Paper Reading 7 LLM- RAG(Retrieval-Augmented Generation)-survey
论文信息
Retrieval-Augmented Generation for Large Language Models: A Survey
AI总结
以下是论文分析和总结的中文版本:
范围和背景
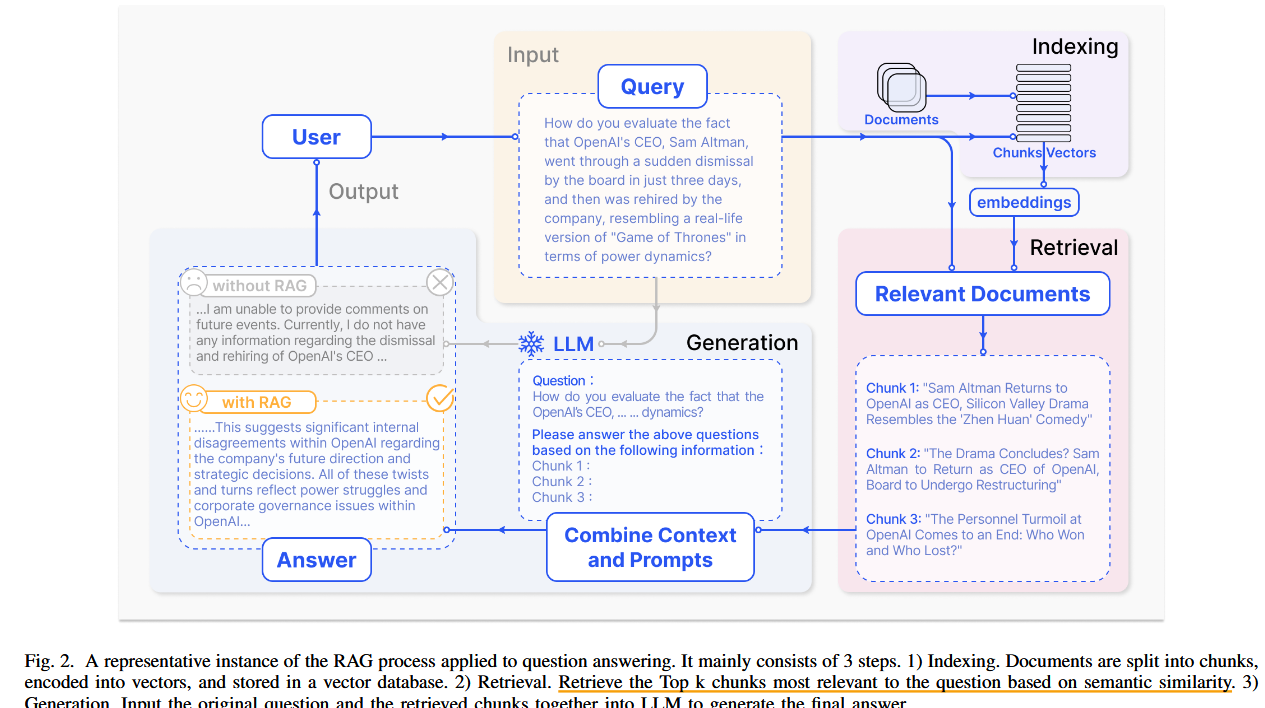
论文围绕大语言模型(LLMs)在实际应用中面临的挑战展开,包括幻觉(hallucination)、知识过时、推理过程不透明等问题。提出了检索增强生成(Retrieval-Augmented Generation,RAG)作为解决方案,通过引入外部知识库来增强生成质量,特别适用于知识密集型任务和领域特定任务,从而提高模型的准确性和可信度。
核心思想
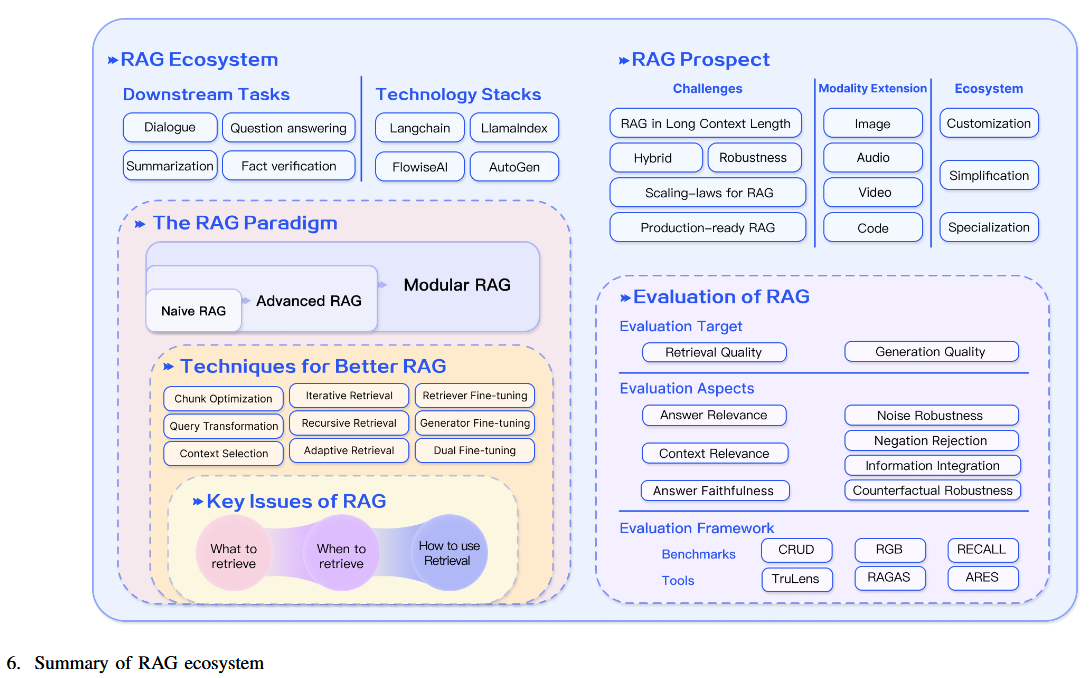
RAG结合了LLMs的内部参数化知识与动态外部数据库,构建了一个协同框架。论文将RAG技术划分为三种范式:
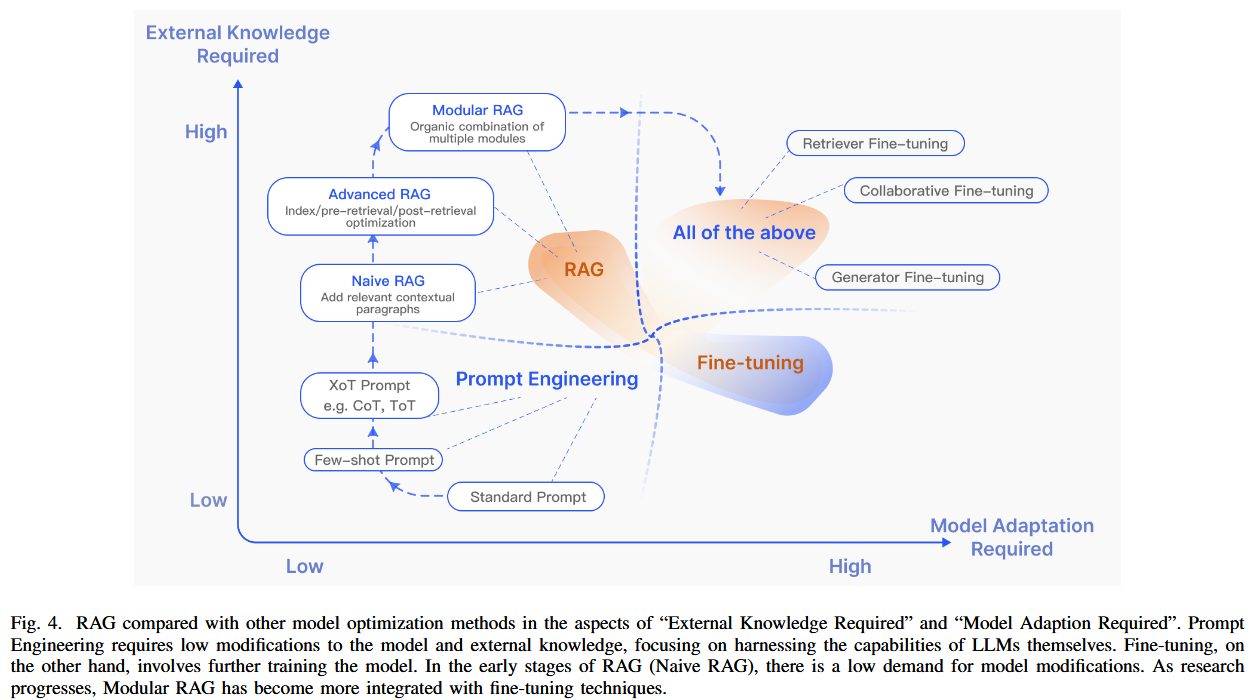
- 基础RAG(Naive RAG):传统的“检索-阅读”模式。
- 高级RAG(Advanced RAG):通过优化索引和检索后处理来提升性能。
- 模块化RAG(Modular RAG):引入模块化设计以适应多样化应用场景。
方法论
论文通过三个核心阶段对RAG系统进行详细分析:
- 检索(Retrieval):探索高效检索外部数据的方法,包括索引优化、嵌入模型和查询增强等。
- 生成(Generation):研究如何将检索到的内容与语言模型结合以生成高质量回答。
- 增强(Augmentation):提出迭代检索、自适应检索等高级工作流程,以应对复杂任务。
同时,文章还提出了一套评价框架和基准,重点衡量RAG的检索质量、生成能力和鲁棒性。
贡献
- 技术整合:系统地总结了RAG领域的最新技术,包括检索、生成和增强的前沿方法。
- 评价框架:提出了适用于RAG系统的评价指标和基准,涵盖准确性、上下文相关性、回答可信度等方面。
- 挑战与未来方向:指出了当前研究的不足,包括对误导性信息的鲁棒性处理、与长上下文模型的结合、以及多模态数据的整合。
创新与差异
与其他方法相比,RAG的独特性体现在:
- 能动态适应并集成外部知识源,而非依赖静态微调。
- 模块化设计使其能够针对任务需求进行优化,例如结合稀疏与密集检索技术。
- 降低幻觉现象并提高生成内容的事实性,显著提升模型的实际应用能力。
结果与结论
论文总结认为,RAG是扩展LLMs能力的重要途径,尤其在以下方面表现突出:
- 实时更新知识。
- 解决领域特定挑战。
- 通过模块化设计应对复杂任务。
论文还强调了未来研究的必要性,如鲁棒性改进、工程效率优化、以及多模态扩展。
与其他方法的对比
- RAG:高度动态且可扩展,适用于实时知识更新和知识密集型任务。
- 微调(Fine-Tuning):适合特定任务但计算成本高,且更新能力有限。
- 提示工程(Prompt Engineering):依赖模型内在能力,外部知识利用有限。
讨论
文章预期RAG未来的发展方向包括:
- 自适应检索:提高效率和相关性。
- 多模态扩展:整合图像、视频、音频等多模态数据。
- 评价框架改进:设计更全面的评估方法以捕捉RAG模型的能力。
文中主要图表
AI 问答
问题一 文中提到的衡量指标有哪些?
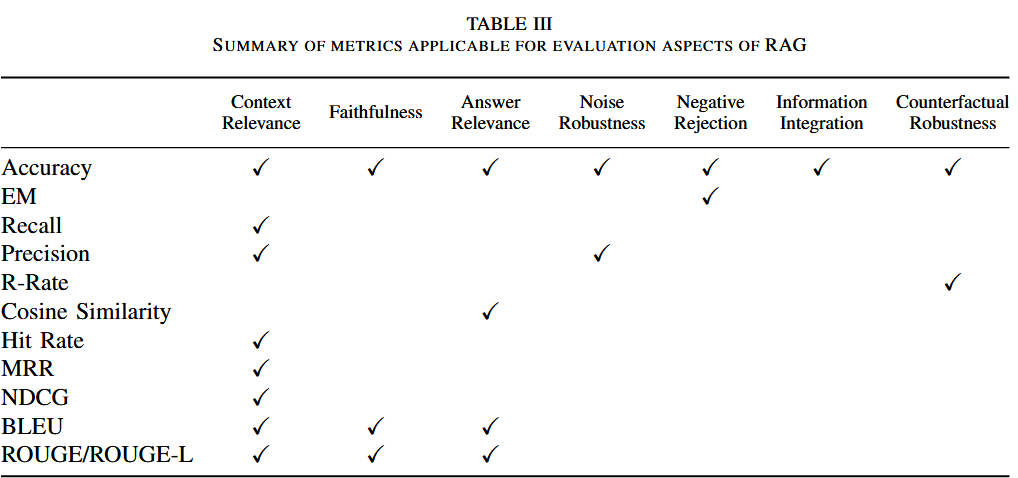
以下是表中各评估指标的计算公式、含义及其解释:
1. 上下文相关性
Accuracy(准确率)
公式: Accuracy=正确检索或生成的数量总测试数量
\[Accuracy = \frac{\text{正确检索或生成的数量}}{\text{总测试数量}}\]含义:衡量系统整体表现的简单指标,表示检索或生成任务的正确性比例。
解释:例如,在检索任务中,返回的文档与问题相关的情况越多,Accuracy 越高。适合衡量单次任务结果的全局表现。
Recall(召回率)
公式: Recall=正确检索的相关文档数量问题中所有相关文档数量
\[Recall = \frac{\text{正确检索的相关文档数量}}{\text{问题中所有相关文档数量}}\]含义:表示检索模块覆盖相关内容的能力,关注信息的全面性。
解释:在问答系统中,召回率高意味着检索模块尽量减少遗漏,但可能会增加噪声文档。
Precision(精确率)
- 公式: Precision=正确检索的相关文档数量检索到的文档总数量
- 含义:检索内容的纯度,表示系统返回的内容中有多少是相关的。
- 解释:精确率高的系统通常在高相关性任务中表现更佳,但可能忽略部分边缘内容。
Cosine Similarity(余弦相似度)
公式:
- \[Cosine Similarity = \frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\| \|\vec{B}\|}\]
其中,$\vec{A}$ 和 $\vec{B}$ 分别是查询和文档的嵌入向量。
含义:计算两向量的相似性,用于评估检索结果与查询的语义匹配。
解释:相似度越高,说明检索结果越贴近用户需求;适合评估语义检索性能。
2. 回答质量
Exact Match (EM,完全匹配)
公式:
\[EM = \frac{\text{生成答案与参考答案完全匹配的数量}}{\text{总问题数量}}\]含义:衡量生成答案与参考答案是否完全一致。
解释:适用于答案明确、无模糊的任务,如事实性问答。对生成语言的多样性不够宽容。
Faithfulness(可信性)
公式: Faithfulness 通常通过人工或模型标注,具体公式为评分平均值:
- \[Faithfulness = \frac{\text{人工或模型标注的总分}}{\text{问题数量}}\]
含义:评估生成答案是否基于检索上下文。
- 解释:确保模型不产生幻觉现象,例如回答未检索到的内容。适合需要生成引用或基于上下文回答的场景。
Answer Relevance(答案相关性)
公式: Relevance=生成答案与问题的语义匹配分数总问题数量
\[Relevance = \frac{\text{生成答案与问题的语义匹配分数}}{\text{总问题数量}}\]含义:衡量生成答案与用户问题的直接相关性。
解释:通过人工标注或语义相似性模型计算,适用于开放性问答任务。
BLEU
公式:
\[BLEU = BP \cdot \exp \left( \sum_{n=1}^N w_n \log P_n \right)\]其中,$P_n$ 表示 n-gram 精确匹配率,$BP$ 是惩罚过短生成的因子。
含义:衡量生成文本与参考文本的 n-gram 匹配程度。
解释:适用于翻译、摘要等任务,关注生成内容的语言表达相似性。
ROUGE
公式:
\[ROUGE-N = \frac{\text{生成文本中与参考文本匹配的 n-gram 数量}}{\text{参考文本中的 n-gram 总数}}\]含义:评估生成文本和参考文本之间的重叠程度。
解释:支持灵活的部分匹配,常用于摘要生成任务。
R-Rate(重现率)
公式:
\[R-Rate = \frac{\text{生成答案中重现的检索内容数量}}{\text{检索内容的总量}}\]含义:衡量生成答案是否忠实重现了检索信息。
解释:确保生成内容与检索内容一致,特别适用于引用型任务。
3. 系统鲁棒性
Noise Robustness(噪声鲁棒性)
公式: 噪声鲁棒性通常通过生成答案质量变化的差异计算:
- \[Robustness = Quality_{no\ noise} - Quality_{with\ noise}\]
含义:衡量系统在噪声文档存在时的表现变化。
- 解释:测试系统过滤无关或干扰性信息的能力。
Negative Rejection(负拒绝)
公式:
- \[Rejection = \frac{\text{无答案问题中生成“无答案”的数量}}{\text{总无答案问题数量}}\]
含义:评估系统在无答案场景下保持沉默的能力。
- 解释:确保模型在无法回答时不生成误导性内容。
Information Integration(信息整合能力)
公式: 信息整合能力通常通过评估多文档综合生成答案的质量:
\[Integration = \frac{\text{综合多文档生成的完整答案分数}}{\text{参考答案分数}}\]含义:衡量系统从多文档中提取并整合信息的能力。
解释:适用于多跳问答和复杂问题场景。
Counterfactual Robustness(反事实鲁棒性)
公式:
\[Robustness = 1 - \frac{\text{错误信息影响生成答案的比例}}{\text{总问题数量}}\]含义:评估模型在存在反事实或错误信息时的抗干扰能力。
解释:测试系统是否能够忽略虚假信息,仅生成基于真实内容的答案。
总结表格
| 指标类别 | 指标 | 公式 | 作用与解释 |
|---|---|---|---|
| 上下文相关性 | Accuracy | $\frac{\text{正确数量}}{\text{总数量}}$ | 测试检索与生成的整体表现。 |
| Recall | $\frac{\text{正确检索数量}}{\text{相关文档总数}}$ | 检索覆盖率,减少遗漏信息。 | |
| Precision | $\frac{\text{正确检索数量}}{\text{检索总数}}$ | 检索内容的质量,减少噪声。 | |
| Cosine Similarity | $\frac{\vec{A} \cdot \vec{B}}{|\vec{A}| |\vec{B}|}$ | 测试查询和文档的语义相关性。 | |
| 回答质量 | EM | $\frac{\text{完全匹配数量}}{\text{总问题数量}}$ | 测试答案与参考答案的完全一致性。 |
| Faithfulness | $\frac{\text{标注总分}}{\text{问题数量}}$ | 测试答案是否忠实于检索内容。 | |
| Answer Relevance | $\frac{\text{语义匹配分数}}{\text{问题数量}}$ | 测试答案与问题的相关性。 | |
| BLEU/ROUGE | $BP \cdot \exp \left( \sum w_n \log P_n \right) / ROUGE−NROUGE-N$ | 测试生成内容与参考答案的相似性。 | |
| R-Rate | $\frac{\text{重现的检索内容数量}}{\text{检索内容总量}}$ | 测试生成答案对检索内容的重现能力。 | |
| 系统鲁棒性 | Noise Robustness | $Quality_{no\ noise} - Quality_{with} $ |
问题二 评估框架
表4 中提到的 Evaluation Framework(评估框架) 为评估 RAG 系统提供了系统化的工具和基准。这些框架从不同维度对 RAG 系统的性能进行全面评估,包括检索质量、生成质量,以及模型在不同场景下的适应性与鲁棒性。
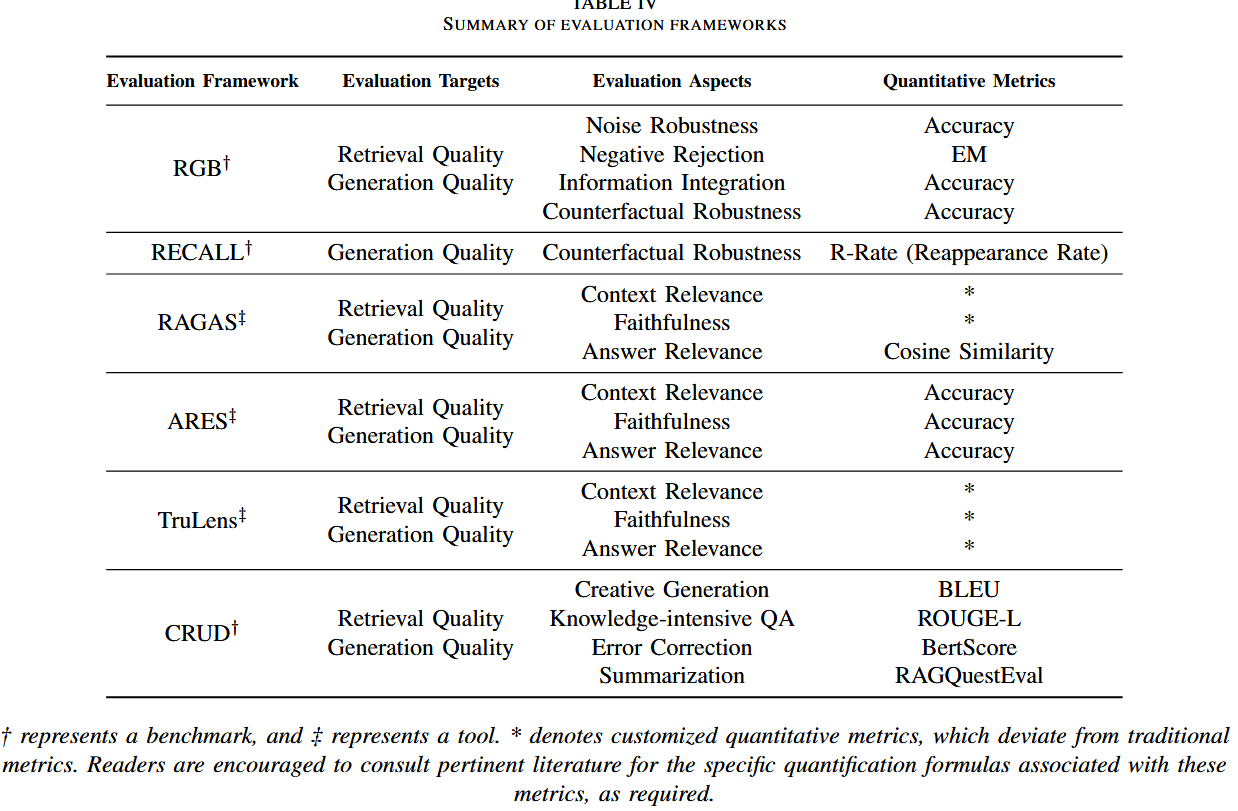
以下是表4中提到的主要评估框架的详细介绍,包括其目标、评估内容和使用的定量指标:
1. RGB(评估框架)
- 目标:
- 评估 RAG 系统的 检索质量 和 生成质量。
- 特别关注系统的鲁棒性,包括噪声文档的处理能力和反事实信息的识别能力。
- 评估内容:
- 噪声鲁棒性(Noise Robustness):系统在存在无关或误导性文档时的表现。
- 负拒绝(Negative Rejection):在缺乏答案时,系统拒绝生成虚假答案的能力。
- 信息整合(Information Integration):从多个文档中提取并综合答案的能力。
- 反事实鲁棒性(Counterfactual Robustness):系统能否忽略错误或虚假信息。
- 定量指标:
- Accuracy:整体正确率。
- EM:完全匹配比例。
- Recall 和 Precision:检索和生成内容的覆盖率与准确性。
2. RECALL(基准评估)
- 目标:
- 评估 RAG 系统生成答案的可信性,尤其是应对反事实场景的能力。
- 评估内容:
- 反事实鲁棒性(Counterfactual Robustness):测试系统是否能够抵抗错误信息对生成答案的干扰。
- 定量指标:
- R-Rate(重现率):生成内容中基于检索信息的比例,确保答案基于真实的上下文而非虚假信息。
3. RAGAS(评估工具)
- 目标:
- 提供自动化的评估工具,量化 RAG 系统的检索和生成表现。
- 评估内容:
- 上下文相关性(Context Relevance):检索内容是否与查询匹配。
- 可信性(Faithfulness):生成答案是否忠实于检索内容。
- 答案相关性(Answer Relevance):生成答案是否与问题直接相关。
- 定量指标:
- 自定义指标,如 Cosine Similarity(语义相似性)和基于模型评分的答案质量评估。
4. ARES(评估工具)
- 目标:
- 提供类似 RAGAS 的自动化工具,专注于检索和生成任务的相关性和质量评估。
- 评估内容:
- 与 RAGAS 类似,强调:
- 上下文相关性(Context Relevance)
- 可信性(Faithfulness)
- 答案相关性(Answer Relevance)
- 与 RAGAS 类似,强调:
- 定量指标:
- Accuracy:生成答案的正确率。
- Faithfulness 和 Relevance:由人工或模型标注的语义和内容一致性评分。
5. TruLens(评估工具)
- 目标:
- 通过自动化和解释性工具评估 RAG 系统的检索和生成质量。
- 评估内容:
- 上下文相关性:检索结果是否与查询匹配。
- 可信性:生成内容是否基于检索上下文。
- 答案相关性:答案与用户问题的直接性和完整性。
- 定量指标:
- 支持用户自定义指标,如 BLEU、ROUGE 和 BERTScore 等,同时包含专门的上下文相关性评估指标。
6. CRUD(评估基准)
- 目标:
- 针对创意生成、知识密集型任务的系统设计专门评估基准,综合测试模型的生成和检索能力。
- 评估内容:
- 创意生成(Creative Generation):生成内容的新颖性和多样性。
- 知识密集型问答(Knowledge-intensive QA):在复杂任务中的知识准确性。
- 错误纠正(Error Correction):模型识别并纠正错误信息的能力。
- 摘要生成(Summarization):在压缩文本时保持关键信息的能力。
- 定量指标:
- BLEU:衡量生成与参考答案的 n-gram 匹配。
- ROUGE-L:评估生成内容与参考答案的最长公共子序列。
- BERTScore:基于语义的生成质量评分。
总结表格
| 框架 | 评估目标 | 评估内容 | 定量指标 |
|---|---|---|---|
| RGB | 检索与生成质量、系统鲁棒性 | 噪声鲁棒性、负拒绝、信息整合、反事实鲁棒性 | Accuracy, Recall, Precision, EM |
| RECALL | 反事实场景中的生成可信性 | 反事实鲁棒性 | R-Rate |
| RAGAS | 自动化评估检索和生成质量 | 上下文相关性、可信性、答案相关性 | Cosine Similarity、自定义指标 |
| ARES | 自动化评估检索和生成质量 | 上下文相关性、可信性、答案相关性 | Accuracy, Faithfulness, Relevance |
| TruLens | 自动化和解释性评估工具 | 上下文相关性、可信性、答案相关性 | BLEU, ROUGE, BERTScore |
| CRUD | 创意生成、知识问答、错误纠正、摘要生成 | 创意生成、知识密集型问答、错误纠正、摘要生成 | BLEU, ROUGE-L, BERTScore |
结论
这些评估框架和工具为 RAG 系统的性能评估提供了多维度的方法,涵盖了从基础检索到生成的各个环节。选择合适的框架和指标需要根据具体任务需求,如是否强调鲁棒性、生成质量或任务多样性。如果需要某个工具的具体应用示例或更详细的解析,请进一步说明!
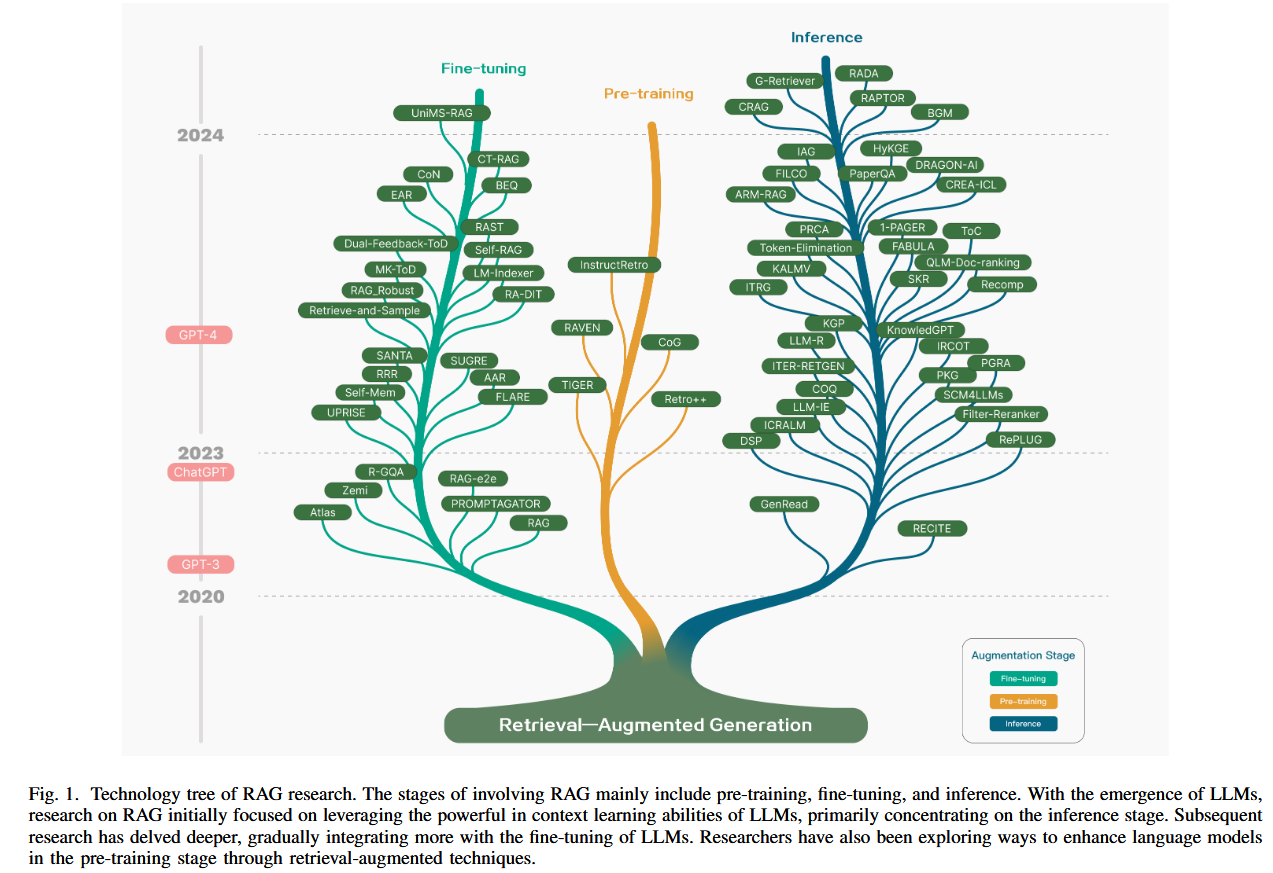
文中将RAG方法分为了三种 检索(Retrieval) 生成(Generation)增强(Augmentation),请分别解释
以下是对文中提到的 RAG 方法三种划分(检索、生成、增强)的综合分析,包括划分原因、每部分解决的问题、主要思想以及代表性方法:
1. 划分原因
RAG 技术被划分为检索(Retrieval)、生成(Generation)*和*增强(Augmentation),主要基于以下逻辑:
- 任务分解:RAG 的核心目标是通过外部知识补充和改进语言模型的生成质量。实现这一目标需要将任务细化为三大环节:获取相关知识(检索)、生成答案(生成)以及优化流程(增强)。
- 模块化设计:这种划分使 RAG 系统可以模块化开发和优化,分别改进各环节的性能,便于适配多样化任务。
- 问题应对:每个环节专注于解决特定问题。例如,检索阶段关注信息覆盖性,生成阶段解决内容准确性,增强阶段提升效率和鲁棒性。
2. 每部分要解决的问题及主要思想
检索(Retrieval)
- 要解决的问题:
- 如何从庞大的外部知识库中快速准确地检索与用户查询相关的信息。
- 在保证相关性的同时,减少冗余和噪声。
- 平衡检索的覆盖性(Recall)与精确性(Precision)。
- 主要思想:
- 基于语义嵌入(Dense Embedding)或稀疏向量(Sparse Vector)的方法,将用户的查询和知识库内容向量化。
- 使用语义相似性计算(如余弦相似度)来检索最相关的文档。
- 通过优化索引结构(如分层索引、元数据附加)和查询扩展(如 Query Expansion)提升检索效果。
- 代表性方法:
- DenseX:提出基于语义向量的密集检索方法,结合细粒度的单元(如短语)进行高效检索。
- HyDE(Hypothetical Document Embedding):通过生成假设性文档,将查询扩展为更语义相关的检索目标。
- FLARE:结合检索与生成过程的主动触发机制,在生成过程中动态调用检索模块。
生成(Generation)
- 要解决的问题:
- 如何利用检索到的信息生成准确且连贯的答案。
- 避免“幻觉”(hallucination)现象,即生成与事实不符的内容。
- 平衡生成内容的可信性(Faithfulness)与多样性(Diversity)。
- 主要思想:
- 将检索到的内容与用户的原始问题结合,作为上下文输入到语言模型中。
- 通过精细化生成过程(如上下文压缩、重排序)提高生成质量。
- 针对具体任务进行模型微调,使生成过程更加适配任务需求。
- 代表性方法:
- Self-RAG:引入反思机制(Reflection Token),通过模型自评估生成质量,并动态调整上下文。
- PRCA(Pluggable Reward-driven Context Adapter):通过奖励机制选择最优上下文,以提高生成的相关性和可信性。
- LlamaIndex:基于轻量级框架的生成方法,利用层级化结构组织上下文并动态调整生成内容。
增强(Augmentation)
- 要解决的问题:
- 如何优化检索和生成之间的交互,提高整体系统的效率和鲁棒性。
- 在复杂任务中,通过多轮检索或动态调整上下文增强系统表现。
- 处理噪声、冗余信息,以及复杂逻辑推理的需求。
- 主要思想:
- 通过迭代检索、递归检索和自适应检索等方式动态优化检索-生成流程。
- 利用强化学习或反馈机制优化检索策略。
- 在不同场景中灵活调整系统的行为,使其适应多样化任务需求。
- 代表性方法:
- ITER-RETGEN:通过生成增强检索的协同机制,反复交替检索和生成,提高信息覆盖率。
- IRCoT(Iterative Retrieval with Chain of Thought):通过链式推理(Chain of Thought)引导多轮检索。
- Self-RAG:结合主动触发机制,根据生成过程中的自反思动态调整检索。
3. 三部分的差异对比
| 模块 | 目标 | 要解决的问题 | 主要方法 | 代表性方法 |
|---|---|---|---|---|
| 检索 | 从知识库中找到相关信息 | 提高相关性、减少噪声,平衡覆盖率和精确率 | 语义嵌入、元数据索引、查询扩展 | DenseX, HyDE, FLARE |
| 生成 | 基于检索内容生成连贯且准确的答案 | 避免幻觉,提升可信性,支持多样性表达 | 上下文压缩、模型微调、生成重排序 | Self-RAG, PRCA, LlamaIndex |
| 增强 | 动态优化检索与生成过程 | 应对复杂任务,提高鲁棒性与适应性 | 迭代检索、链式推理、自适应检索 | ITER-RETGEN, IRCoT, Self-RAG |
总结
- 划分意义:这种划分将复杂的 RAG 系统分解为三个模块,各模块专注解决特定问题,有助于针对性优化。
- 系统整体性:三部分相互补充,检索提供基础信息,生成负责最终输出,增强优化交互与适应性。
- 发展方向:未来研究将更加注重增强模块的灵活性(如主动式检索)和生成模块的可信性(如避免幻觉)。
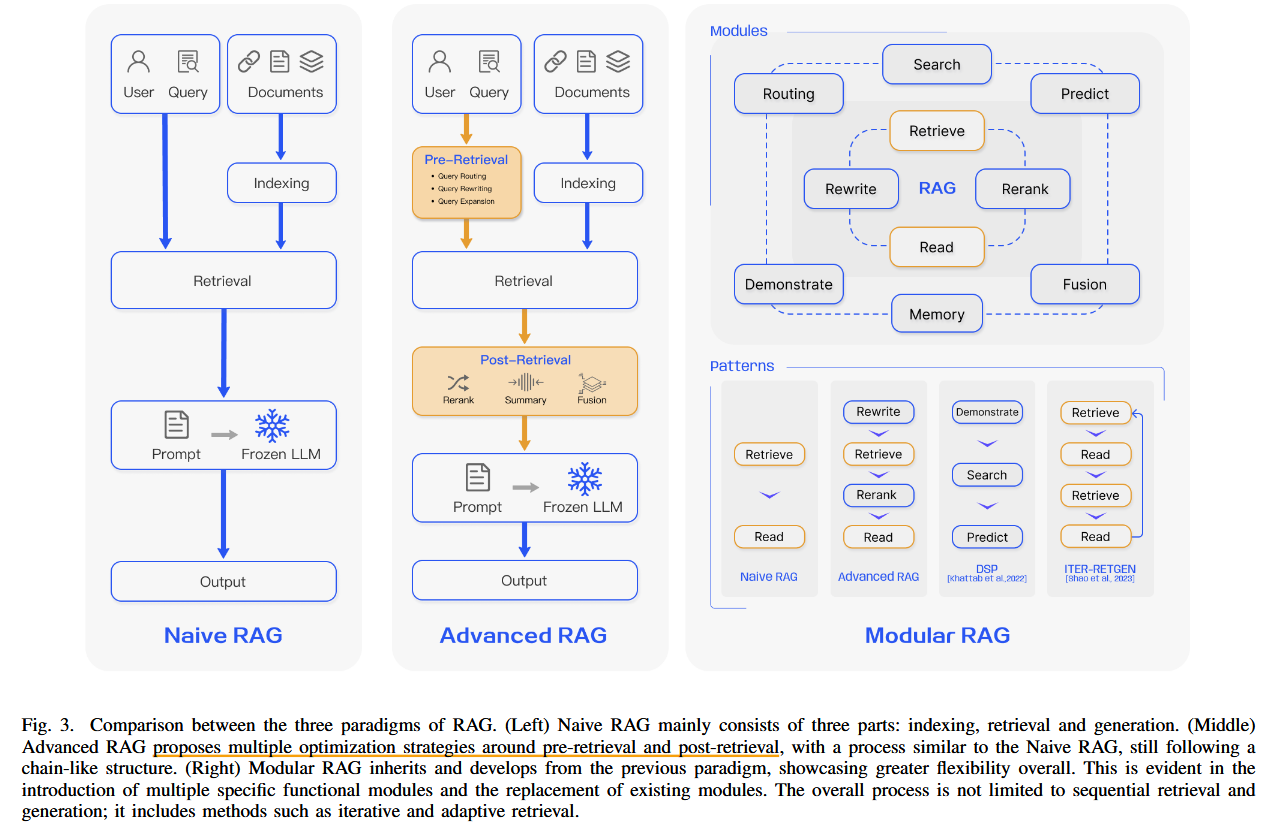
文中将将RAG技术划分为三种范式
文中将 RAG(Retrieval-Augmented Generation)技术划分为三种范式,这是对 RAG 系统在不同任务需求和技术实现上的总结。以下分别从划分依据与原因、主要思想与区别、代表性方法以及与检索、生成、增强三个阶段的关系进行详细介绍。
1. 划分依据与原因
- 划分依据:
- 系统架构复杂性:根据 RAG 系统从简单到复杂的技术实现层次,将其划分为从传统到高级再到模块化的三种范式。
- 任务需求差异:简单任务(如基本问答)可通过基础范式完成,而复杂任务(如多跳推理、多模态生成)则需要更复杂的范式。
- 灵活性与适配性:复杂的范式提供更高的灵活性和适配性,适应多样化场景和动态任务需求。
- 划分原因:
- 优化性能:通过分层分析,明确各类范式的优势,便于针对性改进性能。
- 研究指导:为研发者提供明确的技术方向选择,降低 RAG 技术开发门槛。
- 模块化扩展:复杂的范式可通过模块化设计适应未来任务需求,便于扩展和升级。
2. 每种范式的主要思想与区别
(1)Naive RAG(基础 RAG)
- 主要思想:
- 简单地将检索-生成(Retrieve-Generate)流程串联起来。
- 检索模块从外部知识库中找到相关内容,生成模块利用检索结果生成答案。
- 以固定流程为主,缺乏动态调整能力。
- 区别:
- 直接串联,没有复杂的动态优化机制。
- 适合简单任务,效率高但在鲁棒性和复杂任务适配性上有局限性。
- 代表性方法:
- RAG-Seq:采用检索序列后直接生成答案的简单流程。
- RAG-Token:逐步生成答案时引用检索到的内容。
- DPR(Dense Passage Retrieval):基于密集向量的检索方法,用于提高检索效率。
(2)Advanced RAG(高级 RAG)
- 主要思想:
- 在基础 RAG 的基础上,引入动态优化机制,如:
- 上下文压缩与优化:对检索到的内容进行重排序或过滤,保留最相关的信息。
- 检索与生成交互:生成过程中动态调整检索内容。
- 多轮检索:在生成过程中多次调用检索模块,获取新的信息。
- 在基础 RAG 的基础上,引入动态优化机制,如:
- 区别:
- 动态优化检索与生成的交互流程,适应复杂任务需求。
- 提高系统对任务上下文的理解能力,减少噪声干扰。
- 代表性方法:
- REALM(Retrieval-Augmented Language Model):生成过程中动态检索相关文档。
- FiD(Fusion-in-Decoder):通过融合多个检索到的文档进行生成,提升答案的全面性。
- DRaG(Dynamic Retrieval and Generation):在生成过程中动态调整检索内容。
(3)Modular RAG(模块化 RAG)
- 主要思想:
- 引入模块化设计,将 RAG 系统分解为独立的模块,分别进行优化。
- 支持跨模态和多任务,如文本、图像、视频等多模态信息的结合。
- 通过强化学习、自适应检索、递归生成等技术实现更高的灵活性和扩展性。
- 区别:
- 完全模块化设计,适应多样化和动态任务需求。
- 支持跨模态和复杂推理任务,鲁棒性和灵活性最强。
- 代表性方法:
- IRCoT(Iterative Retrieval with Chain of Thought):通过链式推理方法进行多轮检索与生成。
- Self-RAG:结合自反思机制动态调整系统行为。
- Multimodal RAG:结合多模态输入(如图像+文本),实现更复杂的生成任务。
3. 不同范式与检索、生成、增强三个阶段的关系
| 范式 | 检索(Retrieval) | 生成(Generation) | 增强(Augmentation) |
|---|---|---|---|
| Naive RAG | 单次检索,通常基于密集向量或稀疏向量检索。 | 直接利用检索结果生成答案,无动态优化机制。 | 无增强机制,流程固定简单。 |
| Advanced RAG | 支持多轮动态检索,结合上下文对检索内容进行优化。 | 在生成过程中动态调整检索内容,改进生成质量。 | 部分增强能力,如动态检索与生成交互、自适应上下文优化。 |
| Modular RAG | 灵活选择检索策略(如递归检索、多模态检索)。 | 生成过程中高度模块化,可适应跨模态或复杂任务需求。 | 全面增强机制,包括链式推理、强化学习、自适应策略,适应复杂场景。 |
总结
- 划分依据与原因:
- 基于技术复杂性和任务适配性,划分为基础、高级、模块化三种范式。
- 帮助研发者明确选择方向,根据需求开发适配不同场景的 RAG 系统。
- 主要思想与区别:
- 基础 RAG:简单串联,效率高但灵活性不足。
- 高级 RAG:动态优化交互,提高鲁棒性和复杂任务适配性。
- 模块化 RAG:完全模块化设计,支持多模态和复杂推理任务。
- 代表方法:
- Naive RAG:RAG-Seq, DPR。
- Advanced RAG:REALM, FiD。
- Modular RAG:IRCoT, Self-RAG。
- 与检索、生成、增强的关系:
- 基础 RAG 偏重检索和生成,流程简单。
- 高级 RAG 在增强部分增加优化机制。
- 模块化 RAG 完全覆盖检索、生成、增强三阶段,适应最广。
如果需要深入讨论某一范式或代表方法的实现细节,请进一步说明!
个人理解
相关笔记
| [前沿重器[41] | 综述-面向大模型的检索增强生成(RAG)](https://mp.weixin.qq.com/s?__biz=MzIzMzYwNzY2NQ==&mid=2247489372&idx=1&sn=8fc154edac26943a447d596a4e697ede&chksm=e8824fc2dff5c6d44d8e7a1be4cc1b472e8cdd8e8484bf02d00f78ab708e6340f6f90243cb0c&scene=21#wechat_redirect) |
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/11/27/Paper-Reading-Note-7-LLM-RAG/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)