Paper Reading 6 Continual learning LLM 2
论文信息
Continual Learning of Large Language Models: A Comprehensive Survey
[2404.16789] Continual Learning of Large Language Models: A Comprehensive Survey
论文主要内容
AI总结
以下是对论文 《Continual Learning of Large Language Models: A Comprehensive Survey》 的分析和概括:
Scope or Setting
本论文探讨了持续学习(Continual Learning, CL)在大型语言模型(LLMs)中的应用,旨在解决在不断变化的数据分布中如何适应并保持模型性能的问题。主要研究对象为从一般到特定领域的迁移(垂直持续学习)以及跨时间和领域的适应(水平持续学习)。
Key Idea
论文的核心观点是,尽管CL技术在机器学习领域已有广泛研究,但LLMs在CL背景下提出了独特挑战,例如“灾难性遗忘”(Catastrophic Forgetting)。论文提出两种主要连续性方向:
- 垂直连续性(Vertical Continuity):从通用能力向特定领域的逐步迁移。
- 水平连续性(Horizontal Continuity):跨时间和领域的连续适应。
Method
论文分为以下主要部分:
基础介绍:回顾LLMs和CL的基本概念与研究背景。
学习阶段
:讨论CL在LLMs中的三个阶段:
- 持续预训练(CPT)。
- 领域自适应预训练(DAP)。
- 持续微调(CFT)。
评估协议:概述用于CL和LLMs的评估指标和基准。
研究问题:探讨尚未解决的关键问题及未来研究方向。
论文还结合具体案例,详细介绍CL技术在LLMs中的实现,包括参数扩展、回放和正则化方法等。
Contribution
- 新颖框架:首次提出垂直与水平连续性的明确区分,为CL在LLMs中的应用提供了系统分析。
- 评估总结:整理了适用于LLMs的评估协议及CL技术。
- 技术指南:为未来的CL与LLMs研究提供了详细的技术和理论基础。
- 领域划分:将不同任务如语言迁移、内容适应和时间序列更新归纳为CL的具体挑战。
Difference and Innovation
论文的主要创新在于将CL问题适配到LLMs的新情景中,提出CL的垂直和水平分层模型框架。此外,它探讨了在LLMs的大规模动态环境中,传统CL技术(如回放与正则化)的局限性和改进方向。
Results and Conclusion
- CL技术可以显著提高LLMs对新领域和新任务的适应能力,同时有效缓解遗忘问题。
- 垂直学习需要针对特定领域的优化,而水平学习更需要应对任务序列中的分布突变。
- 论文呼吁开发更实用、可访问的评估基准和针对LLMs的CL新技术。
Contrast with Other Methods
与传统CL方法相比,论文中提到的CL技术需要面对以下新挑战:
- 模型规模的限制:LLMs参数规模远超传统模型,存储和计算成本高。
- 知识转移:垂直CL和水平CL在知识保持和转移方面的需求不同。
Discussion and Proof
论文强调当前CL技术在LLMs中尚有许多未解决的问题:
- 如何平衡旧知识保持与新知识学习。
- 现有评估协议的有效性和适用性。
- 针对特定场景(如语言迁移、时间变化)开发更高效的CL策略。
如果需要进一步分析或可视化数据,请告知!
论文主要内容
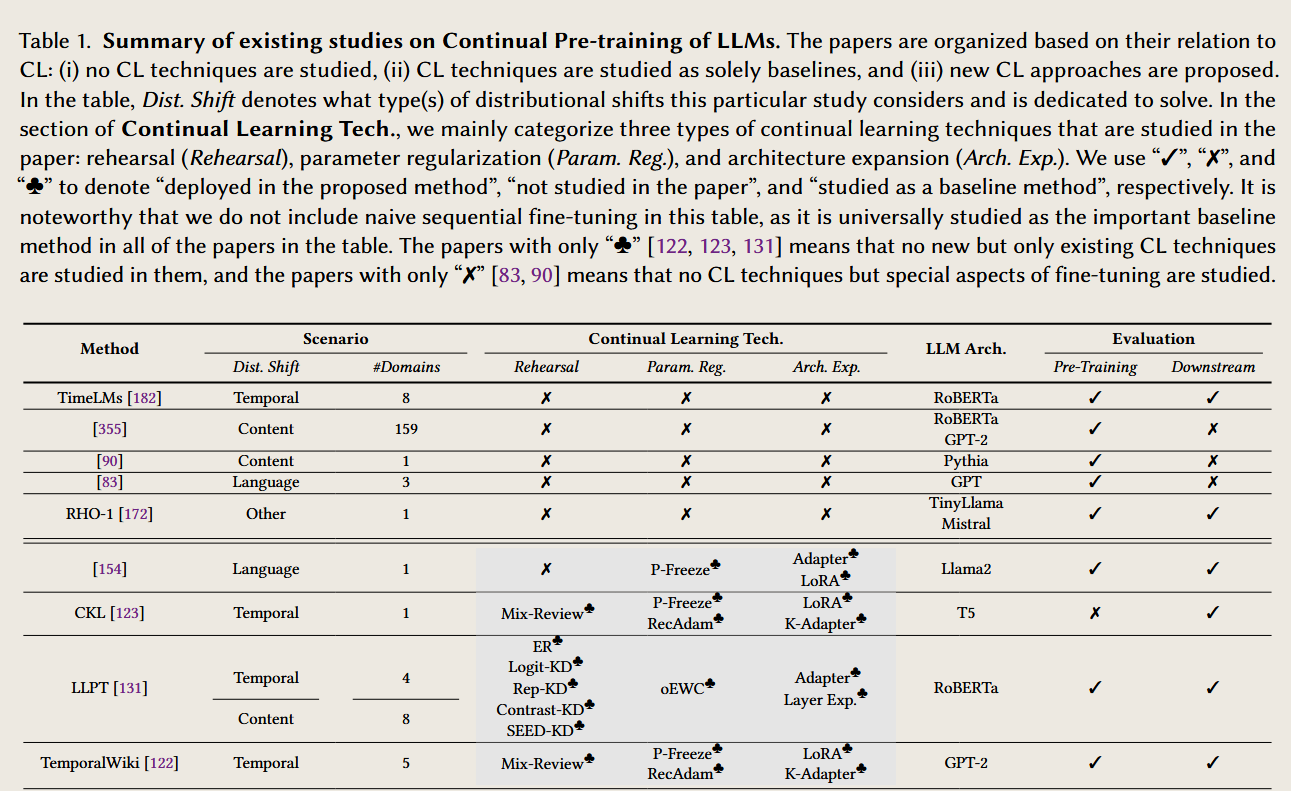
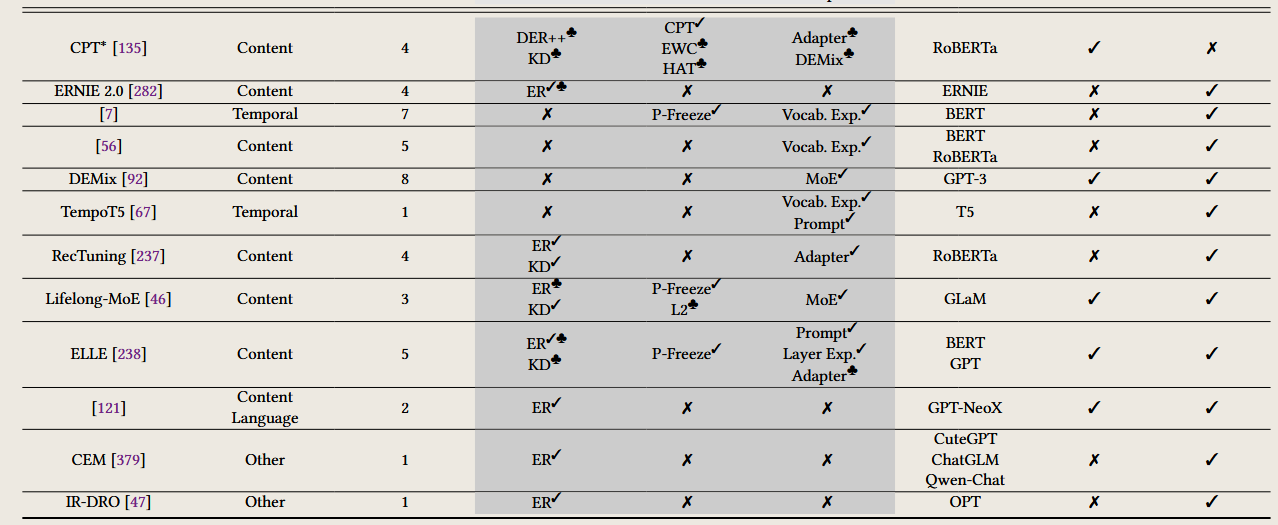
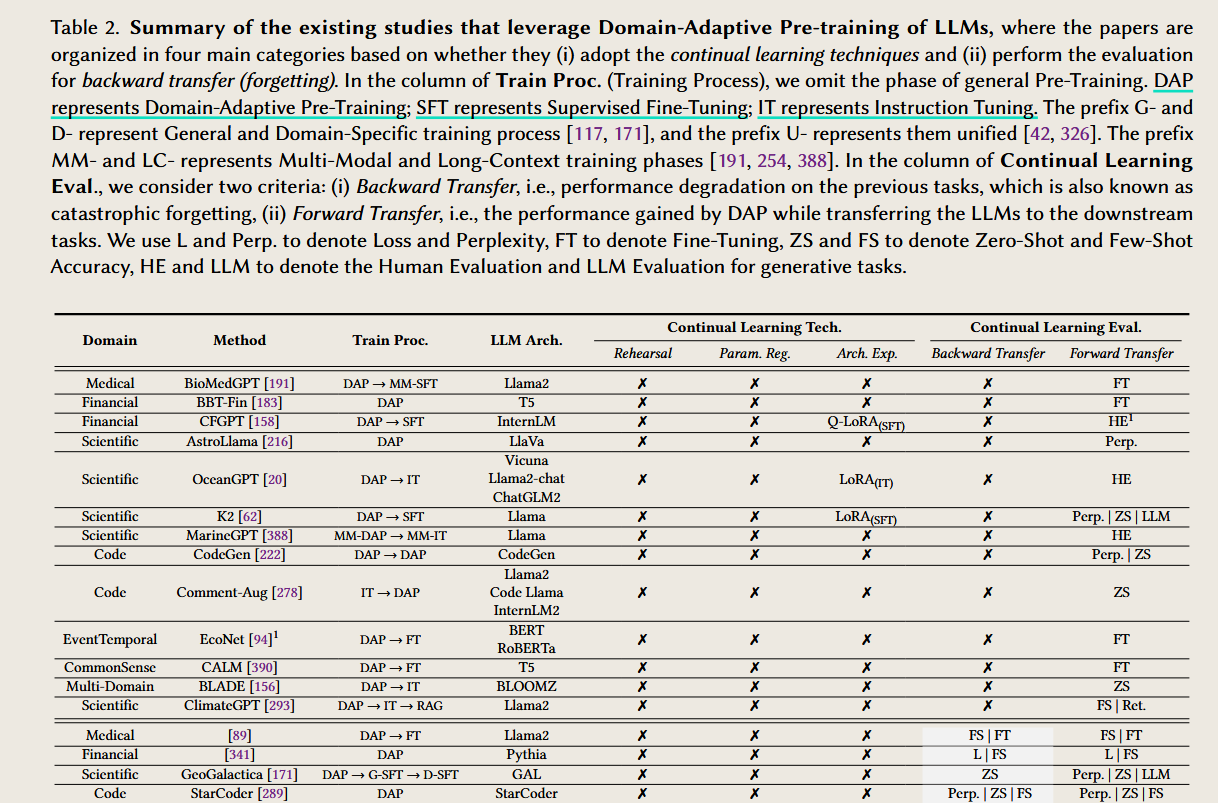
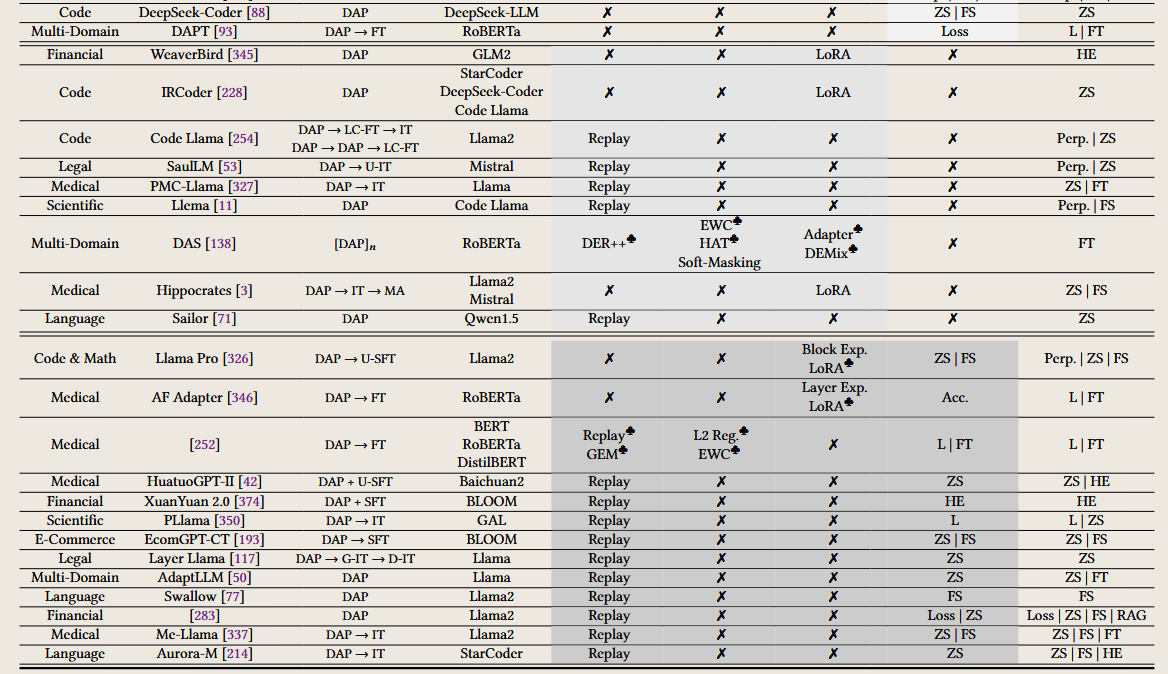
图中提到的缩写介绍
以下是按照持续学习的三个内容分类(CPT、DAP、CFT)对文中提到的多个缩写的详细解释及含义:
1. 持续预训练(Continual Pre-Training, CPT)
CPT 的核心在于应对动态数据分布(如时间、领域、语言)变化,以下是常见的缩写解释:
Temporal Shift(时间变化)
- 含义:指数据分布随着时间的变化而发生转移,例如新闻数据每年更新。
- 实例:从 2023 年的数据迁移到 2024 年的新数据,需同时保留旧知识和适应新知识。
- 挑战
- 时间信息更新,例如“某运动员效力于某队”的信息变化。
- 遗忘旧时间点的数据特性。
Content Shift(内容变化)
- 含义:指模型需要适应数据内容的领域变化,例如从化学数据迁移到生物学数据。
- 实例
- 从金融领域预训练数据转移到法律领域数据。
- 不同领域之间的语义差异可能导致模型性能下降。
- 挑战
- 不同领域数据分布的显著变化可能导致灾难性遗忘。
- 内容间共性知识的挖掘(如基本语法和语言结构)。
Language Shift(语言变化)
- 含义:指模型需要在多语言语料中逐步适应新语言。
- 实例
- 从英语语料迁移到中文语料。
- 学习新语言的同时保留原有语言的能力。
- 挑战
- 新语言和旧语言可能在词汇、语法结构等方面存在冲突。
- 多语言知识的共享和独立性平衡。
2. 持续领域自适应预训练(Continual Domain-Adaptive Pre-Training, DAP)
DAP 的目标是通过领域特定语料增强模型的专业知识,同时保持通用能力。以下是相关缩写解释:
DAP(Domain-Adaptive Pre-training)
- 含义:在领域特定的无标签数据上进一步训练模型以提升领域适应性。
- 实例
- 在医学语料上对通用模型进行领域自适应预训练。
- 特点
- DAP 是垂直方向知识迁移的中间阶段。
- 适配领域语料的同时需要避免通用能力退化(“垂直遗忘”)。
SFT(Supervised Fine-Tuning)
- 含义:在有监督标签数据上进行微调,以优化模型在特定任务上的性能。
- 实例
- 在标注的医学诊断数据上微调医学模型。
- 特点
- 多用于领域预训练后的下游任务微调阶段。
IT(Instruction Tuning)
- 含义:通过有监督数据训练模型,以提高其对自然语言指令的响应能力。
- 实例
- 使用标注的指令-响应数据训练模型生成符合人类预期的输出。
- 特点
- 强调模型对指令和任务的适应性优化。
- 常用于提高 LLM 的对话能力。
MM(Multimodal)
- 含义:涉及多模态数据的领域自适应,如同时处理图像、文本和声音数据。
- 实例
- 在图文结合的数据上训练模型,提升多模态任务能力。
- 特点
- 需要设计适配多模态数据的模型结构(如视觉模块和语言模块的融合)。
3. 持续微调(Continual Fine-Tuning, CFT)
CFT 主要关注具体任务中的性能优化,同时减少新任务对旧任务的负面影响。以下是相关缩写解释:
COIT(Continual Instruction Tuning)
- 含义:在多阶段指令数据上逐步优化模型,以提高其对指令任务的持续适应能力。
- 实例
- 训练一个问答模型,在不同时间点添加新问题数据。
- 特点
- 需要同时保持旧指令任务的表现。
- 强调任务间的知识迁移和适应。
CMR(Continual Model Refinement)
- 含义:通过增量更新模型参数,对其进行逐步优化,同时减少对现有知识的破坏。
- 实例
- 对模型在细分任务上的表现进行精调,如针对特定病种的分类任务。
- 特点
- 注重优化模型对新任务的性能,同时尽量不影响其他任务表现。
CMA(Continual Model Alignment)
- 含义:持续调整模型,使其更符合人类偏好或特定规范。
- 实例
- 对生成式模型进行微调,使其生成的内容符合伦理要求。
- 特点
- 需要在优化新目标的同时不引入偏差或损害已有能力。
CLMMLs(Continual Learning in Multimodal LLMs)
- 含义:在多模态大语言模型中实现持续学习。
- 实例
- 对同时处理图像和文本的模型进行增量训练,适应新的多模态任务。
- 特点
- 需要解决多模态数据之间的知识迁移与整合问题。
总结
- 垂直方向知识转移(CPT 和 DAP)侧重于从通用到领域再到任务的逐步优化,强调模型在分阶段适应中的能力平衡。
- 水平方向知识转移(CFT)更注重动态任务序列中的连续优化,尤其是在新任务适应与旧任务保持之间的平衡。 这些缩写反映了论文在不同层面和方向上对持续学习问题的细化研究,同时为特定场景提供了解决方案和优化思路。
AI对话
问题一 LLM 的continual learning 有什么不同?
传统的Continual learning 方法和大模型下的continual learning 有什么区别,比如应用的场景,关注的问题,常见的设置等
传统的持续学习(Continual Learning,CL)方法与大模型(Large Language Models, LLMs)下的CL在以下几个方面存在显著差异,包括应用场景、关注问题以及常见设置:
1. 应用场景的差异
传统CL:
- 任务特点
- 主要用于中小规模模型,如分类任务、图像识别和强化学习。
- 任务多为明确界定的、离散的,例如多个分类任务的逐步学习。
- 实际场景
- 自动驾驶(处理不同场景的感知任务)。
- 医学诊断(逐步引入新病种的诊断)。
- 工业控制(增加新功能时不破坏已有功能)。
LLMs中的CL:
- 任务特点
- 应用于大规模模型的知识管理,任务常为动态、连续的,如语言迁移、内容更新和用户偏好适配。
- 涉及的任务通常更复杂,包括文本生成、知识回答和多模态任务。
- 实际场景
- 社交媒体(更新趋势语言)。
- 医学文本分析(适配新医学术语或研究成果)。
- 企业知识库(持续整合新知识)。
2. 关注问题的差异
传统CL:
- 灾难性遗忘
- 解决新任务的学习对旧任务表现的负面影响。
- 模型复杂性
- 注重轻量级模型设计,适应有限计算资源。
- 任务界限明确
- 假设任务之间具有明确的边界,模型训练和评估均基于分离的任务。
LLMs中的CL:
- 知识保持与转移
- 更关注在知识的多阶段(如预训练到微调)中保持通用能力。
- 水平与垂直连续性
- 强调跨领域(水平)和逐步适配特定领域(垂直)时的性能均衡。
- 动态分布
- 应对动态的数据分布,例如社交媒体中随时间变化的语言趋势。
- 计算资源挑战
- LLM模型规模大,计算和存储成本高,需要开发高效的CL方法。
3. 常见设置的差异
传统CL:
- 任务设置
- Task-Incremental Learning:不同任务间模型有任务ID区分。
- Domain-Incremental Learning:输入分布发生变化但任务类型不变。
- Class-Incremental Learning:类别逐步增加,任务界限模糊。
- 评估方式
- 平均准确率(Average Accuracy, ACC)。
- 遗忘率(Forgetting Measure, FM)。
- 方法技术
- 重放机制(Replay-based):存储小样本库进行回放。
- 参数正则化(Regularization-based):限制模型参数更新。
- 架构扩展(Architecture Expansion-based):通过增加模型容量适应新任务。
LLMs中的CL:
- 任务设置
- 垂直连续性:从通用预训练到特定领域再到任务微调的分阶段学习。
- 水平连续性:随时间和领域变化动态适配。
- 评估方式
- 性能矩阵(Performance Matrix):记录每阶段的模型性能。
- 前向迁移(Forward Transfer, FWT):新任务对后续任务的提升。
- 后向迁移(Backward Transfer, BWT):新任务对旧任务的帮助或损害。
- 方法技术
- 参数高效微调(PEFT):如LoRA。
- 知识蒸馏:减少更新对原有知识的破坏。
- 模块化设计:通过独立模块处理特定领域。
4. 性能目标的差异
传统CL:
- 优化目标:
- 最大程度减少遗忘,同时提升新任务的学习能力。
- 挑战:
- 强约束下如何兼顾旧任务表现与新任务学习。
LLMs中的CL:
- 优化目标:
- 平衡知识保持(如通用语言能力)和新知识学习(特定领域适应)。
- 提升模型在动态任务序列中的鲁棒性和泛化能力。
- 挑战:
- 高昂的计算成本:如何通过更少数据和训练步骤完成有效更新。
- 模型存储:设计能动态扩展但不冗余的架构。
5. 方法与技术对比
| 特点 | 传统CL | LLMs中的CL |
|---|---|---|
| 数据规模 | 小规模、离散数据 | 大规模、连续动态数据 |
| 任务复杂性 | 分类和回归等简单任务 | 生成式任务、跨模态和动态语境 |
| 灾难性遗忘 | 显著,主要通过回放等解决 | 较低,但知识更新与保持难以平衡 |
| 评估方法 | 准确率、遗忘率 | 矩阵形式(前向迁移、后向迁移) |
| 模型技术 | 小型参数正则化、简单架构扩展 | 大型模型参数高效微调、模块化设计 |
总体而言,LLMs中的CL需要更多地关注知识的动态管理和多领域适配,而传统CL更强调在有限资源下多任务间性能的均衡。
问题二 文章的分类
文中vertical continuity 分为了三个层面,每个层面都有着对应的持续学习的概念,那么这三个层面的持续学习有什么联系和区别
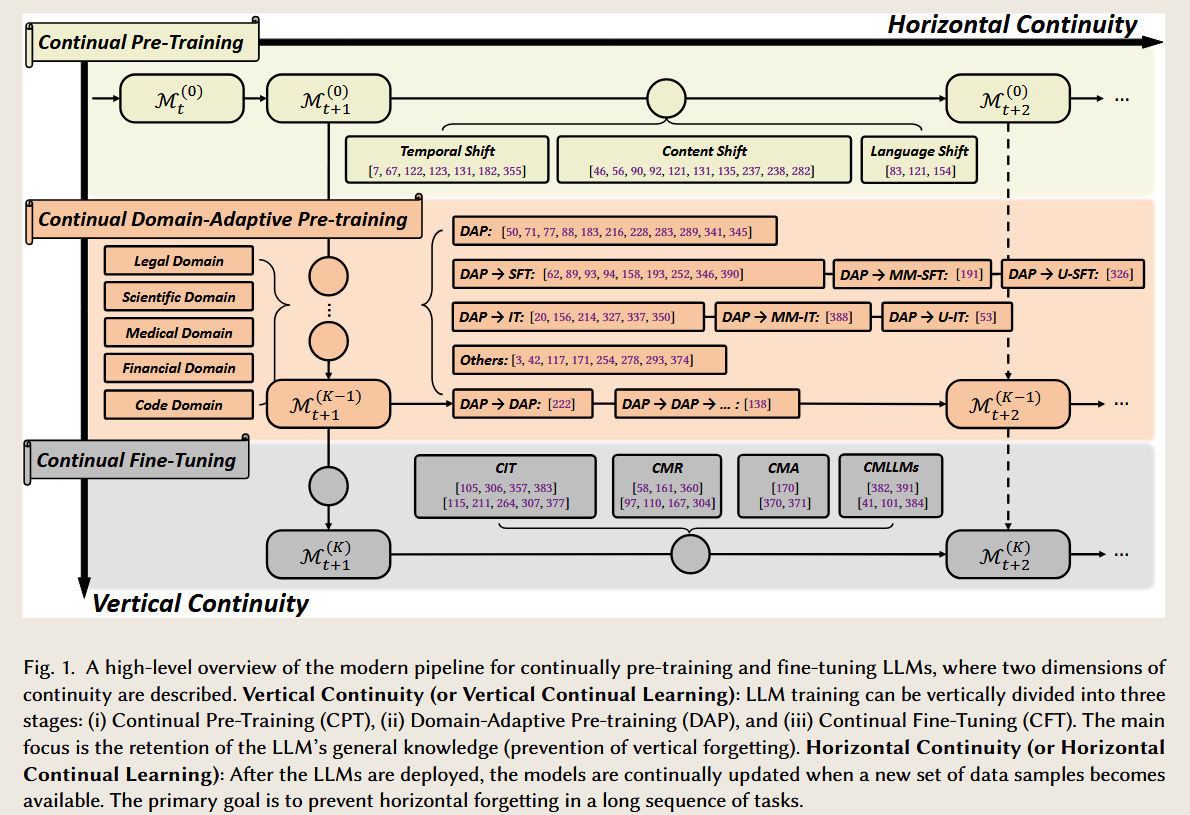
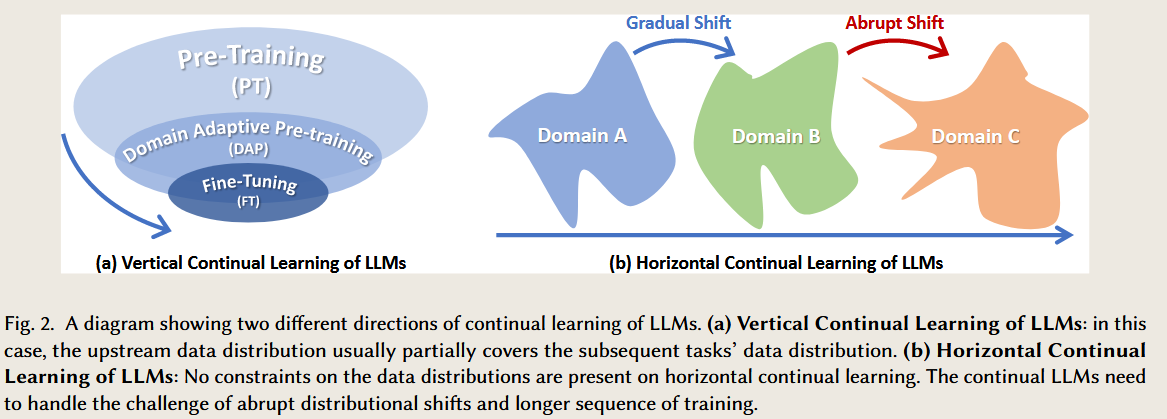
论文中关于垂直连续性(Vertical Continuity) 的讨论,将其划分为三个层面:持续预训练(Continual Pre-Training, CPT)、领域自适应预训练(Domain-Adaptive Pre-training, DAP) 和 持续微调(Continual Fine-Tuning, CFT)。这三个层面既有内在联系,又有显著区别,以下从概念、目标、实现方法和挑战等方面进行分析。
1. 三个层面的定义与目标
| 层面 | 定义 | 目标 |
|---|---|---|
| 持续预训练 (CPT) | 在通用语料上对模型进行多阶段的预训练,以适应不断变化的大规模数据分布(如新数据或时间序列)。 | 提升模型的通用能力,同时减少对已有知识的遗忘,实现基础层面的动态适应。 |
| 领域自适应预训练 (DAP) | 在领域特定的无标签数据上进一步训练通用模型,使其更好地适应特定领域的需求(如医学、法律)。 | 增强领域知识的表达能力,保留通用知识并为后续下游任务微调提供高质量的初始模型。 |
| 持续微调 (CFT) | 在小规模、有标签的下游任务数据上逐步调整模型参数,以优化特定任务的性能(如分类、生成)。 | 最大化特定任务的性能,同时减少对其他任务性能的负面影响,特别是应对动态任务序列。 |
2. 联系:层次递进与协同作用
递进式流程:
- 阶段依赖性:CPT 为 DAP 和 CFT 提供通用的语言能力基础;DAP 进一步在领域层面增强模型;CFT 最终将知识迁移到特定任务。
- 知识传递:模型在前一阶段的知识成为后一阶段的基础。例如,CPT 保持的语言通用能力为 DAP 提供更好的初始化,而 DAP 的领域适配能力为 CFT 提供更有针对性的模型。
共同挑战:
- 灾难性遗忘:各阶段均需解决新知识学习导致的旧知识丢失问题。
- 效率与资源约束:如何高效地利用有限计算资源(尤其是CPT阶段)并将模型更新规模最小化。
评估与优化:
- 统一评估框架:如性能矩阵和前向/后向迁移指标,用以量化各阶段对任务表现的影响。
- 技术共享:如参数正则化(Regularization)、回放机制(Replay)等方法在不同层面均有应用。
3. 区别:侧重点与技术实现的不同
| 特性 | CPT | DAP | CFT |
|---|---|---|---|
| 关注范围 | 通用语言能力的动态扩展 | 领域知识的定向增强 | 下游任务的具体性能优化 |
| 数据特点 | 大规模、无标签、多领域的语料 | 中等规模、无标签、特定领域数据 | 小规模、有标签的任务数据 |
| 任务性质 | 全局适应,数据分布的时间序列变化 | 领域适应,领域间的数据分布差异 | 任务适应,不同任务目标的逐步学习 |
| 灾难性遗忘风险 | 主要体现在语言通用知识的丢失 | 主要体现在通用知识向领域知识的过拟合,导致通用能力下降 | 主要体现在对已有任务的负面迁移影响 |
| 技术实现 | 参数高效扩展(LoRA),新数据过滤,动态预训练方法 | 领域专家模块(Experts),回放通用数据,蒸馏技术 | 数据增强,模型裁剪,多任务学习,优化特定任务数据的适配性 |
| 挑战 | 数据分布动态性大、计算开销高 | 数据来源多样性、领域知识的选择和综合 | 模型小样本学习、动态任务序列中的高效更新 |
4. 实例对比与应用场景
CPT的实例:
- 案例:更新模型以适应社交媒体语言的变化(如2023年新词)。
- 场景:Twitter 数据流的时间序列学习(时间分布)。
DAP的实例:
- 案例:在医学领域数据上进一步训练通用模型,增强医学术语的理解。
- 场景:开发医学助理系统,整合领域知识(内容分布)。
CFT的实例:
- 案例:将经过领域预训练的模型微调用于特定任务(如疾病诊断的分类任务)。
- 场景:医疗影像分析的疾病分类任务(任务分布)。
5. 结论
- 联系:CPT、DAP 和 CFT 是垂直连续学习的三个层次,逐步从通用能力适应到领域能力,再到任务能力,体现出一种自上而下的渐进式知识转移框架。
- 区别:每个阶段的侧重点、数据特性、技术实现和目标都不同,反映了垂直连续性中从广度到深度的逐步收敛过程。
- 综合视角:有效的垂直连续学习需结合三个阶段的特性,设计贯穿整个框架的优化策略,确保知识迁移和保持的高效性与鲁棒性。
问题三 文章的结论
文中 总结的在这三个层面的 General Observations 是什么,怎么理解和解释
论文中关于持续预训练(Continual Pre-Training, CPT)、领域自适应预训练(Domain-Adaptive Pre-Training, DAP) 和 持续微调(Continual Fine-Tuning, CFT) 各自总结了General Observations(通用观察),这些观察揭示了每个层面在方法、技术和挑战上的共性和特性。以下是每个层面的具体总结和分析,以及如何理解这些观察。
1. 持续预训练(CPT)的 General Observations
总结:
- OBS-1:CPT 的技术开发尚处于起步阶段,大多数研究聚焦于适配性(Adaptation)而非解决灾难性遗忘问题。
- OBS-2:CPT 中采用的持续学习技术多样性不足,方法主要集中于架构扩展(Architecture Expansion),如使用模块化结构。
- OBS-3:现有研究与真实生产环境的差距显著。例如,实际场景中的持续预训练通常涉及更长时间序列和更多领域,但现有研究大多基于短时间、有限数据的实验。
理解与解释:
- 技术局限性:持续预训练的技术主要关注如何处理大规模数据分布变化的适配,但针对遗忘的研究较少,显示出传统 CL 技术在大型模型中的直接移植存在难度。
- 方法单一性:当前主要采用参数扩展(如 LoRA 模块)等方法,这些方法在应对模型参数规模和灾难性遗忘方面效果有限。
- 现实需求:CPT 的研究多停留在学术实验阶段,缺乏对真实环境(如动态数据流、多任务序列)的模拟和应对。
2. 领域自适应预训练(DAP)的 General Observations
总结:
- OBS-1:DAP 通常只涉及单阶段训练(如通用模型 → 领域模型),持续性的领域适应较少被研究。
- OBS-2:DAP 在解决垂直遗忘问题上的研究受到关注,部分研究主动采用持续学习技术缓解领域自适应中的通用能力退化。
- OBS-3:虽然 DAP 使用了一些持续学习技术(如回放和参数扩展),但技术多样性不足,对复杂 CL 技术的研究有限。
理解与解释:
- 训练模式的局限性:现有研究多为单次的领域适配(如从通用语料迁移到医学语料),未充分考虑多阶段 DAP 场景的连续性需求。
- 垂直遗忘的关注:领域数据引入可能导致通用能力的退化,研究倾向于通过方法(如通用数据的重放)来减轻这种影响。
- 技术瓶颈:DAP 的方法局限于简单 CL 技术(如参数冻结或小范围重放),尚未充分利用高级 CL 技术(如多任务优化或知识蒸馏)。
3. 持续微调(CFT)的 General Observations
总结:
- OBS-1:CFT 更接近于传统的持续学习场景,任务之间界限更加明确,因此传统 CL 方法如回放和正则化在该场景中应用较多。
- OBS-2:由于 CFT 需要针对具体任务优化,因此其对灾难性遗忘的关注更为显著,强调旧任务性能保持和新任务适应之间的平衡。
- OBS-3:CFT 的研究更多地集中在任务适应性,而对高效性和可扩展性研究不足,尤其是在多任务序列中的动态更新方面。
理解与解释:
- 任务界限清晰:CFT 场景下的任务通常是离散的,因此传统 CL 技术可以直接应用,如经验重放和正则化。
- 适应性挑战:新任务的引入可能对旧任务性能造成显著影响,研究需权衡任务间的知识迁移与保持。
- 效率问题:实际环境中,模型可能面临大量下游任务的动态变化,如何高效地进行逐步更新是一个重要问题。
综合分析:联系与解释
- 观察的共性:
- 灾难性遗忘:所有层面都涉及如何减少知识丢失的挑战,但每个层面的侧重点不同(CPT:通用能力,DAP:领域适配能力,CFT:任务性能)。
- 技术单一性:尽管各层面都在使用 CL 技术,但当前方法多为简单扩展或回放,未充分利用复杂的多任务优化技术。
- 真实场景差距:研究多基于实验室环境的静态或短期任务,未能有效模拟真实场景中的动态连续学习需求。
- 观察的差异性:
- 适应目标不同:CPT 专注于通用能力的动态扩展,DAP 注重领域知识的优化,CFT 则聚焦于特定任务性能的极致优化。
- 技术适配性:CFT 更适合传统 CL 方法,而 CPT 和 DAP 对 CL 技术提出了新的要求,需开发适应大规模模型的高效方案。
- 未来研究方向:
- 在 CPT 和 DAP 中引入更多高级 CL 技术(如多模态融合、动态架构扩展)。
- 针对 CFT 提升动态序列任务的高效更新能力,开发更灵活的模型优化策略。
通过这些观察的总结与解释,我们可以更好地理解论文中对垂直连续性不同层面的分析框架,并为进一步研究提供指导。
问题四 OB 3 的效率问题 怎么理解
在 持续微调(Continual Fine-Tuning, CFT) 中提到的效率问题,主要指的是在动态任务序列中如何以最少的资源开销(包括计算、存储和时间)完成模型的逐步更新,同时确保模型性能和知识保持。这一问题可以从以下几个维度来理解:
1. 动态任务序列的复杂性
CFT 需要在多个下游任务上逐步优化模型性能,这些任务可能是:
- 新增任务:如企业知识库中添加新类别的分类任务。
- 变化任务:如某一任务的输入分布随着时间变化(例如新闻分类中的主题更新)。
- 并行任务:可能需要同时处理多个任务,要求模型具备多任务适配能力。
挑战:
- 任务规模的增长:随着时间推移,任务数量和数据规模可能显著增加,导致逐步训练的时间和资源开销显著上升。
- 任务间冲突:新任务的引入可能对旧任务性能造成损害,需要设计高效策略避免负迁移。
理解:如何在动态的任务序列中实现高效更新,是解决效率问题的核心目标。
2. 模型参数更新的高成本
CFT 的一个关键问题在于模型更新的计算和存储成本:
计算成本
:
- 大型语言模型(LLMs)的参数规模巨大(如数十亿或更多),微调涉及大量的参数更新,训练时间可能十分冗长。
- 对于实时需求(如在线客服系统),这种高计算成本可能不现实。
存储成本
:
- 每次任务的微调可能会保存新的模型版本,导致存储需求指数增长。
- 如果需要对任务序列的每一阶段进行回放,则需存储大量的历史任务数据。
理解:优化参数更新策略,减少模型参数的冗余修改或存储需求,是提高效率的关键方向。
3. 灾难性遗忘与效率的权衡
在CFT中,为了避免灾难性遗忘(新任务对旧任务性能的破坏),通常会使用以下方法:
- 经验回放(Replay):保留旧任务数据或样本进行重放,确保模型记住旧任务。
- 正则化约束(Regularization):对模型参数更新施加约束,防止旧任务参数发生剧烈变化。
- 多任务优化(Multi-task Optimization):在多个任务上同时优化,提升任务间的知识共享。
挑战:
- 经验回放需要存储大量旧任务样本,存储成本高,且可能带来额外的计算负担。
- 正则化方法需要在参数更新时计算额外的约束项(如Fisher信息矩阵),增加了计算开销。
- 多任务优化需要同时加载多任务数据,导致显著的资源消耗。
理解:如何在保持旧任务性能的前提下减少这些方法的计算和存储开销,是效率问题的重要体现。
4. 现有方法的效率瓶颈
现有 CFT 技术在效率方面的不足体现在:
- 过多依赖全模型微调:微调时更新模型的所有参数,虽然可以提升任务性能,但计算和存储成本高。
- 缺乏任务间知识共享机制:如果每个任务都单独更新模型,容易造成重复计算,未能充分利用已有知识。
- 缺少针对动态场景的优化:现有技术多针对静态环境设计,难以高效应对任务序列中频繁变化的需求。
理解:这些效率瓶颈说明需要开发新的优化策略,使模型在动态场景下更加轻量化。
5. 可能的解决方案
技术方向:
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
:
- 使用低秩适配(LoRA)或其他模块,仅更新少量参数,显著降低计算成本。
- 实现对特定任务的高效适配,而无需更新整个模型。
模块化设计
:
- 为不同任务引入独立模块(如专家模块),仅更新与任务相关的部分,而非整个模型。
- 例如,在医学任务中添加医学专家模块,其他任务无需更新。
动态选择机制
:
- 根据任务特点动态选择模型或模块,仅使用最相关的部分参与计算。
高效存储策略
:
- 通过压缩方法存储模型更新或历史任务数据,降低存储成本。
- 例如,使用知识蒸馏将模型压缩为小规模版本。
理解:通过这些方法,可以在保证模型性能的同时减少计算和存储开销,从而提高 CFT 的效率。
6. 总结
CFT 中的效率问题反映了如何在有限资源下实现动态任务序列的高效更新这一核心挑战。解决这一问题的关键在于:
- 优化参数更新机制:减少无关参数的修改或存储需求。
- 提升知识共享能力:通过模块化设计和多任务优化减少冗余计算。
- 适应动态场景:开发能高效处理任务序列变化的新方法。
这既是持续学习研究中的热点问题,也是实现LLMs大规模应用的现实需求。
问题五 文中提到的知识转移,分别在垂直和水平方向上包含哪些层面与意思
论文中提到的知识转移(Knowledge Transfer) 是持续学习中一个核心概念,分别在垂直方向(Vertical Continuity) 和 水平方向(Horizontal Continuity) 体现了不同的层面和内涵。以下是对两种方向上知识转移的详细分析:
1. 垂直方向上的知识转移
垂直方向强调从通用知识到领域知识再到特定任务知识的逐步迁移,涉及逐层递进的知识传递和适配。
主要层面
- 持续预训练(Continual Pre-Training, CPT):
- 知识转移含义:从通用预训练语料中学习广泛的语言知识,作为后续阶段(领域适配和任务微调)的知识基础。
- 目标:在大规模数据中累积通用语言能力(如上下文理解、语法规则),同时减少知识丢失(如“垂直遗忘”)。
- 实例:在多语言语料中预训练,提升模型的语言生成和理解能力。
- 领域自适应预训练(Domain-Adaptive Pre-Training, DAP):
- 知识转移含义:从通用模型迁移到特定领域模型,通过领域语料学习专业知识。
- 目标:增强领域特定能力,同时保持通用知识(如医疗或法律领域的语义理解)。
- 实例:将通用语言模型(如GPT)适配到医学领域语料,增强医学术语处理能力。
- 持续微调(Continual Fine-Tuning, CFT):
- 知识转移含义:将领域模型进一步迁移到具体任务,提升对任务的适应性。
- 目标:最大化任务性能,同时尽量减少对领域知识和通用知识的破坏。
- 实例:从医学领域模型微调到癌症诊断分类任务。
核心特性
- 层级递进
- 知识由通用到具体逐步传递,每个阶段为下一阶段提供初始化或强化的起点。
- 挑战
- 知识保持:如何在迁移过程中减少前一阶段知识的遗忘(例如,CPT 中累积的通用知识不应在 DAP 中丢失)。
- 适应性平衡:如何在保持通用能力的同时增强领域适应性。
2. 水平方向上的知识转移
水平方向强调模型在时间序列和多领域任务中的动态适配,体现为横向迁移。
主要层面
- 时间序列的迁移:
- 知识转移含义:在数据分布随时间变化时,模型逐步学习新知识,同时保持旧知识。
- 目标:更新与当前任务相关的信息(如新闻事件),避免遗忘过时的关键知识。
- 实例:将新闻分类模型从2023年的新闻更新到2024年,同时保持对旧新闻的分类能力。
- 跨领域的迁移:
- 知识转移含义:在多个领域之间迁移知识,提升模型对不同领域任务的通用性。
- 目标:学习领域间的共享特性(如常用语法或词义),同时适应领域特有内容。
- 实例:从金融领域模型迁移到医疗领域模型,并确保跨领域性能稳定。
核心特性
- 动态适配
- 强调模型在新任务或数据中对新知识的快速学习能力。
- 挑战
- 时间序列中的知识矛盾:时间序列中可能出现冲突信息(如“某球员效力于某队”的信息更新)。
- 领域间知识整合:不同领域可能有知识冲突或不一致,如何平衡领域间的适应性是一个难题。
3. 垂直与水平知识转移的联系与区别
| 特性 | 垂直方向知识转移 | 水平方向知识转移 |
|---|---|---|
| 迁移目标 | 从通用知识到特定领域知识再到任务知识的递进迁移。 | 从时间序列或多领域中动态适配新知识,同时保持旧知识。 |
| 任务特点 | 知识层次明确:通用 → 领域 → 任务。 | 知识分布动态:时间序列变化或领域切换频繁。 |
| 适应性重点 | 增强逐步迁移的适应性,保持跨阶段知识稳定。 | 解决多领域或时间序列中知识更新与保持的冲突。 |
| 遗忘风险 | 垂直遗忘(如领域学习导致通用知识退化)。 | 水平遗忘(如新任务导致旧任务表现下降)。 |
| 技术需求 | 关注逐步优化(如参数高效微调、模块化扩展)。 | 关注动态优化(如经验回放、时间权重调整)。 |
4. 理解与解释
- 垂直方向的知识转移 是一种分阶段递进的过程,主要服务于模型能力的不断细化和强化,每个阶段为下一阶段提供稳固的基础。理解其关键在于平衡每一层次的适应性和知识保持。
- 水平方向的知识转移 更注重动态性,面对的是时间和领域的变化,其挑战在于如何在快速适配新知识的同时尽量减少旧知识的遗忘。
通过理解这两种方向的知识转移,我们可以设计更高效的持续学习方法,应对多场景、多任务的复杂需求。
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/11/25/Paper-Reading-Note-6-continual-learning-LLM-2/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)