Continual Learning 1 Introduction
1 Introduction
首先,让我们开始介绍Continual Learning。 我们要回答以下三个问题
- 什么是Continual Learning ?
- 它的目的是什么?
- 它和之前我们常见的机器学习,深度学习的区别和联系在哪里?
我们来回答上面这三个问题:
Continual Learning 是机器学习的一个子领域,主要关注在新的数据上来继续训练模型,在学习新的知识的同时不遗忘掉过去所学习得到的经验。
它和机器学习的一个根本区别在于训练的数据集不同。一般而言,机器学习是在一个确定的数据集中进行学习,训练集和测试集都是来自于这个数据集。而Continual Learning是在新的数据集进行训练,既要学习到新的知识又不能遗忘之前学习到的技能。
打个比方,机器学习好像就是高三总复习,把所有的高考知识点作为数据集,目的是得到一个能够在高考中表现最好的结果。而继续学习则是在你完成高三学习,进入大学之后学习到新知识,检测的标准既要看你在大学学习的怎么样同时也不能忘记了在高中学习到的知识。
还可以这么说,机器学习可以是学习游泳,然后检测标准就是你的游泳速度,继续学习类似铁人三项,学会游泳还得学骑自行车,跑步,并且不能学会自行车后把游泳技能给遗忘掉。
这么一说,大家就能够理解到Continual Learning 的困难之处了吧。
请各位大学生,研究生想一想,如果再次把你们塞到高考考场,那会表现如何呢。
Continual Learning要应对的问题就是遗忘,既能学习新的技能又不能遗忘掉以往的技能。
2 catastrophic forgetting
接下来,我们就介绍在机器学习中的遗忘现象,它被称之为 catastrophic forgetting ,翻译为中文为灾难性遗忘。
对于人类来说,遗忘也是一个很常见的现象。我们都知道在记忆单词的时候,有一个 艾宾浩斯遗忘曲线。
对于机器学习,也会出现这种遗忘现象。
我们都知道神经网络的学习能力其实就是指的是神经网络的拟合能力。那遗忘的原因可能是因为在训练新的数据的时候,梯度下降法修改了原来神经网络的权重,表现出的现象就是在之前任务得到很高的分数的能力消失了。
那我们上面的想法是不是正确的呢?
我们可以通过最简单的神经网络,一个神经元进行Continual Learning的任务测试,看到底是不是会有灾难性遗忘的现象,以及探究这种现象出现的原因到底是什么。
示例
数据集展示
我们使用的数据集是经典的美国曼哈顿房价,我们要看的是房子面积和房价的关系。然后我们将数据进行划分为两部分,2000年以前和2000年以后。也就是我们在2000年以前根据采样得到的数据,训练得到一个神经网络,看看它能不能在2000完成2000年以后得预测任务。
首先,我们先看一下数据的分布
首先是整体数据的分布:
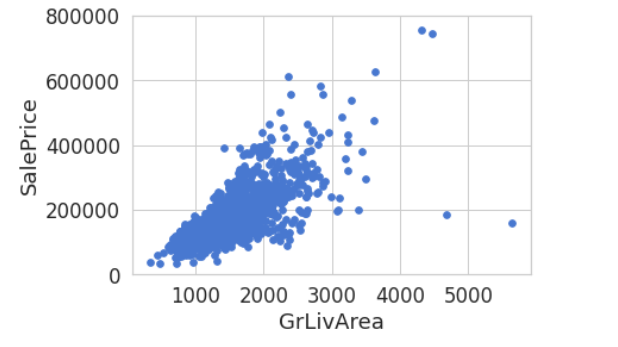
然后我按着时间划分之后,查看一下数据的分布是否存在不同,显然2000年以前的数据,与2000年以后得数据,与整体数据的分布都存在区别。
2000年以前
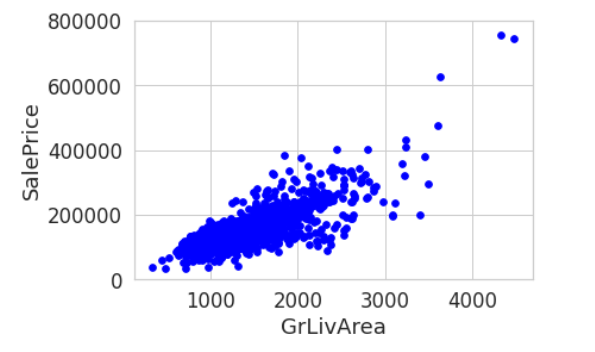
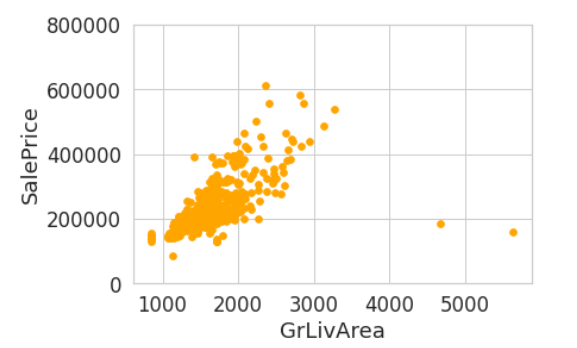
2000年以后:
网络设置
我们的神经网络只包含一个神经元,它有着两个参数 w,b
模型训练
由于我们只有一个神经元,也只能得到一个线性模型,
我们首先根据2000年以前的数据进行训练,得到一个模型,
效果如下
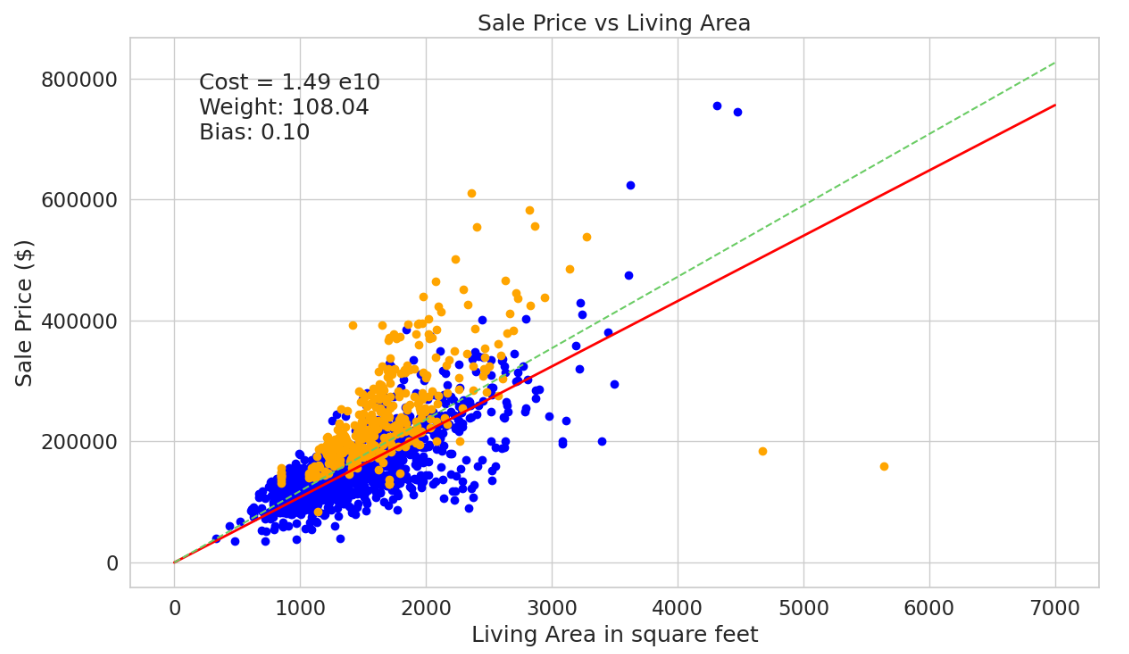
图中,蓝色点是2000年之前的数据,橙色点是2000年之后的数据。绿色线是使用所有数据训练得到的模型,红色为使用2000年之前的数据训练得到的模型。红线也就是我们的模型对于2000年以前的数据拟合地特别好,完美地完成了任务。
然后,我们在这个已经训练好的神经网络的基础上,再进行2000年之后的数据的训练,训练结果如下图所示
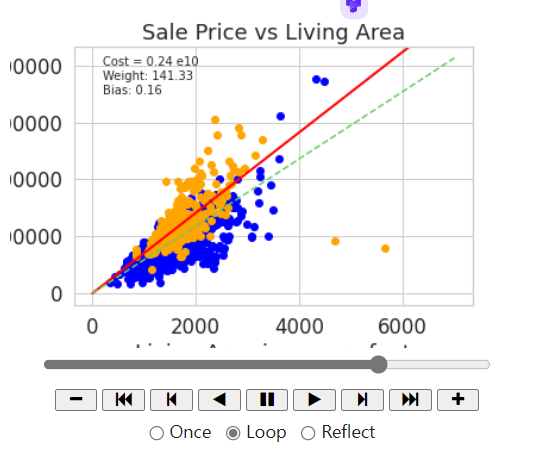
图中,红色线是在之前训练得到模型基础上,使用2000年之后的数据进行训练得到的结果。绿色线是使用所有数据训练得到的结果。可以清晰看出,经过再次训练之后的数据,对2000年之后的结果拟合地更好,而不是反映了所有数据的特征。
上述训练过程损失函数变化如下图所示,
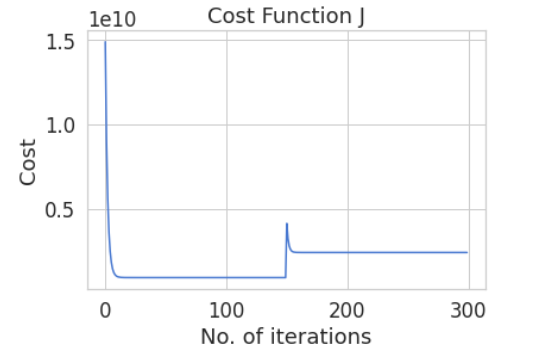
然后还给出了使用所有数据训练得到一个模型的损失函数变化曲线 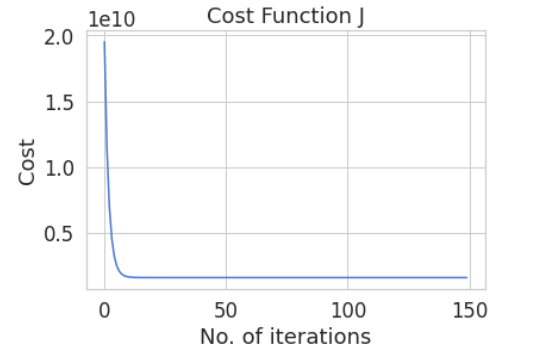
从第一张图中,首先,在第一次训练时,随着训练次数的增加,损失函数下降。然后在第二次任务训练时候,由于之前训练得到的模型不能完全匹配数据,所有训练开始的时候有着较大损失函数,然后损失函数下降,但与第二个训练曲线相比,最后的收敛效果并不好。
结论
首先,使用2000年之前的数据训练得到的模型能够很好地符合数据特点。但是再继续使用2000年之后的数据进行训练,模型更多地反映了2000年之后的数据特点。与所有数据训练得到的模型相比,这样训练得到的结果也并没有很好地符合整体数据的特征。
也就是说,数据出现了灾难性遗忘问题。
3 讨论
上面我们通过人为把数据集进行了区分,然后发现神经网络在学习新的知识时确实存在灾难性遗忘问题。但我们使用全部数据集训练得到的结果反而对整体数据进行了合适的拟合。这样看来,好像是我们故意设置的这个区分,如果使用所有数据集就不需要考虑所提出的灾难性遗忘问题了,也就没有Continual Learning的必要了。
但实际上,灾难性遗忘问题是一个必须考虑的问题。
首先,数据集是有限的有错的,不是全面的完美的。数据集本身可能就会存在一些错误且据集不可能包含所有的信息。在时间上,以房价数据为例,不同年份的数据是不同的,我们要想得到一个更好的数据,就必须根据新的数据对原有的模型进行调整。另外,数据集范围不能包含所有的每一户的交易信息。因此,模型的准确性是强依赖于数据集的,面对新的任务,就需要新的数据。
另外,从数据的使用来说,大模型和个人使用的要求并不是完全一致的。对于个人使用者来说,需要个人的隐私数据和特征数据对大模型进行进一步改造,这样才能更好地适用个人的习惯与目的。这也导致必然需要根据新的数据来进行训练。
我们当然不希望,在加入新的数据进行训练后,原有模型的能力和技巧都消失掉。
想象一下,你买回家一个智能机器人,结果当你告诉他你叫做啥之后,它就只记得这个了,那岂不是崩溃掉。
总之,从Continual Learning概念是深度学习领域发展必然需要的技术。
4 发展历史
下面简要介绍一下发展历史和一些相关概念。

多任务学习 Multi-Task Learning:
多任务学习的目的是能够结合所有任务的共同知识,同时改进所有单个任务的学习性能,因此,多任务学习要求每个任务与其他任务共享模型参数,或每个任务有带约束的模型参数,别的任务能够给当前学习任务提供额外的训练数据,以此来作为其他任务的正则化形式 .
多任务学习需要所有任务的数据,此外,多任务学习随着时间的推移,不会积累任何知识,也就是说没有持续学习的概念,这也是多任务学习的关键问题所在 .
迁移学习 Transfer Learning & Domain Adaptation:
迁移学习是使用源域来帮助另一个任务完成目标域学习的一种学习方式 。它假设源域中有大量的标记训练数据,而目标域只有很少或没有标记的训练数据,但有大量未标记的数据。迁移学习可以 利 用 被 标 记 的 数 据 来 帮 助 完 成 目标域中的 学 习,
然 而 迁 移 学 习 与 连 续 学 习,主 要 有4个不同:
1 迁移学习不是连续的,它仅仅是使用了源域来帮助完成目标域学习;
2迁移学习并没有将过去所学的知识进行积累;
3迁移学习是单向进行的,也就是说,迁移学习仅可使用源域来帮助完成目标域的学习,然而,连续学习是可以在任何方向上进行学习的;
4迁移学习假设源域与目标域非常相似,且这种相似性是人为决定的,然而在连续学习中并没有做出这样一个很强的限制性假设
元学习 Meta-Learning :
元学习,有时被称为“学习如何学习”,指的是一种能力,使得机器学习模型可以通过学习一系列不同的任务来提高其在新任务上的学习效率和效果。元学习主要关注于快速适应新任务,通常是在只有少量数据的情况下。
目标:元学习的目标是使模型能够从少量的数据中迅速学习新任务或适应新环境。
方法:常见的方法包括学习一个能够调整其他模型参数的“元模型”,或者优化模型的初始参数,以便在新任务上快速调整。
区别
焦点差异:持续学习关注于如何保持旧知识并逐步积累新知识,而元学习关注于快速掌握新任务。
方法上的不同:持续学习通常需要解决遗忘问题,而元学习更多关注于找到一种有效的学习策略或参数设置,使得模型能够快速适应新任务。
应用场景:持续学习适用于那些数据持续更新或任务持续变化的场景,元学习适用于那些需要模型在很少的迭代中迅速适应新任务的场景。
在线学习Online Learning:
在线学习是一种处理数据流的学习模式,模型持续地从每个数据点或小批量数据中学习,通常用于处理实时更新的数据。
- 数据流处理:在线学习关注于处理连续到达的数据流。这种数据通常是按时间顺序到达,模型需要及时更新以反映最新数据。
- 实时更新:在线学习模型通常在每个数据点到来时立即更新,或者在处理小批量数据后更新。
- 内存效率:由于数据是流式传入的,在线学习模型通常不会(也不能)存储全部历史数据,而是快速地从当前可用数据中学习。
- 适应性强:这种学习模式适用于动态环境,能够适应数据分布的变化。
在线学习通常实时更新,而持续学习需要在不同任务间平衡知识。在线学习的挑战在于快速适应新数据,持续学习的挑战在于保留旧知识同时学习新知识。
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/01/10/ContinualLearning-1-Introduction/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)