Continual Learning 2 Methods
参考
持续学习:论可持续学习的机器(Continual Learning) - 知乎 (zhihu.com)
介绍几篇incremental/continual/lifelong learning的综述论文 - 知乎 (zhihu.com)
0 CL 要解决的问题
continual learning 要解决的不仅仅是灾难性遗忘问题 ,还要考虑之前记忆与新知识的权衡,学习新的知识的效率和成本的平衡等


1 策略 种类 和历史
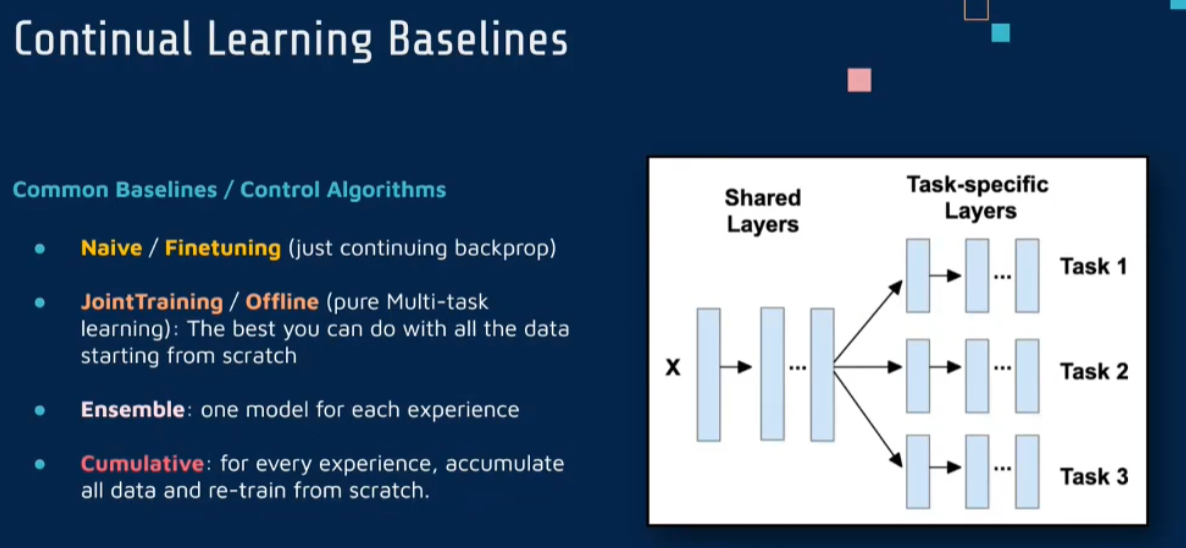
1 baseline
先介绍一下基本的方法
Naive/Fine tuning : fine tuning model on new data
Offline/ JointTraining: all the data ,solve the task all together
Ensemble : one for each and put together
Cumulative: acumulative memory
2 Fundamental Design Choices
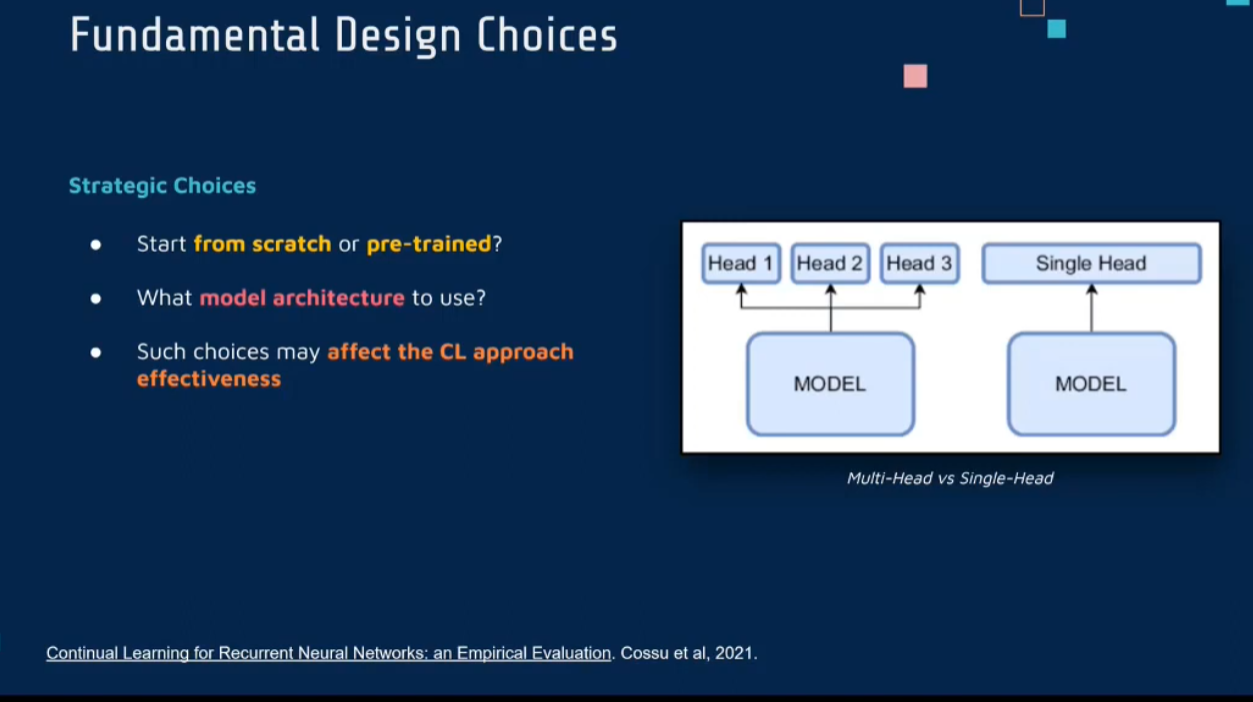
一些基础的选择,例如是从头训练
1 Strategic Choices
- start from pre-triained or sctatch?
- model architecture
3 History
- Task Incremental
- Regularization
- Architectural
- Repaly Strategies
- pre-trained models

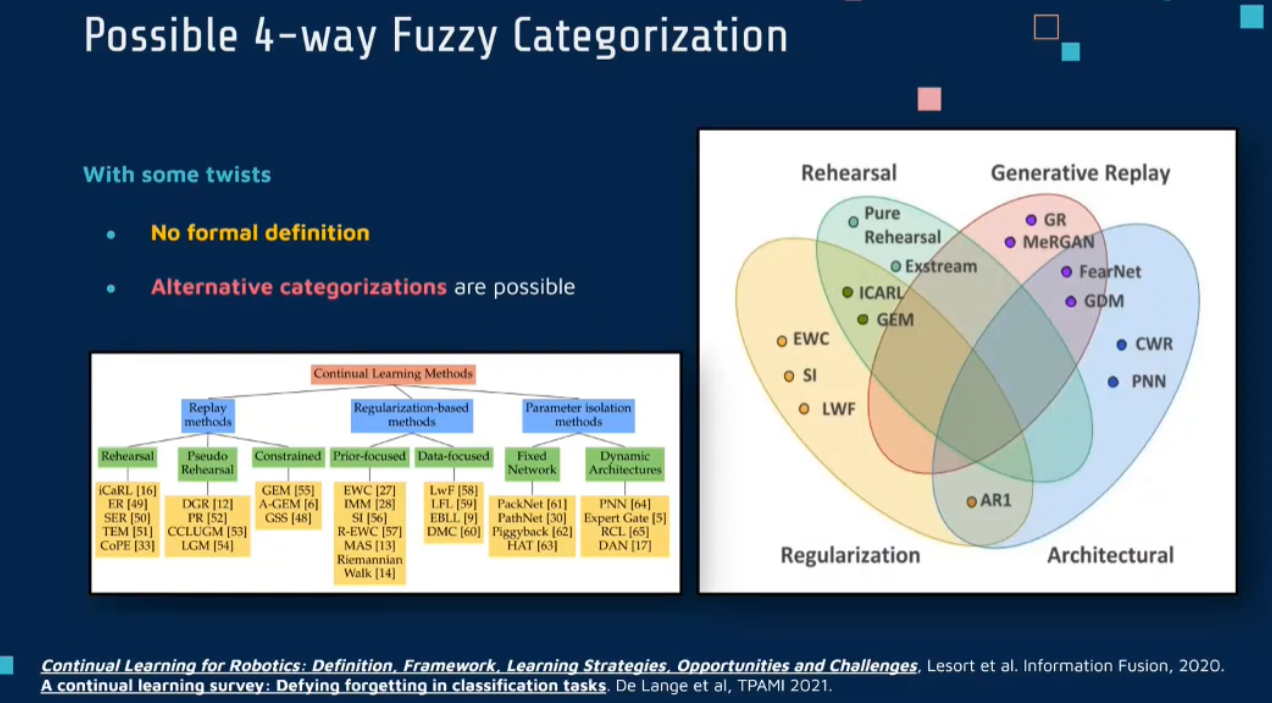
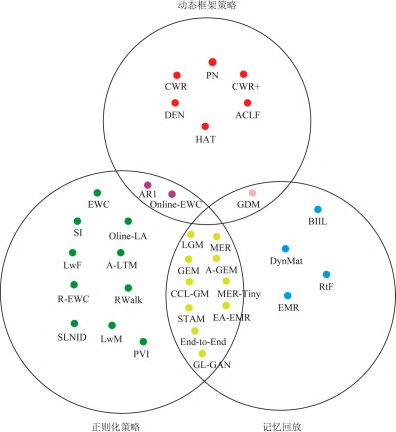
4 Categorization
根据所使用的方法,可以大体将其分为三类或者四类
2 记忆回放
生物学基础
在生物学上,互补学习系统(complementary learning systems,CLS)主要包括海马体和新皮质系统2部分,其中,海马体表现出短期的适应性,并允许快速学习新知识,而这些新知识又会随着时间的推移被放回到新皮质系统,以保持长期记忆.更具体地说,海马体学习过程的主要特点是能够进行快速学习,同时最小化知识间的干扰.相 反,新大脑皮层的特点是学习速度慢,并建立了学习知识间的压缩重叠表示.因此,海马体和新皮质系统功能相互作用对于完成环境规律和情景记忆的学习至关重要.
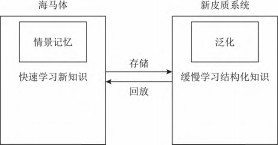
如图所示,CLS包括用于快速学习情景 信息的海马体和用于缓慢学习结构化知识的新皮质2部分,即海马体通常与近期记忆的即时回忆有关,例如短期记忆系统,新皮层通常与保存和回忆遥远的记忆有关,例如长期记忆.CLS理论为记忆巩固和检索建模计算框架提供了重要的研究基础.
分类
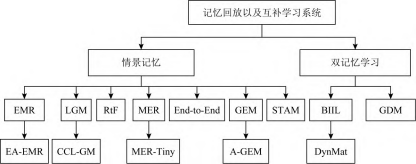
优点与缺点
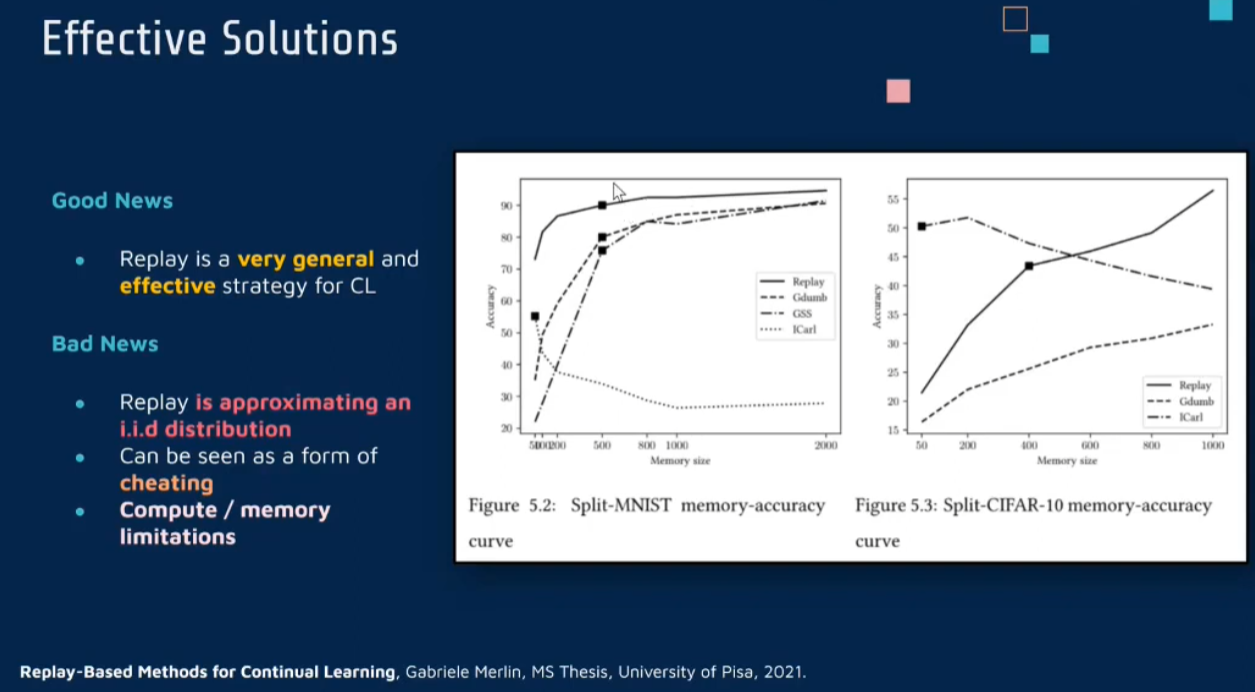
- effective
- cheating?: keep the main primitive gradient set the optimization algorithm as gd, we submit to this algorithm mini batches containing data that the algorithm has already seen before to simulate some on an ad distribution
Random Replay

- for favorite each training batches (there are different over time)
- union of the examples of the current experience data and the random 当前经验数据的实例与随机内存的并集
- h number of example that you should try to recover from the current experience, so that you get an equal reportation of all the all the examples overall. that is the memory size divided by the current i , the maximum amount of examples you may have for each of the experience into the external memory
- select these h patterns from the batch of data the data set related to the current experience
- if the memories are already full you replace randomly these h examples
- operated this replacement once you have selected this example and you have the actual 缓冲 缓冲器 缓和 favorite buffer updated
问题:这和强化学习中的经验池更新有什么区别
回答: 其实是一样的,区别是强化学习有直接的奖励 而不需要交叉验证。强化学习中的 experience replay
论文

Memory Efficient Experience Replay for Streaming Learning
| [Memory Efficient Experience Replay for Streaming Learning | IEEE Conference Publication | IEEE Xplore](https://ieeexplore.ieee.org/abstract/document/8793982) |
《Memory Efficient Experience Replay for Streaming Learning》这篇论文提出了一种针对流式学习环境的持续学习方法,着重于提高经验重放的内存效率。这一方法特别适用于资源受限的环境,如在边缘计算设备上进行学习,其中内存资源有限。
策略重放
在流式学习环境中,数据持续不断地到来,且每个数据点可能只能被访问一次。在这种情况下,使用传统的重放机制(即存储和重用旧数据)可能会导致巨大的内存需求。该论文提出的方法旨在通过更高效地选择和使用重放数据来降低内存需求,同时仍然有效地防止神经网络的灾难性遗忘。
方法
选择性重放:该方法不是盲目地存储所有经历过的数据,而是选择性地保存那些最有可能对模型性能产生重大影响的数据。这种选择基于数据的重要性,比如它们的稀有性或对模型改进的潜在贡献度。
压缩存储:为了进一步减少内存占用,该方法使用数据压缩技术来存储选定的重放样本。这可以通过各种方式实现,比如降维、数据编码或有效的数据压缩算法。
高效重放策略:当使用重放数据进行训练时,该方法采用高效的策略来最大限度地提高这些数据的使用效率。这可能包括优化重放频率和调整训练过程以专注于那些最有信息量的样本。
动态适应:在流式学习环境中,数据分布可能会随时间变化。该方法能够动态调整其重放策略,以适应这种数据分布的变化,确保模型持续有效地学习。
结论
《Memory Efficient Experience Replay for Streaming Learning》提出的方法解决了在资源受限的流式学习环境中进行持续学习的挑战。通过选择性和高效的重放策略,该方法能够在保持较低内存需求的同时,有效地减少神经网络学习过程中的灾难性遗忘。这对于那些内存资源有限,但需要持续从数据流中学习的应用尤其有价值。
Interesting strategy
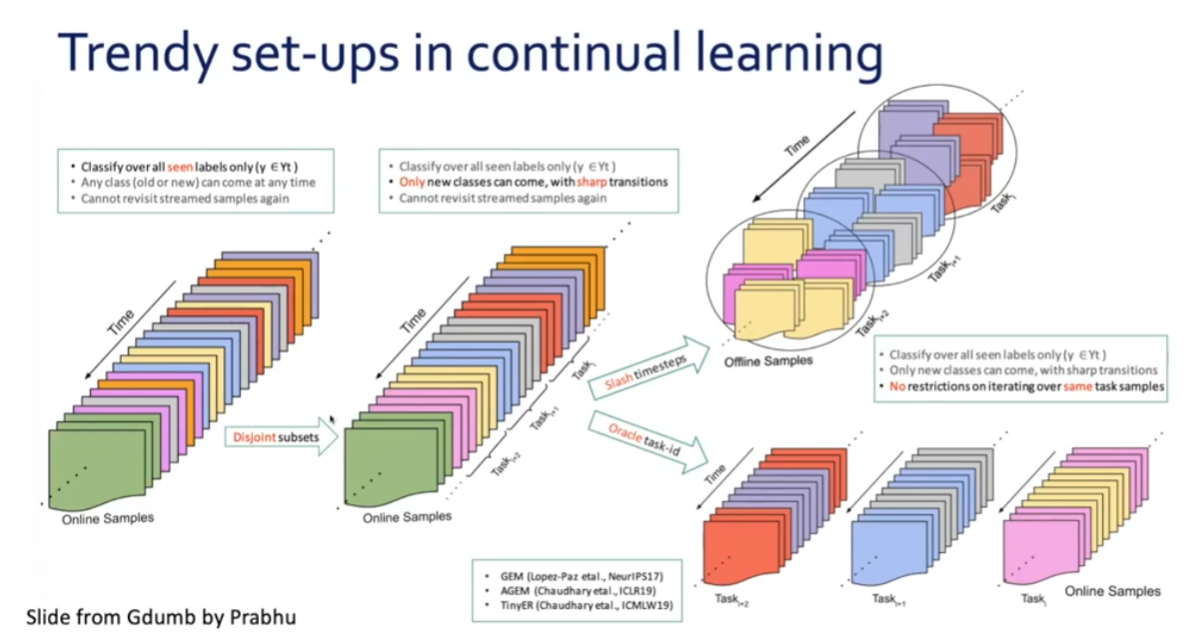

GDUMB
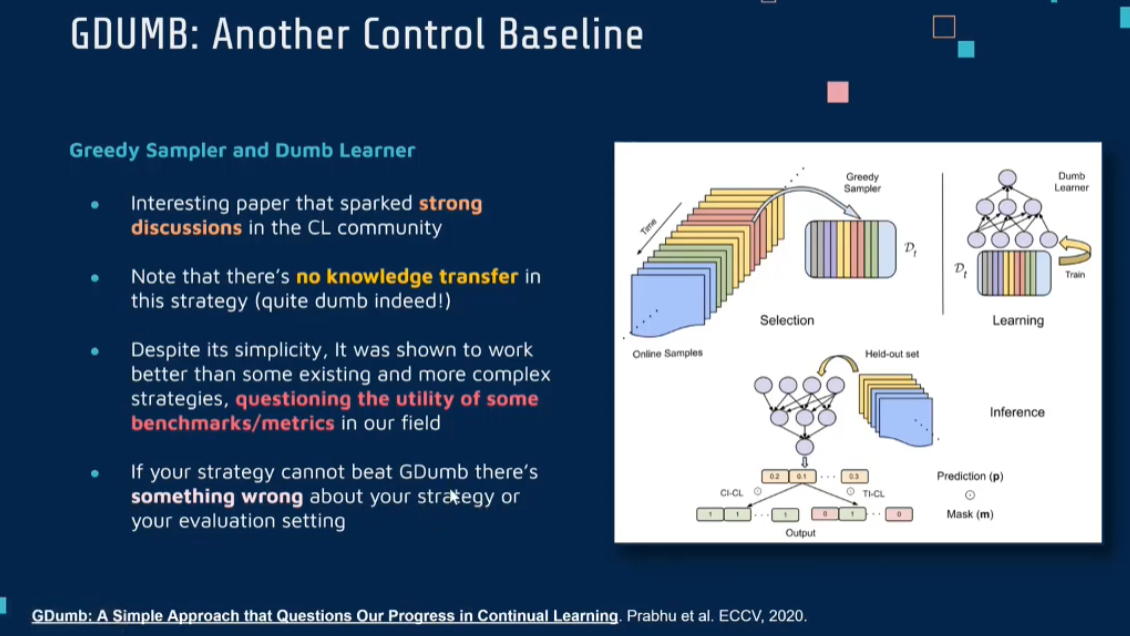
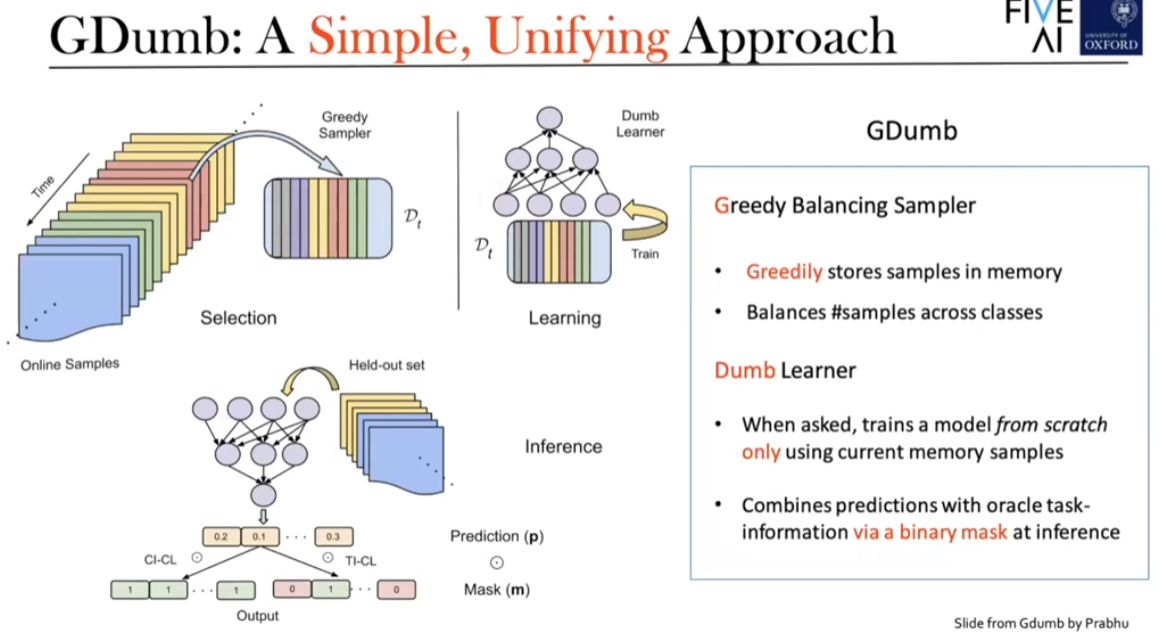
GDumb Approach: The proposed method, GDumb, consists of two main components:
- Greedy Sampler: This component stores samples in memory as they come, ensuring a balanced representation of classes.
- Dumb Learner: At test time, a model is trained from scratch using only the samples in memory. This “dumb” approach assumes no prior knowledge of the problem specifics, making it a simple yet effective method for continual learning.
《GDumb: A Simple Approach that Questions Our Progress in Continual Learning》这篇论文提出了一种名为GDumb的简单但有效的持续学习方法。GDumb的提出旨在质疑当前持续学习领域的复杂方法是否真正取得了显著进步,特别是在实际应用中的有效性。
主要思想
GDumb的核心思想是极度简化持续学习的过程。它采用一种简单的策略:存储一小部分最近遇到的数据,并且只在必要时(即数据存储满时)对存储的数据进行一次性训练。这种方法与传统的持续学习策略形成鲜明对比,后者通常需要复杂的算法来在学习新任务的同时保留旧任务的知识。
方法
数据存储:GDumb维护一个固定大小的内存缓冲区,用于存储最近遇到的样本。这个缓冲区被平均分配给每个类别,以确保数据的多样性和代表性。
简单重训练:当内存缓冲区填满时,GDumb会使用缓冲区中的所有数据从头开始训练一个全新的模型。这意味着模型不是逐渐适应新数据,而是进行完全的重置和重训练。
避免复杂策略:GDumb避免使用任何特殊的技术或策略来处理灾难性遗忘,如动态网络扩展、权重整合或生成重放等。这使得方法极其简单且易于实现。
评估持续学习进展:通过与更复杂的持续学习方法进行比较,GDumb提供了一种评估这些方法是否真正有效的手段,特别是在资源受限或实际应用的场景中。
结论
《GDumb: A Simple Approach that Questions Our Progress in Continual Learning》通过提出GDumb方法,挑战了持续学习领域中复杂方法的必要性和有效性。该方法展示了即使是极其简单的策略,也可以在某些情况下实现与更复杂方法相媲美的性能。GDumb的提出促使研究者重新思考持续学习策略的设计,以及如何更有效地评估这些策略的实际应用价值。

Sample Selection
choose example for min batch
MIR
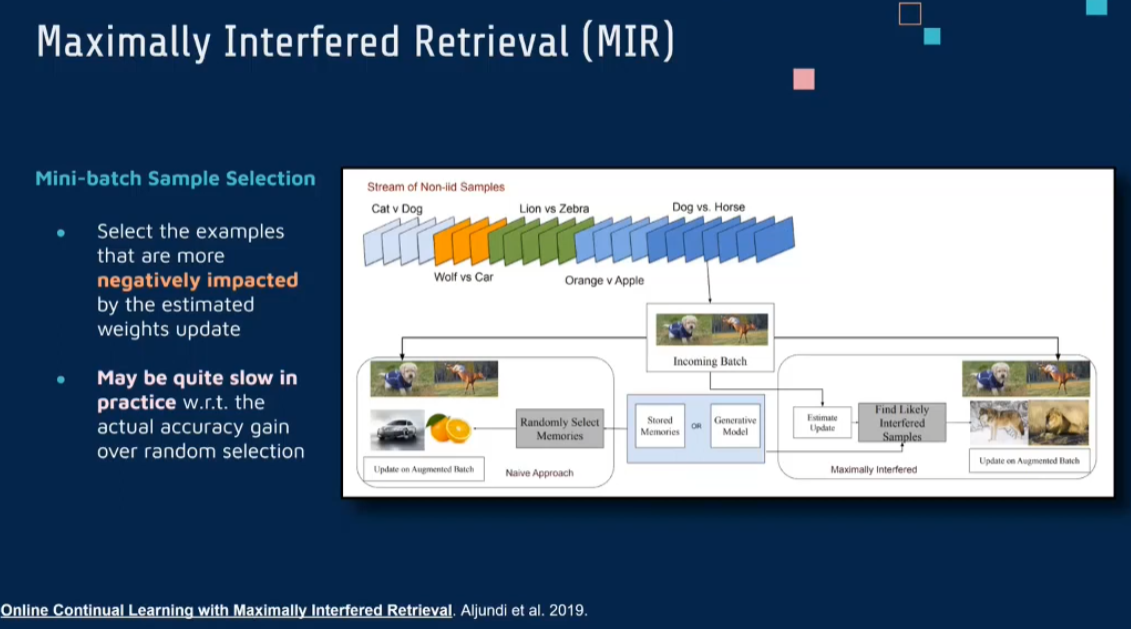
《Online Continual Learning with Maximally Interfered Retrieval》这篇论文提出了一种新的在线持续学习方法,旨在解决传统持续学习中的重要问题之一:如何有效地选择用于训练的样本,以最小化灾难性遗忘并提高新任务的学习效率。
主要思想
论文的核心思想基于这样一个观察:在持续学习过程中,网络容易忘记那些与当前任务高度相关但又在以往任务中较少出现的样本。为了解决这个问题,论文提出了“最大干扰检索”(Maximally Interfered Retrieval, MIR)策略。这个策略的目的是在持续学习的过程中,优先选择那些最可能被遗忘的样本进行重放学习。
方法
- 样本选择机制:MIR通过评估每个样本对于当前模型参数的梯度变化,来识别哪些样本最有可能被遗忘。具体来说,它选择那些梯度变化最大的样本,因为这些样本对于当前模型的影响最大。
- 在线学习:与传统的持续学习方法不同,MIR在在线设置中工作,即数据是按顺序到达的,而不是分批处理。这使得MIR特别适合于需要实时更新模型的应用场景。
- 减少遗忘:通过这种方法,MIR能够有效地减少灾难性遗忘,因为它优先重放那些对当前任务影响最大的样本。这不仅帮助模型保留重要的过往信息,也提高了对新信息的适应能力。
结论
总的来说,《Online Continual Learning with Maximally Interfered Retrieval》提出了一种有效的在线持续学习策略,通过智能地选择重放样本来减少遗忘,提高学习效率。这为持续学习领域提供了一个新的视角,并为解决实时数据流中的学习问题提供了可能的解决方案。
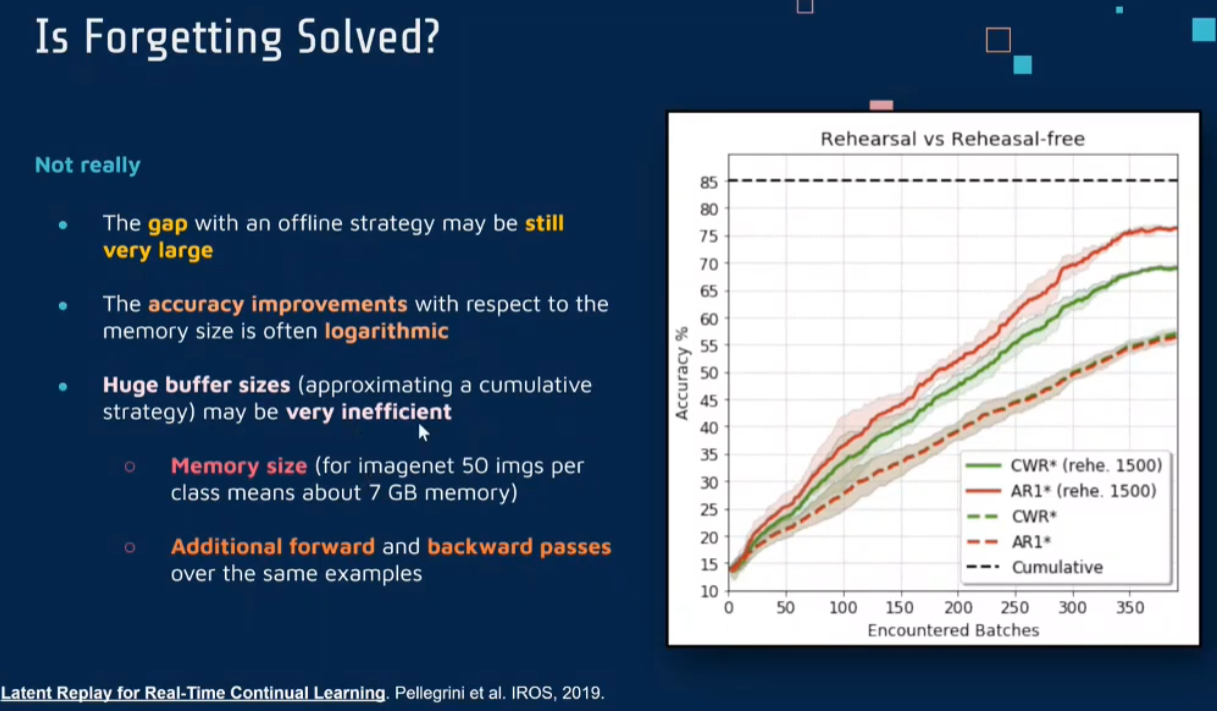
Latent Replay
not from data but from latent
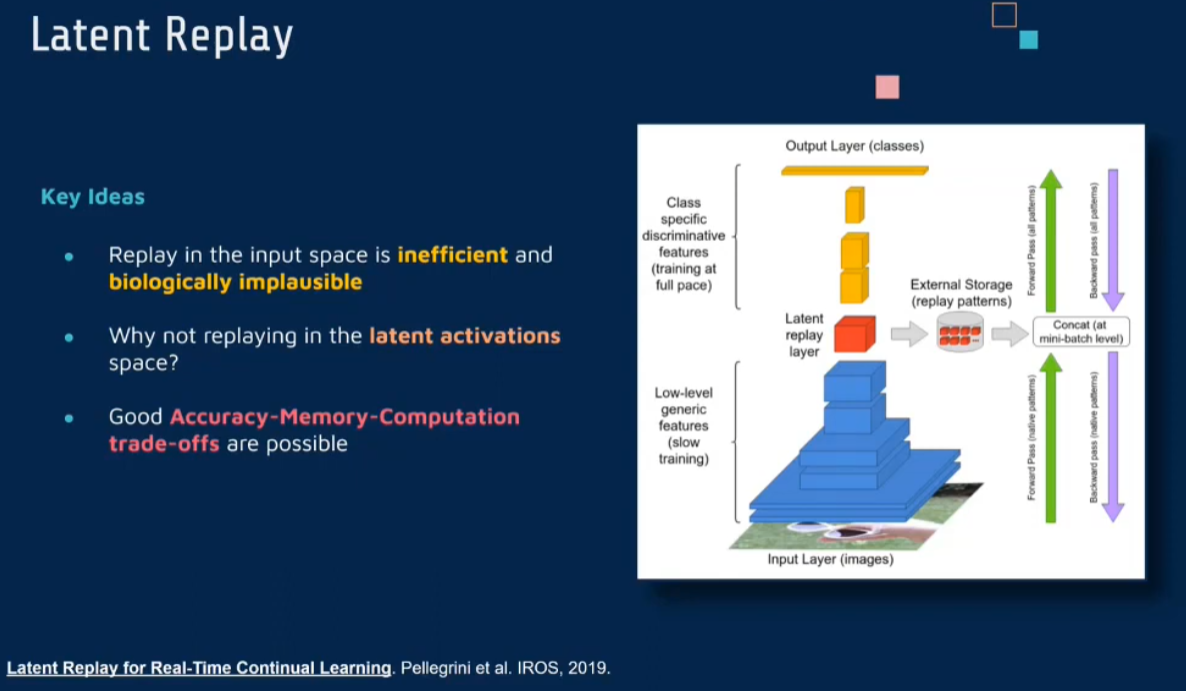
| [Latent Replay for Real-Time Continual Learning | IEEE Conference Publication | IEEE Xplore](https://ieeexplore.ieee.org/abstract/document/9341460) |
《Latent Replay for Real-Time Continual Learning》这篇论文在持续学习领域提出了一个创新的概念——潜在重放(Latent Replay)。这种方法旨在解决实时持续学习中的挑战,特别是在资源有限的设备上进行有效学习的需求。
主要思想
传统的持续学习方法通常依赖于存储先前任务的样本,并定期用这些样本来重新训练模型,以避免灾难性遗忘。然而,这种方法在处理大规模数据集或在资源有限的设备上时可能不太实用。《Latent Replay for Real-Time Continual Learning》论文中提出的潜在重放方法,旨在通过在网络的中间层存储和重放激活(而不是原始数据),来解决这一问题。
方法
- 潜在表示的存储和重放:潜在重放的核心是存储网络在训练过程中中间层的激活(即潜在表示),而非原始训练样本。当需要进行重放时,可以直接使用这些潜在表示,而无需重新处理整个原始输入。
- 减少存储需求:由于潜在表示通常比原始输入数据小得多,这种方法显著减少了存储需求,使得在资源受限的环境中实现持续学习变得可行。
- 实时更新:潜在重放支持在实时数据流的情况下进行学习,允许模型不断适应新数据,同时保持对先前学习任务的记忆。
- 有效应对遗忘问题:通过重放选定的潜在表示,模型可以有效地维持其在之前任务上的性能,减少遗忘。
结论
《Latent Replay for Real-Time Continual Learning》通过引入潜在重放的概念,为实时持续学习提供了一种高效且节省资源的方法。这种方法特别适用于那些需要在资源有限的环境中连续学习和适应的应用,例如移动设备或边缘计算设备上的应用。此外,它也为理解和设计更加高效的持续学习算法提供了新的思路。
Generative Replay
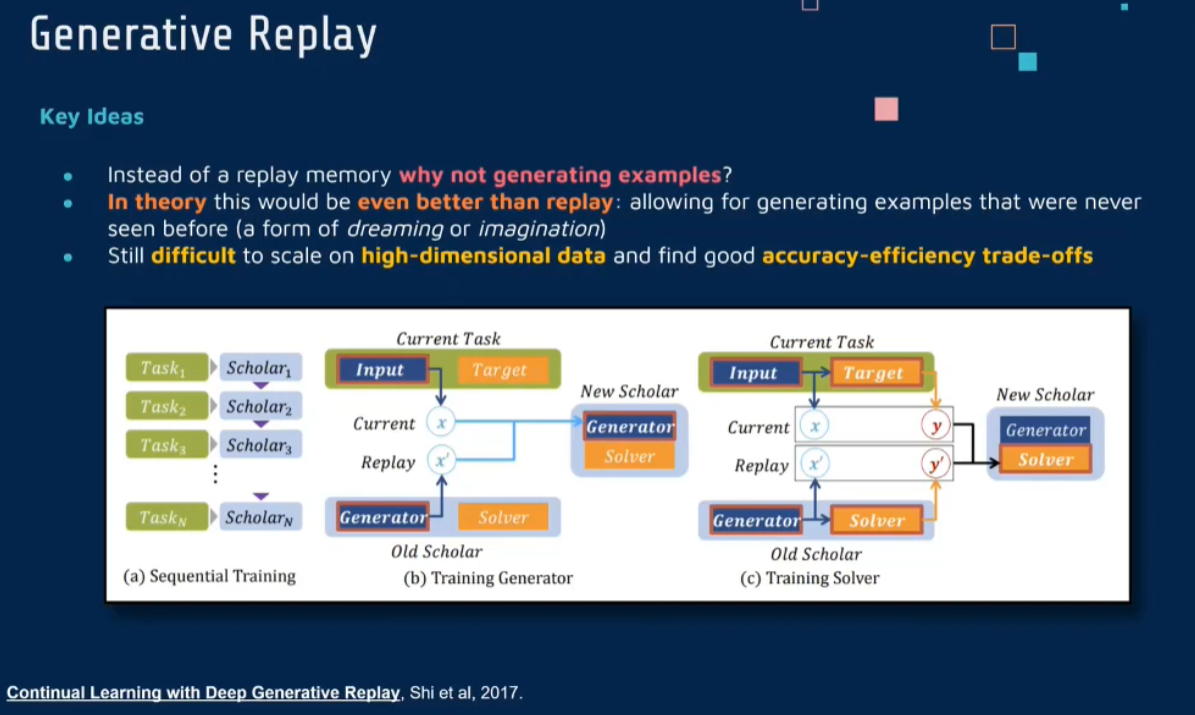
learn a generator may better than from history data
Continual Learning with Deep Generative Replay (neurips.cc)
《Continual Learning with Deep Generative Replay》这篇论文介绍了一种创新的持续学习方法,称为深度生成重放(Deep Generative Replay)。这种方法通过结合生成模型与传统的神经网络,旨在解决持续学习过程中的灾难性遗忘问题。
主要思想
在持续学习的背景下,一个主要挑战是当模型连续学习新任务时,它往往会忘记先前学习的任务。这被称为灾难性遗忘。深度生成重放通过使用生成模型来重放之前学习过的数据,从而帮助网络保留先前任务的知识。
方法
使用生成模型重放数据:该方法的核心是使用生成模型(如生成对抗网络(GAN)或变分自编码器(VAE))来生成旧任务的数据。这些人工生成的数据随后用于训练网络,以防止遗忘。
混合真实与生成数据:在训练过程中,生成的数据与新任务的真实数据一起使用,帮助模型在学习新任务的同时保留对旧任务的记忆。
动态更新生成模型:随着模型学习新任务,生成模型也会相应更新,以确保它可以生成代表性足够且多样化的旧任务数据。
减轻灾难性遗忘:通过这种方式,深度生成重放显著减少了灾难性遗忘,因为它允许模型在学习新信息的同时,通过重放机制保持对过去学习的信息的访问。
结论
《Continual Learning with Deep Generative Replay》提出的深度生成重放是一个有前景的方法,它通过智能结合生成模型和传统的神经网络,为持续学习中的灾难性遗忘问题提供了一个有效的解决方案。这种方法特别适合于那些需要在长期内不断适应新任务,同时保持对历史数据记忆的应用场景。
3 正则化
生物学基础
在神经科学理论模型中,通过具有不同可塑性水平级联状态的触突刺激,来保护巩固学习的知识不被遗忘&受到这一机制的启发,从计算系统的角度来看,可以通过对模型施加正则化约束来避免遗忘。通过正则化方法在模型权重更新时加强约束,以此在保持已有知识的前提下实现对新任务的学习 。
History
分类
Learning without forgetting (LWF)
该方法将知识蒸馏与finetune相结合,利用知识蒸馏策略来避免对之前知识的遗忘.
目标是为一个新任务增加一个任务特定的参数并且只利用新的数据和标签(不使用已经存在任务的标签数据)对特定的任务参数进行学习,使得它能够对新的任务和之 前 的任务都有好的预测效果.

核心摘要
LwF(Learning without Forgetting) 是Incremental Learning领域早期发表的一篇文章,论文的核心要点包括
- 除了LwF本身外,还提出了Fine-tunine, Feature Extraction, Joint Training三种基本的对比方法,并对不同方法进行了分析与实验对比。
- 提出了使用知识蒸馏(Knowledge Distillation)的方法提供旧类的“软监督”信息来缓解灾难性遗忘的问题。并且发现,这种监督信息即使没有旧类的数据仍然能够很大程度上提高旧类的准确率。
- 对参数偏移的正则惩罚系数、正则形式、模型拓展方式等等因素进行了基本的实验对比。(不过具论文中结果这些因素的影响并不明显)。
方法比较
如图中所示
- (a) 中为传统的多分类模型,它接受一张图片,然后通过线性变换、非线性激活函数、卷积、池化等运算操作符输出该图片在各个类别上的概率,。
- (b) 中为Fine-tuning方法,即训练新类时,我们保持旧的分类器不变,直接训练前面的特征提取器和新的分类器权重。
- (c) 称为Feature Extraction,保持特征提取器不变,保持旧的分类器权重不变,只训练新的任务对应的参数。
- (d) 中为Joint Training的方法,它在每个训练任务时刻都同时接受所有的训练数据进行训练。
- (e) 中为LwF方法,他在Fine-tuning的基础上,为旧类通过知识蒸馏提供了一种“软”监督信息。
训练流程
对于新的任务的训练集,LwF的损失函数包括:
- 新类的标签监督信息:即新类对应的logits与标签的交叉熵损失(KL散度)
- 旧类的知识蒸馏:新旧模型在旧类上的的logits的交叉熵损失(包含温度系数:设置温度系数大于一,来增强模型对于类别相似性的编码能力)
- 参数偏移正则项,对于新模型参数关于旧模型参数偏移的正则项。
具体的伪代码如下:

结论
LwF通过巧妙地结合新任务学习和旧任务知识保持,提供了一种有效的持续学习策略。这种方法特别适合于那些需要在不断进化的数据流上训练模型,同时又不能访问旧数据的场景。通过减少灾难性遗忘,LwF能够帮助模型在长期内持续有效地学习。
Elastic Weight Consolidation (EWC)
一种结合监督学习和强化学习方法,即弹性权重整合方法.在提出的模型目标函数中,包括了对新旧任务之间模型参数的惩罚项,从而有效缓解对先前学习的知识中与当下任务相关知识遗忘

| [Overcoming catastrophic forgetting in neural networks | PNAS](https://www.pnas.org/doi/abs/10.1073/pnas.1611835114) |
《Overcoming Catastrophic Forgetting in Neural Networks》这篇论文由Kirkpatrick等人撰写,提出了一种名为“弹性权重整合”(Elastic Weight Consolidation, EWC)的方法,用于解决神经网络在持续学习过程中面临的灾难性遗忘问题。
主要思想
灾难性遗忘是指神经网络在学习新任务时忘记之前学习过的任务的现象。这个问题在持续学习场景中尤为突出,因为持续学习要求模型能够不断适应新的数据或任务,而不丧失对旧任务的记忆。EWC的核心思想是在训练过程中对网络参数施加额外的约束,以保护对先前任务关键的知识,从而减少在学习新任务时对旧任务的遗忘。
方法
权重的重要性:EWC方法通过计算每个权重对先前任务性能的贡献来确定其重要性。重要性高的权重在学习新任务时变化较小,以此保持对旧任务的记忆。
损失函数修改:EWC引入了一种修改后的损失函数,其中包含了一个额外的项,用于平衡新任务的学习和对旧任务知识的保护。这个额外的项是一个正则化项,它基于权重的重要性对权重的改变施加惩罚。
计算权重的重要性:在完成一个任务的学习后,该方法计算损失函数对每个权重的二阶导数,即Fisher信息,来估计每个权重的重要性。
训练过程:在训练新任务时,EWC通过结合原始的损失函数和正则化项来调整权重,确保模型在适应新任务的同时不会显著影响旧任务的性能。
结论
EWC通过一种巧妙的正则化方法解决了神经网络在持续学习过程中的灾难性遗忘问题。这种方法特别适用于需要模型连续学习多个任务,同时保持对每个任务知识的场景。EWC的引入代表了在持续学习领域向更加高效和实用的解决方案迈进的重要一步。
Synaptic Intellgence (SI)
一种在线计算权重重要性的方法,即训练时根据各参数对损失贡献的大小来动态地改变参数的权重,如果参数对损失的贡 献越大,则说明该参数越重要

Continual Learning Through Synaptic Intelligence (mlr.press)
Continuous learning in single-incremental-task scenarios - ScienceDirect
Synaptic Intelligence
《Continual Learning Through Synaptic Intelligence》这篇论文提出了一种称为“突触智能”(Synaptic Intelligence, SI)的方法,专门用于应对持续学习中的灾难性遗忘问题。这种方法的核心思想是量化每个突触(即神经网络中的权重)对于学习任务的重要性,并据此调整其在后续学习过程中的可变性。
主要思想
突触智能的基本思想是,网络中的每个突触都对任务学习有不同程度的贡献。有些突触对某些任务至关重要,而其他突触可能对学习的影响较小。因此,通过识别并保护那些对已学习任务至关重要的突触,可以在学习新任务时减少对旧任务的遗忘。
方法
- 突触重要性的计算:在学习过程中,SI方法计算每个突触的“重要性”,这是通过评估其在任务学习过程中的累积贡献来实现的。具体而言,这涉及到计算突触权重变化与损失函数改善之间的关系。
- 保护重要突触:在学习新任务时,那些被识别为重要的突触的变化会受到限制。这意味着这些突触的权重将在一定程度上被“冻结”,从而保留对以前任务的记忆。
- 灵活的学习过程:对于那些被认为不那么重要的突触,模型可以自由地调整它们的权重来适应新的任务。这确保了模型在保持对过去知识的同时,仍具有学习新任务的灵活性。
- 无需旧任务数据:与一些其他持续学习方法不同,SI不需要存储或重访旧任务的数据集,这使得它在处理大量数据或面临数据隐私问题时更具优势。
结论
突触智能方法通过在保护重要突触和灵活适应新任务之间找到平衡,为解决持续学习中的灾难性遗忘问题提供了一个有效的途径。这种方法特别适合于需要处理连续数据流的应用,如在线学习和实时数据处理,同时也适用于资源受限的环
Hypernetworks
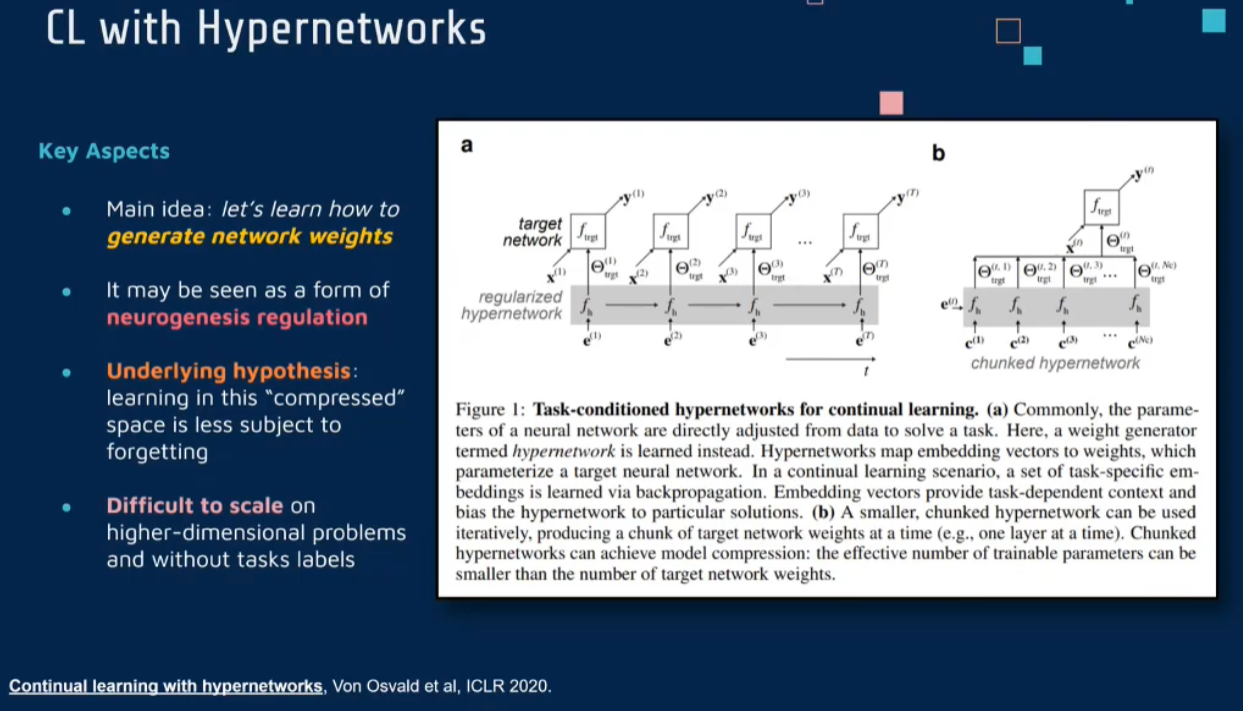
[1906.00695] Continual learning with hypernetworks (arxiv.org)
《Continual Learning with Hypernetworks》这篇论文提出了一种利用超网络(Hypernetworks)进行持续学习的方法。这种方法旨在解决传统神经网络在持续学习过程中面临的灾难性遗忘问题,同时尝试提供一种更灵活和高效的学习机制。
主要思想
传统的持续学习方法通常依赖于修改网络的权重或结构来适应新的任务,这往往导致对旧任务的知识遗忘。在《Continual Learning with Hypernetworks》中,作者提出了使用超网络来生成主网络的权重。超网络是一种特殊类型的神经网络,它的输出是另一个神经网络(称为主网络)的权重。这种方法允许模型在不同任务间更有效地切换,从而减少遗忘。
方法
超网络架构:在这个系统中,有两个关键组件——主网络和超网络。主网络负责执行特定的任务(如分类),而超网络则生成主网络的权重。
任务特定权重生成:对于每个新任务,超网络会生成一组新的权重,用于配置主网络。这些权重是针对当前任务特别优化的,使得主网络能够有效地学习新任务。
减少遗忘:通过为每个任务生成独特的权重集,这种方法减少了新任务学习对旧任务知识的干扰。当需要执行一个旧任务时,超网络可以重新生成适用于那个特定任务的权重。
灵活性和效率:这种方法提供了一种更灵活和高效的方式来处理多任务学习的问题。超网络的使用使得在不同任务间切换变得更加简单和高效。
结论
《Continual Learning with Hypernetworks》中提出的方法为持续学习提供了一个创新的视角,通过使用超网络生成主网络权重来减少灾难性遗忘。这种方法在处理需要快速适应新任务的场景时特别有用,同时也为设计更高效和灵活的持续学习模型提供了新的可能性。
总结

4 动态结构 Architectural Strategies
Multi-Head
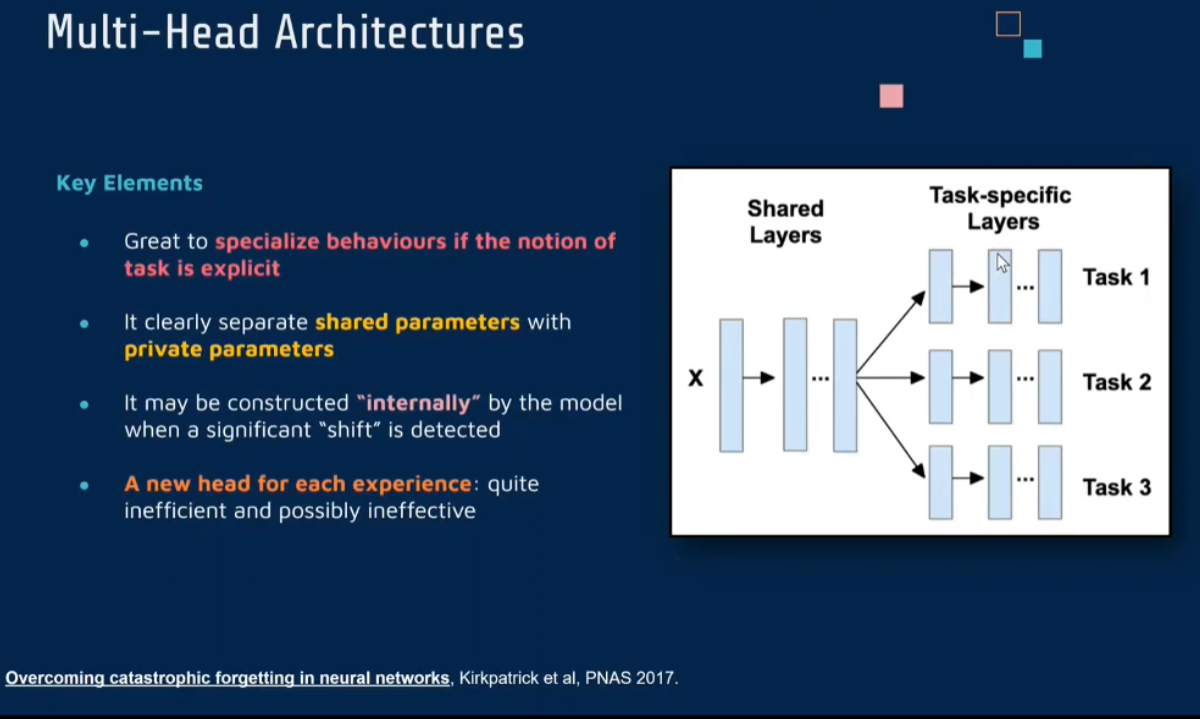
Overcoming catastrophic forgetting in neural networks
| [Overcoming catastrophic forgetting in neural networks | PNAS](https://www.pnas.org/doi/abs/10.1073/pnas.1611835114) |
Copy Weights with Re-Init (CWR)
一 种使用重新初始化复制权重的连续学习方法,该方法可以作为一种基准技术来实现对连续任务的识别

Progressive Neural Networks (PNNs)
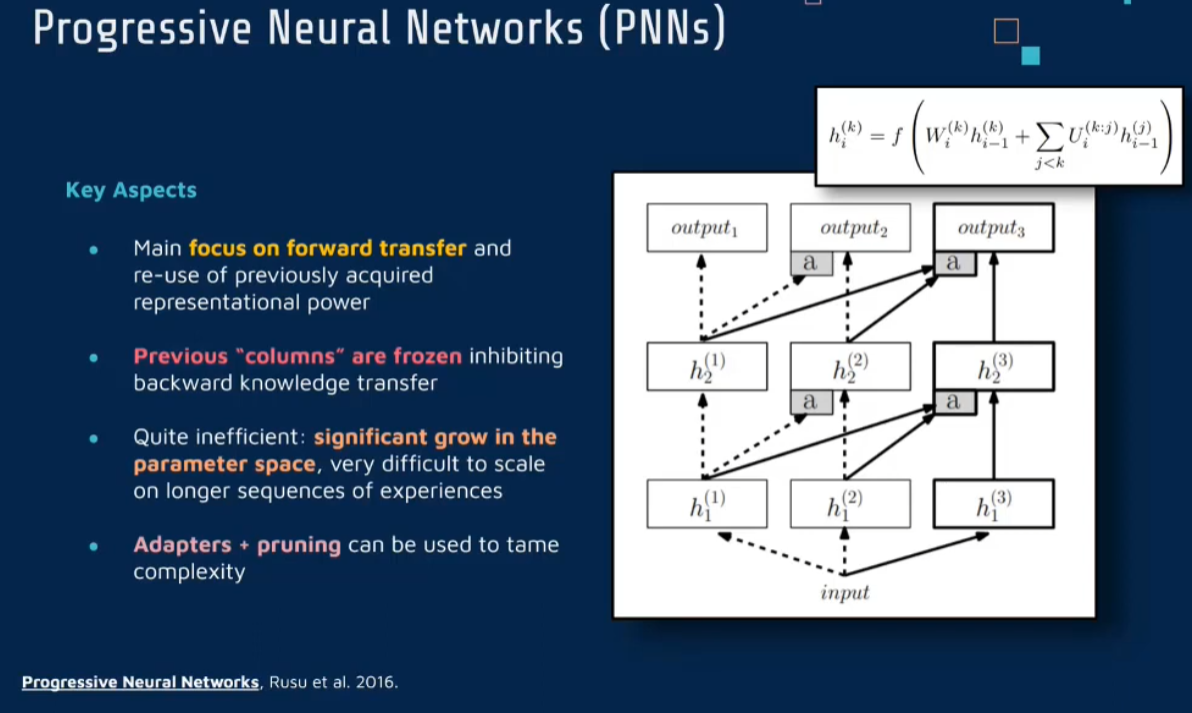
通过分 配 具有 固 定 容 量 的 新子网络来防止对已学习知识的遗忘,这种通过分配具有固定容量的新子网来扩展模型的结构,称为渐进式网络方法,该方法保留了一个预先训练的模型,也就是说,该模型为每个学习任务$t$都对应一个子模型.
给定现有的$T$个任务时,当面对新的任务$t+1$时,模型将直接创建一个新的神经网络并与学习的现有任务的模型进行横向连接.为避免模型灾难性的遗忘,当对新的任务$t+1$的参数$\theta^{t+1}$进行学习时,将保持已经存在的任务$t$的参数$\theta^t$不变.
[1606.04671] Progressive Neural Networks (arxiv.org)
《Progressive Neural Networks》这篇论文提出了一种新的神经网络架构,名为渐进式神经网络(Progressive Neural Networks)。这种架构旨在解决持续学习中的两个关键问题:灾难性遗忘和参数效率性。
主要思想
渐进式神经网络的核心思想是在学习每个新任务时增加额外的网络模块,而不是在单一固定结构的网络上训练所有任务。这样做的目的是为每个新任务保留一个专门的网络结构,同时通过连接这些结构来转移以前任务的知识,从而避免了在学习新任务时遗忘旧任务的知识。
方法
独立的列结构:对于每个新任务,渐进式神经网络会新增一个网络列。每个列由一系列层组成,专门用于学习当前任务。
知识转移:虽然为每个任务创建了独立的列,但这些列之间不是完全隔离的。为了利用之前任务的知识,网络会在列之间建立横向连接。这些连接允许来自旧列的特征被用于新任务的学习,促进知识的转移和共享。
避免灾难性遗忘:由于每个任务都有自己独立的网络列,因此在学习新任务时,旧任务的网络参数保持不变,这自然避免了灾难性遗忘。
参数效率性:渐进式神经网络通过在任务间共享知识来提高参数效率性,尽管每个任务都有自己的专属网络列,但共享的特征表示和横向连接帮助减少了总体参数数量的需求。
结论
《Progressive Neural Networks》中提出的渐进式神经网络为持续学习提供了一种新的架构解决方案。通过为每个新任务增加独立的网络列,并通过横向连接共享知识,这种架构有效地解决了灾难性遗忘问题,并在一定程度上提高了参数效率性。这种方法特别适用于需要模型依次学习多个不同任务,同时保持对以前任务的记忆的应用场景。
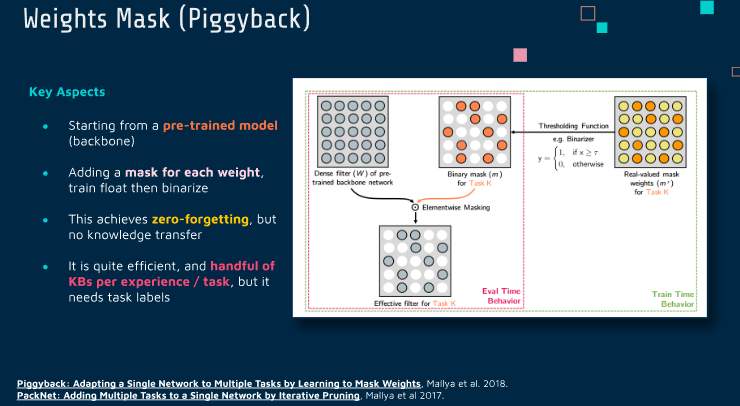
Weights Mask (Piggyback)
Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights.
ECCV 2018 Open Access Repository (thecvf.com)
PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning.
CVPR 2018 Open Access Repository (thecvf.com)
《Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights》这篇论文提出了一种名为“Piggyback”的方法,它旨在解决如何使用单个神经网络高效地处理多个任务的问题,特别是在资源有限的环境中。
主要思想
Piggyback的核心思想是对一个预先训练的网络(通常是在一个大型数据集上训练的,如ImageNet)进行调整,使其能够在不同的任务上表现良好,而无需从头开始训练多个独立的网络。这通过学习每个任务特定的权重掩码来实现,这些掩码决定了原始网络中哪些权重会被用于给定的任务。
方法
预训练的基础网络:首先,需要一个在大型数据集上预训练的基础网络。这个网络的权重在后续过程中不会改变。
任务特定的权重掩码:对于每个新任务,Piggyback方法学习一个权重掩码。这个掩码是一个与网络权重同形状的二值(通常是0或1)数组,它决定了在特定任务上哪些原始权重是激活的。
训练掩码:在学习新任务时,不是更新网络的权重,而是仅仅更新这个任务的权重掩码。通过这种方式,网络可以重新配置自己,以适应新任务,同时保持原始权重不变。
资源高效:这种方法特别适合于资源受限的情况,如移动设备或嵌入式系统,因为它允许多个任务共享同一个网络的权重,而不需要存储和计算多个网络的权重。
结论
《Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights》提出的方法通过在单个预训练网络上使用任务特定的权重掩码,实现了高效的多任务学习。这种方法避免了为每个任务训练独立网络的需要,同时减少了存储和计算资源的消耗。这对于需要在资源有限的设备上部署多任务学习模型的应用来说,是一个非常有价值的解决方案。
Hard Attention to the Task (HAT)
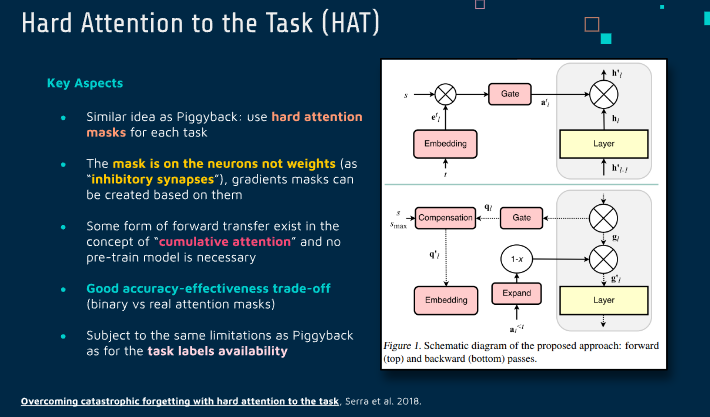
Overcoming catastrophic forgetting with hard attention to the task
Overcoming Catastrophic Forgetting with Hard Attention to the Task (mlr.press)
《Overcoming Catastrophic Forgetting with Hard Attention to the Task》这篇论文提出了一种基于硬注意力机制的方法,用于解决神经网络在持续学习过程中的灾难性遗忘问题。
主要思想
这项研究的核心思想是使用硬注意力机制来动态地选择网络中的一部分来处理特定任务,从而减少在学习新任务时对先前任务知识的遗忘。硬注意力机制在这里指的是一种二元选择过程,它决定了神经网络的哪些部分应该被激活用于当前的任务。
方法
任务特定的子网络:对于每个任务,方法会确定一个专用的子网络,这个子网络由原始网络的一个子集组成。通过专门用于当前任务的子网络,可以减少对其他任务学习的干扰。
硬注意力掩码:为了选择这个子网络,使用了硬注意力机制,即通过学习一个掩码来选择网络中的哪些部分对当前任务是重要的。这个掩码是二元的,即它决定了每个神经元是否对当前任务有效。
训练过程:在训练期间,除了学习任务特定的输出外,还需要学习用于每个任务的硬注意力掩码。这意味着网络需要学习如何为每个新任务选择合适的子网络。
减少遗忘:通过这种方式,每个任务都有一个专门的、优化的网络区域,这减少了在学习新任务时对先前任务知识的遗忘。
结论
这篇论文提出的基于硬注意力的方法为解决持续学习中的灾难性遗忘问题提供了一个新颖的视角。通过为每个任务动态选择专用的子网络,它不仅减少了遗忘,而且提高了学习的效率。这种方法特别适合于需要处理多任务学习且资源有限的应用场景。
Supermasks in Superimposition
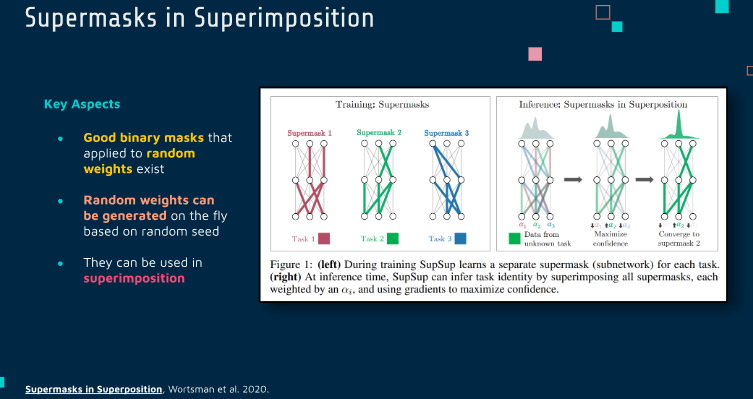
Supermasks in Superposition,
Supermasks in Superposition (neurips.cc)
《Supermasks in Superposition》这篇论文介绍了一种新颖的神经网络训练方法,它基于一种称为“超级掩码”(Supermasks)的概念。这种方法的核心思想是在单个固定的、随机初始化的神经网络中通过叠加不同的掩码来实现多个任务的学习,而不是改变网络的权重。
主要思想
传统的神经网络训练涉及调整网络权重以适应不同的任务。与之相反,这篇论文提出的方法不改变权重,而是使用一系列的掩码来“激活”或“抑制”网络中的特定连接。这些掩码被称为超级掩码。关键的创新点是同时使用多个这样的掩码,每个掩码对应一个特定的任务,而这些掩码共同作用于同一个未经训练的随机权重网络。
方法
固定的随机权重网络:首先,创建一个具有固定随机权重的神经网络。这些权重在整个训练和应用过程中保持不变。
任务特定的超级掩码:对于每个任务,学习一个超级掩码。这个掩码决定了在处理特定任务时哪些网络连接是激活的。实质上,掩码决定了网络的哪些部分被用于当前任务。
掩码的叠加:在处理多任务学习时,可以通过叠加多个超级掩码来实现。这意味着网络可以同时处理多个任务,每个任务使用不同的掩码配置。
训练和应用:尽管网络的权重是固定的,但通过调整掩码来优化网络的性能。这种方法的训练涉及找到最优的掩码配置,以最大化网络在各个任务上的性能。
结论
《Supermasks in Superposition》这篇论文提出的方法是对神经网络训练和持续学习范式的一种根本性改变。通过在一个固定的网络上使用多个任务特定的掩码,这种方法能够有效地同时处理多个任务,同时避免了传统方法中的权重调整和灾难性遗忘问题。这为多任务学习和神经网络的适应性提供了新的可能性。
总结

5 Hybrid strategy
Why
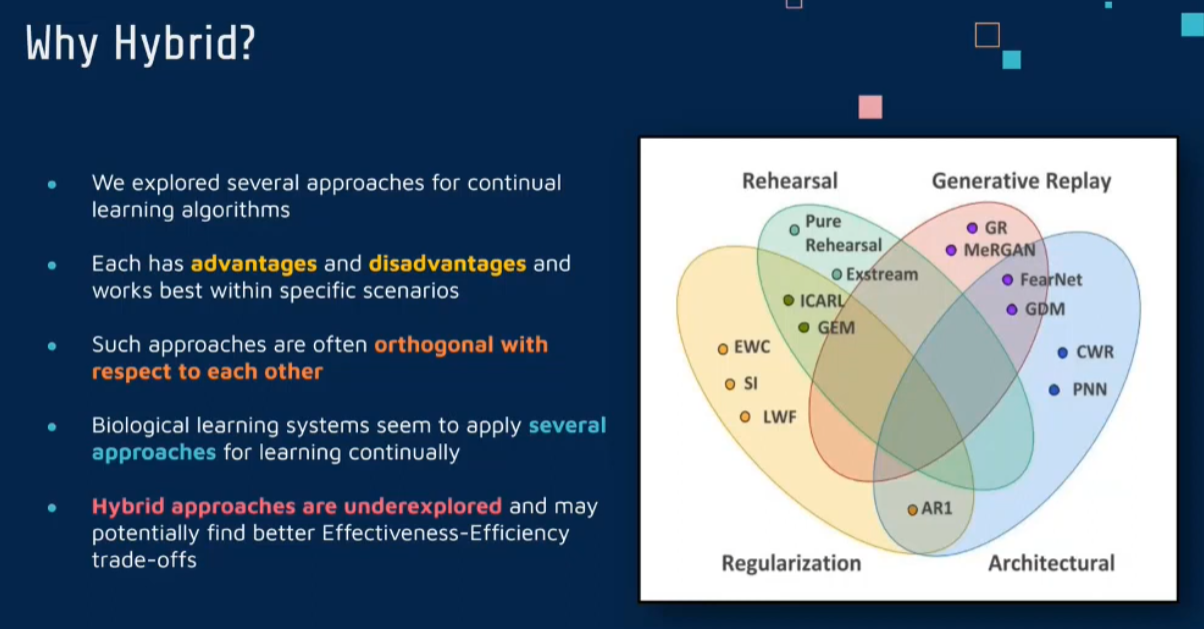
Gradient Episode Momory
该 模 型 能够实现知识正向迁移到先前任务的功能,以及将先前任务学习的知识正向地迁移到当前任务上.
模型最主要的特征是为每个任务存储一个情景记忆模型来避免灾难性遗忘.该 模 型 不 仅 能 够最小化当前任务的损失,而且可以将任务D情景记忆模型的损失作为不等式约束来避免损失函数的增加,但允许损失函数的减少

Gradient Episodic Memory for Continual Learning
Gradient Episodic Memory for Continual Learning (neurips.cc)
《Gradient Episodic Memory for Continual Learning》这篇论文介绍了一种用于持续学习的新方法,名为梯度情景记忆(Gradient Episodic Memory, GEM)。GEM旨在解决神经网络在持续学习过程中遇到的灾难性遗忘问题。
主要思想
梯度情景记忆的核心思想是在神经网络训练过程中保存一些先前任务的样本,并使用这些样本来约束新任务学习中的权重更新,从而避免对先前学习任务的遗忘。这是通过确保新任务的权重更新不会恶化先前任务的性能来实现的。
方法
情景记忆的存储:对于每个学习的任务,GEM会在一个情景记忆库中存储一组代表性样本。这些样本代表了网络在该任务上学习的知识。
梯度约束:当网络开始学习一个新任务时,它会计算新任务的梯度,并与存储在情景记忆中的每个旧任务的梯度进行比较。目标是确保新任务的梯度更新不会使任何旧任务的性能下降。
优化过程调整:如果新任务的梯度更新有可能恶化旧任务的性能,GEM会调整优化过程,以找到一个折中方案,即既可以提升新任务的学习,又不会显著损害旧任务的性能。
避免灾难性遗忘:通过这种方式,GEM能够在学习新任务时保护已经学习的任务的性能,从而有效地避免灾难性遗忘。
结论
《Gradient Episodic Memory for Continual Learning》提出的GEM方法为神经网络在持续学习过程中的灾难性遗忘问题提供了一个创新的解决方案。通过使用情景记忆来指导新任务的梯度更新,GEM不仅提高了网络对新任务的学习效率,而且保护了网络对先前任务的记忆,这对于需要持续学习和适应新任务的应用场景尤为重要。
- get access to a particular example x y um related to a particular task t so that in the end you have a triple x y t y
- have a kind of a separate memory for each task
- the gradient sorry for the current loss after have computed a particularly a particular gradient for the loss to minimize on the current training
- the gradient for the previous loss compute the gradient with respect to the same loss function computed with the current mapping function f of θ favorite theta on the examples related to all the previous tasks that 我们 favorite we have stored in our memory
- coming up with a new gradient not allow for an increase in the loss on the previous task allow for learning the new task but without interfering in the previous task
- operate the update uh to the weight
- evaluation of those mapping of this mapping function overtime computing our
Evaluation
- looping over all the possible evaluation examples and computing the average of the accuracy over time
Incremantal Classifier and Representation Learning (iCaRL)

iCaRL: Incremental Classifier and Representation Learning
CVPR 2017 Open Access Repository (thecvf.com)
《iCaRL: Incremental Classifier and Representation Learning》这篇论文介绍了一种名为iCaRL(增量分类器和表示学习)的持续学习方法。iCaRL的目标是有效地处理新类的学习,同时保留对之前类的记忆,尤其是在类别数量逐渐增加的情况下。
主要思想
iCaRL的核心思想是结合了表示学习(即特征提取)和分类器学习,以适应新类别的出现,同时减少对旧类别的遗忘。这是通过维护一个有限大小的代表性样本集合(称为记忆集)和利用这些样本来更新网络表示和分类器来实现的。
方法
表示学习:随着新类别的引入,网络的表示(即特征提取部分)被更新以包含对新类别的信息。这是通过在新旧类别的样本上训练网络来实现的。
记忆集:iCaRL维护一个有限大小的记忆集,存储每个类别的一些代表性样本。这个集合在新类别数据到来时更新,并用于帮助网络记住旧类别的信息。
增量学习:每当引入新类别时,iCaRL不仅在新类别上训练网络,还在记忆集中的旧类别样本上重新训练,以减少遗忘。
基于近邻的分类器:iCaRL使用基于近邻的方法作为其分类器。在分类新样本时,它比较样本的特征表示与记忆集中样本的特征表示,并根据最近的邻居做出分类决策。
样本选择策略:由于记忆集的大小是有限的,因此iCaRL实施了一种样本选择策略,以保持记忆集中样本的多样性和代表性。
结论
iCaRL为持续学习中的类别增量问题提供了一个有效的解决方案,通过结合表示学习和增量分类器更新,并通过维护一个有限大小的代表性样本集合来减少遗忘。这使得iCaRL特别适用于类别数逐渐增加的应用场景,如逐步学习新类别的图像识别任务。
核心摘要
iCaRL可以视为Class-Incremental Learning方向许多工作的基石。文章的主要贡献包括:
给Class-Incremental Learning的设定一个规范的定义:
- 模型需要在一个新的类别不断出现的流式数据中进行训练。
- 模型在任意阶段,都应该能够对目前见到的所有类别进行准确的分类。
- 模型的计算消耗和存储消耗必须设置一个上界或者只会随着任务数量缓慢增长。
第一次阐明了我们可以在将来的训练阶段保留一部分典型的旧类数据,这极大地提高了模型能够实现的准确率上限,并提出了一种有效的典型样本挑选策略herding:贪心的选择能够使得exemplar set 的特征均值距离总的均值最近的样本。

- 提出了使用保留的旧类数据来进行nearest-mean-of-exemplars的分类方式,而非直接使用训练阶段的到的线性分类器。这是因为使用交叉熵损失函数在不平衡的数据集上直接进行训练,很容易出现较大的分类器的偏执。而模型提取的特征则能够很大程度上缓解这个问题。
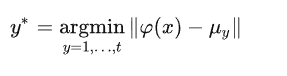
训练流程
当新的任务到来时:
- 将新来的类别数据集与保留的旧类数据的exemplar set合并得到当前轮的数据集。
- 使用sigmoid将模型输出的logits转化为0-1之间。将目标标签转化为one-hot向量表示。
- 对于新类的分类,我们使用binary cross entropy来计算损失。这里的binary cross entropy的计算仅仅考虑了所有的新的类别的计算,这种方式能够使得我们在学习新的样本的时候,不会更新旧的线性分类器中的权重向量,从而减少不均衡的数据流对样本分类的影响。
- 对于旧类的分类,则仿照LwF的模式,计算新旧模型在旧类上的概率输出的binary cross entropy的损失来训练模型。

iCaRL对后来的方法的影响颇深。在此之后,相当数量的类别增量学习方法都仿照这一范式。创建一个exemplar set来存储典型的旧类样本。使用知识蒸馏来提供旧类的监督信息。
Progress Compress PC
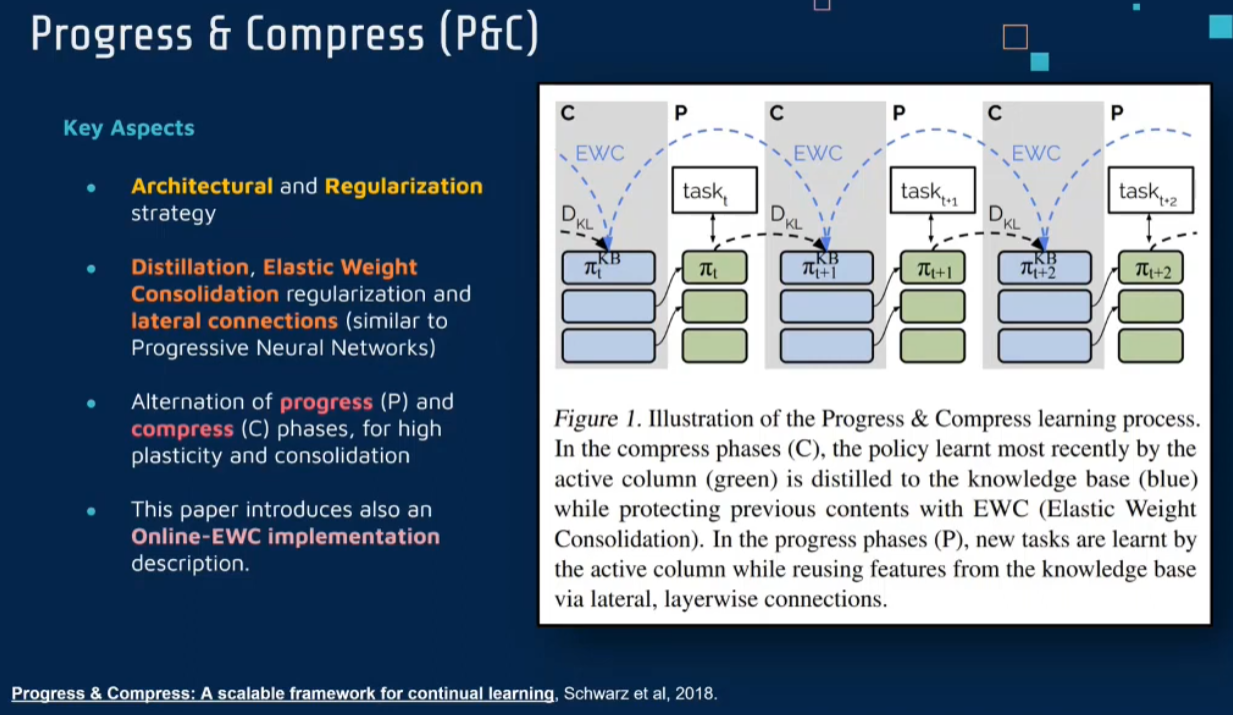
Progress & Compress: A scalable framework for continual learning
Progress & Compress: A scalable framework for continual learning (mlr.press)
AR1 : a Flexible Hybrid Strategy
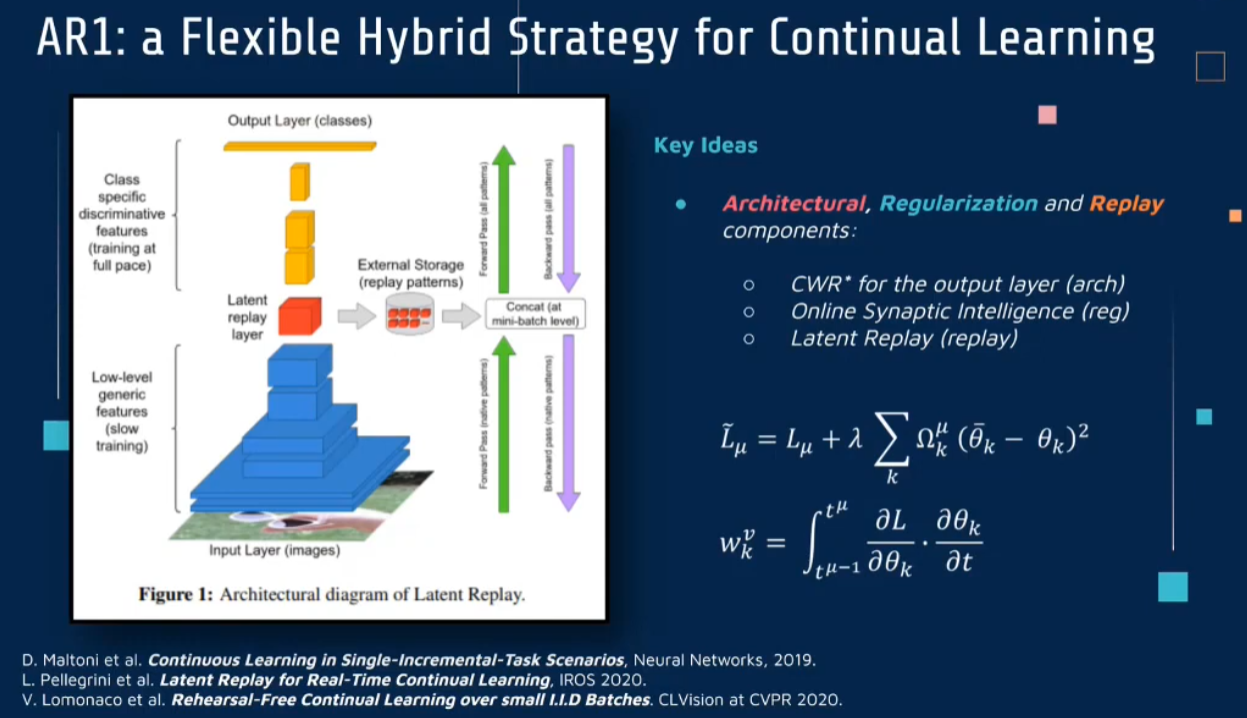
AR1: a Flexible Hybrid Strategy for Continual Learning
Generative Negaive Replay
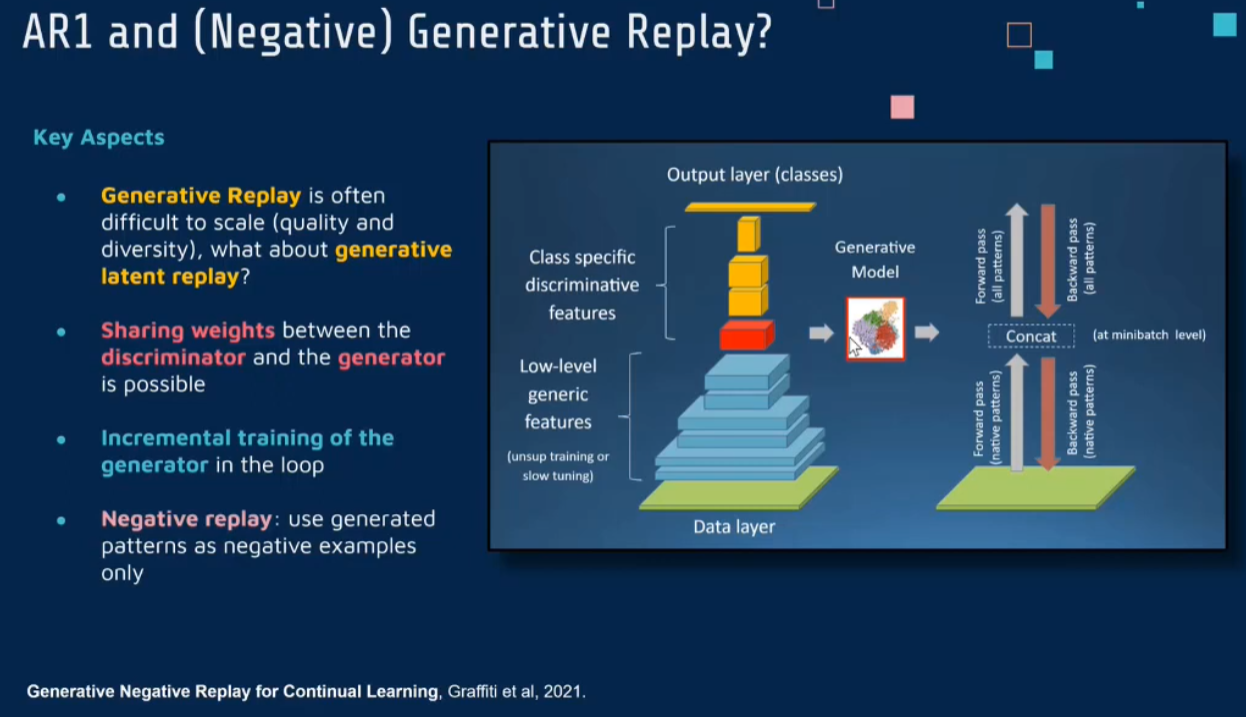
Generative negative replay for continual learning
Generative negative replay for continual learning - ScienceDirect
《Generative Negative Replay for Continual Learning》这篇论文提出了一种新颖的持续学习方法,名为生成性负重放(Generative Negative Replay)。该方法旨在通过生成和使用负样本来减轻神经网络在持续学习过程中遇到的灾难性遗忘问题。
主要思想
传统的持续学习方法,如重放(Replay)或生成重放(Generative Replay),通常侧重于重现正样本(即先前学习过的数据)。相比之下,生成性负重放的核心思想是除了重放正样本外,还生成并使用负样本(即与已学习任务不相关或相反的样本)。这样做的目的是增强网络对不同任务之间区分的能力,从而减少新任务学习对旧任务知识的干扰。
方法
生成负样本:使用生成模型(如生成对抗网络GAN)来生成与已学习任务不相关或对立的负样本。这些负样本被设计为与现有任务相区别,从而帮助网络更好地区分不同的任务。
混合重放:在训练过程中,将这些生成的负样本与正样本(即先前任务的数据)一起使用。通过这种混合重放,网络不仅学习如何识别新任务的特征,还学习如何区分旧任务和新任务。
优化分类边界:通过在正样本和负样本之间建立更清晰的分类边界,该方法有助于优化网络的决策边界,从而提高区分不同任务的能力。
减少任务间干扰:这种方法特别注重减少任务间的干扰,即使得网络在学习新任务的同时,减少对已经学习任务的遗忘。
结论
《Generative Negative Replay for Continual Learning》提出的生成性负重放方法为持续学习中的灾难性遗忘问题提供了一个新的视角。通过引入生成的负样本来增强网络区分不同任务的能力,这种方法有望提高持续学习的效率和效果,尤其是在任务之间有明显区分的情况下。
总结

文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/01/12/ContinualLearning-2-Methods/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)