BCT–Towards Backward-Compatible Representation Learning
1. Scope or Setting(研究背景与问题设定)
本论文探讨了在开放世界的视觉分类和检索任务中,如何通过训练新模型,使得新旧模型的特征表示保持向后兼容性(Backward Compatibility),从而避免重新计算旧模型的特征表示。作者提出了一种名为Backward-Compatible Training (BCT) 的训练方法,旨在解决这一问题。
Key Idea(核心思想)
论文的核心思想是通过向后兼容训练,使得新模型生成的特征表示可以直接与旧模型的特征表示进行对比,而无需重新索引旧的特征表示。这种方法通过在新模型的训练中引入影响损失(Influence Loss),使新模型的特征表示与旧模型保持一致。
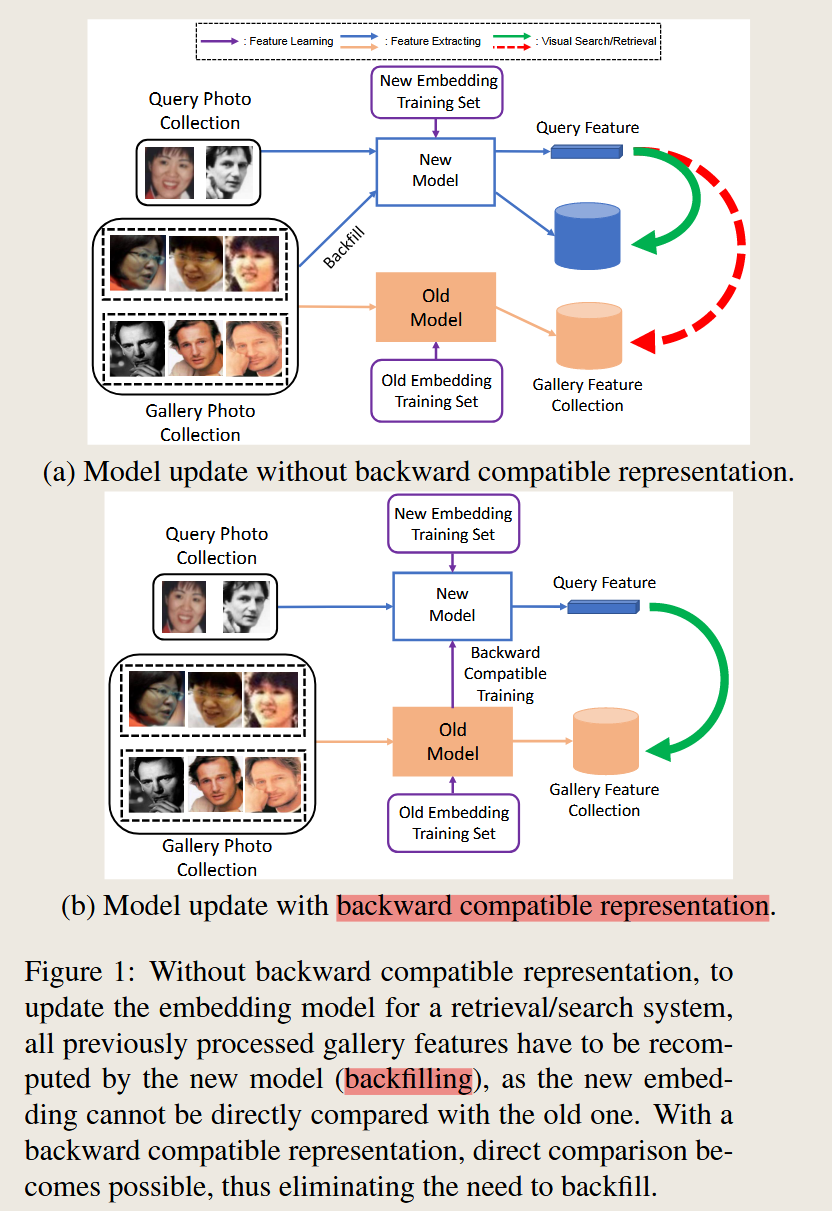
这一张图就能把BCT的想法解释地特别清晰,
最大的区别在于上面的第一张图需要把整个 Gallery 的图像重新放大新的模型,得到在新的特征空间下对应的特征向量,生成新的特征数据集。而下面的第二章图,也就是本文中提到的方法就不需要进行这一步,也就是所谓的 Backfilling 或者称之为 Re-indexing。
那是如何进行实现的呢? 这里面多了一个紫色的箭头,从old model 指向 new model ,也就是 new model 要学会旧模型的特征表示,也就是这里的 backward compatible representation。
评判标准 Criterion for Backward Compatibility
在2.2.2节中,文中给出了判断新模型与旧模型在特征空间中是否向后兼容的标准,主要通过以下几个不等式进行约束。这些不等式的目的是确保新模型在处理特征表示时,能够像旧模型一样有效地区分不同类别的图像,并且可以将同一类别的图像聚集在一起。
不等式1:区分类别间图像
\[d(\phi_{\text{new}}(x_i), \phi_{\text{old}}(x_j)) \geq d(\phi_{\text{old}}(x_i), \phi_{\text{old}}(x_j)), \quad \forall (i, j) \in \{(i, j) \vert y_i \neq y_j \}\]解释:这条不等式的意思是,对于属于不同类别的样本 $x_i$ 和 $x_j$,新模型生成的特征表示 $\phi_{\text{new}}(x_i)$ 和 $\phi_{\text{new}}(x_j)$ 之间的距离应该不小于旧模型生成的特征表示之间的距离。这确保了新模型能够至少和旧模型一样好地分离不同类别的图像特征。
意图:该约束的目的是防止新模型对不同类别图像的区分能力下降,即保证新模型能够有效地区分不同类别的特征。
不等式2:聚合同类别图像
\[d(\phi_{\text{new}}(x_i), \phi_{\text{old}}(x_j)) \leq d(\phi_{\text{old}}(x_i), \phi_{\text{old}}(x_j)), \quad \forall (i, j) \in \{ (i, j) \vert y_i = y_j \}\]解释:对于同一类别的样本 $x_i$ 和 $x_j$,新模型生成的特征表示 $\phi_{\text{new}}(x_i)$ 和 $\phi_{\text{new}}(x_j)$ 之间的距离应小于或等于旧模型生成的特征表示之间的距离。这意味着新模型在同类图像的特征聚合方面不应劣于旧模型。
意图:该约束的目的是保证新模型对同类图像的特征聚类能力不会比旧模型差,以确保新模型生成的特征依然能够聚集同类别图像的表示。
这些不等式的总意图
这两个不等式共同构成了衡量向后兼容性的标准。简而言之,新模型的特征表示必须能够和旧模型一样好,甚至更好地:
- 区分不同类别的图像;
- 聚集同一类别的图像。
这些约束使得新模型即使在特征提取维度、网络结构或训练数据集发生变化的情况下,仍然能够与旧模型保持特征兼容性,避免了重新计算旧特征的需求 .
Method(方法)
论文提出了一种新颖的训练框架,包含以下几个步骤:
向后兼容训练(Backward Compatible Training, BCT):通过在新模型的训练损失中加入旧模型分类器的影响损失,使得新模型在保持分类准确率的同时,与旧模型的特征表示兼容。
损失函数设计:论文提出了一个包含两个部分的损失函数:一个用于新数据集的常规训练损失,另一个是旧模型分类器的影响损失,公式为:
\[L_{BCT}(w_c, w_\phi; T_{new}, T_{BCT}) = L(w_c, w_\phi; T_{new}) + \lambda L(w_c^{old}, w_\phi; T_{BCT})\]Contribution(创新与贡献)
论文的贡献主要体现在以下几个方面:
- 定义并解决了向后兼容表示学习问题,该问题要求新模型在不牺牲准确率的前提下,能够直接与旧模型的特征表示兼容。
- 提出了向后兼容训练框架(BCT),通过影响损失来保持新旧模型特征表示的一致性。
- 进行了广泛的实验验证,展示了BCT方法在面部识别等任务中的有效性,并表明该方法可以在多种神经网络架构和损失函数下实现兼容性。
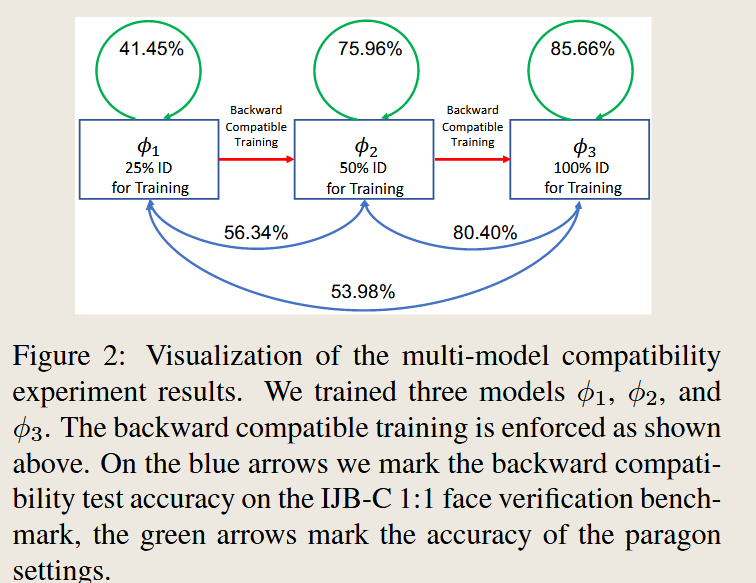
Difference and Innovation(区别与创新)
与传统的方法不同,BCT方法允许在引入新数据或新模型时,不需要重新计算旧特征,从而节省了大量的计算资源。相比于其它增量学习和持续学习方法,BCT强调的是新旧模型特征表示之间的直接兼容性,而不是通过知识蒸馏或回放策略来保持旧任务的记忆。
Continual Learning for Visual Search with Backward Consistent Feature Embedding
论文信息
Continual Learning for Visual Search with Backward Consistent Feature Embedding
设定
这篇论文的研究设定围绕视觉搜索中的持续学习(Continual Learning in Visual Search),主要针对不断增长的图库数据集和分类类别,提出了一种能够增量学习的框架。在视觉搜索中,系统需要在每次会话(session)中不断更新数据库,并引入新的类别,这种情况下,模型不仅要学习新类别,还需要保持旧类别特征嵌入的一致性,以避免“灾难性遗忘”(Catastrophic Forgetting)和特征空间不兼容的问题。
该设定的一个重要特点是,系统在处理每个新会话的数据时,不仅要更新新数据,还需要确保原有数据在检索系统中的表现不下降。这与传统方法不同,传统方法通常需要重新提取旧数据的特征,计算开销非常大,而本文提出的框架通过维持向后兼容性(Backward Compatibility)来避免这一问题。
创新点(Innovation)
向后兼容的特征嵌入: 本文最大的创新在于提出了向后兼容的特征嵌入机制,该机制允许新旧特征嵌入空间在视觉搜索任务中保持兼容。这意味着在模型更新之后,旧的特征不需要重新提取,模型依然能够有效地使用原来的特征进行检索,从而显著减少了计算开销。与其他方法不同,该方法在保持旧数据表现稳定的同时,能够处理新数据的学习。
通用增量学习设定(General Incremental Setup): 本文提出的框架能够处理更加通用的增量学习场景,不仅涵盖了传统的“分离设定”(Disjoint Setup)和“模糊设定”(Blurry Setup),还能够应对新旧类别同时出现的情况。与传统方法不同,本文不需要预先知道未来所有类别,而是允许模型灵活处理新类别的加入。
多会话损失函数设计: 作者设计了三个主要损失函数来确保模型的向后兼容性和新类别的学习能力: 会话内区分损失(Intra-session Discrimination Loss):确保新数据在当前会话中的区分能力,用于学习当前session数据的判别性表示,确保模型能够有效区分新数据的类别;
- 邻近会话模型一致性损失(Neighbor-session Model Coherence Loss):通过知识蒸馏,保持新旧模型特征空间的一致性,,避免因新模型引入而导致旧特征失效。
- 会话间数据一致性损失(Inter-session Data Coherence Loss):通过重放旧数据的特征,确保新模型与旧模型在长时间内的一致性。避免因多次更新而造成的特征空间不兼容问题。
避免特征重新提取的机制: 该方法主要针对视觉搜索中的特征一致性,重点在于如何减少新旧数据在嵌入空间中的不兼容问题,避免特征重提取带来的计算开销。本文提出了一种避免特征重新提取的机制,确保模型更新后仍然可以使用旧特征空间进行检索。这种机制不仅减少了计算量,还提高了系统在处理大规模图库时的效率,适合实际中的视觉搜索系统。
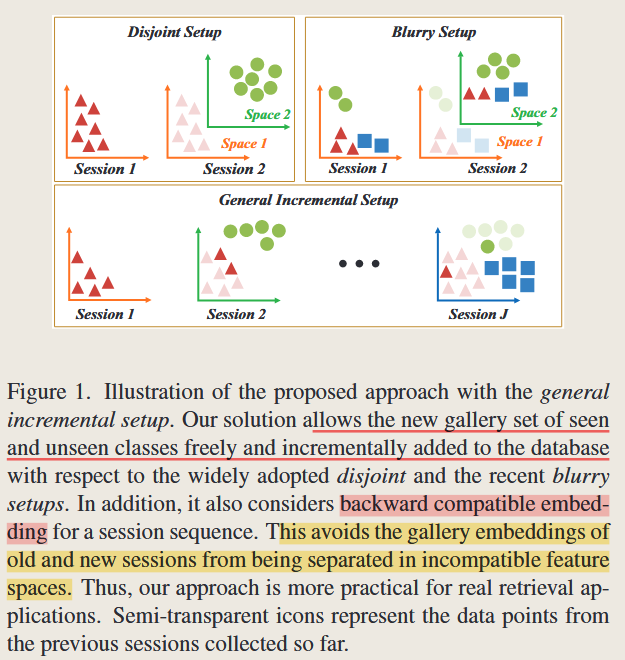
原理与技术细节
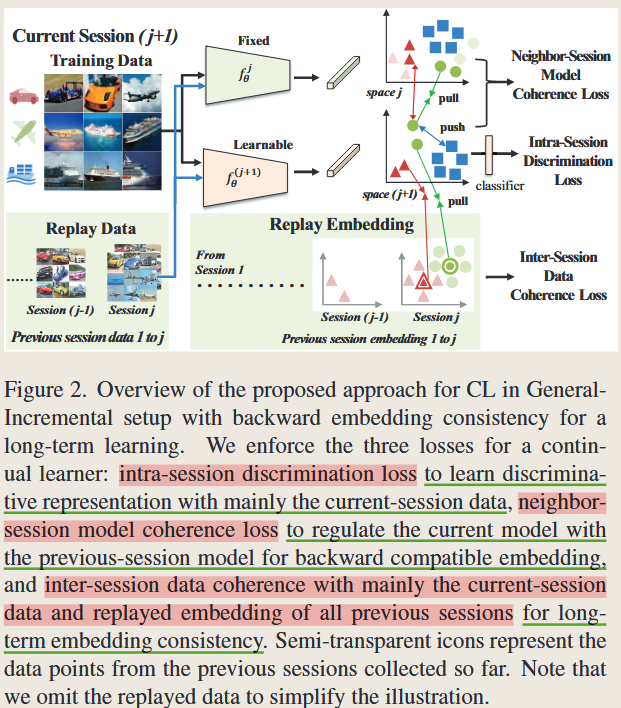
session间数据一致性损失(Inter-Session Data Coherence Loss)
设计思想与原理: session间数据一致性损失的目的是在多个session之间保持特征空间的一致性,以避免在增量学习过程中,由于特征空间变化而导致的兼容性问题。通过重放嵌入(replayed embedding)和使用少量回放数据,该损失能够确保新学习的特征与先前的嵌入空间保持兼容性。
技术细节:
旧类的特征被提取为 $g_i = f_i{G_i} \vert^{j_{i=1}}$
目标是在当前的session $j+1$ ,训练模型$f_{j+1}$从$G_{j+1}(\mathbf{g}{j+1}=f{j+1}{G_{j+1}})$ 中提取特征,且保持之前的特征$\mathbf{g}_{1:j}$保持不变
但由于不同的特征空间不一定具有可比性,为了避免单个session过拟合,将之前所有sessions的特征进行聚合起来,如下式所示
\[E_c = \frac{1}{j} \sum_{i=1}^j \xi(\mathbf{g}_{ic}),c \in C(i)\]其中 ,$C(i)$是在session $i$中出现的类别指数集,即不同的图像类别,例如猫狗可能在不同的 session都会新添加进来
$\mathbf{g}_{ic}$是 在类别$c \in G_i$中的数据的提取的特征集合, 也就是不同session,相同类别的特征
$\xi$表示 期望运算符
整个算式大概是说在不同的session $i\in 1,\dots,j$ ,将相同类别$c$的特征放在一起,然后取平均得到这个类的特征均值
第一部分损失函数为$L^{d_I}_{ {1:j};j+1} $, 目的是使得强制session间数据一致性,
\[L^{d_I}_{ \{1:j\};j+1} = \sum_{c \in \Pi_{j+1}} \sum_{x_i \in c} \Vert f_{j+1}(x_i) - E_c \Vert,\]其中 ,
$\Pi_{j+1} = \cup_{i=1}^j C(i) \cap C(j+1)$ 表示当前session $j+1$ 与所有先前session$i\in1,\dots,j$之间的重叠出现的类$c$,
$x_i$表示当前session $(j+1)$ 中属于类别$c$的数据
**整体大概是说 在第 $j+1$ 的session 中属于类$c$ 的样本$x_i$ ,它的特征提取结果$f_{j+1}$ 要与 这个类的特征均值 $E_c$ 的差别 **
也就是同一类别在不同session 下要保持特征一致性
第二部分损失函数为 $L^d_{{1:j};j+1}$, 目的也是使得不同 session 之间特征变化不要太大。只不过上面全部是基于在特征集合$E_c$下讨论的,下面的公式是考虑在 replay data中的原始数据 data
\[L^{d_o}_{ \{1:j \};j+1} = \sum_{c \in \Gamma_{j+1}} \sum_{\tilde{x}_i \in c} \Vert f_{j+1}(\tilde{x}_i) - E_c \Vert,\]其中,
$\Gamma_{j+1} = \cup_{i=1}^j C_{i}$ 代表 在旧类$C_i$在 replayed 的数据 ,这里还说使用 iCARL中的技术,在每一类的均值周围搜索邻居,作为代表数据 添加到 replay使用
$\bar{x_i}$ 表示 replay data 中的数据
整体大概是说,当新的session $j+1$ 可能不包含某个特定类$c$,但更新完之后的神经网络$f_{j+1}$ ,依然要保证这个类$c$的特征 和 这个类的特征均值保持一致,那么怎么来做呢,就是从 replay data 中来找到这个类$c$,让它来限制这个新训练后的神经网络,仍然能够保证这个类$c$的结果不变。
综上这两个方法,就得了一个综合总的损失函数,损失函数形式为:
\[L^d_{ \{1:j\};j+1} = \frac{1}{n} \left( L^{d_I}_{\{1:j\};j+1} + L^{d_o}_{\{1:j\};j+1} \right)\]使用“重放嵌入”策略,即保留每个session中的一部分嵌入,并在后续session中使用这些嵌入进行训练,以保持特征空间的一致性。
损失函数考虑了当前session与所有先前session之间的特征空间一致性。
相邻session模型一致性损失(Neighbor-Session Model Coherence Loss)
设计思想与原理:
相邻session模型一致性损失旨在通过知识蒸馏的方式保持相邻session模型之间的特征空间一致性。该损失函数通过使得当前session模型的输出与前一session模型的输出一致,来防止模型在更新过程中遗忘之前学到的特征表示。通过这种方式,模型能够在增量学习的同时,保持对旧数据的良好表现。
技术细节:
使用一种基于三元组(triplet loss)的蒸馏策略,将之前session模型(教师模型)生成的嵌入作为指导,来训练当前session模型(学生模型)。
蒸馏损失基于样本的三元组 (anchor, positive, negative) $ f_{j+1}(x_a)$, $f_j(x_a)$, and $f_j(x_n)$. 进行,其中正样本与锚点样本来自相同类别,负样本与锚点样本来自不同类别。
该损失旨在拉近正样本和锚点样本之间的距离,同时推远锚点样本和负样本之间的距离。
损失函数形式为:
\[L_{m_{j:j+1}} = \frac{1}{n} \sum_{x_a} {\left[ d_{j+1}^j(x_a, x_a) - d_{j+1}^j(x_a, x_n) + m \right]}_{+}\]其中,
$d_{j+1}^j(x, y) = \Vert f_{j+1}(x) - f_j(y) \Vert $,
$m$ 是预设的边界(默认为 0.1),
$f_j(\cdot)$ 和 $f_{j+1}(\cdot)$ 分别表示前一session和当前session的模型。
损失函数确保了当前模型的输出与前一模型的嵌入空间保持一致性,特别是在相似和不相似样本之间。
session内判别性损失(Intra-Session Discrimination Loss)
设计思想与原理:
session内判别性损失的目的是在当前session内学习判别性特征,使得模型能够有效区分当前session中的新数据类别。在视觉搜索任务中,模型需要具备区分新添加数据类别的能力,因此在当前session数据中进行分类训练是必要的。session内判别性损失通过使用分类损失(如 softmax 交叉熵损失)来实现,确保模型可以在新的数据上进行有效的判别。
技术细节:
使用 Normalized Softmax(NSoftmax)损失进行优化。该损失在分类层的输出上应用 L2 正则化,确保模型的输出嵌入向量具有统一的尺度,这有助于在视觉搜索任务中提高相似性度量的稳定性和准确性。
损失函数形式为:
\[L_{c_{j+1}} = - \frac{1}{n} \sum_{i=1}^{n} \log\left(\frac{\exp(w_{y_i}^T f_{j+1}(x_i) / T)}{\sum_{k} \exp(w_k^T f_{j+1}(x_i) / T)}\right)\]其中,$x_i$ 是当前session中的数据样本,$y_i$ 是其对应的类别标签,$w_k$ 是分类层的权重向量,
$f_{j+1}(x_i)$ 是通过当前session模型提取的 L2 归一化特征嵌入,
$T$ 是温度参数(默认为 0.05)。
整个表达式:
\[\frac{\exp(w_{y_i}^T f_{j+1}(x_i) / T)}{\sum_{k} \exp(w_k^T f_{j+1}(x_i) / T)}\]是 Softmax 函数的输出,表示样本 $x_i$ 被预测为真实类别 $y_i$ 的概率。Softmax 函数将模型的输出(logits)转换为概率分布,使得所有类别的预测概率之和为 1。
$\exp(w_{y_i}^T f_{j+1}(x_i) / T)$
- $f_{j+1}(x_i)$ 是样本 $x_i$ 的特征嵌入向量,表示通过模型第 $j+1$ 次会话训练后的神经网络提取的特征表示;
- $w_{y_i}^T$ 是与真实类别 $y_i$ 相关的权重向量;
- $\exp(\cdot)$ 是指数函数,应用于特征嵌入和权重的点积,放大其值;
- $T$ 是温度参数,用于调节 Softmax 函数的平滑度。较大的 $T$ 值使得概率分布更加平滑,较小的 $T$ 值使得分布更加尖锐。
这一项 $\exp(w_{y_i}^T f_{j+1}(x_i) / T)$ 表示模型为样本 $x_i$ 在真实类别 $y_i$ 上计算出的“非归一化概率”(logit),通过 Softmax 转换为概率。
$\sum_{k} \exp(w_k^T f_{j+1}(x_i) / T)$
- $w_k^T$ 是与类别 $k$ 对应的权重向量;
- $\sum_{k}$ 表示对所有类别的指数项求和,这个和代表所有类别的“非归一化概率”之和。
这一项 $\sum_{k} \exp(w_k^T f_{j+1}(x_i) / T)$ 是 Softmax 分母,表示所有类别的非归一化概率的总和。Softmax 函数通过对所有类别的非归一化概率进行归一化,输出各类别的概率分布。
总体损失函数
整体损失函数由以下几个部分组成:会话内区分损失、邻近会话模型一致性损失和会话间数据一致性损失。整体损失函数的表达式如下:
\[L = L_{\text{intra}} + \alpha \cdot L_{\text{coherence}} + \beta \cdot L_{\text{data\_coherence}}\]其中:
- $L_{\text{intra}}$ 是会话内区分损失(Intra-session Discrimination Loss),用于确保当前会话中新类别数据的区分性。
- $L_{\text{coherence}}$ 是邻近会话模型一致性损失(Neighbor-session Model Coherence Loss),用于保持新旧模型在特征空间中的一致性。
- $L_{\text{data _ coherence}}$ 是会话间数据一致性损失(Inter-session Data Coherence Loss),通过重放旧数据的嵌入,保持新模型对旧类别的记忆。
- $\alpha$ 和 $\beta$ 是用于调整不同损失项的权重系数。
默认情况下,我们在实验中根据经验将$\alpha$设置为 $10$,将$\beta$ 设置为 $1$,并且在这项工作中使用cos距离进行检索
向后兼容的理解
这篇文章主要讲的是 特征空间中,新的 session 不断进来,然后要保持之前的 特征空间仍然可以使用,也就是所谓的向后兼容。新训练的模型所产生的特征嵌入应与之前模型的嵌入保持一致。也就是说,当引入新类别或新任务时,新模型的特征嵌入与旧模型的特征嵌入应能够共存,从而使得模型对先前类别或任务的检索和分类性能不下降,或者只受到较小的影响。
举例说明向后兼容性
假设有一个图片搜索系统,最初训练的模型支持对10个不同的动物类别(如猫、狗、鸟等)的图片进行检索,系统通过提取图片的特征嵌入来对图片进行索引和存储。用户可以通过上传一张图片来检索相似的动物图片。
初始模型的使用:
- 初始模型已经训练好了,它可以提取每张图片的特征,并将它们嵌入到特征空间中。所有与这10个动物类别相关的图片都已经被索引好,系统可以高效地根据图片进行检索。
增量学习阶段:
假设现在有了新的需求,用户想要增加5种新的动物类别(如马、牛、鹿等),此时就需要进行增量学习。为了应对新的类别,模型必须进行重新训练,能够提取新类别图片的特征嵌入。然而,这里出现了一个问题:新的模型是否能够保持对旧类别(猫、狗、鸟等)的有效检索能力?即使模型学会了新类别,是否仍然能够高效处理之前已经索引的图片?
- 向后兼容性解决的问题:如果新模型和旧模型不兼容,用户可能会发现旧的动物类别(比如猫和狗)的检索结果变得很差,甚至无法正确识别旧图片。这就导致了“灾难性遗忘”的问题,旧类别的特征嵌入和新的特征嵌入之间出现了不兼容现象。
- 向后兼容性确保的效果:通过设计向后兼容的机制,新模型不仅能够学习新的类别特征,还能够保持与旧模型的特征空间一致。因此,系统不需要重新索引之前的所有图片,检索时,用户上传的猫和狗图片依然能够准确地匹配到数据库中已有的相关图片。同时,新增的马和牛类别的检索功能也可以正常工作。
举例总结:
在我们的例子中,向后兼容性保证了新模型在扩展系统功能(如增加新类别)的同时,能够与之前训练的模型保持一致。这样,用户既可以检索到旧类别的图片(如猫和狗),又能够检索到新类别的图片(如马和牛),并且整个系统不需要重新处理和索引原有的图片数据。这大大提高了系统的效率和性能。
思考与疑问
这篇文章提出了向后兼容的特征,这样首先就是不需要再重新来训练,其次解决了灾难性遗忘问题。
但其实有一个问题,特征随着加入的类越来越多,那么特征空间肯定会发生变化吧, 这种向后兼容的设置是否还有效,另外,这里是依赖于一个 重放嵌入(replayed embedding)和使用少量回放数据机制,也就是说不光是存储了数据,还存储了特征来保证这个长期过程中的稳定性。
还有一个点是这种向后对齐某种程度上是不是牺牲了新的类的表现,但可能我们的衡量标准是所有的类的平均检测效果,所以这种牺牲是可以接受的?
如何应对兼容性成本?
就像你提到的,这种兼容机制会带来代价。但研究人员已经提出了一些方法来缓解这一问题:
- 特征重放机制(Feature Replay):通过保存旧类的特征嵌入,而不是保存所有旧数据样本,能够在保持一定兼容性的同时减少计算和存储的开销。这样避免了必须重新处理旧类的全部数据。
- 弹性网络方法:一些方法,如弹性权重整合(EWC),通过为旧类分配重要性权重来保护与旧任务相关的权重。这种方式可以在不大幅增加计算量的前提下,保持兼容性。
- 动态扩展模型:在一些更加灵活的模型中,可以动态增加模型的容量(如通过网络剪枝或模型扩展),从而为新类别提供更多的参数资源,同时减轻旧类别嵌入的漂移。这类方法可以在一定程度上缓解特征空间饱和的问题。
总结与展望
综上所述,向后兼容性在持续学习中是一个有效但存在挑战的机制。初期的兼容性效果较好,但随着类别增多和特征空间饱和,长期兼容性会逐渐变得困难。与 Windows 向后兼容一样,维护这种兼容性确实有代价,但研究界已经在努力提出各种机制来降低这种成本(如特征重放、知识蒸馏、模型扩展等)。
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/09/27/Paper-Reading-Note-3-Continual-Learning-in-Image-Retrieva-BCT(AI)/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)