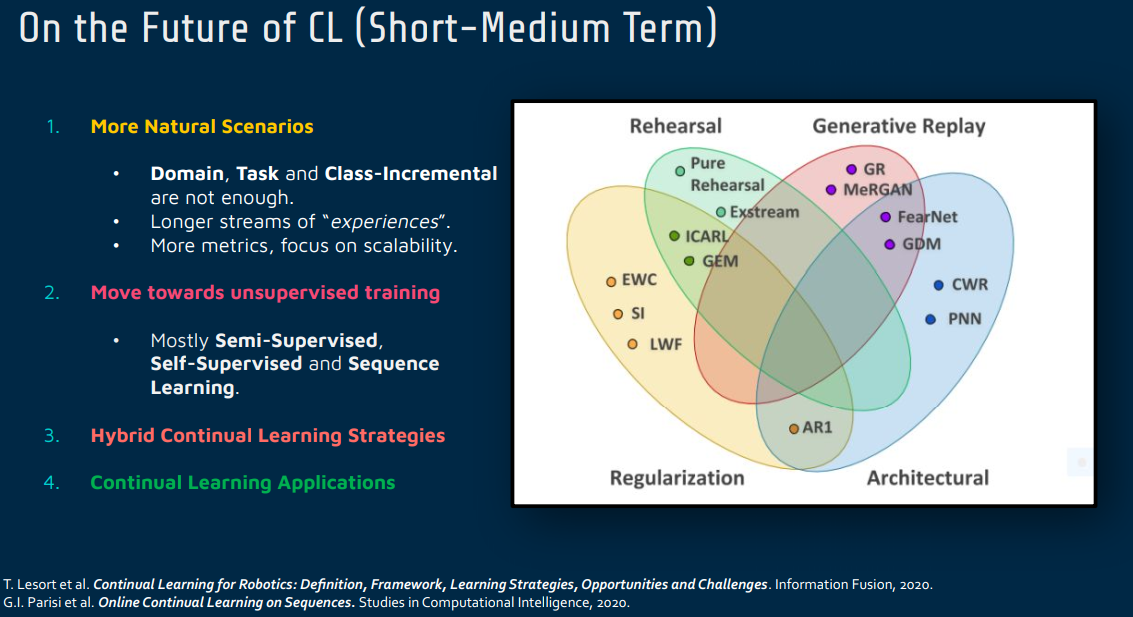
Continual Learning 3 Future Direction
Meta Learning & Continual Learning
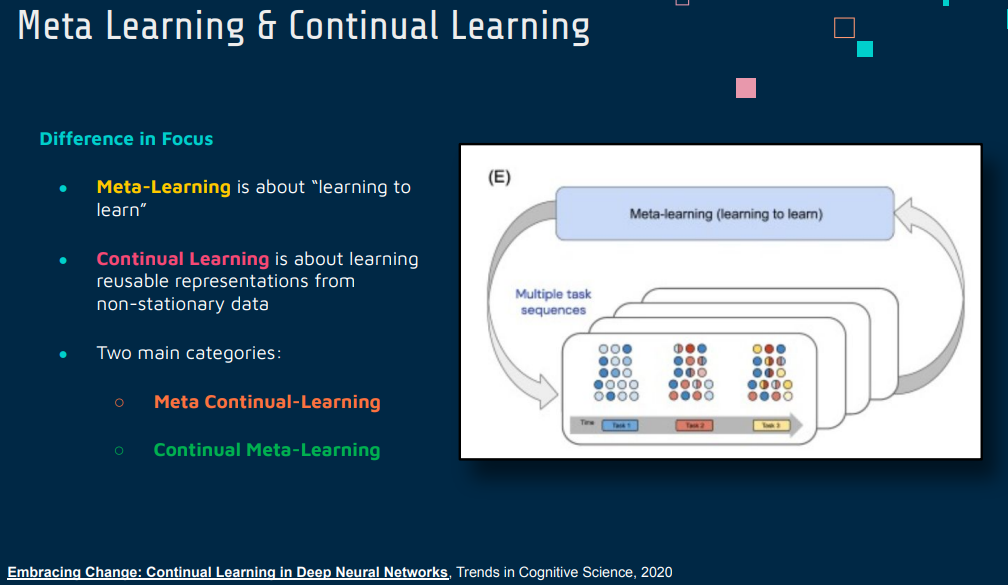
Continual Learning(持续学习)和 Meta Learning(元学习)是两个在机器学习领域中的重要概念,它们各自具有独特的目标和方法,尽管它们之间有一定的交叉。
Continual Learning(持续学习)
持续学习,也称为增量学习或生命周期学习,指的是一种能力,使得机器学习模型可以不断适应新的数据或任务,而不会忘记之前学到的知识。这个领域的主要挑战是解决“灾难性遗忘”问题,即新学习的任务会干扰和覆盖模型之前学习的知识。
- 目标:持续学习的主要目标是使模型能够适应新信息,同时保持对旧信息的记忆。
- 方法:常见的方法包括使用经验重放、正则化策略、动态网络扩展等技术来保持先前任务的知识。
Meta Learning(元学习)
元学习,有时被称为“学习如何学习”,指的是一种能力,使得机器学习模型可以通过学习一系列不同的任务来提高其在新任务上的学习效率和效果。元学习主要关注于快速适应新任务,通常是在只有少量数据的情况下。
- 目标:元学习的目标是使模型能够从少量的数据中迅速学习新任务或适应新环境。
- 方法:常见的方法包括学习一个能够调整其他模型参数的“元模型”,或者优化模型的初始参数,以便在新任务上快速调整。
区别
- 焦点差异:持续学习关注于如何保持旧知识并逐步积累新知识,而元学习关注于快速掌握新任务。
- 方法上的不同:持续学习通常需要解决遗忘问题,而元学习更多关注于找到一种有效的学习策略或参数设置,使得模型能够快速适应新任务。
- 应用场景:持续学习适用于那些数据持续更新或任务持续变化的场景,元学习适用于那些需要模型在很少的迭代中迅速适应新任务的场景。
总的来说,尽管持续学习和元学习在机器学习领域内都非常重要,但它们各自解决了不同的问题并采取了不同的方法。
Continual Reinforcement Learning
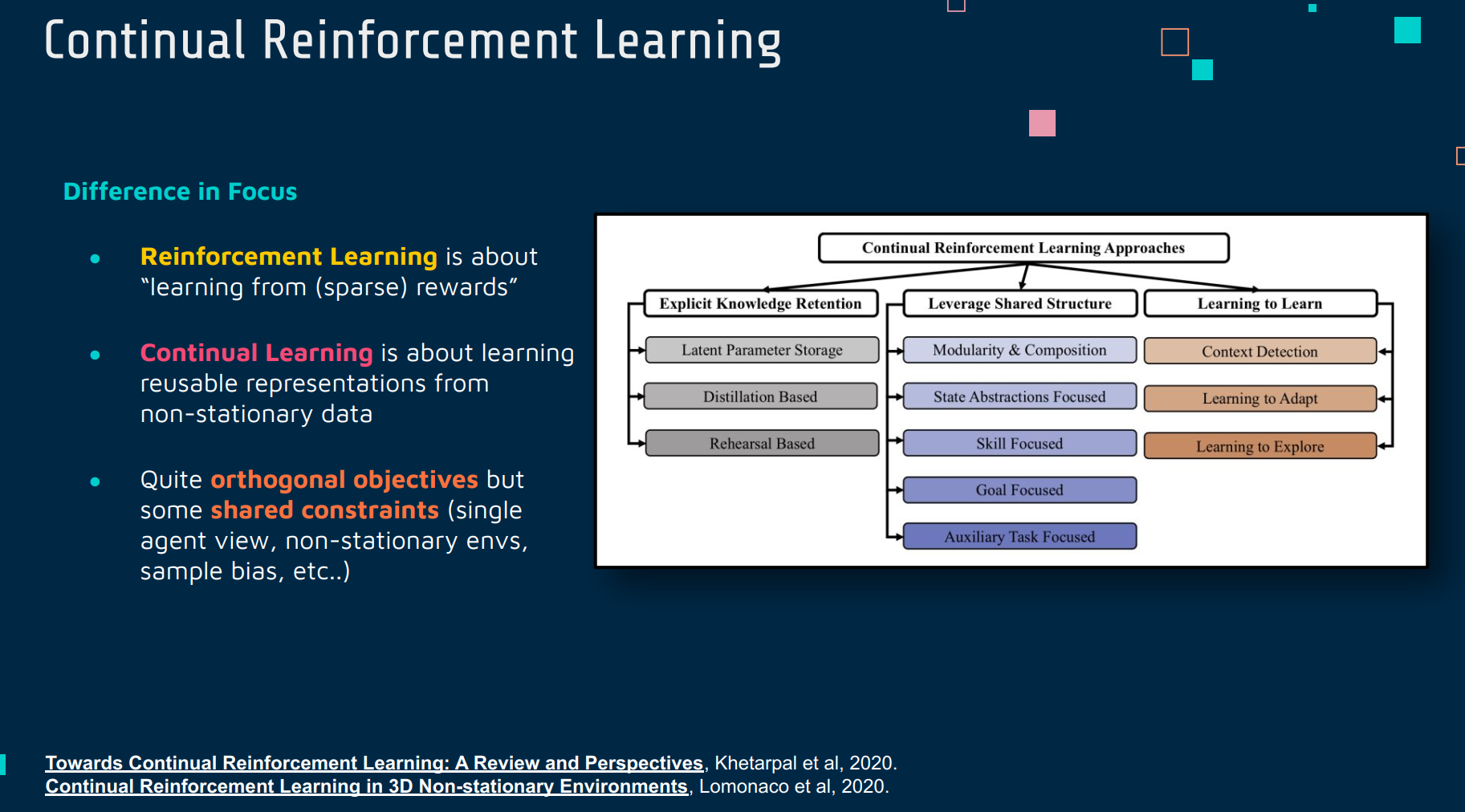
Continual Learning(持续学习)
持续学习关注于如何使机器学习模型能够不断地学习新任务,同时保留之前任务的知识,避免发生灾难性遗忘。持续学习的核心挑战在于如何在不断变化的数据流中有效地更新模型,而不会损失先前学习到的信息。
Reinforcement Learning(强化学习)
强化学习是一种让机器学习模型通过与环境的交互来学习的方法。它主要关注于如何根据环境反馈(奖励或惩罚)来优化决策或行为策略。强化学习的关键在于学习如何在给定的状态下选择最优的动作。
两者的联系与区别
- 联系:持续学习和强化学习都涉及到动态环境中的学习过程。在某些情况下,强化学习模型可能需要在不断变化的环境中适应新的策略,这与持续学习中的问题类似。
- 区别:
- 目标差异:持续学习的主要目标是解决在学习新任务时如何保留旧知识的问题,而强化学习的目标是最大化累积奖励。
- 方法上的不同:持续学习侧重于管理知识和避免遗忘,强化学习则侧重于根据环境反馈学习策略。
- 应用场景:持续学习适用于任务或数据集逐渐演变的场景,强化学习适用于需要通过试错来学习最佳行为的场景。
Continual Reinforcement Learning(持续强化学习)
持续强化学习是持续学习和强化学习概念的结合。它涉及到在不断变化的环境中训练强化学习模型的问题,要求模型不仅能够适应新的环境或任务,同时也能保留对先前环境或任务的知识。这在实际应用中非常重要,比如在动态变化的环境中部署机器人或自动驾驶系统。在持续强化学习中,模型需要在多个不同的任务或环境中连续学习,而不是专注于单一的、静态的任务。
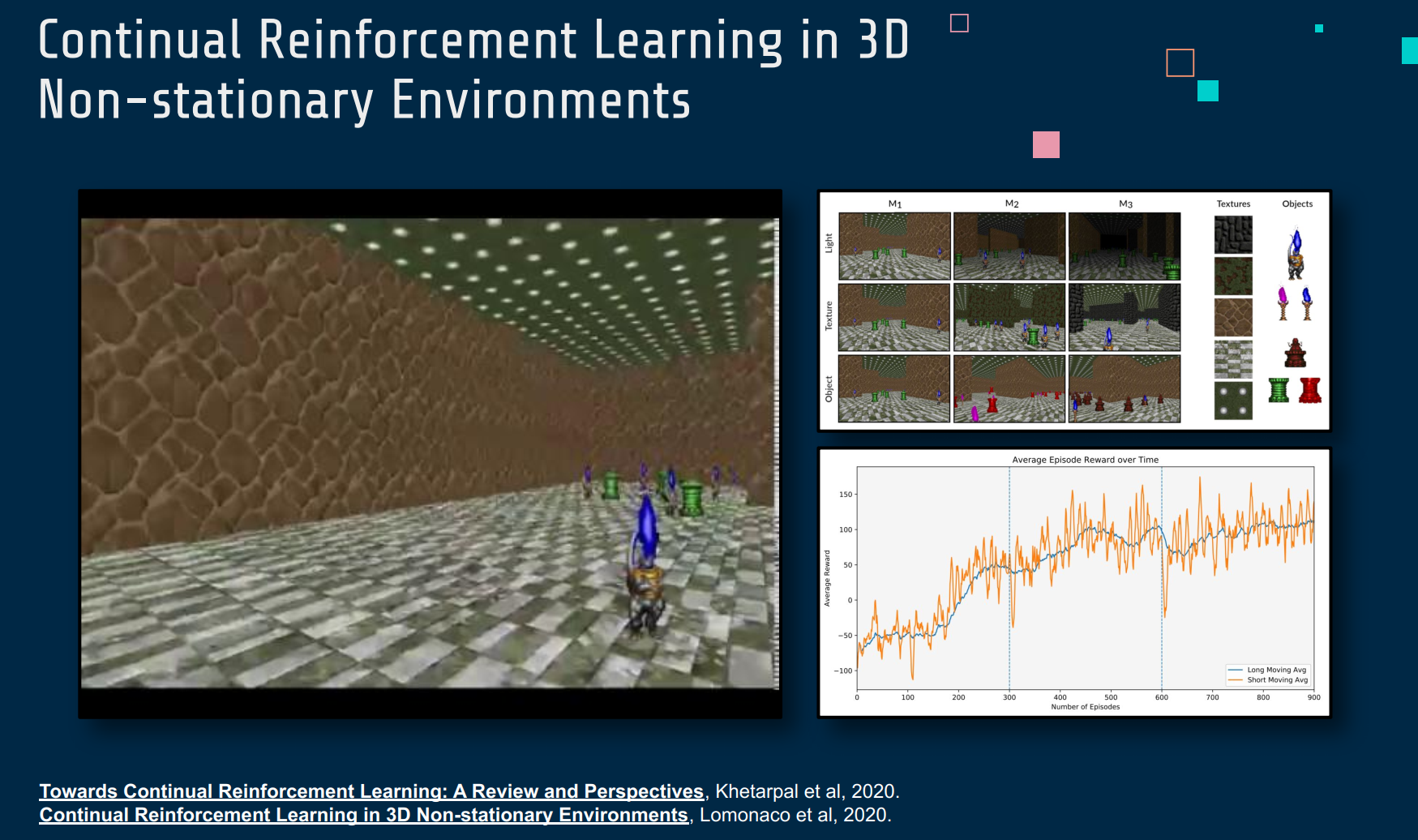
Towards Continual Reinforcement I earning: A Review and Perspectives
Continual Reinforcement L earnina in 3D Non -stationary Environments
Continual Unsupervised Learning
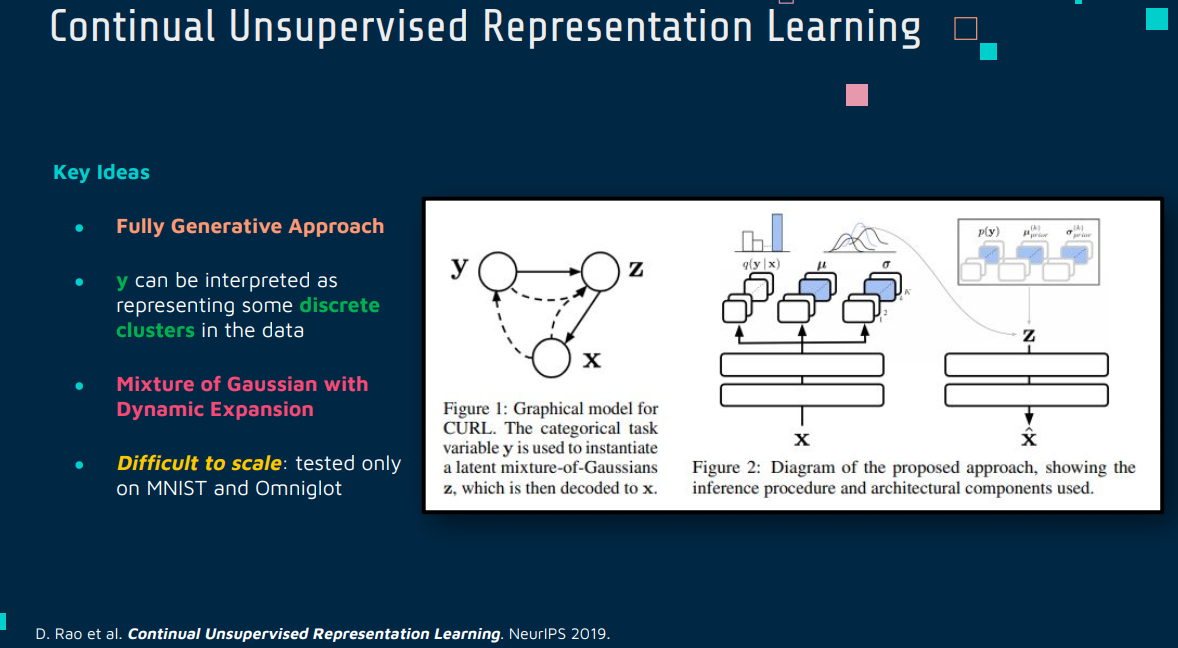
Continual Unsupervised Learning(持续无监督学习)是机器学习中的一个研究领域,它结合了持续学习(Continual Learning)的概念和无监督学习(Unsupervised Learning)的方法。这个领域的目标是开发能够在连续数据流上不断学习和适应的模型,而不需要依赖于标注数据。
核心思想
在传统的无监督学习中,模型通常在一个固定的数据集上进行训练,以学习数据的潜在结构或模式。而在持续无监督学习中,模型面临的是一个不断变化的数据流,它需要适应新数据,同时保持对之前数据的知识。这种学习方式对应用于动态变化的环境或长期任务非常重要。
持续无监督学习的挑战
灾难性遗忘:和其他形式的持续学习一样,持续无监督学习也需要解决灾难性遗忘的问题,即新数据的学习不应导致旧知识的丢失。
数据表示的适应性:模型需要能够适应新数据的特征分布,这可能随时间发生变化。
无监督的环境下的学习:由于缺乏明确的标注,模型需要自行发现数据中的模式和结构,这使得学习过程更加复杂。
方法和技术
自编码器变体:使用自编码器(如变分自编码器)来学习数据的表示,这些表示可以在时间上适应新的数据分布。
聚类方法:使用动态聚类算法来不断更新数据的聚类结构。
生成模型:使用生成模型(如生成对抗网络)来捕捉数据分布的变化,并生成用于训练的样本。
记忆机制:实现记忆机制来存储先前的知识,例如通过选择性地保存代表性数据样本。
持续的学习策略:采用特定的策略来平衡新知识的学习和旧知识的保留,例如使用重放机制或正则化技术。
应用领域
持续无监督学习在多种应用中都非常有价值,如在动态环境中的异常检测、实时数据流的模式识别、自然语言处理中的主题建模等。
结论
持续无监督学习是一个挑战性但富有前景的研究领域,它扩展了机器学习模型在动态和未标注环境中的应用能力。随着数据量的不断增长和环境的不断变化,这种类型的学习方法变得越来越重要。

1 Self-Supervised Learning
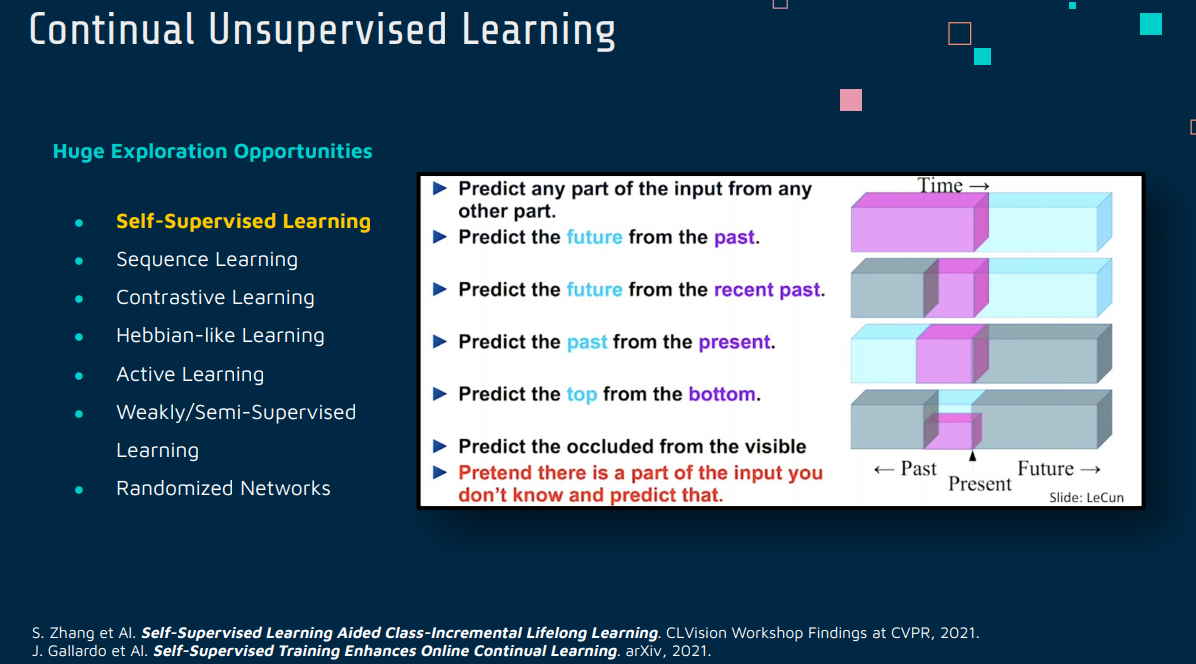
Self- Supervised Learning Aided Class-Incremental Lifelong Learning
[2006.05882] Self-Supervised Learning Aided Class-Incremental Lifelong Learning (arxiv.org)
[2103.14010] Self-Supervised Training Enhances Online Continual Learning (arxiv.org)
Self-Supervised Learning(自监督学习)和 Continual Learning(持续学习)是两个独立但互补的机器学习领域。它们各自解决了不同的问题,但在某些情况下可以结合起来,以增强学习模型的能力和效率。
Self-Supervised Learning(自监督学习)
自监督学习是一种无需人工标注的学习方法。在这种学习范式中,模型利用输入数据本身作为监督信号来学习。例如,在图像处理中,可以通过预测图像的一部分或属性来训练模型,而无需外部提供的标签。自监督学习的关键优势在于它能够利用大量未标注的数据来学习数据的内在特征和结构。
Continual Learning(持续学习)
持续学习,又称为增量学习或生命周期学习,关注于如何让机器学习模型在面对连续数据流时能持续学习新任务或信息,同时保留旧任务的知识。持续学习的挑战在于防止新学习的知识覆盖旧知识,这被称为灾难性遗忘。
两者的联系与区别
- 区别:
- 目标不同:自监督学习的目标是从未标注的数据中提取有用信息,而持续学习的目标是在一系列任务中持续学习而不遗忘旧知识。
- 方法差异:自监督学习依赖于数据本身作为学习信号,持续学习则依赖于有效的策略来平衡新旧知识的学习。
- 联系:
- 结合使用:可以将自监督学习用于持续学习环境,以提高模型对新任务的适应性,同时减少对标注数据的依赖。自监督学习可以提供丰富的特征表示,有助于持续学习模型更好地泛化到新任务。
结合应用
将自监督学习和持续学习结合起来可以提高模型在持续学习环境中的性能,尤其是在数据标注有限的情况下。例如,自监督学习可以用于预训练模型,以学习丰富的特征表示,然后在持续学习任务中利用这些表示来提高模型对新任务的适应性和对旧知识的保留能力。这种结合利用了自监督学习在特征提取方面的强大能力,以及持续学习在处理连续任务中的有效性。
2 Sequence Learning

3 Hebbian-like Learning

[1904.09330] Continual Learning with Self-Organizing Maps (arxiv.org)
Hebbian-like Learning(赫布型学习)
赫布型学习是一种基于赫布理论的学习规则,通常总结为“共同激活的神经元互相加强”,即如果两个神经元同时激活,那么它们之间的连接会被加强。这种学习机制是无监督的,因为它不依赖于外部的错误或奖励信号来调整神经连接的权重。
- 特点:赫布型学习主要用于模型的自组织和特征提取,它可以帮助神经网络捕捉输入数据中的统计规律。
- 应用:在神经科学和一些特定的神经网络模型中,如自组织映射(SOM)和部分竞争性网络,赫布型学习是一种重要的学习规则。
Continual Learning(持续学习)
持续学习,也称为生命周期学习或增量学习,指的是机器学习模型在一系列任务中持续学习的能力,而不会忘记以前学习的知识(解决灾难性遗忘问题)。
- 特点:持续学习的核心挑战在于如何使模型能够适应新任务和新数据,同时保留对旧任务和数据的记忆。
- 应用:持续学习在需要模型对数据流或连续出现的任务持续适应的场景中非常重要,如在线学习和实时数据处理。
联系与区别
- 联系:
- 信息保留:两者都涉及到如何在神经网络中保存和利用学习过的信息。赫布型学习通过加强共同激活的神经元的连接来保存信息,而持续学习则试图保留过去任务的知识。
- 自适应学习:它们都促进了网络对新信息的适应性,尽管方法和应用上有所不同。
- 区别:
- 学习机制:赫布型学习是基于神经元活动模式的无监督学习,而持续学习通常涉及监督学习或强化学习,并且侧重于任务间的知识转移。
- 应用领域:赫布型学习更多地应用于模式识别和特
4 Active Learning
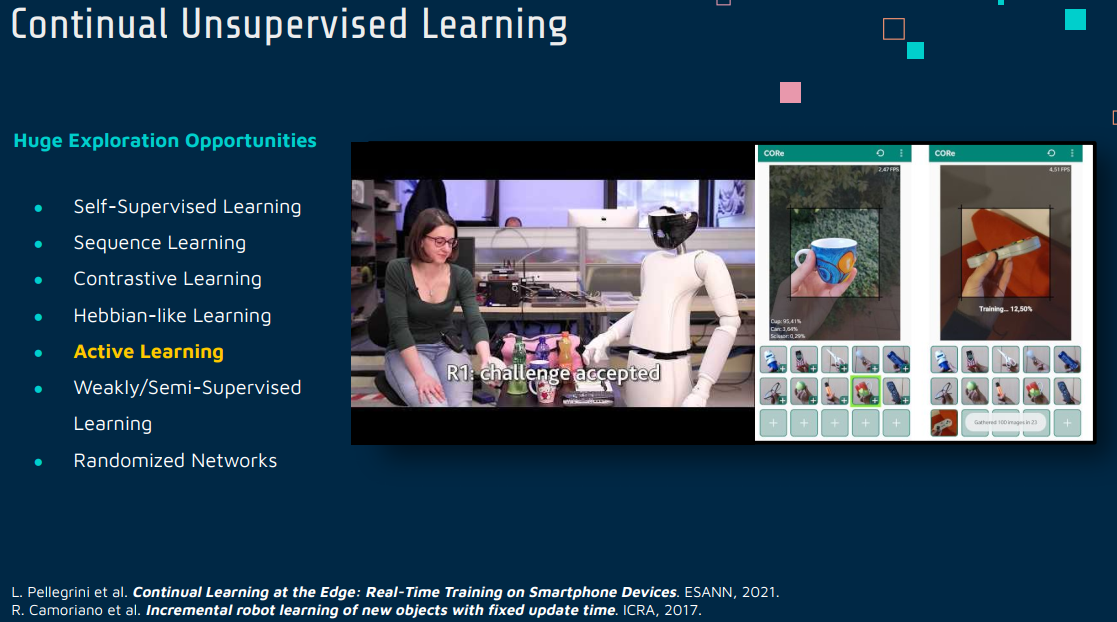
[2105.13127] Continual Learning at the Edge: Real-Time Training on Smartphone Devices (arxiv.org)
Active Learning(主动学习)和 Continual Learning(持续学习)是机器学习中两个独特但相关的领域,它们各自有着不同的焦点和方法,但也存在可能的结合点。
Active Learning(主动学习)
主动学习是一种学习策略,其中学习算法可以主动选择要标注的数据点,以此来优化学习过程。主动学习的核心思想是,通过选择性地获取最有信息量的数据标签,可以使用更少的标注数据来训练有效的模型。
- 特点:在有限的标注资源或标注成本高昂的情况下特别有效。
- 应用:常用于分类和回归任务,尤其是在数据标注成本高昂或数据量庞大的场景中。
Continual Learning(持续学习)
持续学习关注于如何使机器学习模型能够在处理连续数据流或连续变化的任务时,持续学习新知识,同时避免遗忘先前学到的知识。
- 特点:关键挑战是解决灾难性遗忘问题,即新任务学习可能会干扰旧任务的知识。
- 应用:适用于动态环境中的模型训练,如在线学习、实时数据处理。
联系与区别
- 联系:
- 互补目标:主动学习可以优化数据的选择过程,减少模型训练所需的标注数据;持续学习则关注于如何在长期过程中保留和积累知识。
- 数据效率:两者都关注于如何高效利用数据,虽然它们的方法和应用场景不同。
- 区别:
- 焦点差异:主动学习侧重于数据选择的智能化,而持续学习侧重于跨任务的知识保留。
- 学习策略:主动学习是一种数据驱动的策略,强调最大化数据的价值;持续学习则侧重于学习算法和模型架构的适应性。
结合应用
将主动学习与持续学习结合起来可以创建一种强大的学习范式,尤其是在资源受限或数据动态变化的情况下。例如,在一个持续学习的场景中,可以利用主动学习来选择最具信息量的新数据点进行标注和训练,这样可以在保留旧知识的同时,高效地学习新信息。这种结合不仅能提高数据利用效率,还能帮助模型更好地适应新任务,同时减少遗忘现有知识。
5 Weakly/Semi-Supervised Learning
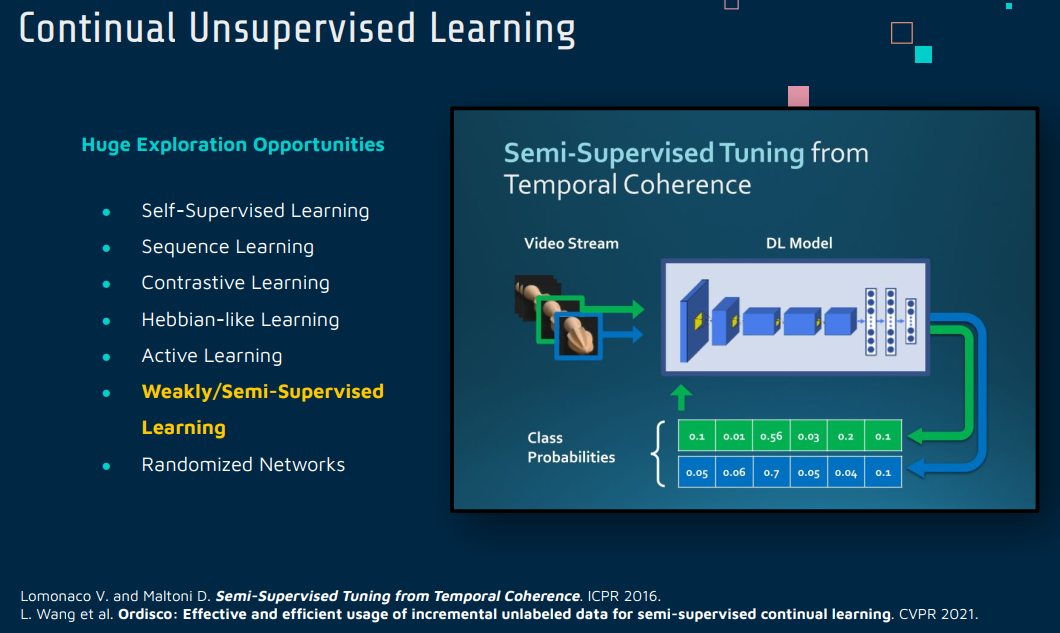
CVPR 2021 Open Access Repository (thecvf.com)
Semi-Supervised Learning(半监督学习)和 Continual Learning(持续学习)是机器学习中两个不同的领域,它们各自有独特的特点和应用,但也存在潜在的结合点。
Semi-Supervised Learning(半监督学习)
半监督学习是一种机器学习方法,它结合了有标签的数据(监督学习)和无标签的数据(无监督学习)。在许多实际应用中,获取大量标注数据可能既昂贵又耗时,而半监督学习可以利用大量未标注的数据来提高学习效果。
- 特点:能够有效利用未标注数据来提升学习性能。
- 应用:广泛应用于图像识别、自然语言处理等领域,特别是在标注数据稀缺的情况下。
Continual Learning(持续学习)
持续学习关注于模型在一系列连续的任务中的学习能力,尤其是在新任务的学习过程中如何保留对旧任务的知识。主要挑战是解决灾难性遗忘问题,即新学习的信息覆盖旧知识的问题。
- 特点:专注于跨任务的知识保留和转移。
- 应用:适用于需要模型不断适应新任务的场景,如在线学习和实时数据处理。
联系与区别
- 联系:
- 提高学习效率:两者都寻求在有限的数据或资源条件下提高学习效率。半监督学习通过利用未标注数据,持续学习通过有效管理知识遗忘和转移。
- 适应性:两者都需要对动态或不完全的数据环境具有适应性。
- 区别:
- 学习过程:半监督学习通常在一个固定的数据集上进行,强调标注和未标注数据的结合;持续学习面对的是一系列连续变化的任务或数据流。
- 主要挑战:半监督学习的挑战在于如何有效利用未标注数据,而持续学习的挑战在于如何在新任务的学习中保留旧知识。
结合应用
将半监督学习和持续学习结合可以创建一个强大的学习系统,特别是在数据标注有限且任务持续更新的情况下。例如,在一个持续学习的场景中,可以使用半监督学习方法来利用大量未标注的数据,以增强模型对新任务的学习,同时减少对旧任务知识的遗忘。这种结合可以使模型在资源有限的环境中更加有效和适应性强,尤其是在数据动态变化的实际应用中。
6 Randomized Networks
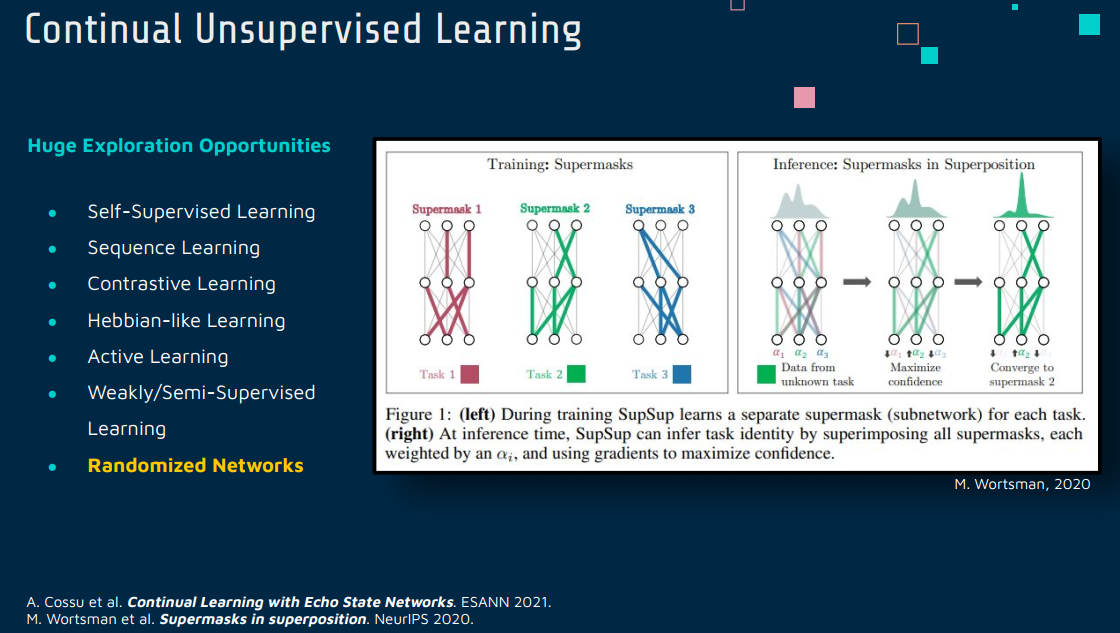
Continual Learning with Echo State Networks.
[2105.07674] Continual Learning with Echo State Networks (arxiv.org)
Randomized Networks(随机化网络)和 Continual Learning(持续学习)是机器学习领域中两个相对独立的概念,但它们之间存在潜在的结合方式。
Randomized Networks(随机化网络)
随机化网络指的是在其结构或参数中引入随机性的神经网络。这种随机性可以体现在多个方面,如随机初始化网络权重、在训练过程中随机修改网络连接或参数等。随机化网络的优点包括提高模型的泛化能力、加快训练速度、降低过拟合风险等。
- 特点:随机化网络通过引入随机性来增加模型的多样性和鲁棒性。
- 应用:广泛应用于神经网络的初始化、集成学习方法以及某些特定类型的网络设计,如随机森林。
Continual Learning(持续学习)
持续学习强调模型在一系列连续任务中的学习能力,特别关注如何在学习新任务时保留对以前任务的知识,避免灾难性遗忘。
- 特点:关注于跨任务的知识保存和转移,特别是在连续数据流或不断变化的任务环境中。
- 应用:适用于需要模型不断适应新任务的场景,如在线学习、实时数据处理。
联系与区别
- 联系:
- 提高适应性和泛化能力:随机化网络可以提高模型的泛化能力,这对持续学习中的模型适应新任务可能是有益的。
- 处理不确定性:两者都在某种程度上处理了不确定性——随机化网络在结构或参数中引入不确定性,而持续学习处理的是任务或数据的不确定性。
- 区别:
- 目标差异:随机化网络主要关注于通过引入随机性来提高模型性能,而持续学习关注于如何有效地管理跨任务的知识。
- 方法和应用:随机化网络通常用于提高模型的初始性能或鲁棒性,而持续学习则关注于模型在长期学习过程中的性能。
结合应用
将随机化网络与持续学习结合起来可以在持续学习模型中引入额外的泛化和适应性。例如,可以使用随机初始化的网络作为持续学习任务的起点,或者在持续学习过程中引入随机化技术来增加模型对新任务的适应性。此外,随机化方法也可以用于持续学习中的正则化,以减少对旧任务的遗忘。这种结合可以使持续学习模型在面对新任务时更加灵活和鲁棒。
Other relevant work

Sustainable AI


Open Questions

1.Is it possible to learn robust, deep representations continually?
2.Are currently addressed scenarios and eval metrics enough?
3.What is the right level of supervision?
4.How to know what to forget and what to remember?
5.What’s the relationship with concept drift?
6.Is replay a research direction worth pursuing?
7.S computation more important than memory?
8.Is gradient descent the right algorithm to learn continually?
9.Continual Meta-Learning & Meta-Continual Learning: what’s the right relationship?
10.What is the relationship with Sequence and Continual Learning ?
- 是否可以持续学习鲁棒、深入的表示?
- 可能性:目前的研究表明,通过改进学习算法和网络架构,可以持续学习深入的表示。例如,使用正则化技术和动态网络调整来减少遗忘,增加模型的适应性。
- 挑战:持续学习中的主要挑战是如何在学习新任务时保持对旧知识的稳定性,即解决灾难性遗忘问题。
- 当前处理的场景和评价指标是否足够?
- 观点:一些学者认为现有的场景和评价指标可能过于简化,不足以覆盖真实世界中的复杂情形。
- 改进:需要更多地模拟现实世界的复杂性和不确定性,引入更多维度的评价指标来全面评估模型的持续学习能力。
- 何为合适的监督水平?
- 观点:过度依赖标注数据可能会限制模型的泛化能力,而过少的监督又可能导致学习效率低下。
- 平衡:结合监督学习、无监督学习以及半监督学习,以达到有效学习与模型泛化之间的平衡。
- 如何判断什么该忘记,什么该记住?
- 方法:利用重要性评估和记忆管理策略,如动态保留重要特征或使用记忆重放。
- 研究:需要深入研究不同类型信息的重要性和持久性,以及其对持续学习性能的影响。
- 与概念漂移的关系是什么?
- 关系:持续学习需要应对概念漂移的问题,即数据分布和环境条件随时间的变化。
- 应对:通过适应性学习策略和模型更新来应对概念漂移,确保模型在变化的环境中保持有效。
- 重放是否值得作为研究方向?
- 价值:重放作为一种减轻灾难性遗忘的有效手段,是值得研究的。它能帮助模型回顾旧知识,增强记忆。
- 创新:未来的研究可以探索更高效和智能的重放机制,例如选择性重放和条件重放。
- 计算是否比记忆更重要?
- 观点:两者都重要,但它们的重要性可能取决于特定的应用场景。
- 平衡:在资源有限的环境中,找到计算和记忆之间的最优平衡是关键。
- 梯度下降是否适合持续学习?
- 问题:梯度下降可能导致新知识覆盖旧知识,特别是在参数共享的场景中。
- 替代方案:探索新的优化算法,例如基于元学习或贝叶斯方法的优化策略。
- 持续元学习与元持续学习:正确的关系是什么?
- 探索:持续元学习关注于通过持续学习改进元学习能力,而元持续学习则利用元学习来增强持续学习。
- 融合:两者可以相互补充,共同促进模型在新任务上的快速适应和跨任务的知识保留。
- 序列学习与持续学习的关系是什么?
- 关系:序列学习专注于时间序列数据的模式识别,而持续学习则更广泛地关注于连续任务的学习。
- 结合:在处理时间序列数据时,持续学习可以应用序列学习的技术来更好地理解和预测数据模式。

1.Is curiosity important for continual learning?
2.What about Curriculum Learning?
3 Compositionality is a key aspect of human intelligence: what to expect for CL Systems?
4.Self- Reflection”: accuracy of learned functions, given only unlabeled data?
5.Self-reflection that can detect every possible shortcoming (called impasse) of the agent
6 Knowledge and Reasoning
- 持续学习中好奇心的重要性
- 观点:好奇心或探索性驱动在持续学习中非常重要。好奇心激励模型探索未知或不确定的数据和环境,有助于发现新知识并适应新任务。
- 研究:有研究表明,引入好奇心或类似动机的机制可以提高持续学习模型的性能,尤其是在复杂和动态变化的环境中。
- 课程学习的影响
- 作用:课程学习通过有序的任务呈现来模拟人类学习过程,可以提高持续学习的效率。它按照从简单到复杂的顺序逐步呈现任务,有助于模型更有效地学习和适应。
- 应用:在持续学习中应用课程学习可以帮助模型逐步构建知识,减少一次性面对复杂任务时的压力。
- 组合性对持续学习系统的意义
- 重要性:组合性是人类智能的关键特征,允许人类高效地组合和重组知识。对于持续学习系统而言,组合性可能是实现高级认知和适应性的关键。
- 期望:持续学习系统未来可能需要更好地理解和利用组合性,以模仿人类在面对新任务和环境时的适应和学习能力。
- “自我反思”:在仅有未标注数据的情况下学习功能的准确性
- 挑战:在没有标注数据的情况下,评估学习功能的准确性是一个挑战,因为缺乏明确的性能评价标准。
- 方法:可以通过自监督学习、无监督学习技术或内部评估机制来实现“自我反思”,例如,利用重构误差或内部一致性评估模型性能。
- 自我反思:检测代理可能短板(即僵局)
- 需求:对持续学习系统而言,检测并解决其短板(或僵局)是至关重要的。这要求系统能够自我诊断和调
The Future

Distributed Learning
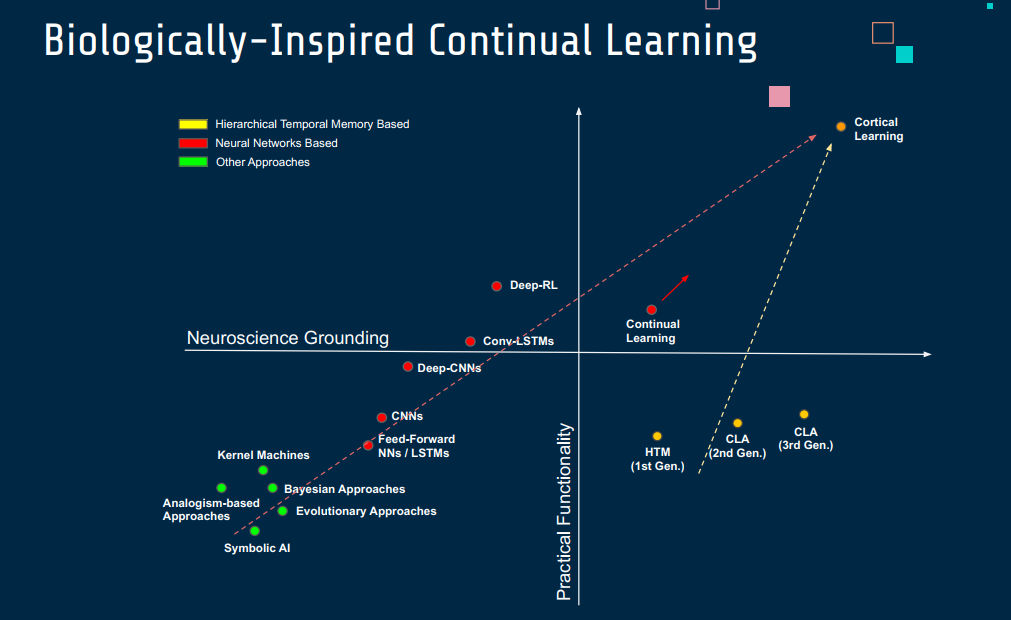
Biologically -Inspired
Agent Centric


Ex-Model Continual Learning
学科交叉方向
Continual Learning(持续学习)与神经科学、行为认知等学科的结合,为理解和模拟人类和动物的学习机制提供了独特的视角和方法。这种跨学科结合的方向可以帮助我们更好地理解大脑的学习和记忆机制,并在人工智能领域创造出更高效、更自然的学习系统。
与神经科学的结合
模拟大脑的学习过程:神经科学研究如何通过神经元和突触的活动来学习和存储信息。持续学习可以借鉴大脑的这些机制,如赫布学习理论(Hebbian learning theory)和突触可塑性(synaptic plasticity)。
灾难性遗忘的生物学基础:探索大脑如何避免新信息覆盖旧知识的机制,可以为解决持续学习中的灾难性遗忘问题提供线索。
神经元编码策略:研究大脑如何通过不同的神经元编码策略(如稀疏编码)来高效处理信息,为持续学习提供灵感。
与行为认知的结合
认知模型:研究人类和动物如何在长期记忆和短期记忆中存储和处理信息,可以帮助设计更好的持续学习算法。
注意力机制:认知科学中的注意力理论可以应用于持续学习,以帮助模型确定哪些信息是重要的,应该被优先学习和保留。
决策制定过程:了解人类如何基于有限的信息和经验做出决策,可以为持续学习中的样本选择和任务优先级策略提供指导。
结合的潜在方向
- 跨学科研究项目:鼓励计算机科学、神经科学和心理学等领域的研究人员合作,共同探索学习和记忆的新模型。
- 生物启发的算法开发:开发新的算法,模拟生物大脑处理信息和学习的方式。
- 实验验证:使用神经科学和行为科学的实验结果来测试和验证持续学习模型的有效性。
通过这种跨学科的结合,持续学习不仅可以在理论上取得进展,还可以在实际应用中实现更自然、更符合人类和动物学习方式的人工智能系统。
Multi-Agent Systems
将 Continual Learning(持续学习)与Multi-Agent Systems(多智能体系统)相结合,是一个前景广阔的研究方向。这种结合不仅有助于提高系统的适应性和智能水平,还能在复杂环境中实现更有效的协作和决策。以下是一些将持续学习和多智能体系统相结合的潜在方向:
适应性和灵活性
- 环境适应性:在不断变化的环境中,多智能体系统需要持续学习和适应。例如,自动驾驶车队需要适应不断变化的交通环境。
- 智能体间的策略学习:智能体可以持续学习其他智能体的行为和策略,以实现更有效的协作或竞争。
增强协作和沟通
- 动态协作策略:多智能体系统可以通过持续学习来动态地调整其协作策略,以应对新的任务或挑战。
- 有效沟通:智能体可以持续学习如何更有效地与其他智能体沟通,提高整体系统的协同效率。
知识共享和迁移
- 知识共享:智能体可以通过共享经验来加速整个系统的学习过程。例如,一个智能体在特定任务上的学习成果可以被其他智能体利用。
- 跨任务学习:智能体可以持续学习多种任务,并将在一个任务上获得的知识迁移到其他任务。
处理不确定性和复杂性
- 不确定性管理:在复杂和不确定的环境中,多智能体系统需要持续学习以更好地做出决策。
- 环境建模:智能体可以持续学习环境模型,以更好地预测和适应环境变化。
结论
结合持续学习和多智能体系统可以大大提高系统的智能水平和适应性,尤其是在动态和复杂的环境中。这种结合不仅可以加强智能体间的协作,还可以提高整个系统对新挑战的应对能力。
gan
Continual Learning(持续学习)和GAN(生成对抗网络)是两个不同的机器学习领域,但它们可以以有意思的方式结合在一起。
Continual Learning(持续学习)
持续学习专注于如何使机器学习模型能够在连续的任务或数据流上不断学习,同时避免之前学到的知识被新任务覆盖(灾难性遗忘)。
- 特点:着重于跨任务的知识转移和保留。
- 应用:适用于需要模型对新信息持续适应的场景,如在线学习、自适应系统。
GAN(生成对抗网络)
GAN由两个网络组成:一个生成网络和一个判别网络,它们相互竞争,生成网络学习生成逼真的数据,而判别网络学习区分真实数据和生成的数据。
- 特点:强于生成逼真的数据样本。
- 应用:广泛应用于图像合成、风格转换、数据增强等领域。
联系与区别
- 区别:
- 目标不同:持续学习解决的是如何在长期内保存和更新知识的问题,而GAN专注于生成逼真的数据。
- 工作机制:持续学习侧重于学习策略和记忆管理,GAN则依赖于生成器和判别器之间的对抗过程。
- 联系:
- 数据生成:GAN可以为持续学习提供数据增强和重放的手段,以缓解灾难性遗忘。
结合方向
- 生成重放:使用GAN生成历史数据样本,用于持续学习中的重放,以减少遗忘。
- 数据增强:在持续学习场景中,GAN可以用于生成新的训练样本,增强模型的泛化能力。
- 新任务的快速适应:GAN可以帮助持续学习模型快速适应新任务,通过生成该任务的数据样本进行预训练。
- 模型鲁棒性:使用GAN挑战持续学习模型,提高其对逆向样本的鲁棒性。
结合GAN和持续学习可以在持续学习模型的数据处理、记忆保持和任务适应性方面带来显著的改进。
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/01/14/Continual-Learning-3-Future-directions/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)