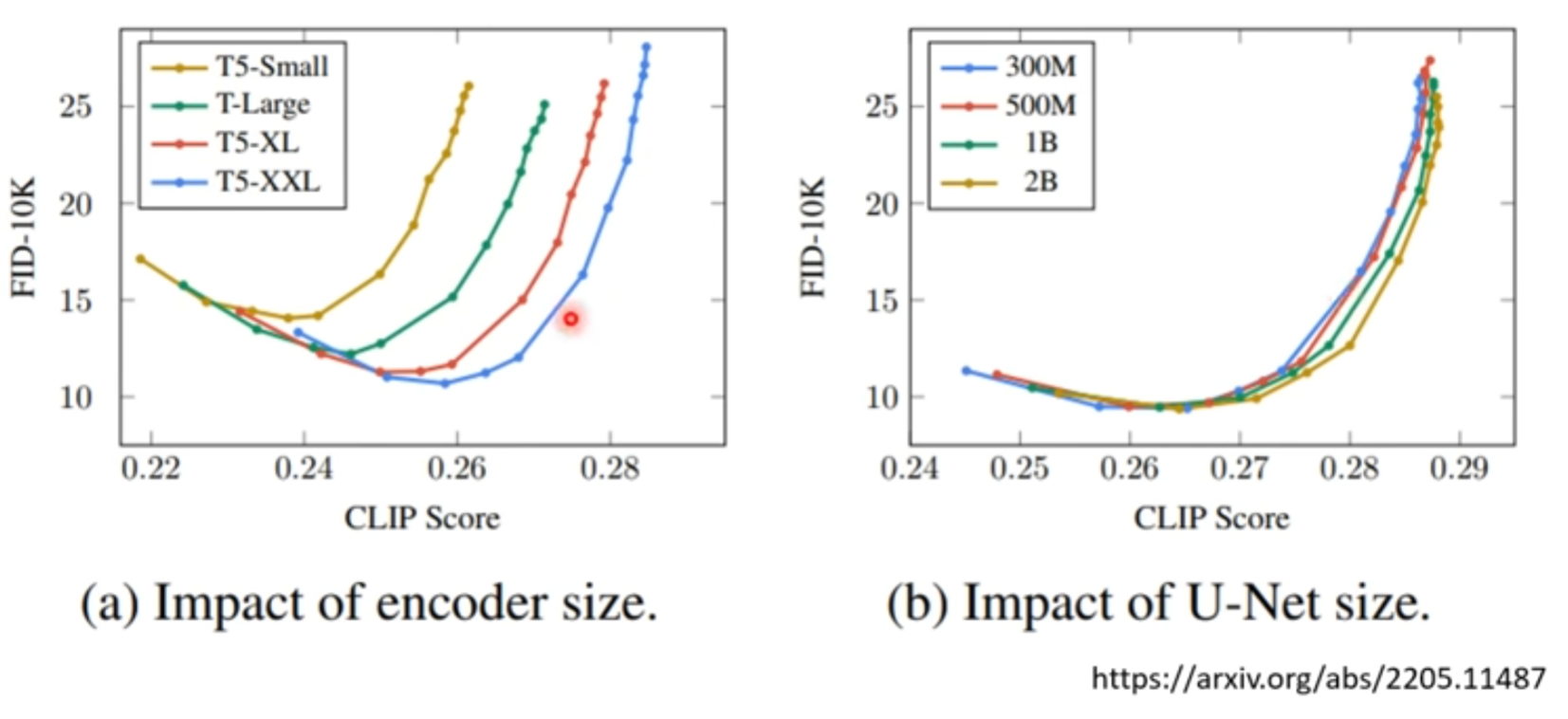
1 文字的 encoder
对结果影响很大
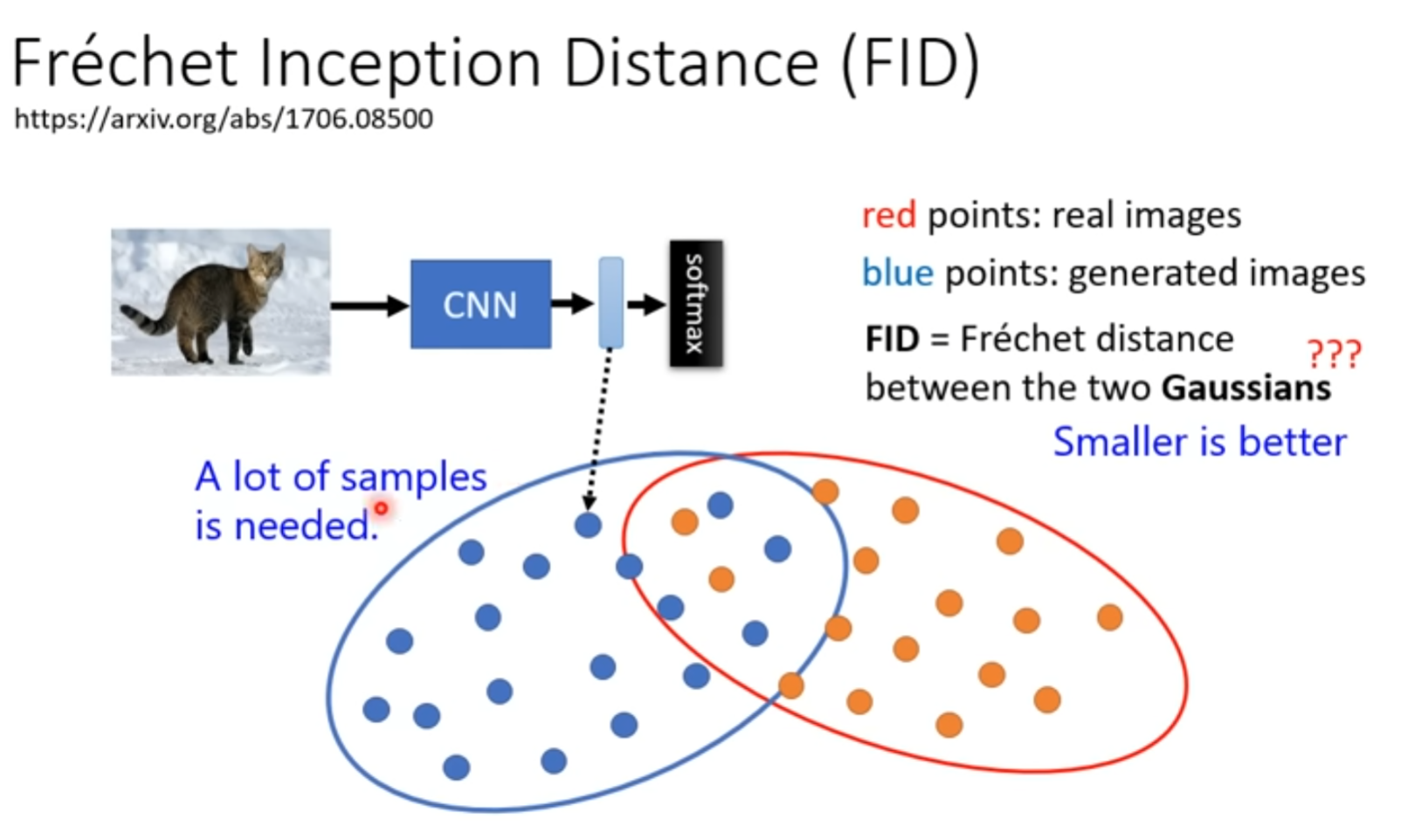
FID 衡量图像生成效果
有一个图片分配的model,
然后 生成图片和真实图片的距离
假设两组都是 高斯分布 ,然后计算 Frechet distance
距离越小越好
问题,需要大量的结果才能衡量FID
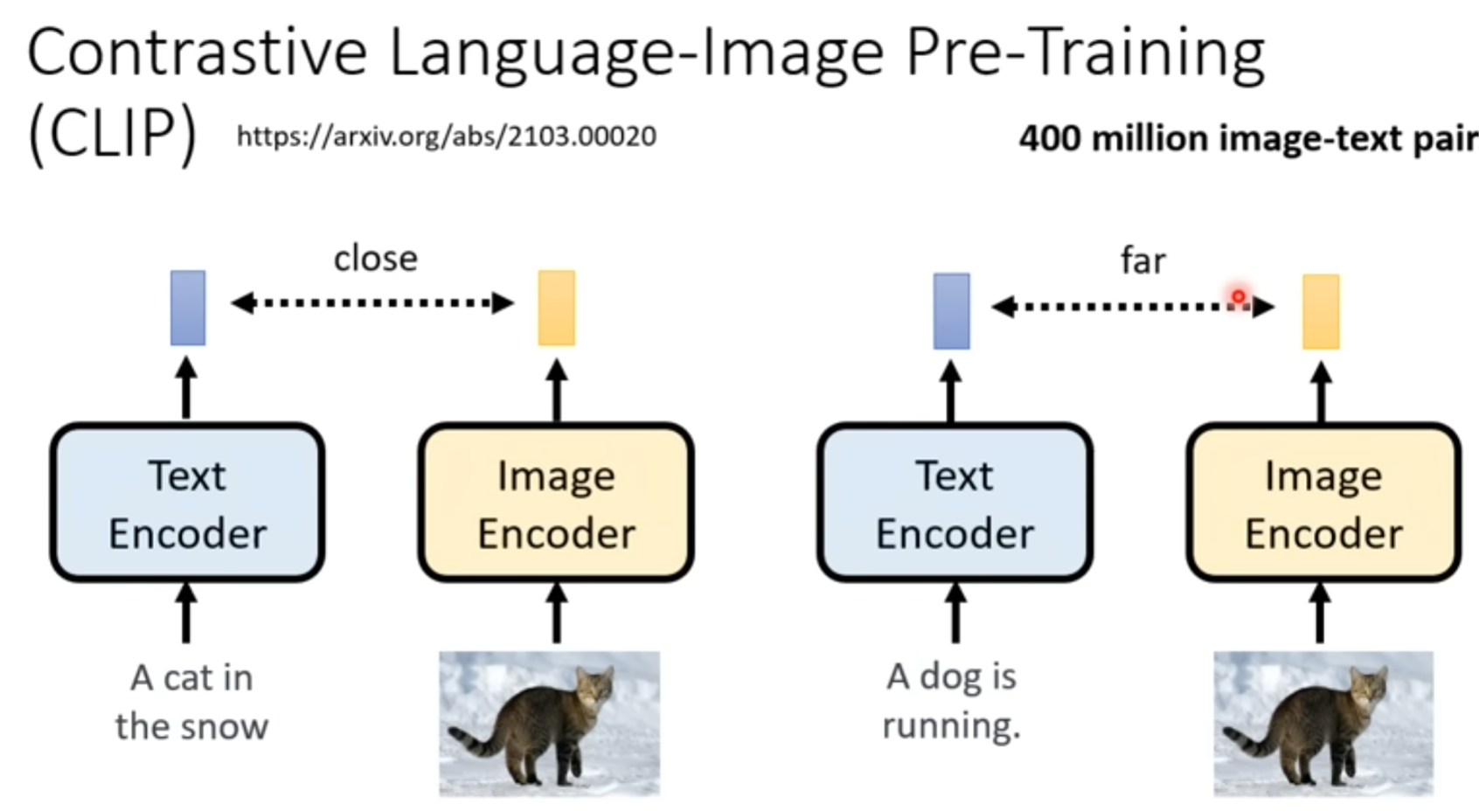
CLIP 4
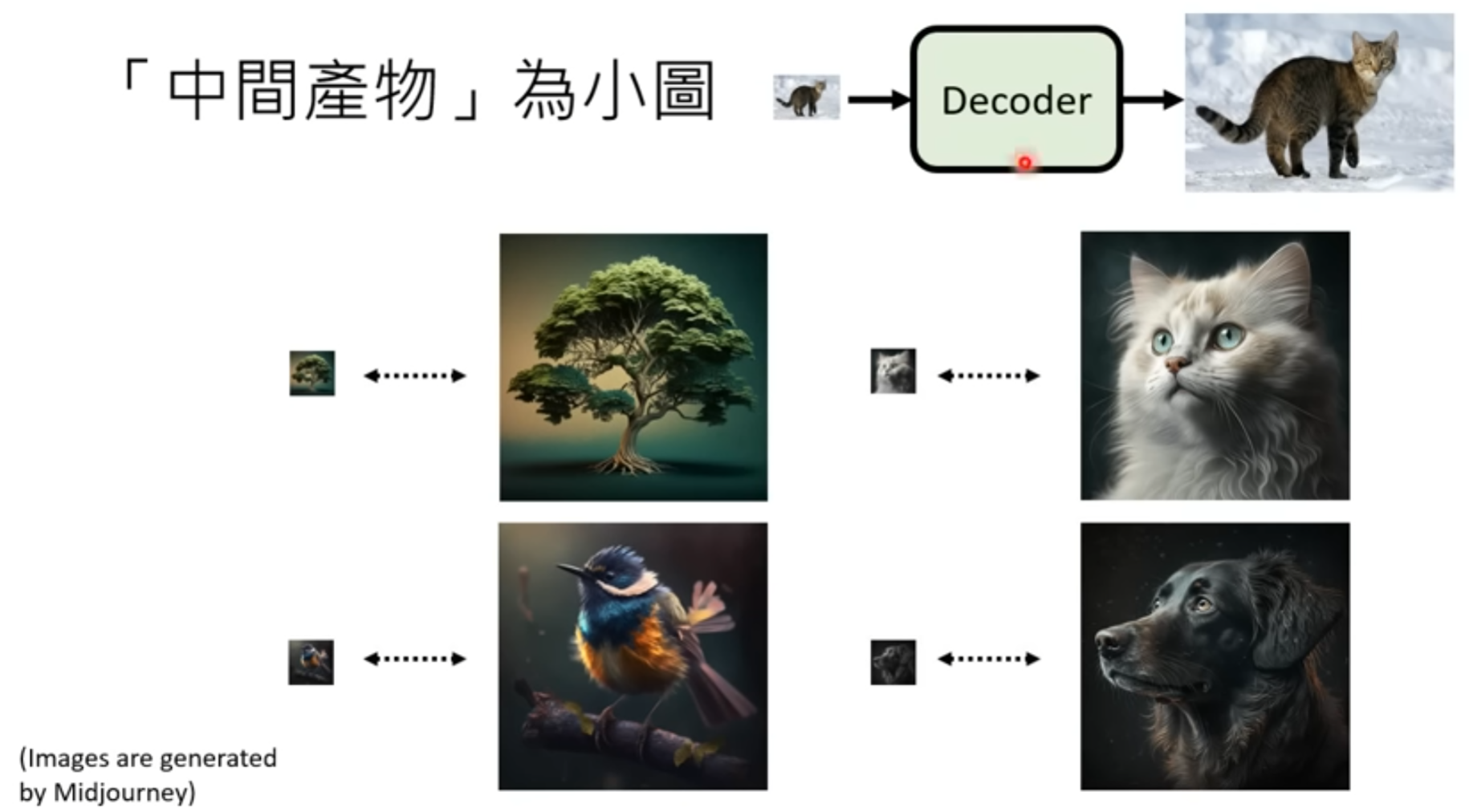
2 decoder
1 如果中间产物是小图,decoder将小图变成大图
2 如果中间是latent Representation,那就训练一个auto encoder
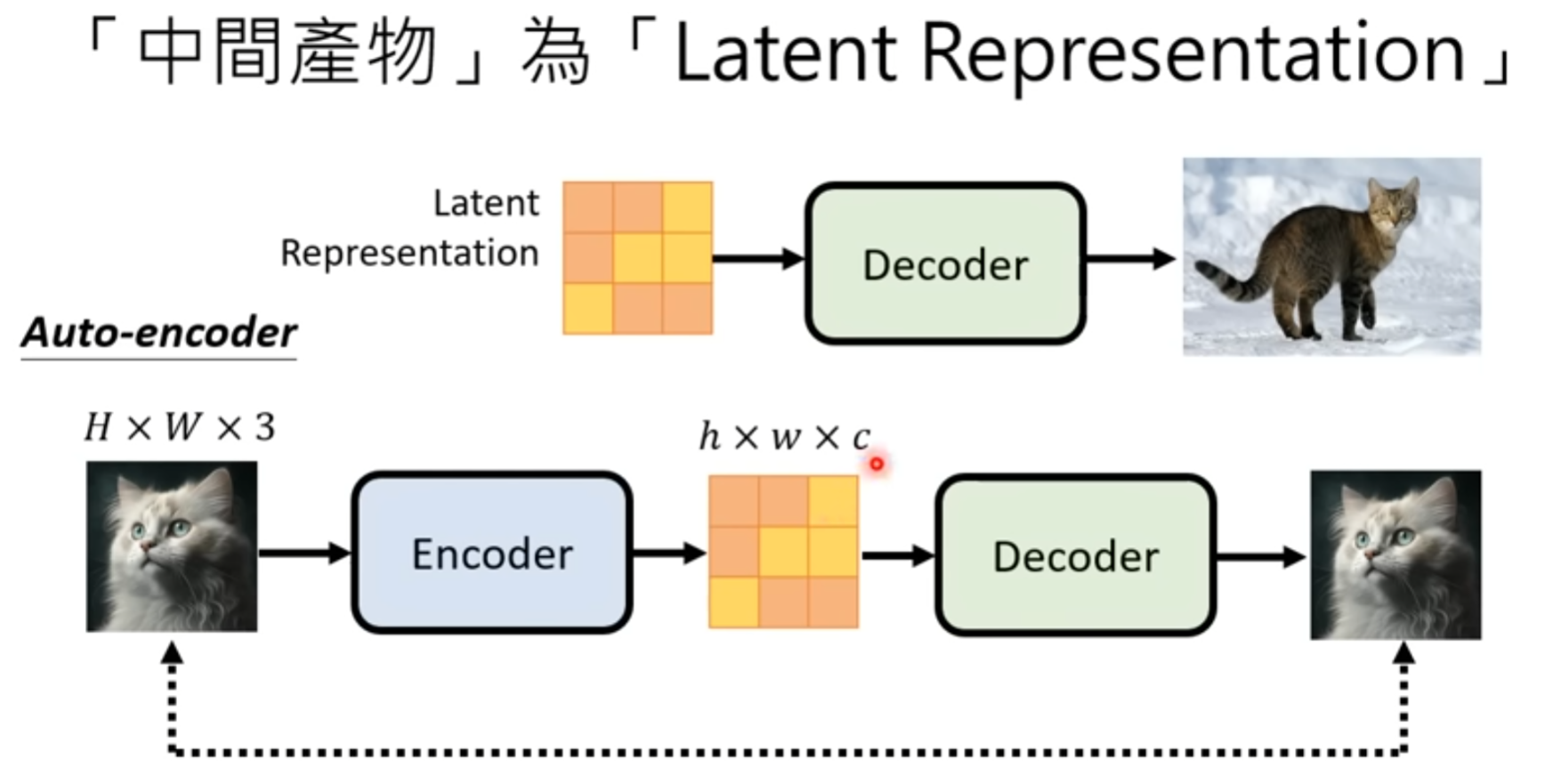
3 Generation model
VAE vs Diffusion Model
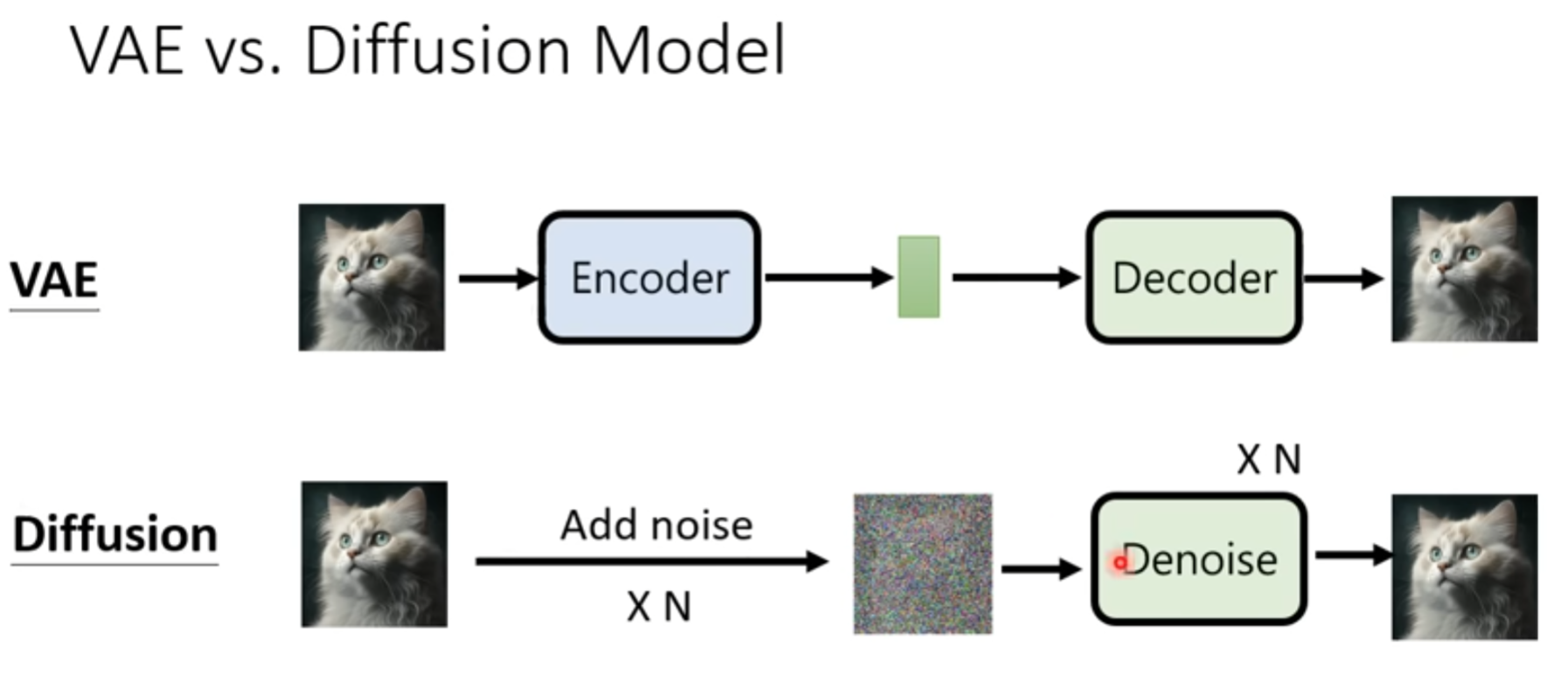
算法
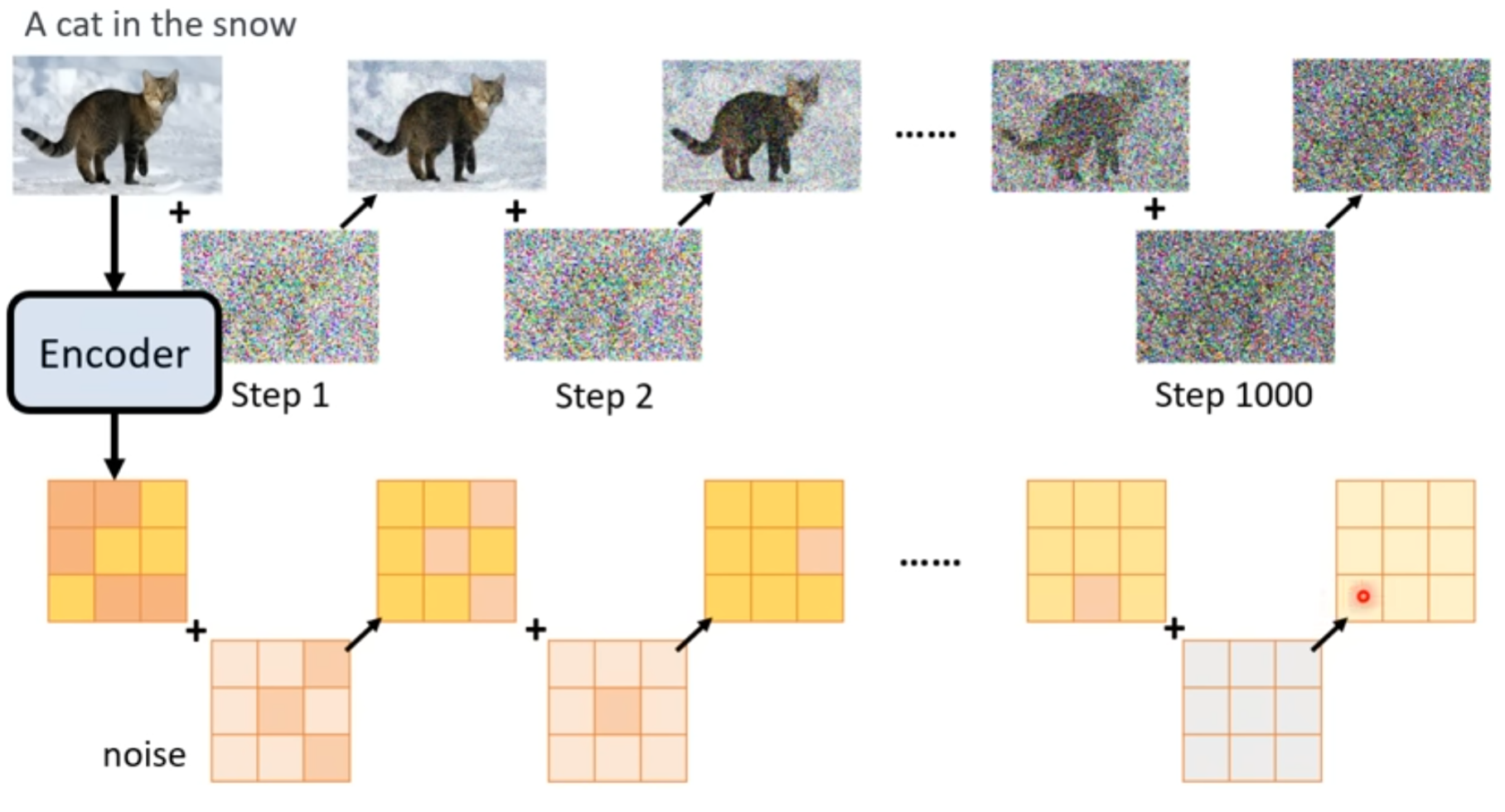
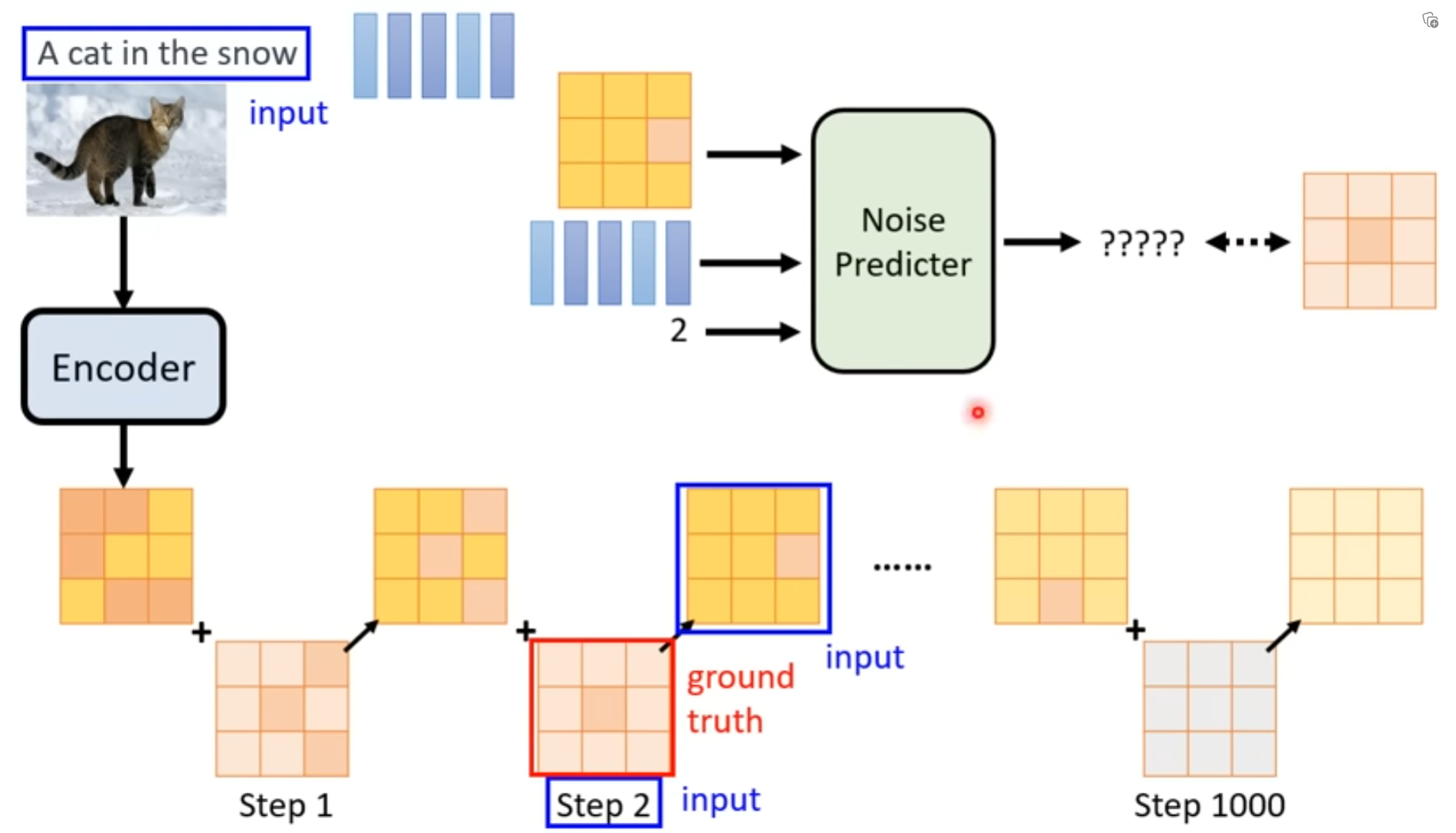
1 Training

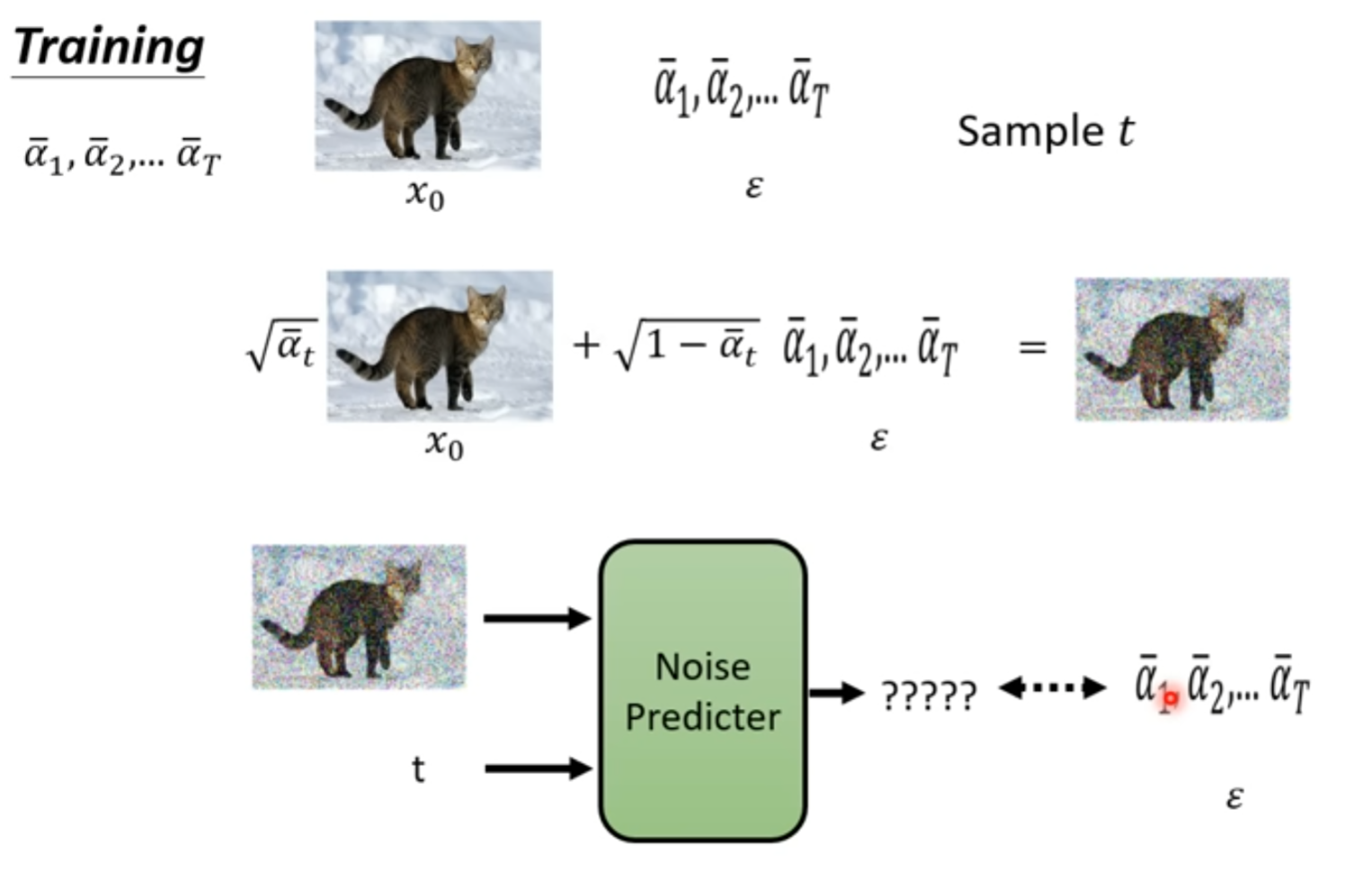
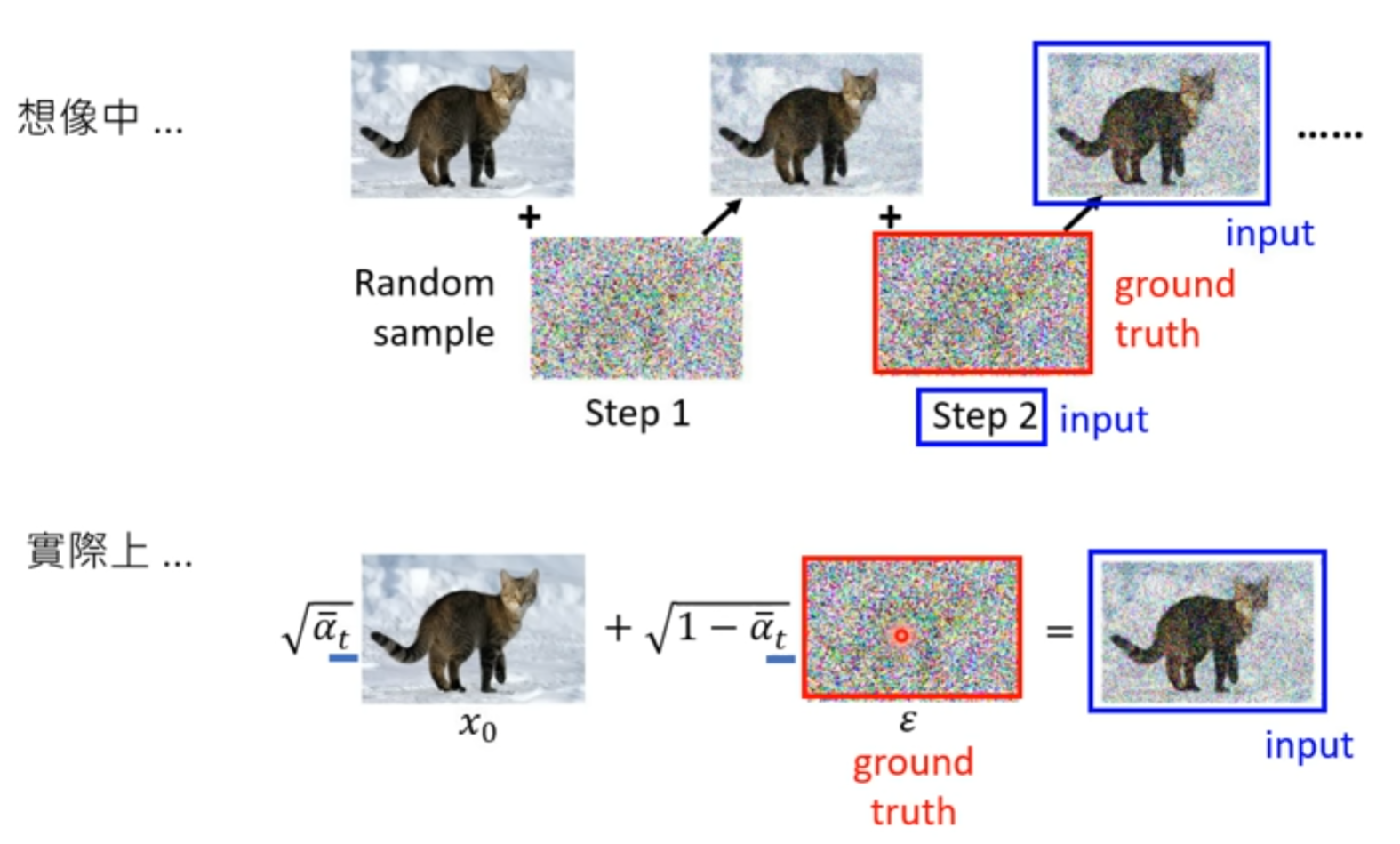
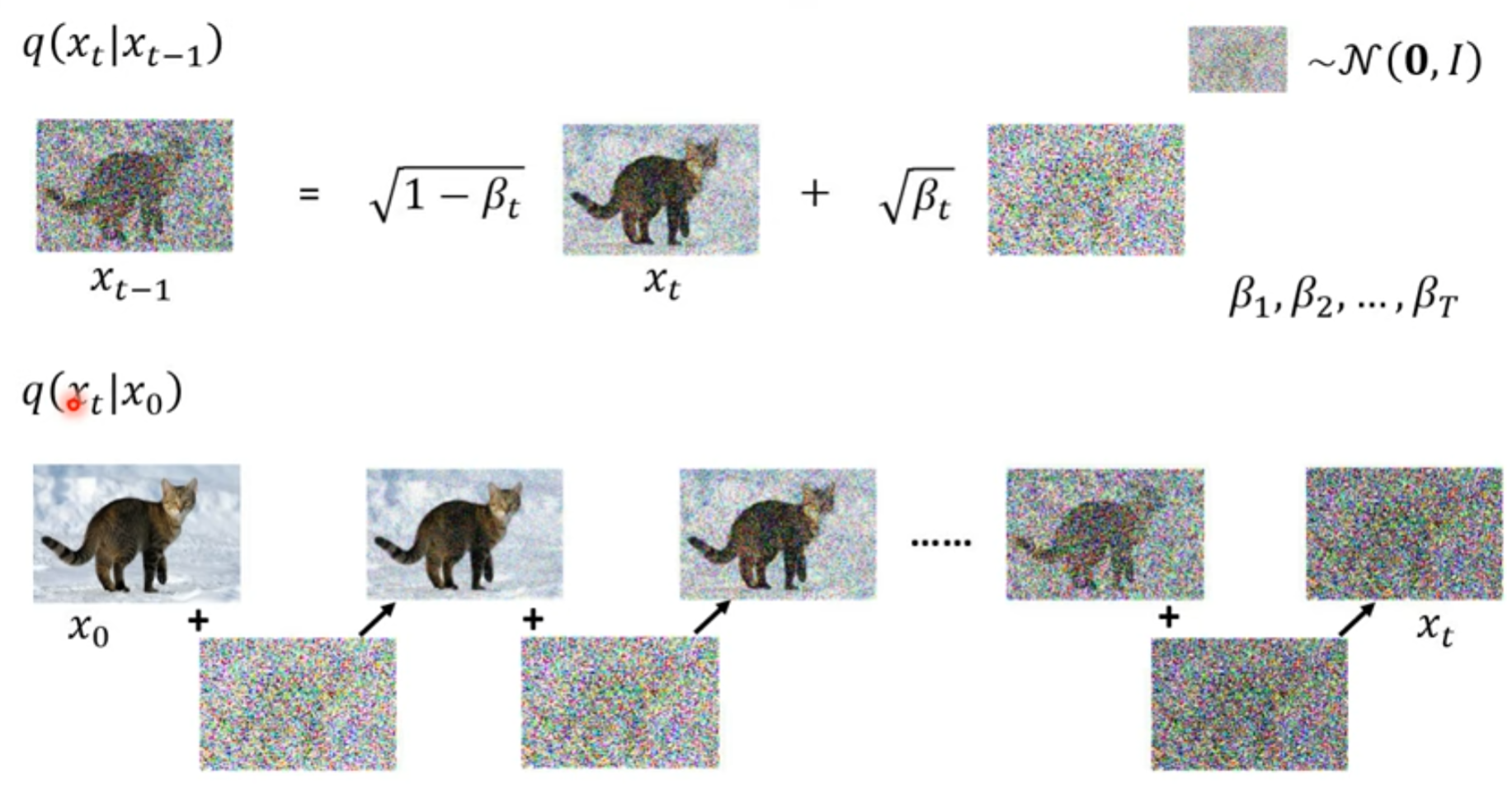
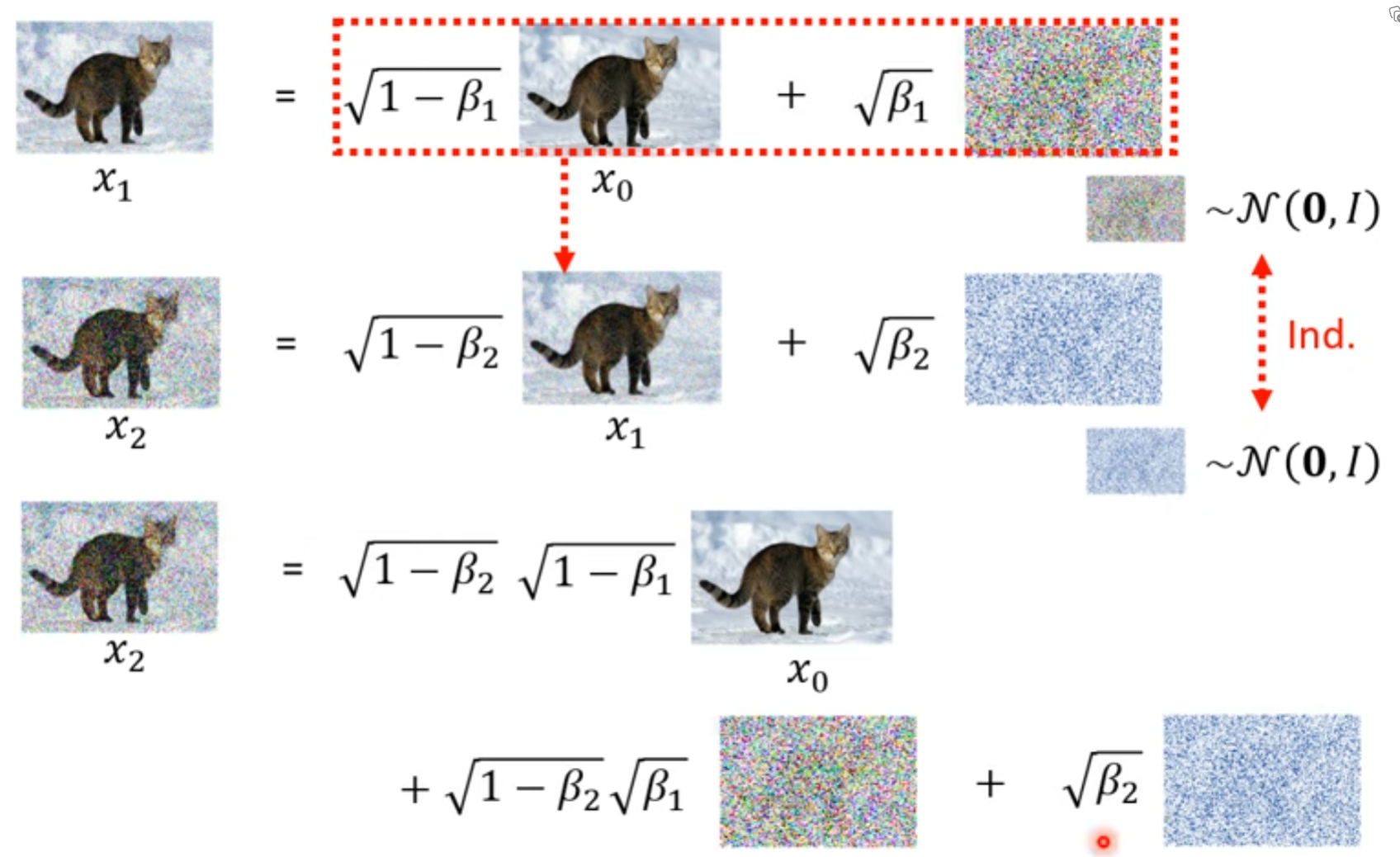
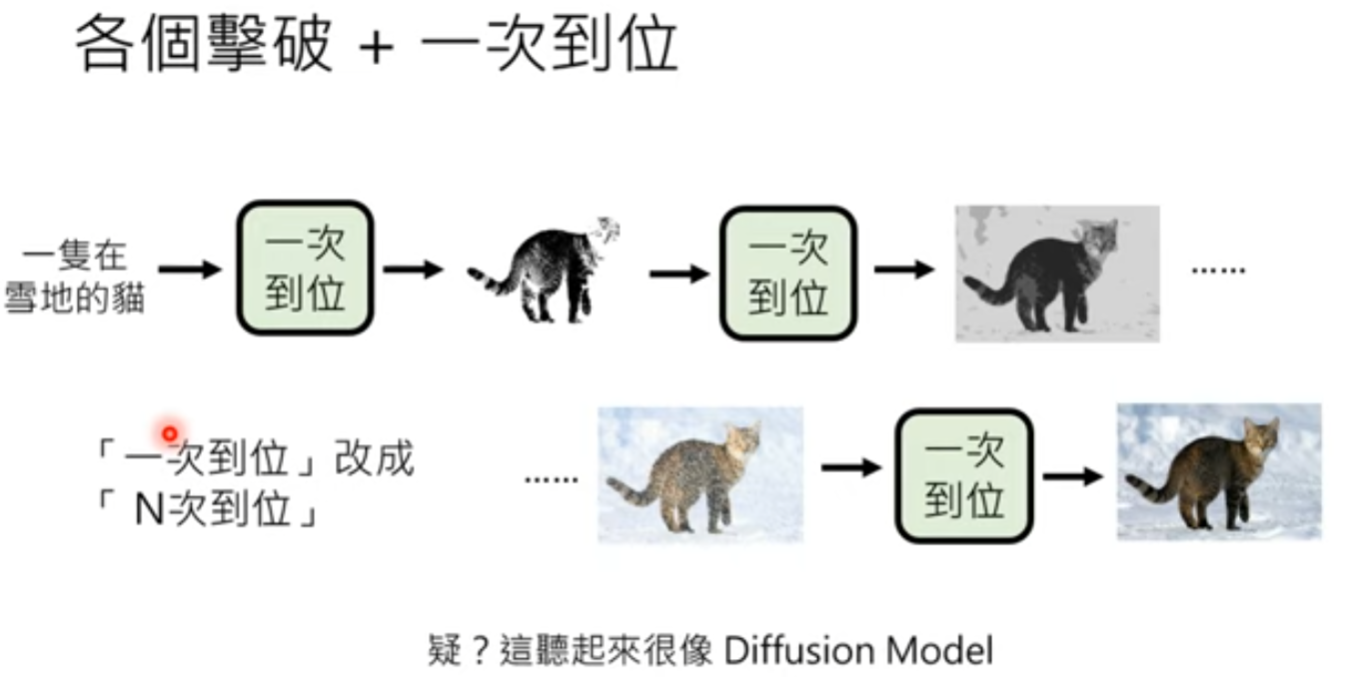
加入噪声的时候,并不是我们想象中的一步步产生结果
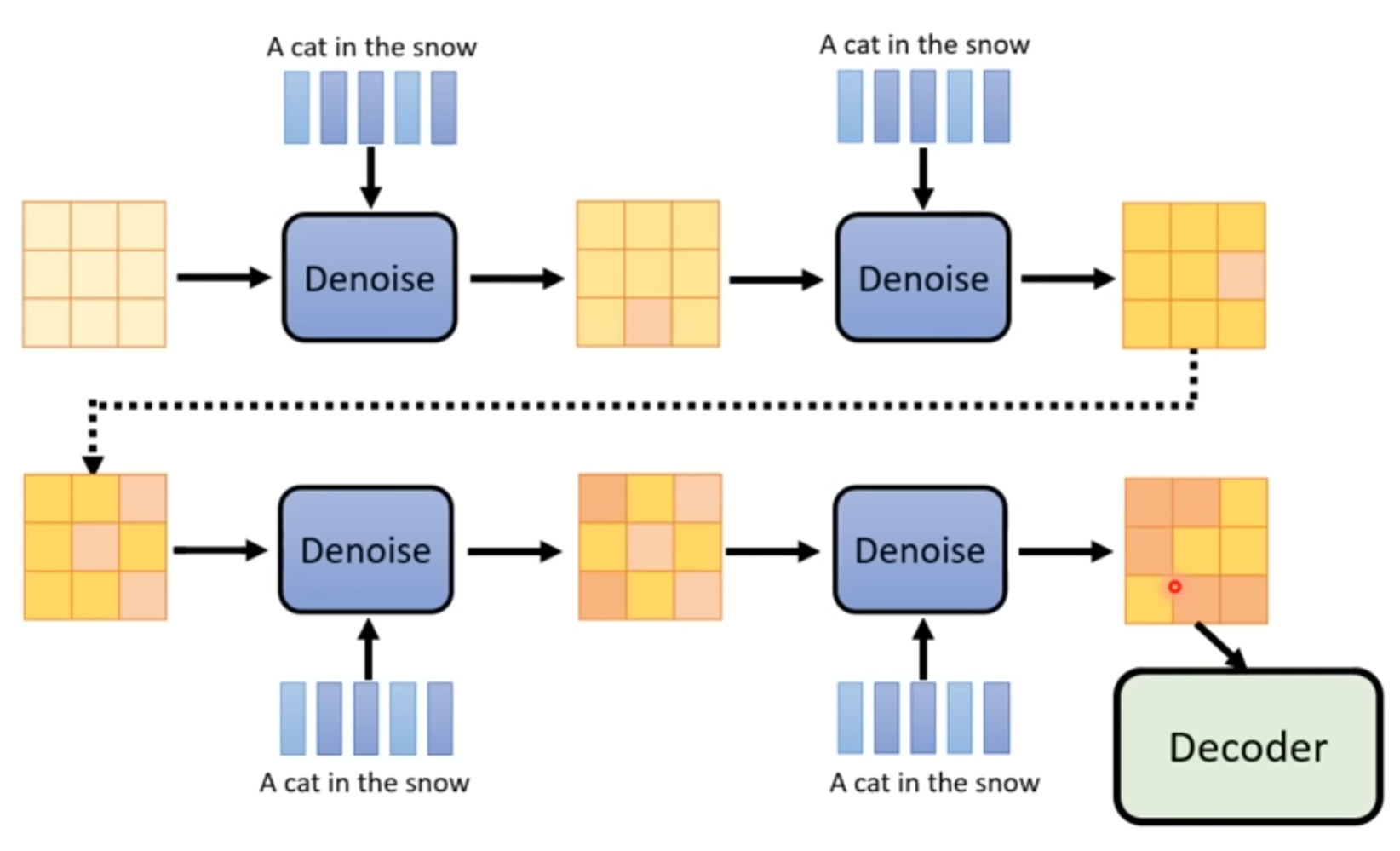
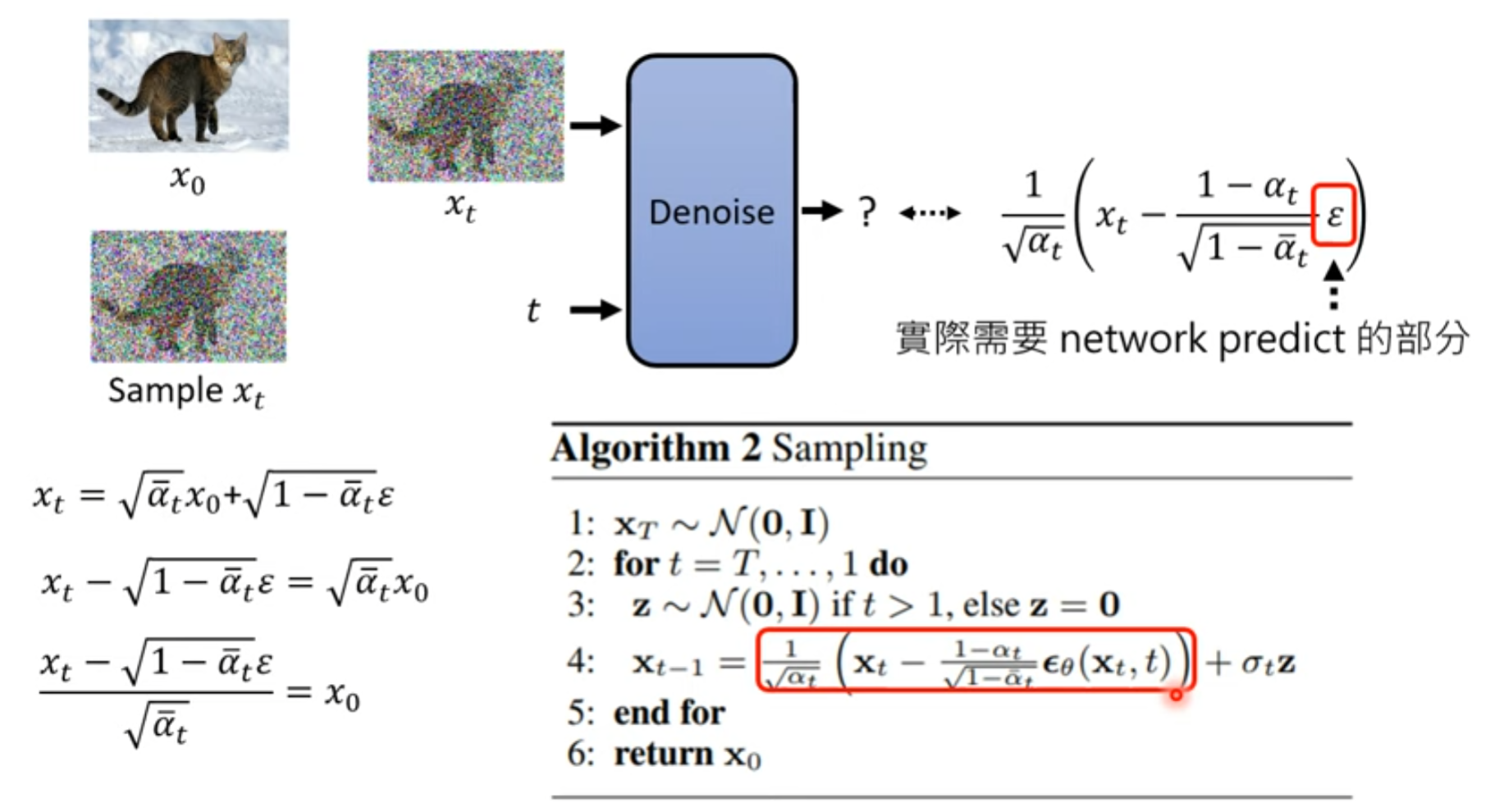
2 Sampling
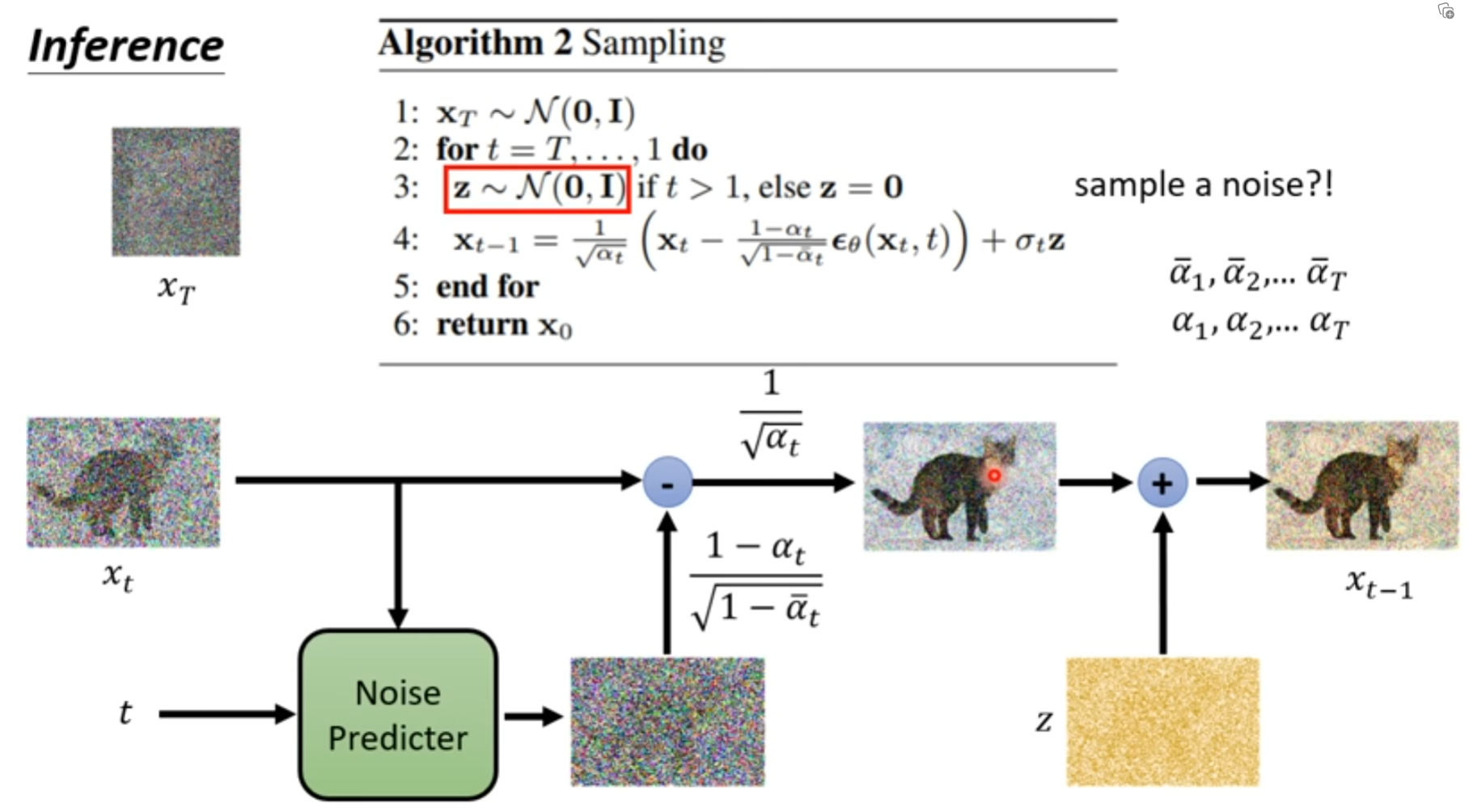
数学推导
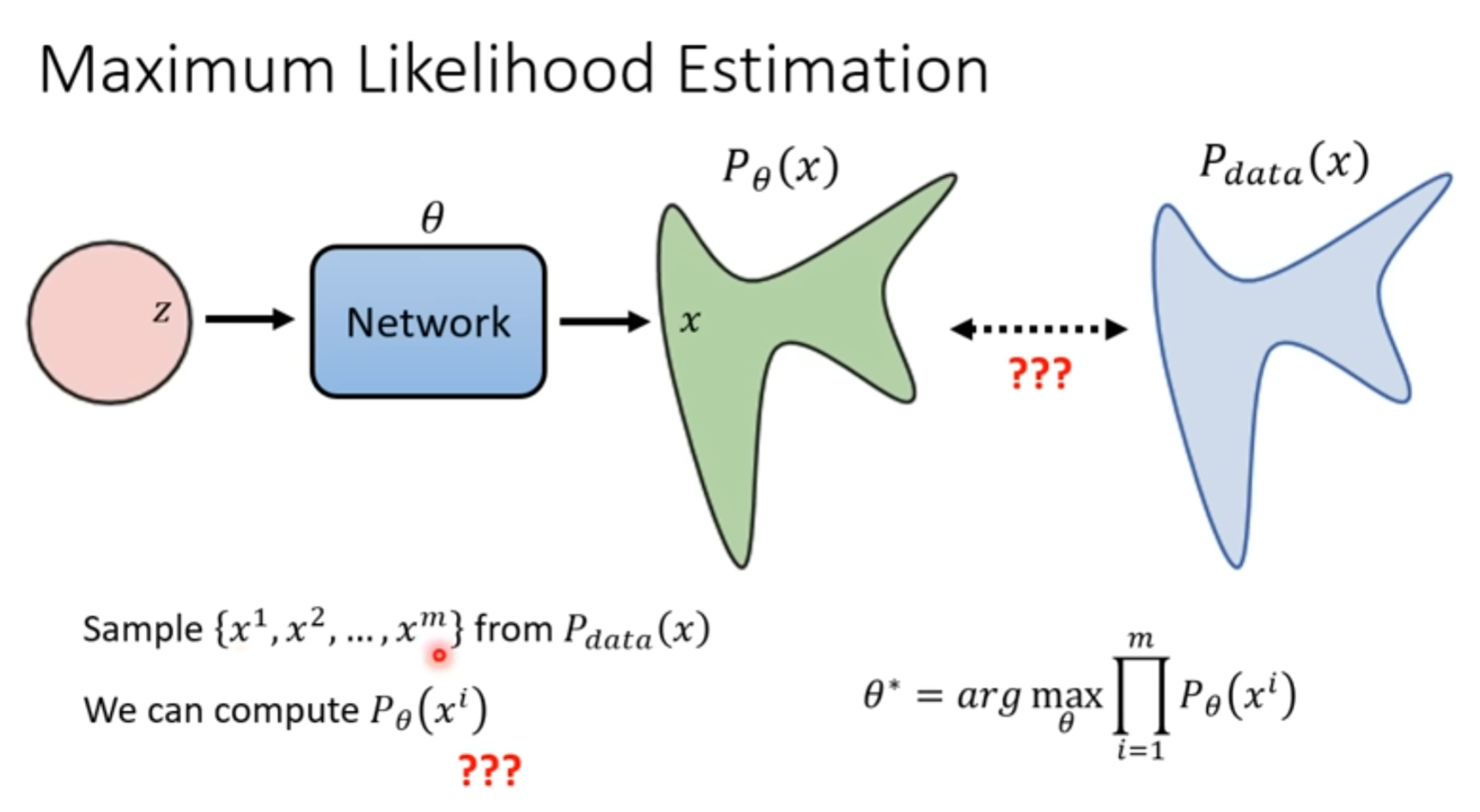
目标
找到一个$\theta$ ,让sample的样本在生成得到的概率分布$P_\theta$中越大越好,(这其实等价于让分布$P_\theta$和$P_{data}$越接近越好)

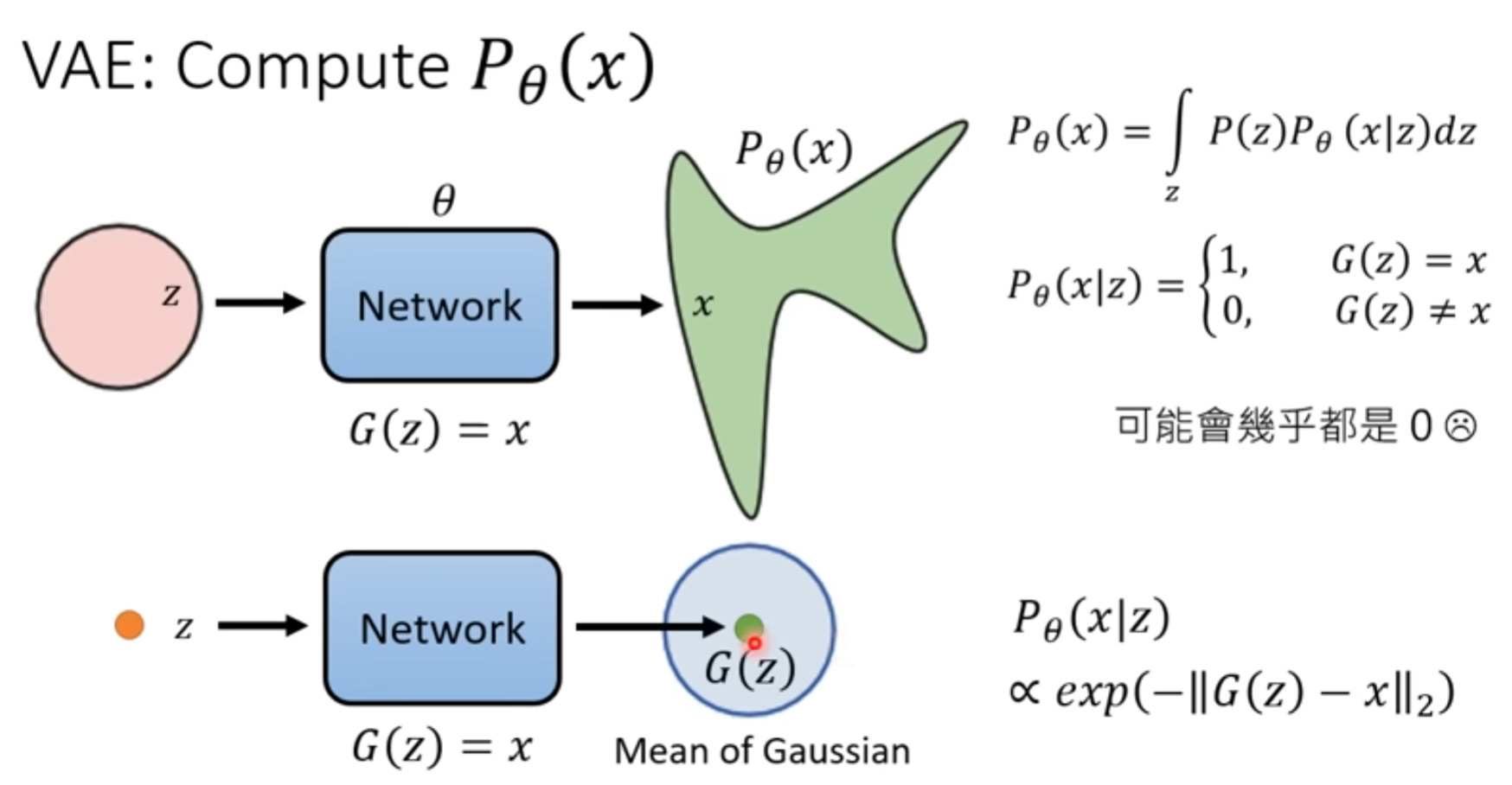
VAE
认定生成的分布是一个 高斯分布
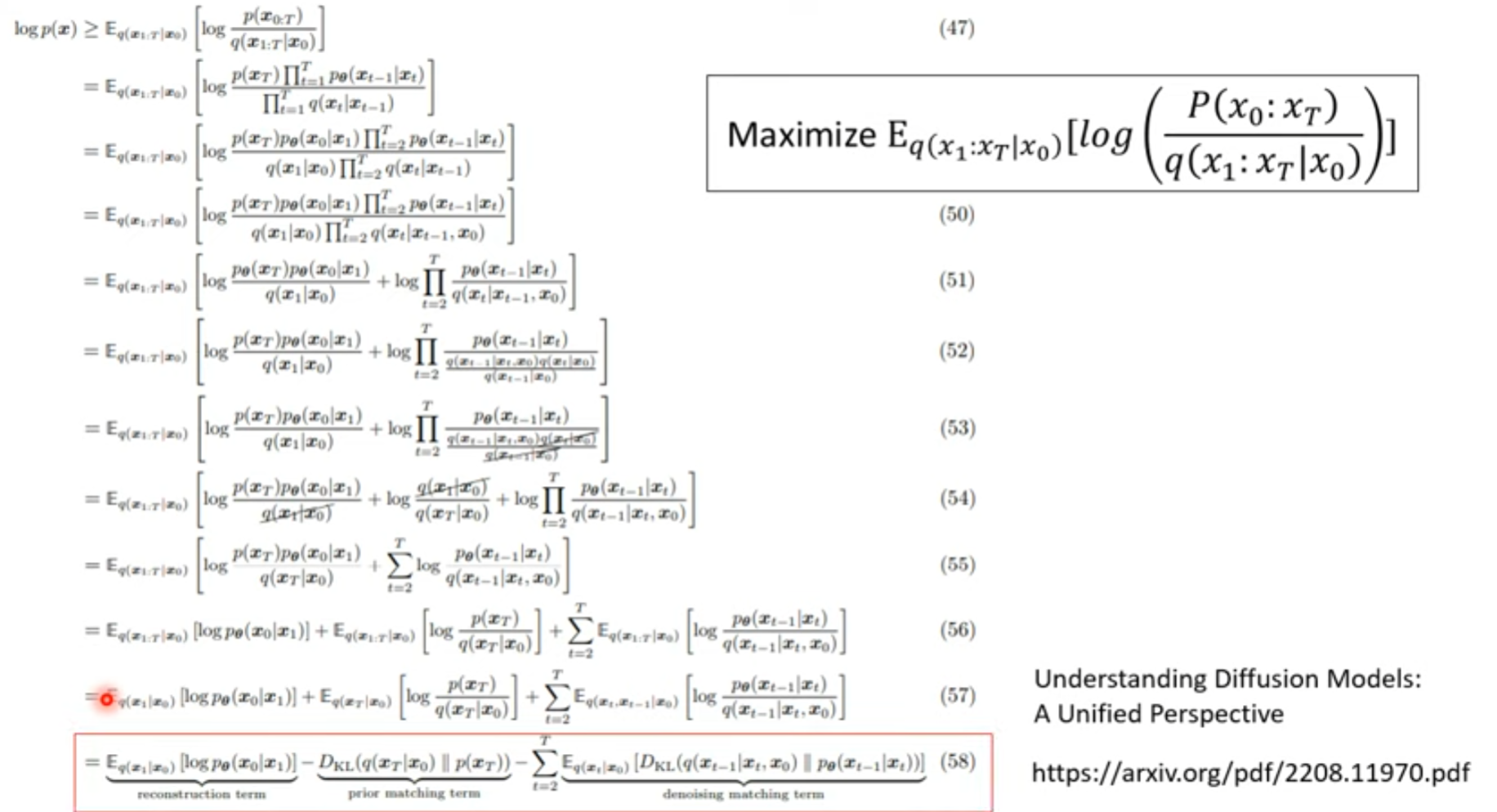
VAE 下界

DDPM
把这个结果也想象成 高斯分布
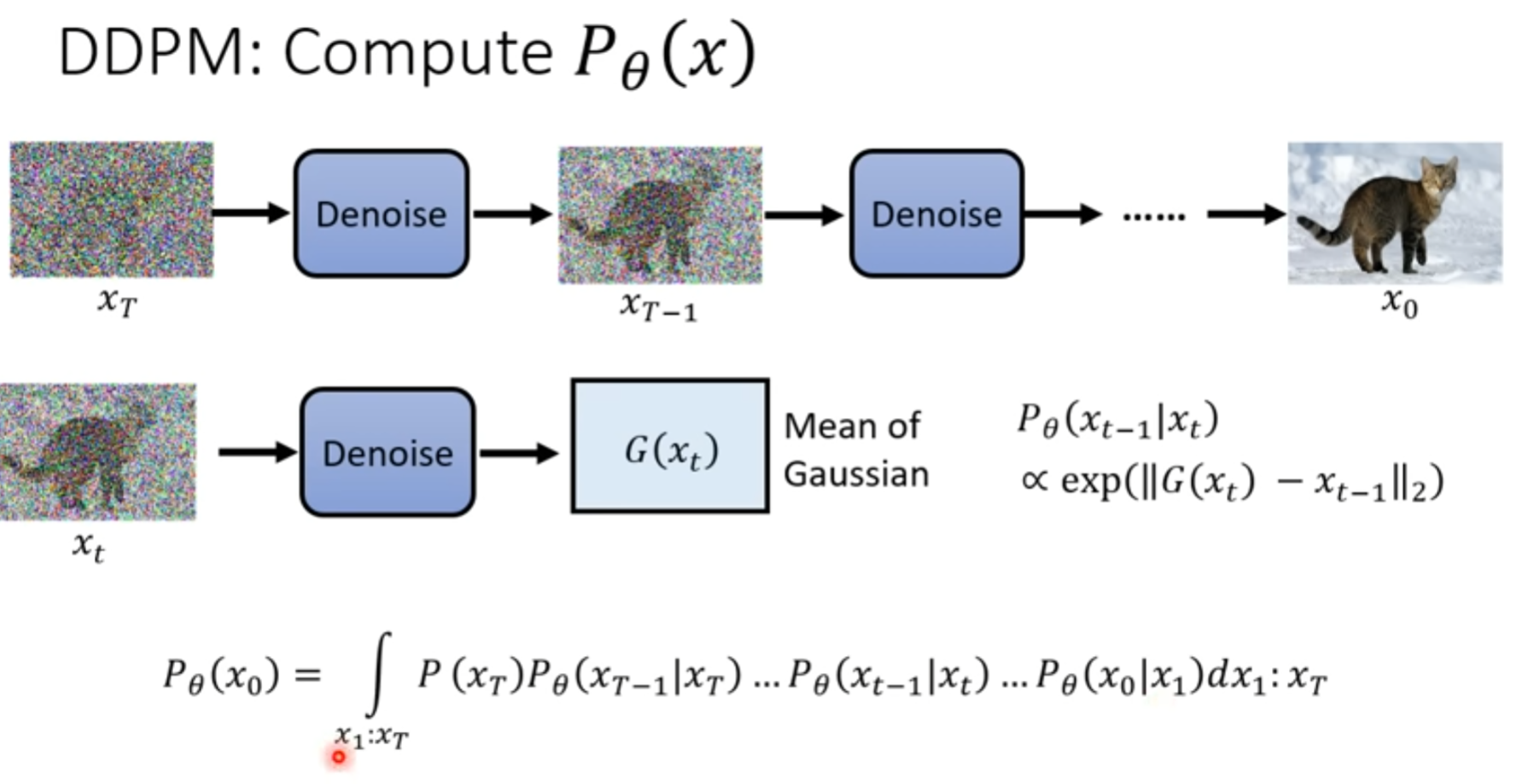

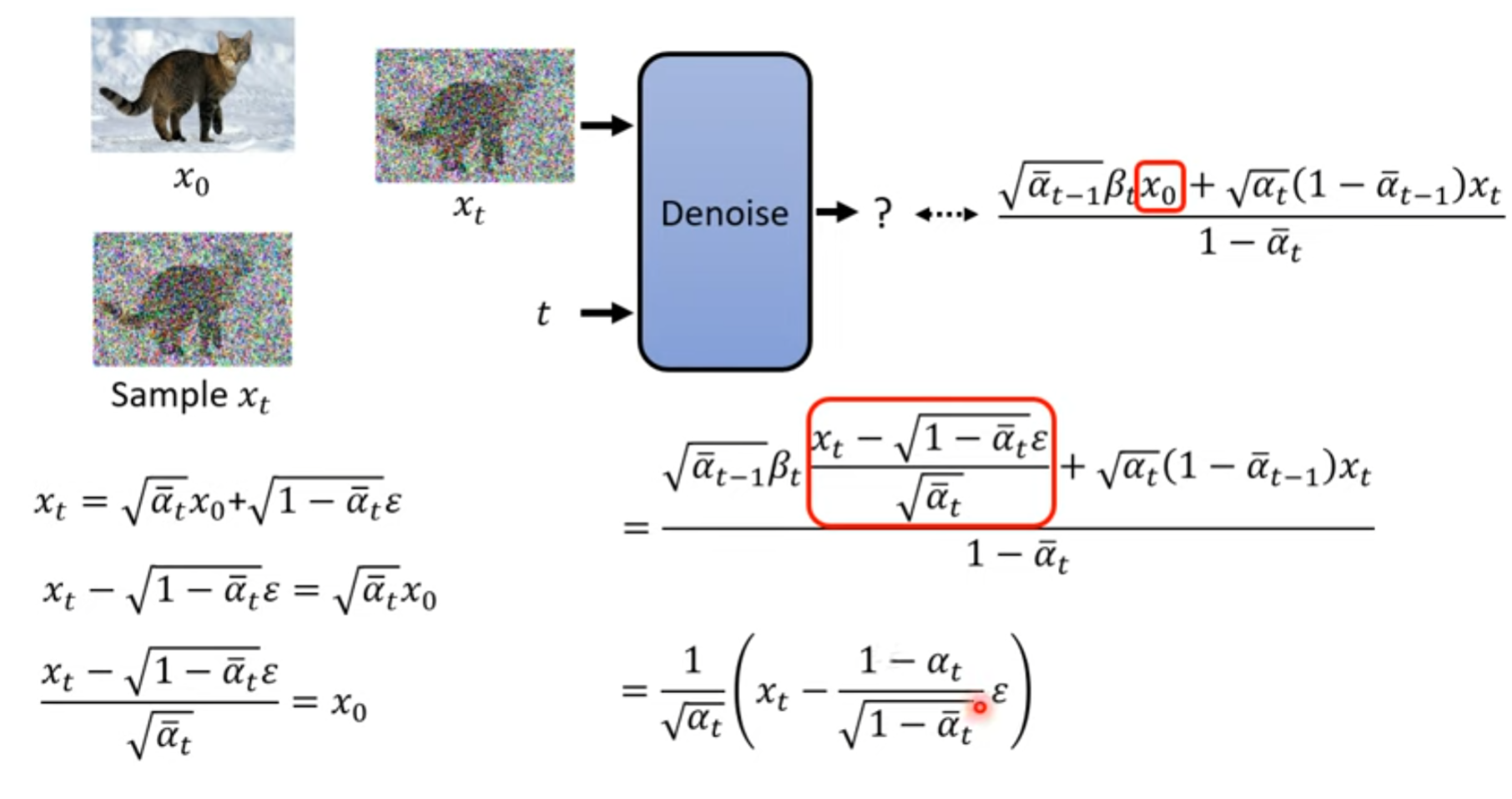
如何直接计算出来

如何最小化

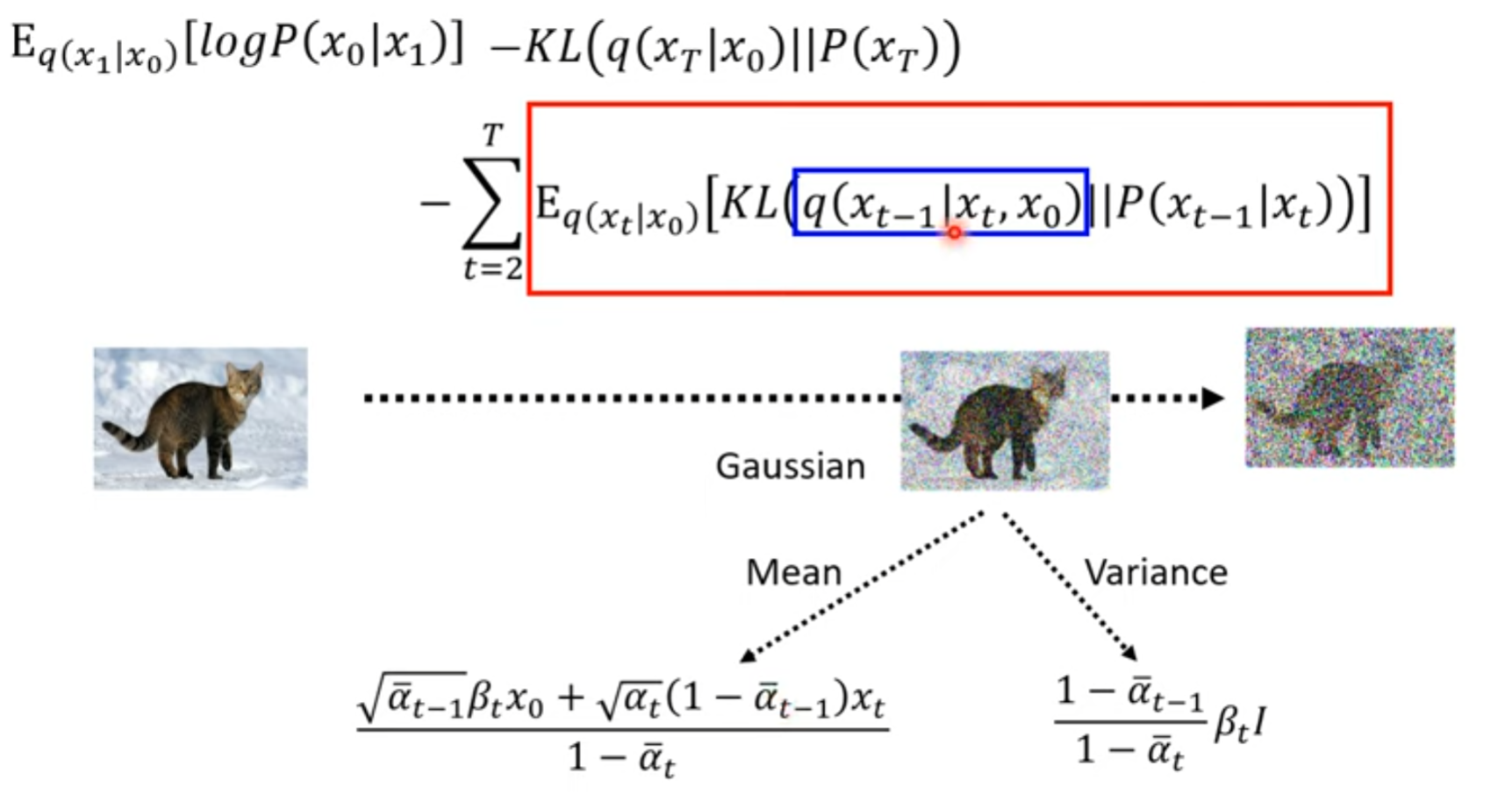
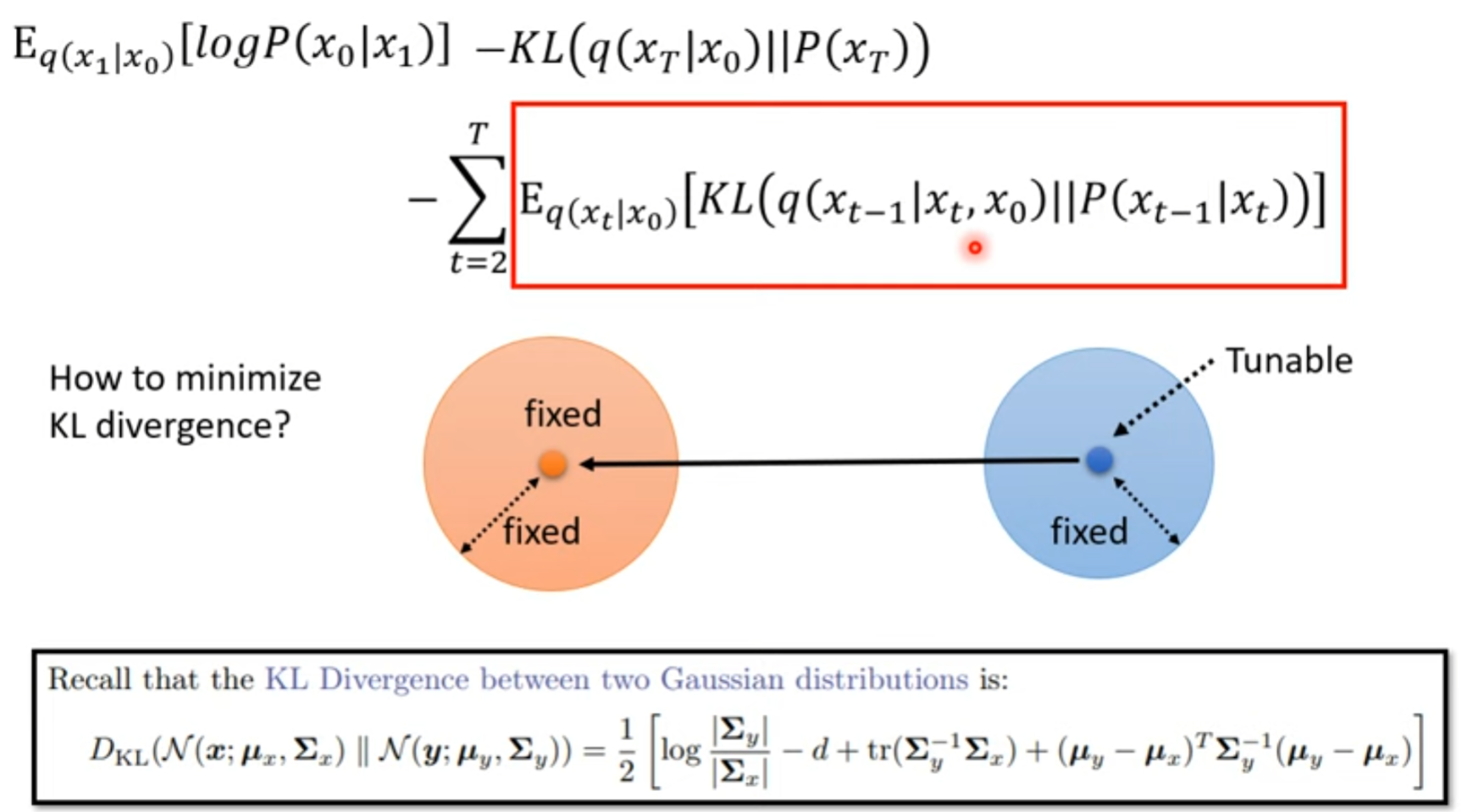
Denoise的目标
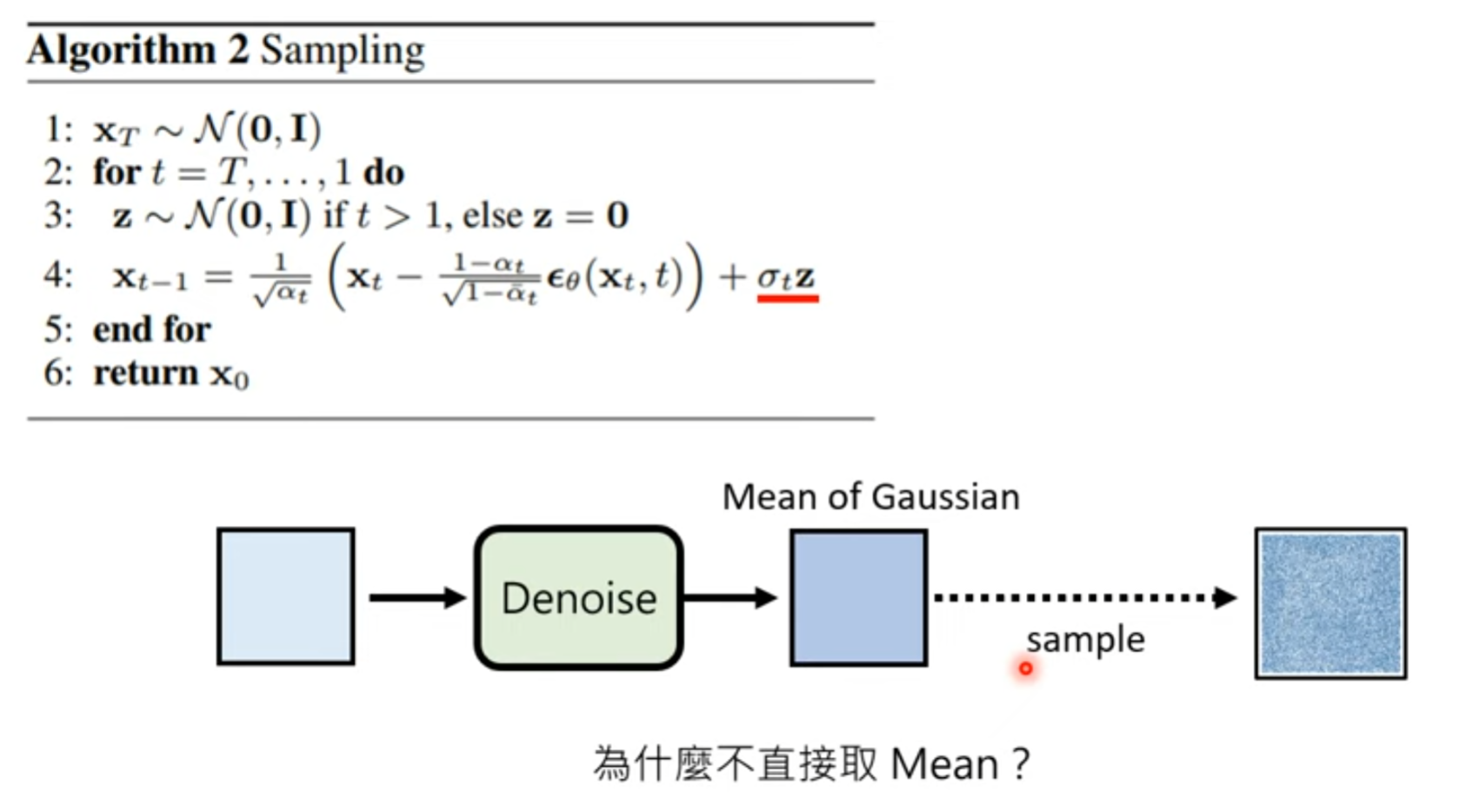
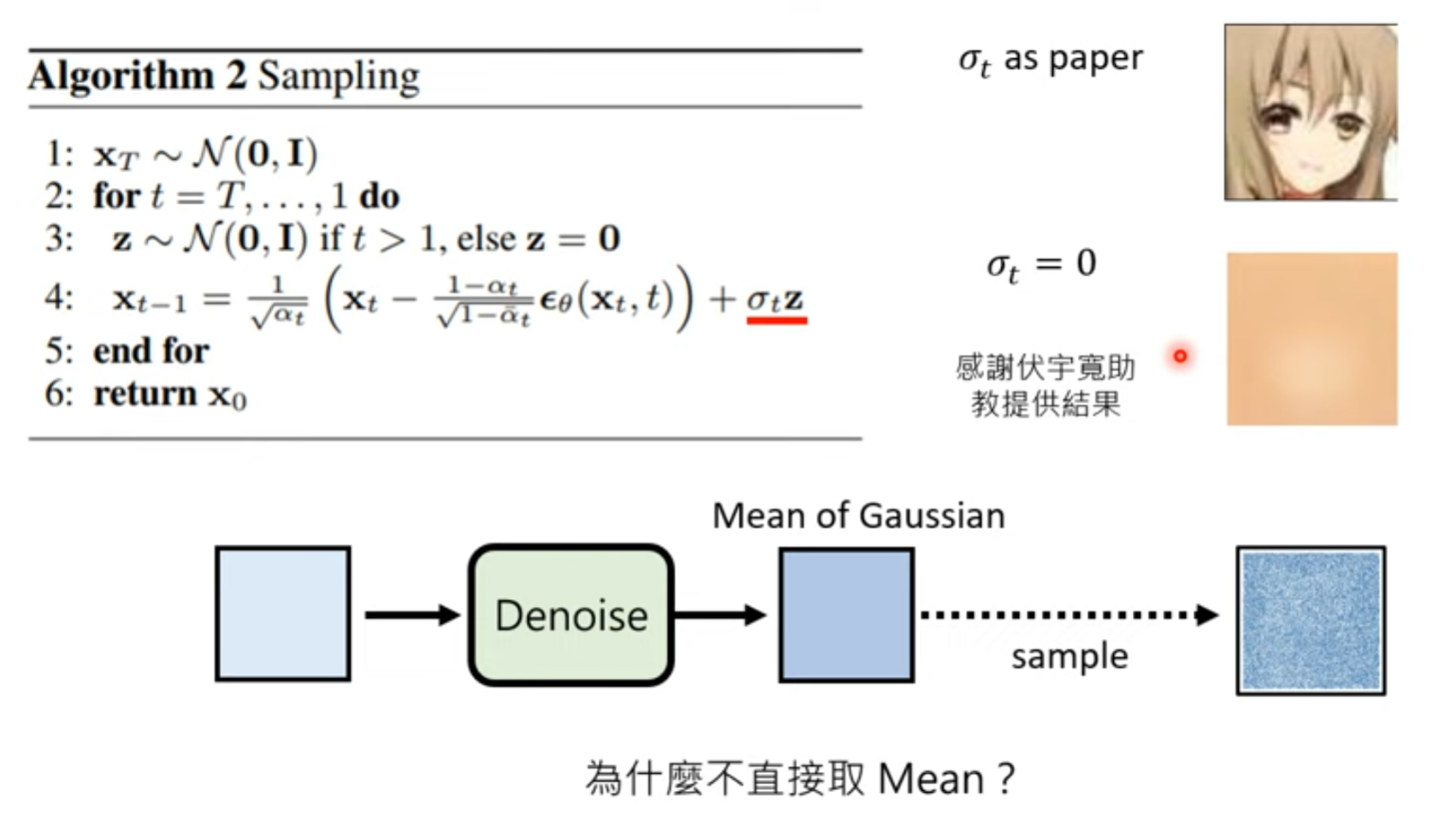
为什么还要加noise
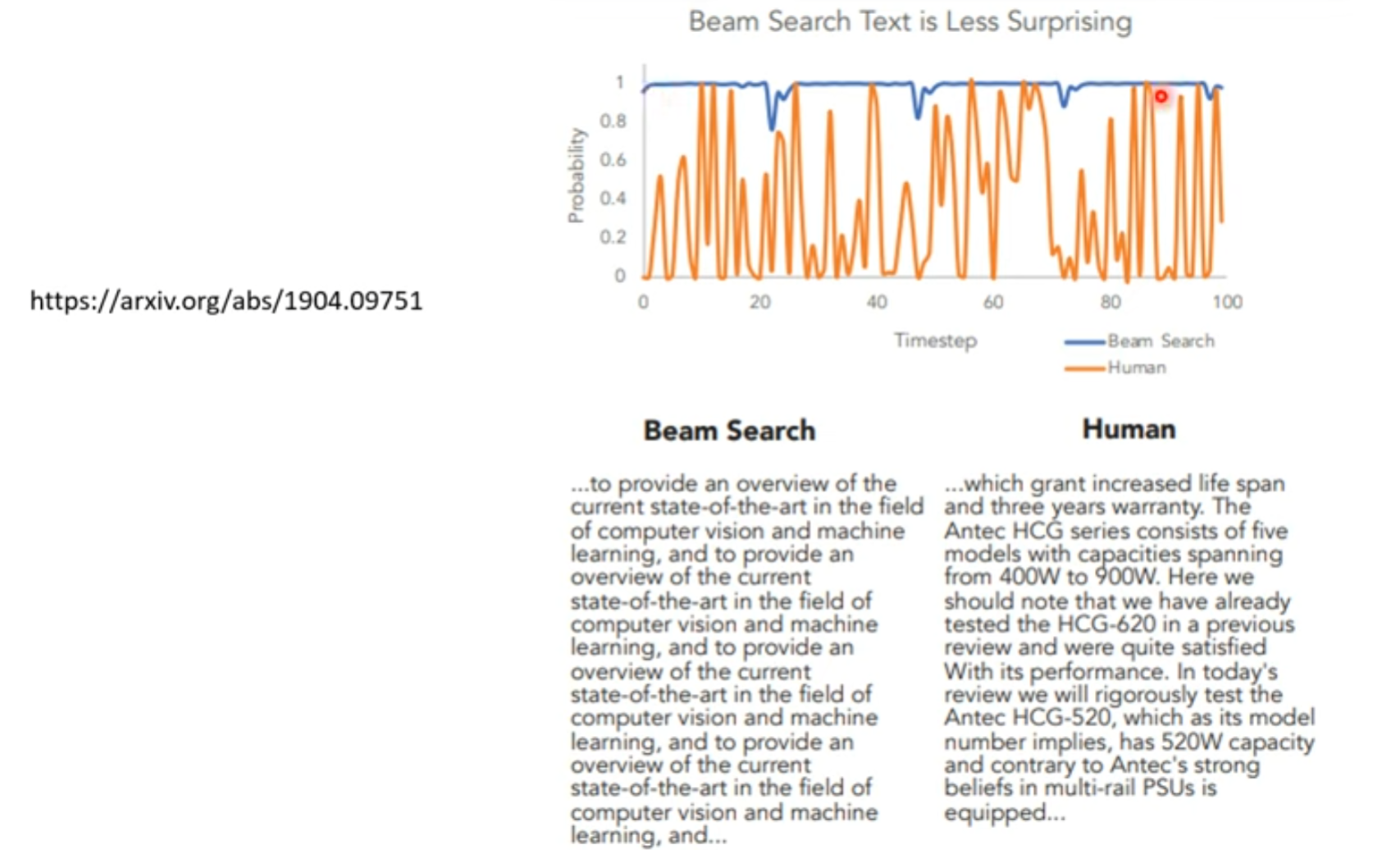
直接选择几率最大的,可能效果不好
验证效果
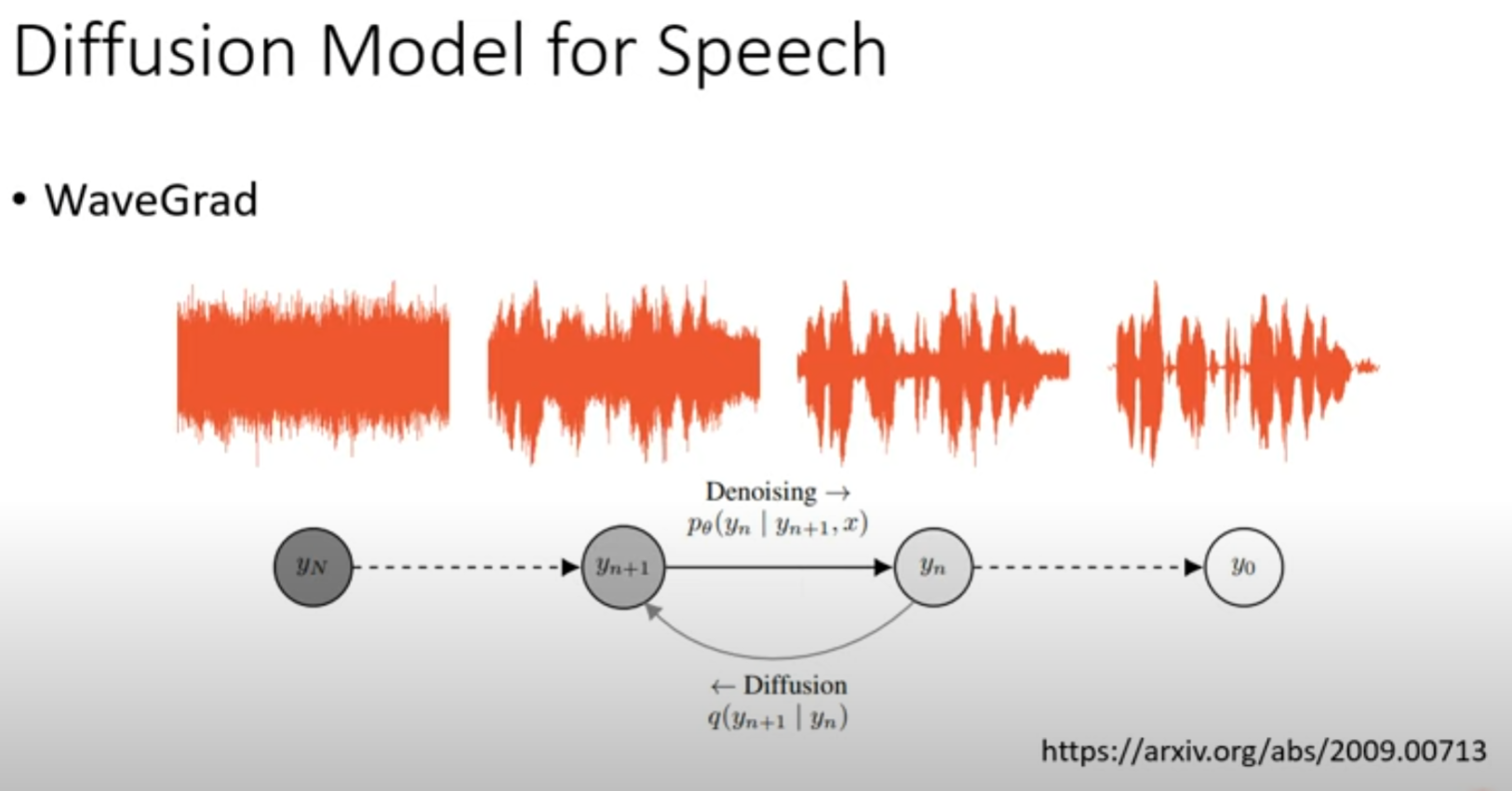
DM for speech
for Text
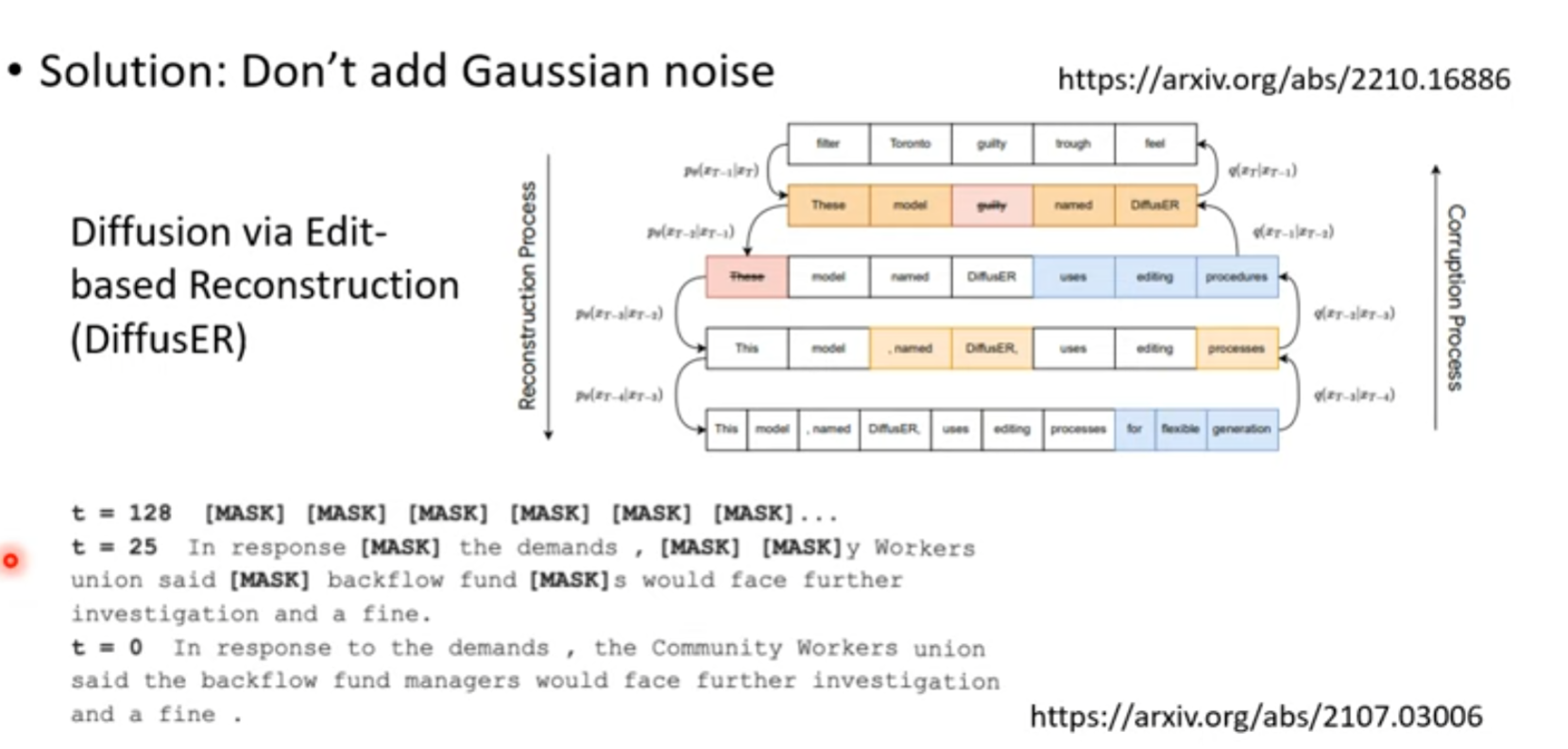
存在问题 文字是离散的,没法加noise
解决方法1,把noise加载 latent space


方法2 其他的 noise Distribution
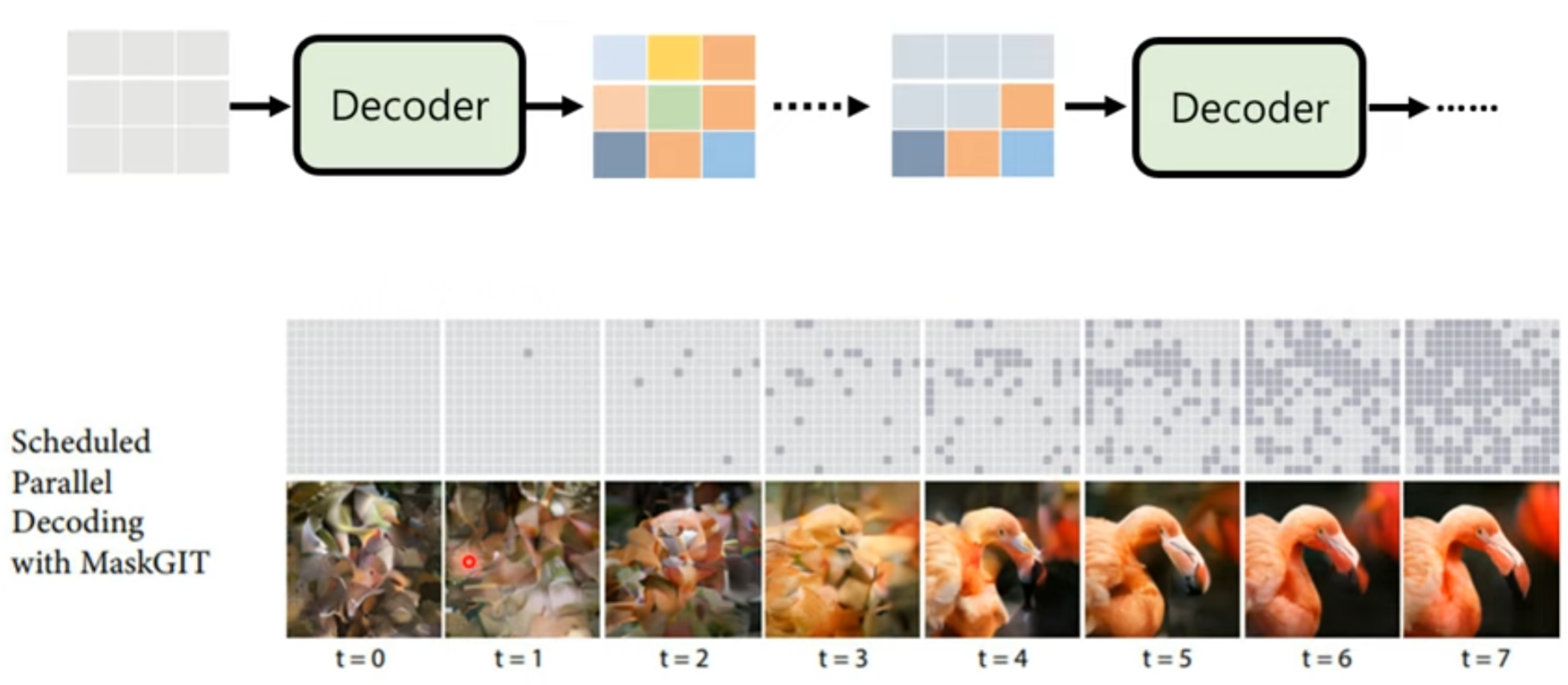
nar 方法
其他方法
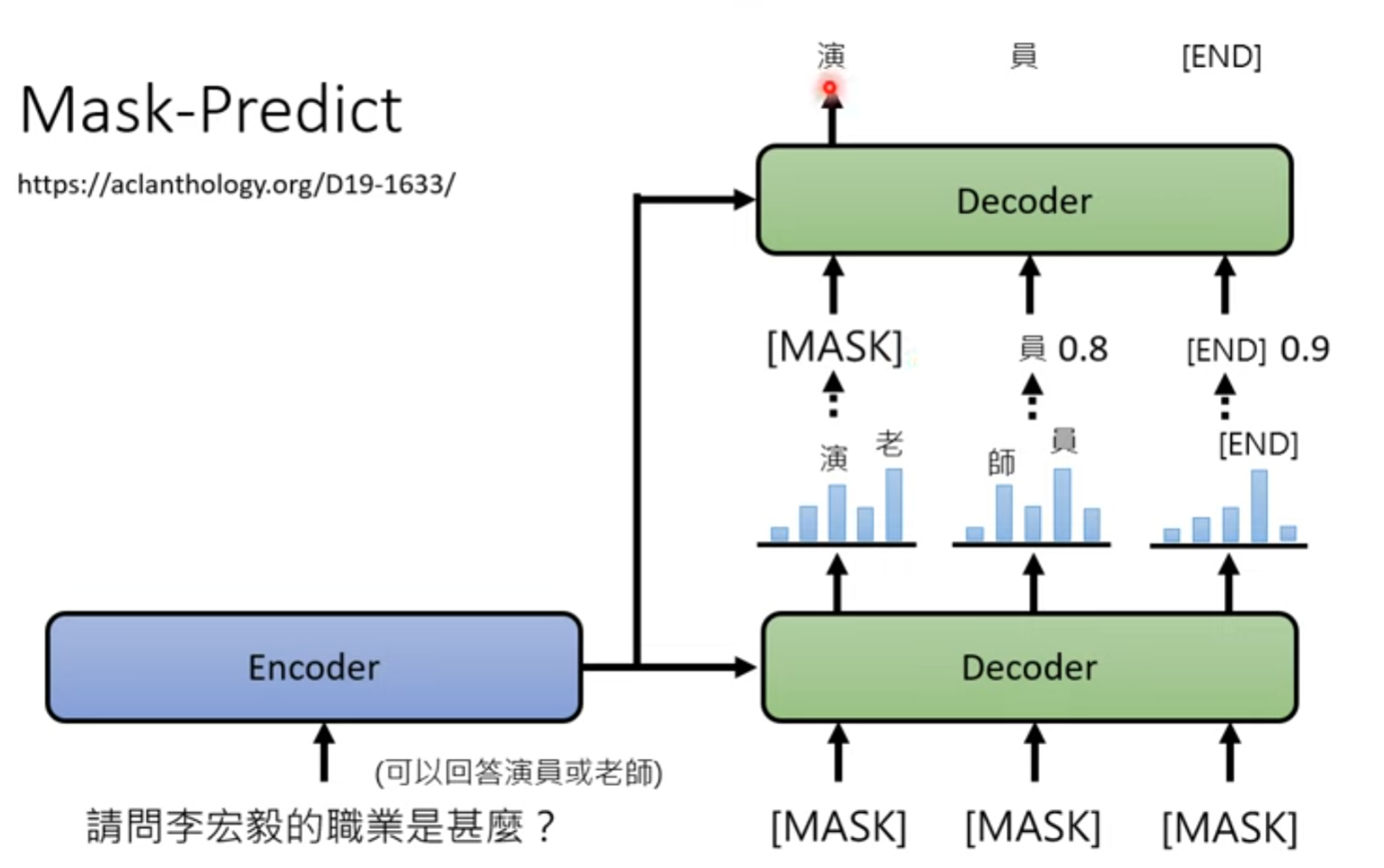
1 Mask-Predict
在latent space上再进行 auto coder

文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2023/10/01/Generativa-AI-03-Diffsion-Model/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)