Paper Reading 4 Distributed continual learning
Projected Latent Distillation for Data-Agnostic Consolidation in distributed continual learning
这篇文章设置了一个很奇特的场景,但我觉得这个场景可能是很现实有效的
在介绍这篇文章的场景之前,咱们先学习一些关于联邦学习,分布式学习的基础知识
联邦学习
参考链接
[只看这一篇就够:快速了解联邦学习技术及应用实践通俗易懂]-腾讯云开发者社区-腾讯云
核心思想
联邦学习的核心思想是将模型训练过程分散到多个数据持有方上,而不是将数据集中存储。在联邦学习的框架下,每个客户端(如手机、智能设备或企业)会在自己的本地数据上独立训练模型,并将更新后的模型参数传输到中心服务器(而非原始数据)。服务器会对这些来自不同客户端的模型更新进行汇总(通常是加权平均),然后将合并后的全局模型再分发给各个客户端。这个过程不断循环,最终形成一个在全体数据基础上优化的全局模型,而数据始终保留在客户端上。
联邦学习的主要步骤
- 本地训练:各客户端在本地数据上进行模型训练,并生成更新的模型参数。
- 模型上传:客户端将本地训练的模型参数上传至中央服务器。
- 全局模型聚合:服务器对所有上传的参数进行加权平均或其他聚合操作,得到更新的全局模型。
- 模型分发:将更新后的全局模型下发至各客户端,并进入下一轮迭代训练。
示意图如下,
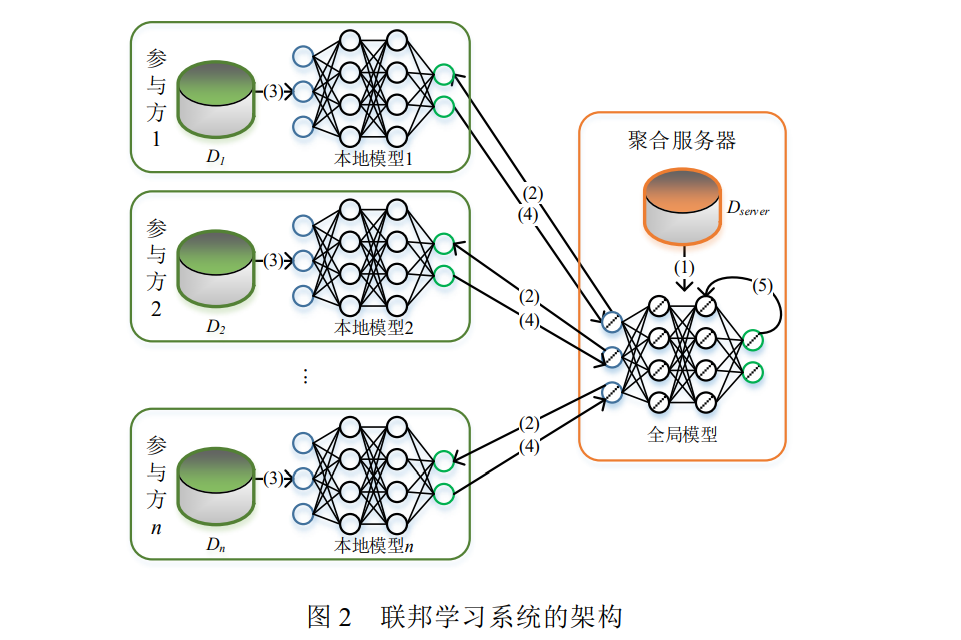
这里面有一些显而易见的问题,首先是 模型的数据如何进行 加密上传与分发 , 其次就是中心模型如何汇总更新。
还有一些其他问题,就是不同的参与方应当是学习相同的任务,可能是不同的来源。那么如果遇到新的类别或者说混进去了新的类别的数据,这是否会对整个联邦学习进程产生负面影响?
整个联邦学习的目的是为了得到一个更好的中心模型,主要解决的是数据分布式和隐私性的问题。
持续学习
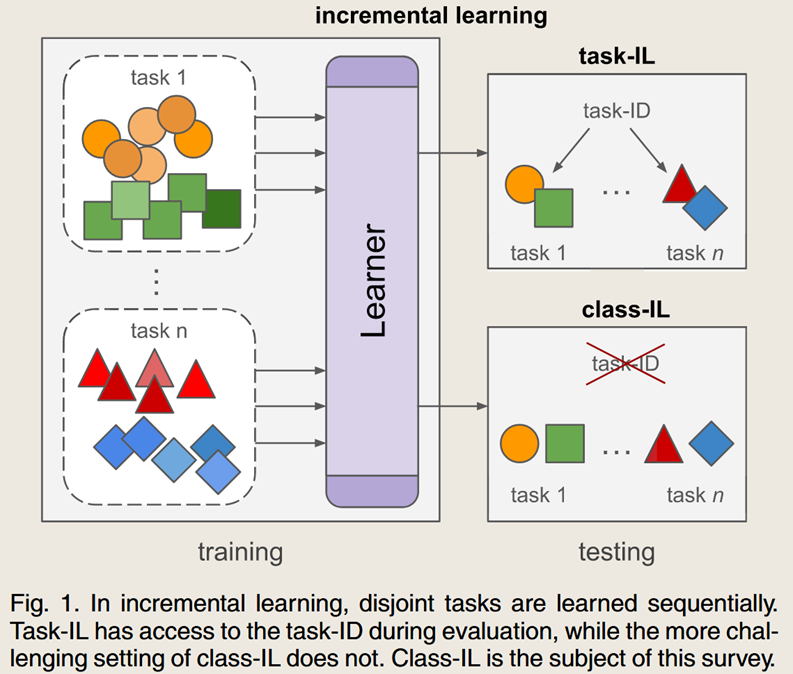
持续学习就是模型持续学习新的任务与新的类别。
更常见的是 class-incremental learning ,要求在测评的时候对之前所有类别都要识别,要平均效果最好。解决的问题是 灾难性遗忘的问题,即不光学好新的,还不能忘记旧的。
还通常有着之前数据不可见的设定,这称之为 data-free class-incremental learning (DFCIL)
分布式持续学习
这篇文章提出了一个新的场景,他称之为 Distributed Continual Learning (DCL) scenario 。 那这个和 联邦学习有什么区别呢?
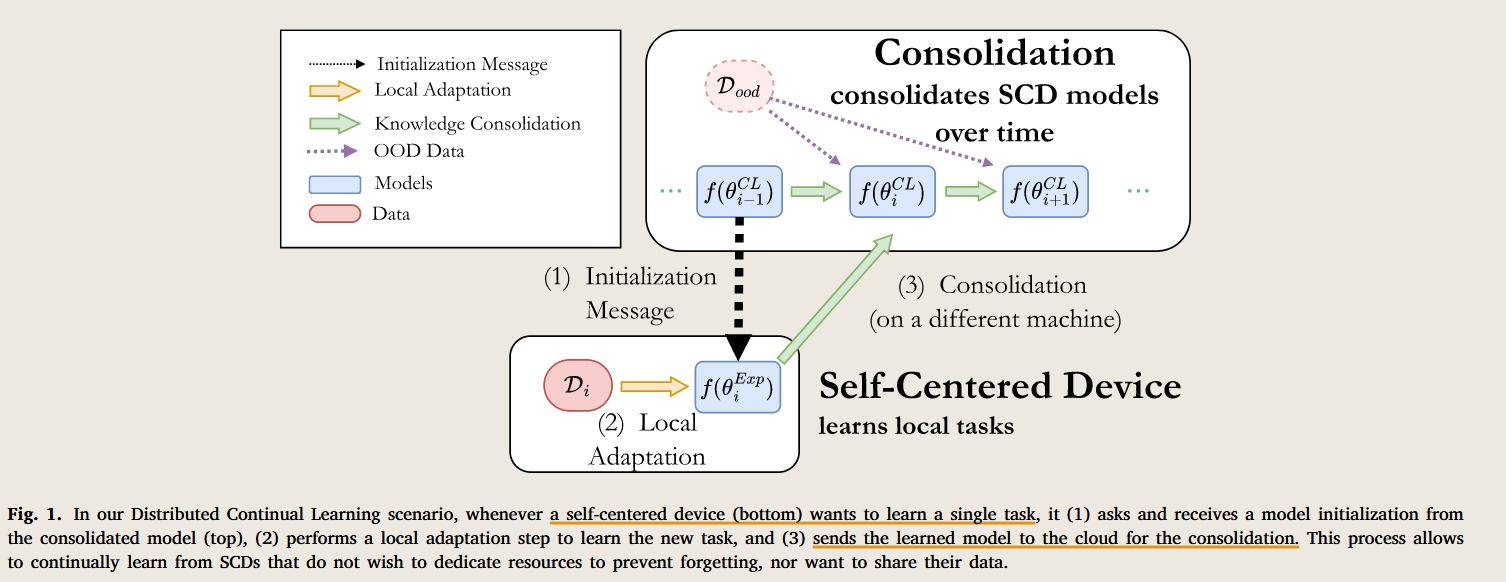
区别就是这里的子设备 是 self-centered devices (SCDs). 也就是说子设备只关心自己的任务表现, 更确切地是说他们只关心自己某个任务上地表现。
(1) they greedily optimize their performance only over a specialized domain
(2) they do not want to waste model capacity or computational resources to learn other tasks.
它们也是独立训练地。 那么它们又怎么构成联盟的呢?因为中心模型 被是一个 多任务模型。 只有本地模型初始化地时候会从中心复制一个模型过来,然后本地化适应与训练结束后,再将模型发送回中心。
中心模型地任务就是在原始模型的基础上,结合多个本地化小模型进行融合,然后得到新的模型。
这样设置和联邦学习的区别是什么呢?
在分布式持续学习里,每个SCD只专注于自己的本地任务,学习是持续的,任务流非静态,且设备学习的任务可能不同。通信仅在设备完成任务后将模型发送至中心进行整合,实现了设备间的知识转移。
传统分布式学习,所有节点共同完成同一任务,节点上的数据通常是相同的或同一分布的部分。这种设置适用于独立同分布(i.i.d.)的场景,通过参数平均或梯度聚合方法进行整合,以确保在不同节点的学习同步进行。
联邦学习,通常在所有设备上完成同一个任务,但每个设备的数据分布可能不一致(非i.i.d.),联邦学习通过多轮参数聚合,逐步生成一个全局模型。该全局模型以所有设备的学习结果为基础,聚合不同设备的数据特征。
这种场景有什么现实应用或者需求吗?
DCL的特点:高隐私保护、低通信开销、支持多任务、知识迁移和独立学习。
DCL允许不同设备在本地任务上独立学习,适合每个设备关注不同任务或具有不同目标的场景。DCL能够进行长期知识积累,每次在不干扰已学习任务的情况下整合新任务的知识,且支持不同任务之间的知识迁移,有利于长期积累和跨任务迁移。
这种场景和经典的class -incremental learning 有什么区别?
分布式持续学习在多设备环境中通过分布式学习和知识整合解决了数据隐私和通信带宽限制问题,而类别增量持续学习则适用于单一模型的类别扩展,注重新旧任务的平衡和灾难性遗忘的缓解。
所以这个就是 class- incremental learning 不过设置为了分布式设备与场景,
导致出现了模型的整合,而不是任务数据类别的增加;另外就是在class -incremental learning中模型是可以获得当前任务的数据的,而分布式场景下是不能获得任何原始数据的。
这个场景是不是更适合手机端的语音识别,每个人的口音和语言习惯是不一致的,所以本地端是一个高隐私保护,专注于一个领域的专家,而中心端就是提高模型的泛化能力?
1汇总和整合设备学习成果。中心模型需要整合这些通用特征,以提升全局语音识别模型在所有用户中的适用性和准确率。
2提升模型的泛化能力。中心模型的任务是将不同用户的特征加以整合,形成一个更加多样化的模型,从而提升模型在不同用户群体间的适用性。
3发现和整合新语言特征。语言习惯是动态变化的,随着新词语和表达方式的出现,中心模型需要从用户的学习成果中识别这些趋势,及时更新全局模型。
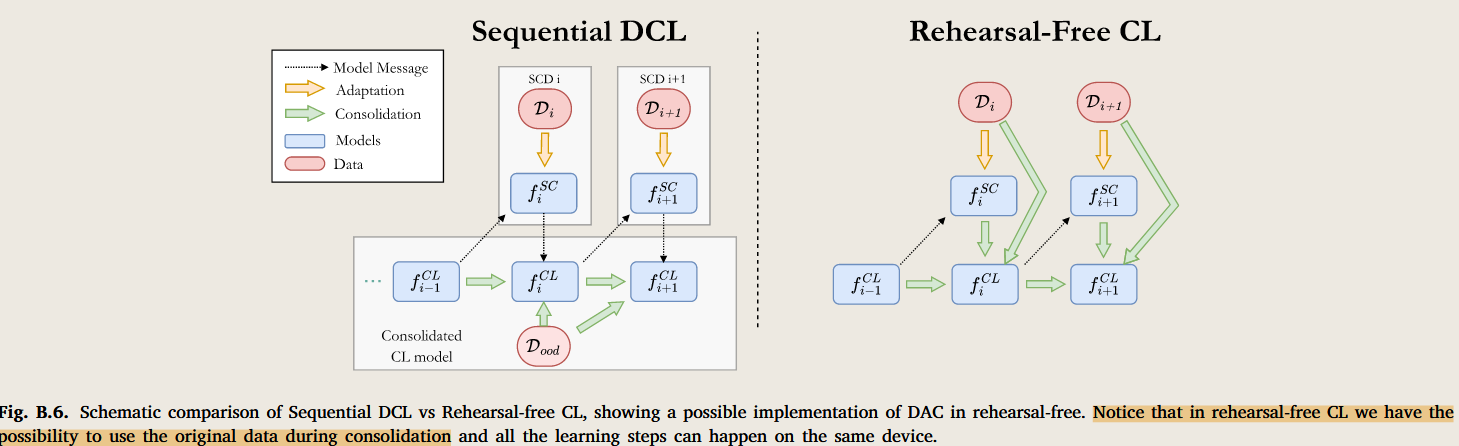
场景设置 :
1 参与者端的设备的任务不是一致的
2 参与者只有在初始化 和 本地端训练完成后和中心模型进行通话一次
3 中心端是多任务的模型
4 中心端序列地聚合不同本地端模型地任务能力
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/09/25/Paper-Reading-4-Distributed-continual-learning/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)