Paper Reading 8 LLM- Information Retrieval
论文信息
Large Language Models for Information Retrieval: A Survey
AI总结
以下是对您上传论文的详细分析,包括其主要内容的概括:
1. 范围与设置(Scope or Setting)
这篇论文的重点是探讨大型语言模型(Large Language Models, LLMs)在信息检索(Information Retrieval, IR)领域的应用和发展:
- 范围:论文专注于文本检索,涵盖了传统 IR 方法与 LLM 驱动的现代方法之间的演进。
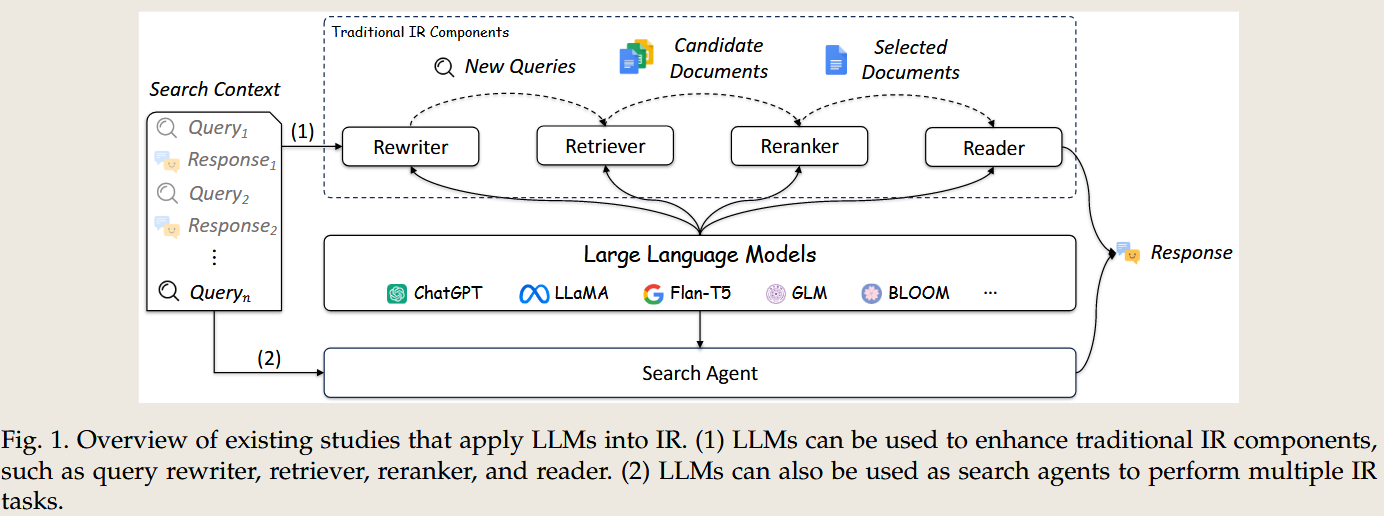
- 场景:包括搜索引擎、对话系统、问答系统等典型 IR 场景,以及 LLM 在检索器、重排序器、读者模块和搜索代理中的应用。
- 目标:总结 LLM 与 IR 系统结合的关键方法,分析其局限性,并展望未来方向。
2. 核心思想(Key Idea)
LLMs 的强大语言理解和生成能力通过增强查询重写、检索、重排序和结果阅读,重塑了 IR 系统的性能和用户体验。论文提出:
- 利用 LLMs 改善 IR 系统关键模块的性能。
- 通过搜索代理模拟人类的搜索行为,实现复杂任务的全流程自动化。
3. 方法(Method)
论文将 LLM 在 IR 系统中的应用分为四个关键模块:
- 查询重写器(Query Rewriter):改进用户查询的表达,解决语义差距问题。
- 检索器(Retriever):高效召回相关文档,采用密集向量和生成式方法。
- 重排序器(Reranker):对初步检索的文档进行精细排序,提高文档相关性。
- 阅读器(Reader):生成用户友好的答案或摘要,整合检索到的信息。
4. 贡献(Contribution)
- 整合研究现状:提供了 LLM 应用于 IR 系统的全面综述,覆盖了方法、技术、及其适用场景。
- 创新点:首次系统性讨论 LLM 驱动的搜索代理(Search Agent),为复杂 IR 任务提出自动化解决方案。
- 理论与实践结合:既讨论了基于 LLM 的研究方法,也分析了实际应用中的成功案例,如 New Bing。
5. 区别与创新(Difference and Innovation)
- 与传统 IR 的区别
- 传统 IR 强调关键词匹配和统计模型。
- 现代 IR 借助 LLM,能够捕捉复杂的语义关系,实现上下文理解。
- 创新点
- 引入生成式模型以替代传统索引-检索-排序的范式。
- 动态调整查询表达和检索策略,增强任务适配性。
6. 结果与结论(Results and Conclusion)
- 结果:通过整合 LLM 的强大语言能力,IR 系统在检索准确性、上下文适应性、和生成质量上取得显著改进。
- 结论
- LLMs 提升了从简单问答到复杂对话的全流程 IR 能力。
- 搜索代理可能成为未来 IR 发展的新范式。
7. 与其他方法的对比(Contrast with Other Methods)
- 传统 IR 方法(如 BM25 和 TF-IDF)在效率和解释性上表现优异,但在处理复杂语义关系时存在局限。
- LLM 驱动的方法可以动态适配复杂任务,但面临高计算开销和有限领域知识的挑战。
- 与其他 PLM(如 BERT)相比,LLM 在处理未见任务和对话生成中表现更为优异。
8. 讨论(Discussion)
论文讨论了以下问题:
- 数据稀缺性:LLM 的预训练需要大量标注数据,难以适配小型领域。
- 推理能力:如何在生成内容的同时保证其真实性和相关性。
- 模型效率:应对 LLM 高昂计算开销的策略。
9. 验证与支持(Proof)
- 基于多项实验结果证明 LLM 提升了 IR 各模块的性能,例如:
- Query2Doc 改进了检索性能。
- RepLLaMA 提高了语义检索的准确性。
- 通过案例分析验证了搜索代理在复杂任务中的潜力。
文中主要图表

AI 问答
问题一 总结分析文中主要内容,
分别详细介绍在 query rewriter, retrieval, reranker, reader这四个部分的主要的任务目标,之前IR传统的做法,和LLM出现之后的影响包括思想的变化和方法的区别等
以下是对论文中 Query Rewriter(查询重写器)、Retrieval(检索器)、Reranker(重排序器) 和 Reader(阅读器) 四个部分的详细分析,分别从任务目标、传统 IR 的方法、以及 LLM 出现后的影响进行介绍。
1. Query Rewriter(查询重写器)
任务目标
- 解决语义差距问题:用户查询与文档语言之间存在语义差异,查询重写器的目标是优化用户查询,使其更易于检索器找到相关内容。
- 增强查询表达:通过扩展、精炼或重构用户查询,提高检索系统对复杂查询的理解能力。
传统 IR 方法
- 关键词扩展
- 使用规则或统计方法(如 WordNet 或共现分析)扩展用户查询。
- 缺点:对复杂语义理解不足,无法处理多义词和上下文信息。
- 基于用户点击的查询推荐
- 通过历史数据对相似查询进行推荐,但依赖历史数据,泛化能力差。
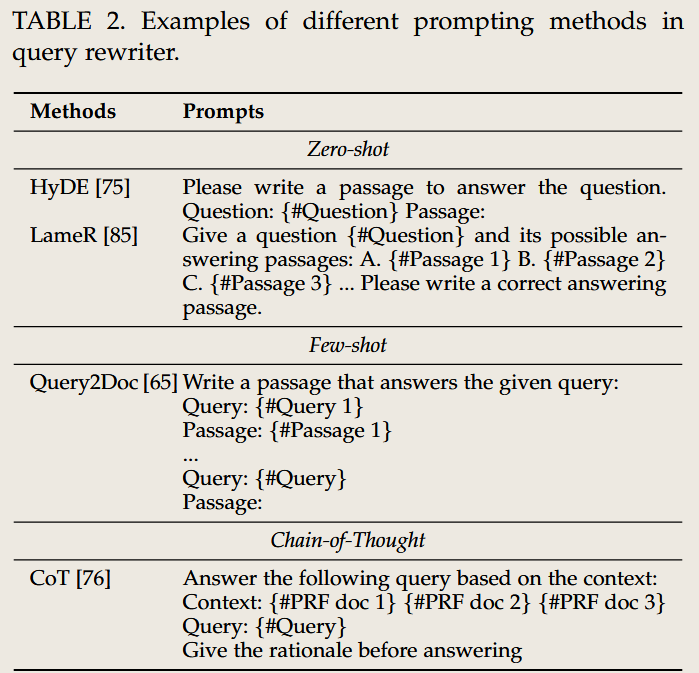
LLM 出现后的影响
思想的变化
- 从基于规则的查询优化转向生成式模型,支持复杂语义和上下文感知。
- 不再仅限于关键词扩展,而是进行多层次语言表达优化。
方法的区别
- 生成式方法:通过 LLM 动态生成优化后的查询,如 GPT 模型可以根据用户输入生成更精确的查询表达。
- 语义嵌入:LLM 可以直接将查询编码到高维语义空间,与文档进行匹配。
案例
- Query2Doc:生成与文档标题匹配的查询表达,缩小语义差距。
传统方法
- WordNet
- 使用词汇网络进行查询扩展,解决同义词匹配问题。
- 缺点:仅适用于词汇层面扩展,无法处理复杂语义关系。
- Pseudo-Relevance Feedback (PRF)
- 基于初次检索结果自动扩展查询。
- 缺点:易引入噪声,无法动态调整扩展策略。
- Click-through-based Query Expansion
- 通过分析用户点击日志,对查询进行推荐或重写。
- 缺点:依赖历史数据,缺乏泛化能力。
LLM 方法
- Query2Doc
- 生成与目标文档匹配的查询表达,缩小语义差距。
- T5 for Query Rewriting
- 微调 T5 模型生成更自然、更精确的查询重写结果。
- GPT-based Rewriting
- 使用 GPT 模型动态生成优化后的查询,支持复杂语义感知和上下文关联。
2. Retrieval(检索器)
任务目标
- 高效召回相关文档:从大规模知识库中快速找到与查询最相关的文档,作为后续处理的输入。
- 平衡覆盖率与精确性:既要尽可能多地覆盖相关文档(Recall),又要减少无关文档的引入(Precision)。
传统 IR 方法
- 稀疏向量方法
- 使用 BM25、TF-IDF 等方法,通过关键词匹配实现文档检索。
- 缺点:无法捕捉深层语义关系,面对自然语言查询时表现不佳。
- 结构化检索
- 基于预定义规则或数据库查询语言(如 SQL)实现检索,适合结构化数据,但对非结构化文本效果有限。
LLM 出现后的影响
- 思想的变化
- 转向语义检索,从表面词匹配过渡到基于语义相似性的匹配。
- 从静态索引到动态生成索引,增强了系统对复杂任务的适配能力。
- 方法的区别
- 密集向量方法:LLM 生成查询和文档的嵌入向量,通过向量相似度实现检索。
- 生成式检索:直接生成相关文档的内容或标识,而不是检索索引。
- 案例
Dense Passage Retrieval (DPR):使用 LLM 的双编码器模型(Dual Encoder)实现高效密集检索。
RepLLaMA:将生成式语言模型用于动态检索。
传统方法
- BM25
- 经典稀疏向量方法,基于关键词匹配进行文档召回。
- 优点:效率高,适合大规模检索场景。
- 缺点:无法捕捉深层语义关系。
- TF-IDF
- 基于关键词的重要性权重(词频和逆文档频率)实现检索。
- 缺点:对语义匹配无能为力。
- Structured Query Language (SQL)
- 用于结构化数据检索,基于固定规则和查询逻辑。
- 缺点:对非结构化文本无适用性。
LLM 方法
- Dense Passage Retrieval (DPR)
- 基于双编码器(Dual Encoder)方法,使用 BERT 或类似模型生成语义嵌入。
- RepLLaMA
- 基于 LLaMA 模型实现的生成式检索,直接生成文档内容或标识。
- REALM(Retriever-Augmented Language Model)
- 将检索器深度集成到生成模型中,通过迭代优化检索结果。
- Contriever
- 无监督语义检索方法,利用对比学习提高嵌入向量的质量。
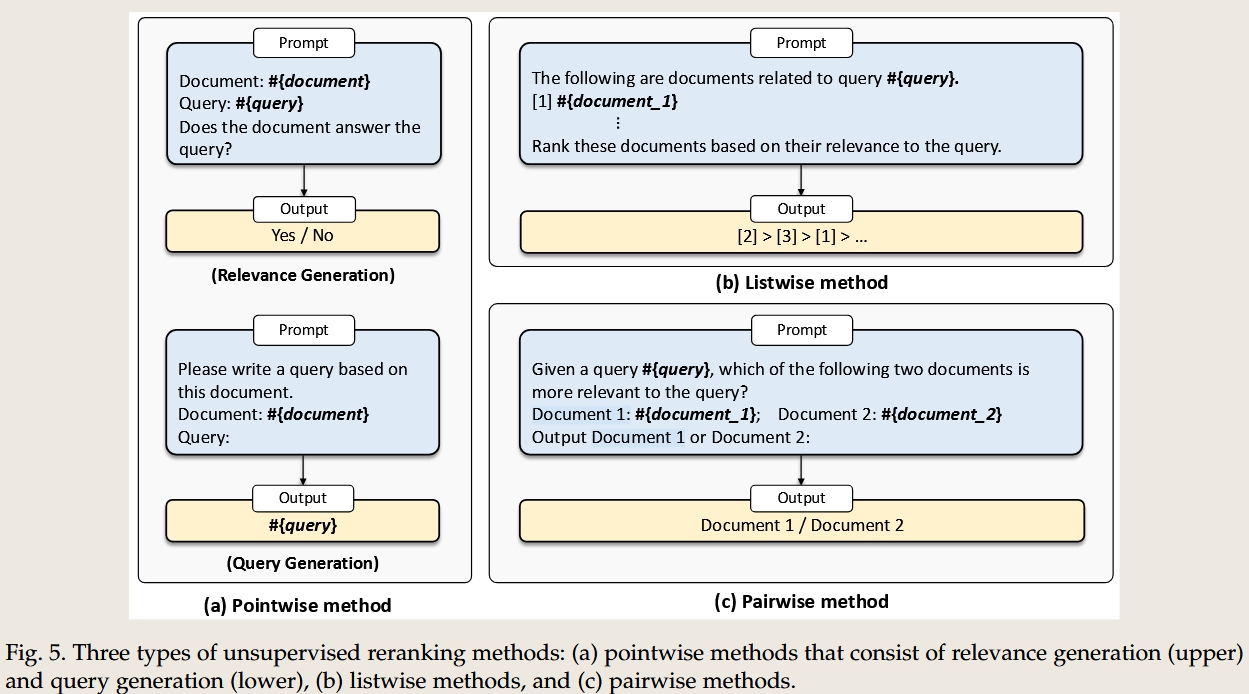
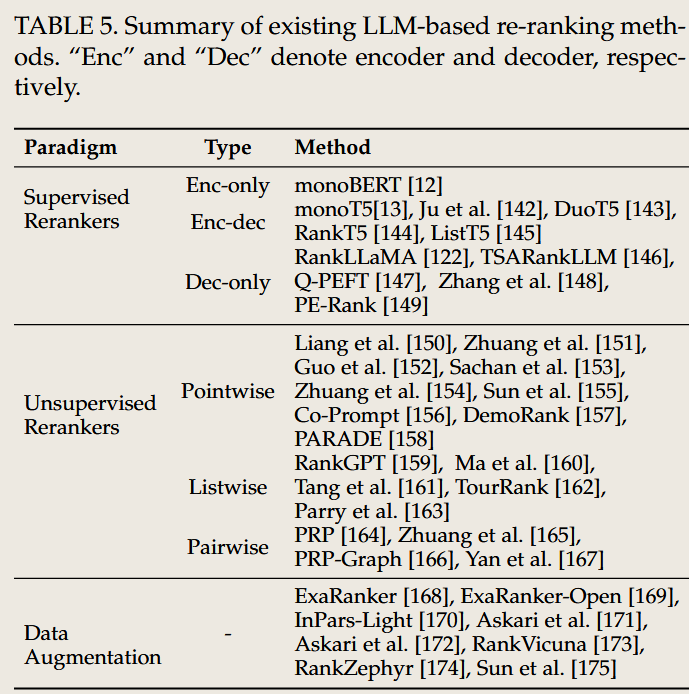
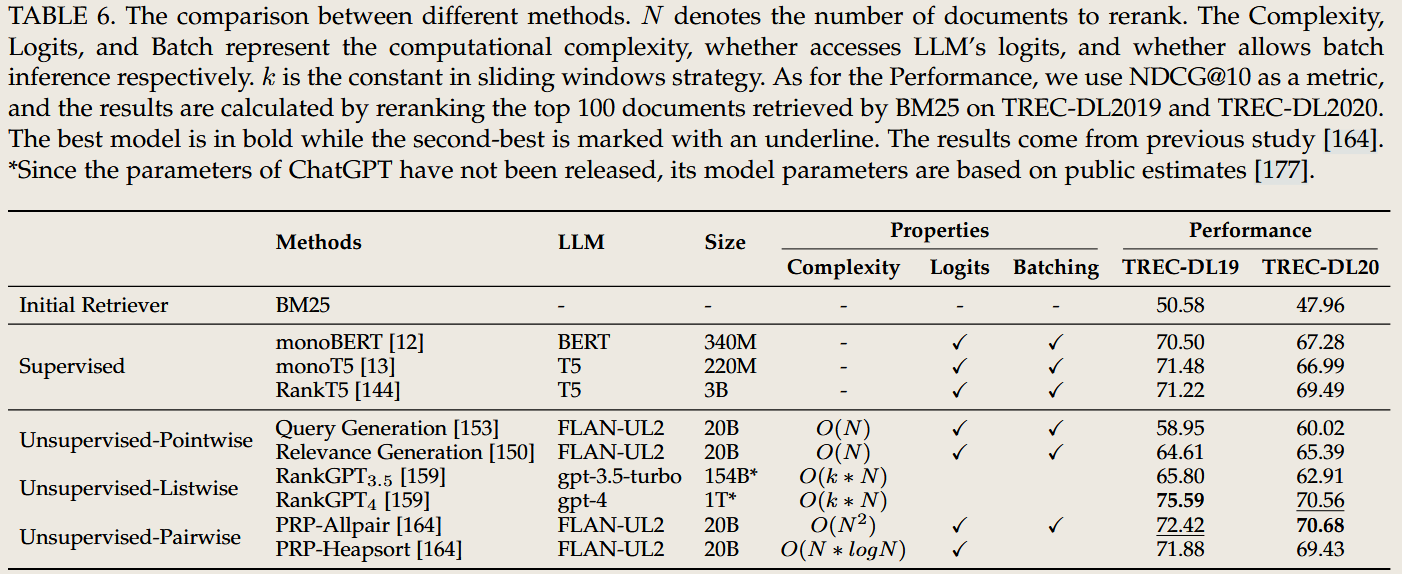
3. Reranker(重排序器)
任务目标
- 优化文档排序:对初步检索到的文档集合进行细粒度评估,根据相关性重新排序。
- 提升结果质量:确保返回的文档集前几位更相关,提高用户满意度。
传统 IR 方法
- 手工设计特征
- 使用浅层机器学习模型(如 SVM)对文档相关性进行评分,依赖手工设计的特征(如文档长度、词频等)。
- 缺点:模型复杂度低,难以捕捉深层语义关系。
- 基于统计模型
- 统计文档与查询的匹配程度,但无法利用上下文信息。
LLM 出现后的影响
- 思想的变化
- 引入深度语义理解,通过 LLM 捕捉文档与查询之间的复杂关系。
- 将重排序问题转化为生成式任务,直接预测最优文档排序。
- 方法的区别
- 跨编码器方法(Cross-Encoder):将查询与每篇文档作为输入,对其相关性进行精细评估。
- 生成式方法:通过 LLM 生成文档优先级评分,支持上下文增强。
- 案例
- Fusion-in-Decoder (FiD):融合多篇文档的内容,在生成答案的过程中隐式完成重排序。
- RAG:结合检索与生成,将高相关性文档提前。
传统方法
- LambdaMART
- 基于梯度提升树(GBDT)的学习排序算法,优化检索结果顺序。
- 缺点:依赖手工设计特征,难以捕捉复杂语义关系。
- RankSVM
- 使用支持向量机进行文档排序,基于特征权重进行相关性计算。
- 缺点:模型复杂度低,难以适应语义层次需求。
- BM25-based Reranking
- 使用 BM25 对初步检索结果进行二次排序。
- 缺点:性能提升有限。
LLM 方法
Cross-Encoder Models
- 使用 BERT 或 GPT-3 将查询和文档作为输入,直接评估相关性。
- 代表方法:MonoBERT、T5-Reranker。
Fusion-in-Decoder (FiD)
- 融合多个检索文档内容,并在生成过程中进行隐式重排序。
ColBERT
- 使用交互式双编码器模型捕捉查询与文档间的细粒度关系。
RAG (Retrieval-Augmented Generation)
- 动态调整重排序策略,优先展示相关性最高的文档。
4. Reader(阅读器)
任务目标
- 生成最终答案:整合检索到的信息,生成用户友好的答案或摘要。
- 支持多样化任务:从简单问答到复杂的对话生成、文档摘要等。
传统 IR 方法
- 直接返回文档片段
- 从检索到的文档中选取一部分作为答案,未经过深度处理。
- 缺点:用户需要自行阅读文档,无法满足复杂任务需求。
- 抽取式摘要
- 使用传统 NLP 技术从文档中抽取关键句子生成摘要,内容片段化且缺乏流畅性。
LLM 出现后的影响
- 思想的变化
- 从片段抽取转向生成式回答,提供连贯且语义完整的答案。
- 通过引入上下文和推理能力,支持复杂问题的多步解答。
- 方法的区别
- 生成式阅读器:直接生成自然语言答案,而非片段化输出。
- 上下文增强:通过多轮对话动态调整答案内容。
- 案例
- ChatGPT / GPT 系列:生成详细和上下文相关的答案。
- REALM:将阅读器与检索器深度集成,通过循环迭代优化生成内容。
传统方法
- Extractive QA Systems
- 通过规则或传统 NLP 模型从文档中抽取相关片段作为答案。
- 缺点:答案片段化,不够连贯。
- ROUGE-based Summarization
- 抽取式摘要模型,选取文档中与查询最相关的句子。
- 缺点:缺乏生成能力,摘要质量受限。
- Statistical Models
- 基于统计方法(如 N-gram)生成答案。
- 缺点:生成结果缺乏自然语言流畅性。
LLM 方法
- GPT-3 / ChatGPT
- 生成详细且连贯的自然语言答案,支持多轮交互和上下文适配。
- REALM
- 通过迭代检索与生成优化答案内容。
- FiD Reader
- 使用多个检索文档作为上下文,生成综合性答案。
- UnifiedQA
- 微调 T5 模型,用于开放性问答任务,支持多模态输入。

总结对比表
| 模块 | 任务目标 | 传统 IR 方法 | LLM 带来的变化 |
|---|---|---|---|
| Query Rewriter | 优化用户查询,提高检索效率 | 关键词扩展、点击推荐 | 生成式查询重写,支持语义感知和动态优化 |
| Retriever | 高效召回相关文档,平衡覆盖率与精确性 | BM25、TF-IDF 等稀疏向量方法 | 密集向量检索与生成式检索,支持深层语义匹配 |
| Reranker | 精细排序文档,提高检索结果的相关性和质量 | 手工特征+浅层模型排序 | LLM 跨编码器评估与生成式重排序,捕捉深层语义关系 |
| Reader | 生成连贯的自然语言答案,支持复杂任务 | 文档片段抽取、统计方法 | 生成式阅读器,整合上下文和推理,支持多轮交互和多模态生成 |
| 模块 | 传统方法 | LLM 方法 |
|---|---|---|
| Query Rewriter | WordNet, PRF, Click-based Methods | Query2Doc, T5 Rewriter, GPT-based Rewriting |
| Retriever | BM25, TF-IDF, SQL | DPR, RepLLaMA, REALM, Contriever |
| Reranker | LambdaMART, RankSVM, BM25 | Cross-Encoder, FiD, ColBERT, RAG |
| Reader | Extractive QA, ROUGE-based Summarization | GPT-3, FiD Reader, REALM, UnifiedQA |
这些方法展示了从传统 IR 方法到现代 LLM 驱动技术的演进,体现了 LLM 在捕捉深层语义、动态调整策略和生成连贯答案方面的优势。如果需要进一步分析某一方法的细节或实际应用案例,请随时告知!
问题二 介绍文中提到的 Agent 概念 并分析其与之前RAG论文中提到的Modular RAG的区别与联系
Agent 概念和Modular RAG 的确有许多相似之处,尤其是在模块化设计和任务适应性方面。以下是对它们的共同点、区别和联系的详细分析:
1. 共同点
1.1 模块化设计
共同点
:两者都采用模块化的设计思想,将任务分解为多个功能模块,各模块协同工作。
- Agent:典型模块包括 规划器(Planner)、执行器(Executor) 和 反馈环(Feedback Loop)。
- Modular RAG:模块化地分解为 检索(Retriever)、生成(Generator)、以及其他增强模块(如多轮推理模块、上下文优化模块)。
优势
- 灵活性:模块可以单独优化并适应不同任务需求。
- 扩展性:通过新增或改进模块,支持更复杂的任务(如多模态生成或跨领域推理)。
1.2 动态适配
共同点
:都强调动态调整以适应任务需求:
- Agent:可以根据任务复杂性动态规划步骤,并通过用户反馈调整执行策略。
- Modular RAG:支持多轮检索、上下文动态更新等机制,以优化生成质量。
优势
- 提高效率:通过动态优化减少无效步骤或冗余信息。
- 适应复杂任务:在多步推理或多模态任务中表现优异。
1.3 目标:复杂任务分解
共同点
:都旨在处理复杂的、需要多步推理的任务:
- Agent:将复杂任务分解为多个子任务,逐步完成并反馈优化。
- Modular RAG:通过链式推理(Chain of Thought)或递归检索解决复杂问题。
1.4 基于 LLM 的核心技术
共同点
:两者均利用 LLM 强大的语言理解与生成能力:
- Agent:依赖 LLM 进行查询优化、推理和动态规划。
- Modular RAG:使用 LLM 在生成阶段提升内容连贯性,并通过检索模块补充知识。
2. 区别
2.1 系统架构与核心设计
| 维度 | Agent | Modular RAG |
|---|---|---|
| 架构核心 | 强调任务分解、动态规划和多轮交互,以实现全流程任务自动化 | 专注于优化检索与生成的协作,通过模块化设计提升生成质量和适配性 |
| 反馈机制 | 包含 反馈环(Feedback Loop),根据任务中间结果或用户反馈动态调整执行策略 | 检索和生成间的反馈较少,流程较固定,仅支持多轮检索与增强上下文优化 |
| 任务流动性 | 动态分步执行任务,可根据任务复杂性灵活调整步骤 | 固定检索-生成流程,适合特定任务,但灵活性相对较低 |
| 用户交互 | 高度依赖用户反馈,与用户多轮对话协作完成复杂任务 | 以系统内部优化为主,用户交互较少,仅通过输出结果间接体现性能 |
2.2 任务目标
- Agent
- 主要目标:实现复杂任务的全流程自动化。
- 适用场景:多轮对话、跨模态生成、任务驱动型搜索(如法律咨询、学术研究)。
- Modular RAG
- 主要目标:通过模块协作提升生成内容的准确性和可信性。
- 适用场景:知识密集型问答(如医疗问答、金融分析)。
2.3 扩展性与任务适配
- Agent
- 具有更强的扩展性,支持多模态、多任务(如图像+文本的联合推理)。
- 灵活性更高,可通过用户反馈实时调整任务执行。
- Modular RAG
- 任务适配能力强,但更多集中在单一任务(如检索型问答)上。
- 扩展性相对受限,适应跨模态和复杂任务需引入额外模块。
2.4 强调方向
- Agent:强调任务的全流程协同与动态调整,是一种模拟人类搜索与推理行为的通用框架。
- Modular RAG:关注检索与生成模块间的深度协作,解决知识补充与生成质量的问题。
3. 联系
3.1 基于模块化设计
两者都依赖模块化设计,将复杂任务分解为若干独立模块。其基础模块(如检索、生成)具有相似的功能:
- 检索模块:从外部知识库获取相关信息,解决知识补充问题。
- 生成模块:通过 LLM 生成答案,提升内容连贯性和准确性。
3.2 与 RAG 的核心思想继承
- Agent 和 Modular RAG 都是对传统 RAG 的扩展。
- Agent 强化了任务分解与动态调整的能力。
- Modular RAG 在 RAG 的固定流程上引入了模块化优化和任务适配能力。
3.3 面向复杂任务的增强能力
两者都扩展了传统 IR 系统在复杂任务中的表现能力:
- 在需要多步推理、链式推理或动态上下文调整的任务中,两者均表现优异。
4. 总结对比表
| 维度 | Agent | Modular RAG |
|---|---|---|
| 核心设计思想 | 模拟人类行为,动态规划,任务驱动的全流程自动化 | 模块协作优化,专注提升检索与生成的整体性能 |
| 模块化 | 包括规划器、执行器和反馈环,模块功能更多样化 | 检索与生成的模块化设计,强调优化与适配 |
| 动态调整能力 | 动态调整任务流程,支持多轮交互与任务优化 | 动态更新上下文和多轮检索,但流程固定 |
| 用户交互 | 高度交互,通过多轮对话逐步调整执行策略 | 较少直接交互,优化侧重于系统内部 |
| 适用场景 | 跨模态生成、多步推理、多轮交互 | 知识密集型任务(如问答、摘要生成) |
| 扩展性 | 更强,支持多模态输入和动态任务适配 | 较高,主要集中在知识补充与生成质量的优化 |
| 与 LLM 的关系 | 依赖 LLM 进行任务分解、查询优化、生成等全流程支持 | 使用 LLM 提升生成质量,通过检索补充知识 |
5. 结论与展望
- 联系:Agent 和 Modular RAG 都是对传统 RAG 的拓展,旨在通过模块化设计和动态调整解决复杂任务中的挑战。
- 区别:Agent 更侧重任务全流程的动态性和交互性,而 Modular RAG 聚焦于提升固定流程的性能和适配性。
- 未来方向
- Agent:进一步探索多模态适配能力和任务分解自动化技术。
- Modular RAG:优化模块间的协作效率,引入更智能的上下文动态更新机制。
问题三 介绍 各个部分的 limition 和 future work
以下是文中针对各部分(Query Rewriter、Retriever、Reranker 和 Reader)所提及的不足(Limitations)和未来方向(Future Work)的综合分析与总结:
1. Query Rewriter(查询重写器)
不足
- 上下文敏感性不足
- 当前的查询重写方法对复杂上下文的理解有限,特别是在多轮对话中,可能无法准确捕捉用户真实意图。
- 多义性处理不完善
- 查询重写可能在处理多义词和复杂语义结构时出现偏差,生成的查询表达可能偏离用户原始需求。
- 对领域知识的适配性不足
- 在高度专业化领域(如医疗、法律)中,查询重写往往缺乏足够的背景知识支撑,生成的查询表达可能缺乏精确性。
未来方向
- 上下文感知增强
- 研究能够捕捉多轮对话历史并生成上下文相关查询的方法。
- 知识驱动重写
- 引入外部知识库(如医疗知识图谱)增强查询重写的领域适配能力。
- 生成控制与用户反馈
- 增加用户反馈环节,动态调整生成的查询表达,使其更符合用户需求。
2. Retriever(检索器)
不足
- 检索效率与精度的权衡
- 当前的密集检索方法在大规模文档库中面临效率瓶颈,而稀疏检索方法的精度不足。
- 动态性与实时性不足
- 很多检索器使用静态索引,无法及时响应最新信息的变化。
- 跨模态检索挑战
- 对于跨模态数据(如图像+文本),现有检索方法的语义对齐能力较弱。
- 噪声过滤问题
- 高召回率的同时容易引入大量无关文档,影响后续生成质量。
未来方向
- 高效稠密检索算法
- 开发更高效的密集向量检索方法,例如稀疏与稠密检索的混合架构。
- 动态索引与增量更新
- 引入动态索引机制,支持知识的实时更新和检索。
- 跨模态检索
- 研究跨文本、图像、视频等多模态数据的联合检索方法。
- 检索优化反馈回路
- 引入用户反馈或生成模型的指导,动态调整检索策略。
3. Reranker(重排序器)
不足
- 高计算开销
- 跨编码器方法(Cross-Encoder)虽然能显著提高排序精度,但计算成本极高,限制了其在大规模系统中的应用。
- 相关性评估的主观性
- 当前的相关性评估指标(如 NDCG)可能无法完全反映用户的真实需求和优先级。
- 上下文与领域知识不足
- 在高度复杂的任务中,排序器对任务背景的理解和领域适配性仍然有限。
未来方向
- 高效排序模型
- 开发基于轻量级编码器的排序方法,在降低计算成本的同时保持较高精度。
- 用户意图建模
- 引入用户行为数据(如点击记录)增强排序的个性化能力。
- 多模态排序
- 探索文本、图像、视频等多模态输入的统一排序机制。
4. Reader(阅读器)
不足
- 幻觉现象(Hallucination)
- 阅读器在生成答案时可能引入虚假信息或与检索内容不一致的内容。
- 答案可信性不足
- 生成的答案在一些领域(如法律、医疗)缺乏足够的可信性,可能误导用户。
- 对长文档的处理能力有限
- 当前的阅读器在处理长文档时表现有限,可能无法全面整合所有相关信息。
- 生成效率问题
- 大规模生成模型的计算成本高,影响实时性。
未来方向
- 幻觉现象的缓解
- 增强阅读器的内容对齐能力,确保生成内容严格基于检索结果。
- 答案验证与引用
- 引入验证模块,增加生成答案的可解释性,例如明确标注答案出处。
- 长文档处理优化
- 研究能够高效整合长文档信息的方法,例如局部摘要与全局上下文结合。
- 轻量化生成模型
- 优化生成模型结构,降低计算开销,提高实时生成能力。
5. 整体总结
目前的不足
- 上下文感知与领域适配
- 各模块对上下文和专业领域的适配性均有不足,影响其在复杂场景中的表现。
- 动态性与实时性
- 静态索引和固定流程的设计难以满足动态任务需求。
- 高效性与计算开销
- 高效检索与生成仍是当前的技术瓶颈,尤其是在大规模数据和实时任务中。
- 跨模态与多任务适应性
- 对多模态输入和复杂任务的适配能力较弱,限制了系统的扩展性。
未来方向
- 模块间的深度协作
- 构建更紧密的模块协同机制,打通检索、排序和生成的完整链路。
- 用户驱动的优化
- 增强系统的交互性和反馈机制,通过用户行为动态调整任务执行策略。
- 跨模态与多任务适配
- 开发统一框架支持跨模态输入和多任务执行。
- 轻量化与高效性
- 在各模块中引入高效模型和算法,降低系统整体计算成本。
- 知识验证与解释性
- 增强系统的透明性,通过明确引用和验证机制提高用户信任度。
总结
文中针对 Query Rewriter、Retriever、Reranker 和 Reader 各模块的局限性与未来改进方向进行了深入讨论。这些不足主要集中在上下文适配性、动态调整能力、计算效率和多模态适应性等方面,而未来的研究将致力于通过模块协作、用户交互优化和高效轻量化设计来提升系统整体性能。如果需要深入探讨某一模块的技术方案或改进策略,请随时告知!
文中第四部分介绍
以下是对检索器(Retrievers)部分内容的中文总结:
检索器在信息检索中的作用
- 检索器是信息检索(IR)系统的第一步筛选器,负责识别与用户查询相关的文档。
- 核心目标:
- 效率:在海量数据中保持快速响应。
- 召回率:确保不遗漏任何相关文档,以便下游处理(如重新排序)。
解决的挑战
- 查询模糊性
- 用户的查询往往简短且模糊,难以准确理解其意图。
- 冗长且噪声较多的文档
- 编码长文档并提取其中相关内容是一个重大挑战。
- 数据局限性
- 高质量的领域特定标注数据通常难以获取,因为人工标注成本高昂。
- 模型局限性
- 基于BERT等架构的神经检索器在扩展性和性能方面存在瓶颈。
大语言模型(LLM)的影响
LLM 为检索任务带来了变革性能力,主要体现在以下两方面:
- 检索数据优化
- 通过LLM优化模糊查询或噪声文档内容,提升检索精度。
- 训练数据增强
- 使用LLM生成伪数据(如查询、相关性标签和完整示例)以弥补训练数据的不足。
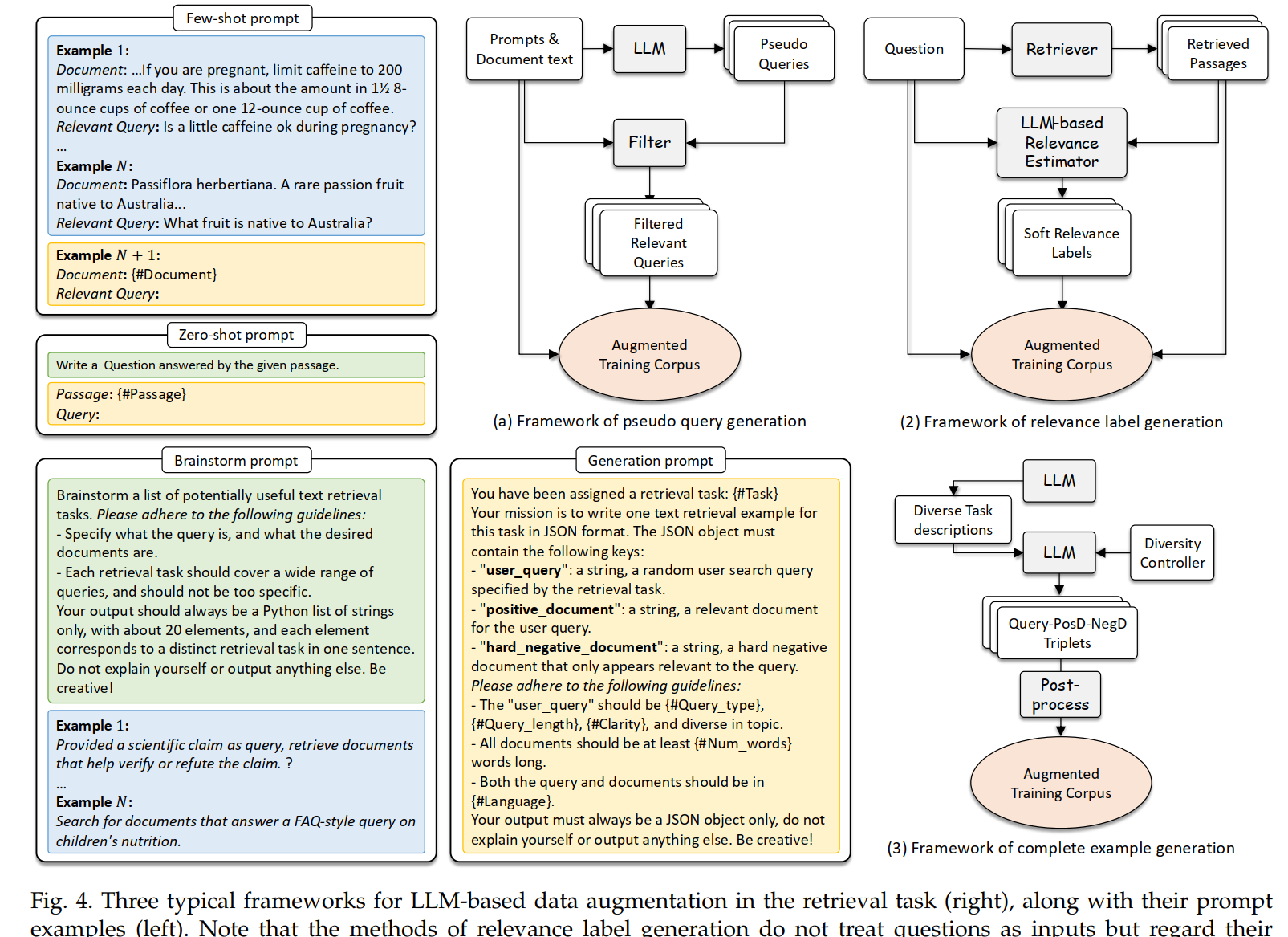
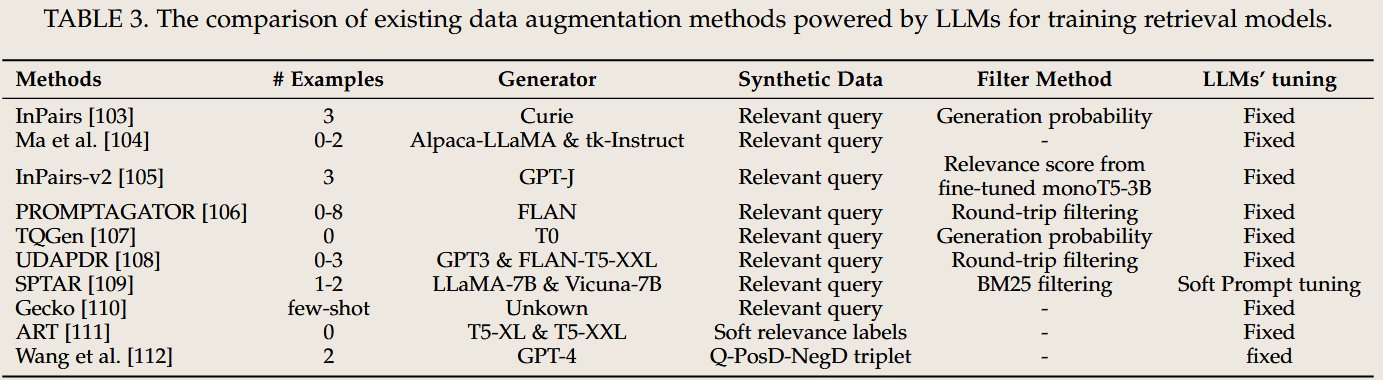
数据增强技术
- 伪查询生成
- 从文档生成合成查询,使用如GPT的模型,可通过迭代优化适应特定领域。
- 相关性标签生成
- 通过计算查询相对于文档的条件概率生成软相关性标签。
- 完整示例生成
- 生成查询、正样本文档和困难负样本三元组,以丰富训练数据集的多样性。
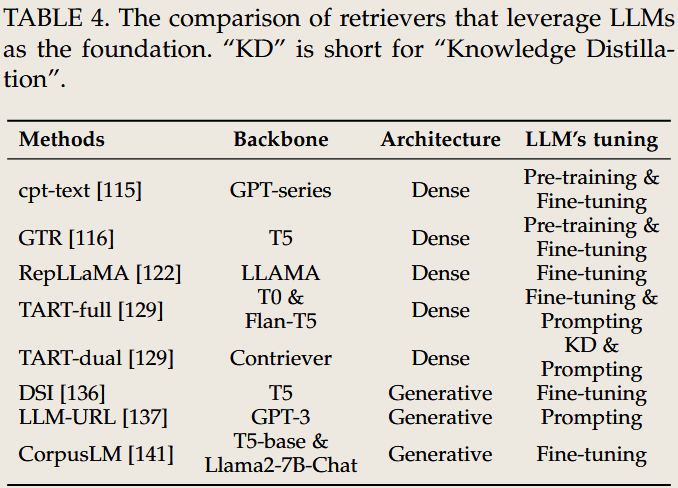
模型改进
LLM作为骨干被集成到以下两种类型的检索器中:
- 密集检索器(Dense Retrievers)
- 使用嵌入向量来编码查询和文档之间的语义相似性。
- 基于LLM的密集检索器提升了跨领域的泛化能力和任务特定的性能。
- 示例包括RepLLaMA和指令式嵌入等方法。
- 生成型检索器(Generative Retrievers)
- 打破传统的“索引-检索-排序”范式,通过直接生成文档标识符(如URL)来响应用户查询。
- 技术包括微调(如DSI)或上下文学习(如LLM-URL),无需预先建立索引即可生成准确的标识符。
局限性
- 推理成本
- LLM模型规模庞大,导致响应时间较慢。
- 与真实查询的不匹配
- 生成的数据可能无法完全反映现实用户的行为或意图。
- 领域适应性
- LLM需要针对特定领域或任务进行微调。
- 效率问题
- 提高系统速度和成本效益仍是一个关键挑战。
这部分展示了LLM如何通过解决传统挑战和引入新方法来提升检索性能,同时也强调了在计算和领域适应性方面需持续创新的必要性。
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/11/29/Paper-Reading-Note-8-LLM-Information-Retrieval-IR/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)