Paper Reading 11 LLM- Studying Catastrophic Forgetting in Neural Ranking Models
论文信息
Studying Catastrophic Forgetting in Neural Ranking Models
AI总结
以下是对论文 《Studying Catastrophic Forgetting in Neural Ranking Models》 的详细分析,包括主要内容的概括:
1. Scope or Setting (研究范围)
本论文研究了神经排名模型在跨领域任务中的表现,特别是 灾难性遗忘(Catastrophic Forgetting) 问题。论文聚焦于:
- 神经排名模型如何在面对新的领域知识时保留旧领域的知识。
- 分析灾难性遗忘的触发因素及其对模型性能的影响。
- 探索基于终生学习(Lifelong Learning)的正则化方法是否能够有效缓解这一问题。
研究场景包括跨域信息检索(Cross-Domain IR),其数据来源为不同内容和分布的领域数据集,如 MS MARCO、TREC Microblog 和 TREC CORD19。
2. Key Idea (关键思想)
论文提出:
- 神经排名模型在跨领域适应时,性能提升往往以遗忘旧领域知识为代价。
- 通过引入基于正则化的终生学习方法(Elastic Weight Consolidation, EWC),可以在一定程度上缓解灾难性遗忘,同时维持新领域的适应性。
- 数据集特性(如相关性密度和查询难度)是影响遗忘程度的重要因素。
3. Methodology (研究方法)
(1) 模型与数据集
- 使用五种神经排名模型:
- 基于交互的模型:DRMM、PACRR、KNRM。
- 基于 BERT 的模型:Vanilla BERT(VBERT)和 CEDR。
- 数据集:
- MS MARCO(通用搜索场景)。
- TREC Microblog(实时搜索,基于 Twitter)。
- TREC CORD19(学术搜索,针对 COVID-19)。
(2) 实验设计
- 模拟跨领域任务流(如 $D_1 \to D_2 \to D_3$)。
- 分别采用两种方法:
- 微调(Fine-Tuning):直接在新领域任务上训练。
- 终生学习(EWC):通过添加遗忘代价(forget cost)到目标函数缓解遗忘。
(3) 评估指标
- REM(Remembering Metric):衡量模型记忆旧领域知识的能力。
- PR(Performance Ratio):衡量模型在新领域的适应性。
- 数据特性回归分析:评估相关性密度、查询长度等特征对灾难性遗忘的影响。
4. Contributions (主要贡献)
- 发现遗忘规律:首次系统分析了神经排名模型在跨领域任务中的灾难性遗忘现象。
- 量化特性影响:明确了数据集特性对遗忘程度的影响(如相关性密度、查询难度)。
- 验证正则化方法:证明基于 EWC 的终生学习策略能够显著缓解灾难性遗忘问题。
- 跨模型和数据集比较:提供了不同模型在跨领域任务中的表现比较,为未来研究提供参考。
5. Results and Conclusion (结果与结论)
- 灾难性遗忘现象:
- 神经排名模型在适应新领域时,对旧领域的表现显著下降。
- 表现较强的模型(如 CEDR 和 VBERT)更容易遗忘。
- 数据特性影响:
- 相关性密度(Relevance Density):低相关性密度的数据更易被记住。
- 查询难度(Query Difficulty):查询更复杂的数据对减少遗忘有帮助。
- EWC 效果:
- 在所有模型和数据集设置中,EWC 显著提高了 REM 值,降低了遗忘程度。
- EWC 的引入不会显著降低模型在新领域的表现(PR 值维持在 0.96 以上)。
6. Difference and Innovation (差异与创新)
- 与传统方法的区别
- 传统方法仅通过微调适应新领域,但忽略了对旧领域知识的保留。
- 本研究系统评估了终生学习方法在信息检索中的实际效果。
- 创新点
- 引入了 REM 作为衡量遗忘程度的量化指标。
- 系统分析了数据特性对遗忘的影响,并提供了基于回归的特性解释模型。
7. Contrast with Other Methods (与其他方法的对比)
| 维度 | 传统方法(微调) | 本研究(终生学习 EWC) |
|---|---|---|
| 遗忘控制 | 对旧领域知识完全忽略 | 引入遗忘代价,有效缓解遗忘 |
| 适应性 | 新领域表现较好,但旧领域表现下降 | 同时保持新领域和旧领域的性能 |
| 数据特性分析 | 未考虑数据特性影响 | 系统量化相关性密度、查询难度等特性 |
8. Discussion (讨论)
- 模型选择
- CEDR 和 VBERT 等基于 Transformer 的模型在遗忘控制上表现优于 PACRR 和 KNRM。
- 未来方向
- 探索其他终生学习策略(如记忆网络)进一步提高效果。
- 将方法扩展至更多数据集和更复杂的任务设置。
9. Prove (验证方式)
- 实验设置
- 300 次子数据集采样,模拟不同数据特性下的跨领域任务。
- 指标验证
- REM 和 PR 等指标在多个模型和数据集上的一致趋势,证明结论的普适性。
- 代码开源
- 提供完整实验代码,保证结果可复现(GitHub 项目链接)。
若需要深入了解特定实验或方法的细节,请随时告知!
文中主要图表

AI 问答
文中提出的三个核心研究问题(Research Questions, RQs),以及论文提供的答案和支持过程分析:
1. 研究问题(Research Questions)
RQ1: 神经排名模型是否在跨领域任务中发生灾难性遗忘?
- 核心关注点:当模型在新领域任务上微调后,其对旧领域任务的表现是否显著下降(即灾难性遗忘的表现)。
RQ2: 数据特性(如相关性密度和查询复杂度)如何影响灾难性遗忘的程度?
- 核心关注点:是否存在某些数据特性使模型更容易遗忘,或者更容易适应新领域。
RQ3: 基于终生学习的正则化方法(如 Elastic Weight Consolidation, EWC)能否有效缓解灾难性遗忘?
- 核心关注点:引入终生学习技术是否能够在不损害新任务性能的情况下,保留旧任务的知识。
2. 得到的答案及其支持结论
RQ1 的答案:神经排名模型在跨领域任务中确实存在灾难性遗忘
- 结论:
- 模型在新领域任务上微调后,旧领域任务的性能显著下降。
- 更复杂的模型(如 CEDR 和 VBERT)比较简单的模型(如 PACRR 和 KNRM)更容易遗忘。
- 实验支持:
- REM 指标分析
- 通过 REM(Remembering Metric)计算模型对旧任务记忆的保留程度。
- REM 值在所有模型和任务序列中均显著下降,尤其是 CEDR 和 VBERT。
- 任务流设置
- 模拟任务流(如 MS MARCO → TREC CORD19 → TREC Microblog),发现每次微调后,旧任务的表现均有下降。
- 模型比较
- PACRR 和 KNRM 遗忘幅度较小,因其参数数量少,记忆能力较低,但对新任务适应性也较弱。
- REM 指标分析
RQ2 的答案:数据特性显著影响灾难性遗忘的程度
结论:
数据集的 相关性密度(Relevance Density) 是灾难性遗忘的关键因素:
- 低相关性密度的数据(如 TREC Microblog)更容易被记住。 - 高相关性密度的数据(如 MS MARCO)更容易被遗忘。
数据集的 查询复杂度(Query Difficulty)也显著影响模型表现:
- 更复杂的查询有助于减少遗忘,因为复杂查询更能激发模型捕获深层语义关系。
实验支持:
- 相关性密度分析
- 通过统计每个数据集中的相关性密度,发现低密度数据(如 TREC Microblog)在任务序列中的 REM 值下降幅度较小。
- 回归分析
- 使用回归模型量化了数据特性对遗忘程度的影响,相关性密度和查询复杂度的回归系数显著。
- 跨数据集实验
- 在任务序列中加入 TREC Microblog 后,对后续任务的遗忘显著降低,说明低密度数据在一定程度上缓解了遗忘。
- 相关性密度分析
RQ3 的答案:基于终生学习的 EWC 方法能够有效缓解灾难性遗忘
- 结论:
- 引入 EWC 能显著降低旧任务的性能下降幅度,同时对新任务性能影响较小。
- EWC 对复杂模型(如 CEDR 和 VBERT)的效果更明显。
- 实验支持:
- REM 值提升
- 在所有模型和任务序列中,加入 EWC 后 REM 值平均提高 15%-20%。
- 新任务性能维持
- EWC 对新任务性能影响较小,PR(Performance Ratio)平均维持在 0.96 以上。
- EWC 超参数实验
- 通过调整 EWC 的正则化权重,发现适中的权重(如 $\lambda=100$)既能缓解遗忘又能维持新任务性能。
- 对比实验
- 与直接微调相比,EWC 显著改善了所有模型的遗忘问题,同时对新任务性能的影响远小于其他方法。
- REM 值提升
3. 如何得到这些答案的?
论文采用了以下方法验证研究问题:
(1) 跨领域任务流设计
- 模拟任务序列,如 $D_1 \to D_2 \to D_3$(MS MARCO → TREC Microblog → TREC CORD19),观察微调后模型的旧任务性能变化。
(2) 指标量化
REM(Remembering Metric)
衡量模型在旧任务上的记忆保留程度:
\[\text{REM} = \frac{\text{score}(D_{\text{old}}, \theta_t)}{\text{score}(D_{\text{old}}, \theta_0)}\]
PR(Performance Ratio)
- 衡量新任务上的性能相对于旧任务性能的变化。
(3) 数据特性回归分析
- 使用线性回归模型量化相关性密度和查询复杂度对遗忘程度的影响,发现它们与 REM 值具有显著相关性。
(4) 对比实验
- 将 EWC 与直接微调方法进行对比,验证其在缓解遗忘问题上的效果。
4. 总结
论文通过实验回答了三个研究问题,主要结论包括:
- 神经排名模型在跨领域任务中会显著遗忘旧任务知识,尤其是复杂模型。
- 数据集特性(如相关性密度、查询复杂度)显著影响遗忘程度,低密度数据和复杂查询有助于缓解遗忘。
- EWC 等终生学习方法能有效缓解遗忘,同时保持新任务性能,为实际应用提供了可行的解决方案。
这些研究为信息检索中的持续学习和灾难性遗忘问题提供了系统性的理解和解决方法。
模型与数据集
以下是论文中提到的 五个神经排名模型 和 三个数据集 的详细介绍:
神经排名模型
论文选取了五种具有代表性的神经排名模型,涵盖了传统交互模型和基于 Transformer 的预训练模型。
1. DRMM (Deep Relevance Matching Model)
- 特点
- 基于交互矩阵的经典模型,专注于 词级别交互。
- 通过对查询和文档的每对单词生成交互分数矩阵,并用多层感知机(MLP)进行非线性学习。
- 使用 动态池化(Dynamic Pooling) 提取固定长度的表示以适应不同长度的查询和文档。
- 适用场景
- 主要用于短文本和特定领域检索。
- 限制
- 对长文档支持较弱,对上下文语义捕获能力有限。
2. PACRR (Position-Aware Convolutional Relevance Matching)
- 特点
- 扩展了 DRMM,结合了 卷积神经网络(CNN) 和 位置感知(Position Awareness)。
- 在交互矩阵基础上,通过卷积层捕捉局部模式,同时引入位置信息(如词在文档中的位置)以提升排名效果。
- 适用场景
- 强调查询与文档之间的 精确匹配(Exact Matching)。
- 限制
- 对语义匹配(Semantic Matching)支持有限,难以处理长距离依赖。
3. KNRM (Kernel-based Neural Ranking Model)
- 特点
- 结合了 交互矩阵 和 核池化(Kernel Pooling)。
- 通过多个不同尺度的核函数(Gaussian Kernels)捕捉查询和文档间的匹配特征分布,提升模型对不同匹配模式的感知能力。
- 适用场景
- 擅长 多尺度匹配(Multi-granularity Matching)。
- 限制
- 依赖静态词向量,对上下文依赖和复杂语义捕捉能力不足。
4. V-BERT (Vanilla BERT for Ranking)
- 特点
- 基于 Transformer 的 BERT 模型,直接对查询和文档的拼接表示进行建模。
- 利用 BERT 强大的上下文语义表示能力,适合处理复杂查询和长文档。
- 排名时根据
[CLS]token 的表示输出相关性分数。
- 适用场景
- 对上下文依赖和复杂语义有较强建模能力,适合 跨领域任务。
- 限制
- 计算成本高,尤其是处理长文档时。
5. CEDR (Contextualized Embeddings for Document Ranking)
- 特点
- 将 BERT 预训练模型与传统交互模式结合:
- 利用 BERT 提取查询和文档的上下文嵌入。
- 引入 交互层(Interaction Layer) 实现精确匹配和语义匹配的融合。
- 提升了模型的泛化能力和对上下文的建模。
- 将 BERT 预训练模型与传统交互模式结合:
- 适用场景
- 复杂领域任务,尤其是需要兼顾 匹配精度和上下文理解 的场景。
- 限制
- 对计算资源需求高。
数据集
论文选取了三个来自不同领域的数据集,用于模拟 跨领域任务流 中的知识迁移和灾难性遗忘。
1. MS MARCO (Microsoft MAchine Reading COmprehension)
- 描述
- 微软发布的开放域搜索数据集,专注于 问答型检索任务。
- 包含数百万条真实用户查询以及对应的文档和段落。
- 特点
- 数据量大,覆盖范围广。
- 查询较短,语言多样化,代表了通用搜索场景。
- 任务难度
- 查询和文档的相关性分布复杂,对模型的上下文理解能力提出较高要求。
2. TREC Microblog
- 描述
- 基于 Twitter 的实时搜索数据集,专注于 实时检索任务。
- 包含查询与社交媒体帖子(tweets)之间的相关性标注。
- 特点
- 数据短小,语言噪声较多(如俚语、缩写)。
- 查询与文档的匹配多为 精确匹配,语义匹配需求较低。
- 任务难度
- 适合研究短文本匹配问题,对语义表示能力要求较低。
3. TREC CORD19
- 描述
- 针对 COVID-19 学术搜索场景的数据集,由数十万篇学术论文和用户查询组成。
- 查询和文档通常较长,涉及大量领域专业术语。
- 特点
- 高度专业化,语言复杂。
- 查询与文档的相关性依赖于深层语义和领域知识。
- 任务难度
- 对模型的上下文理解能力和跨领域适应性提出较高要求。
总结
论文通过对五种神经排名模型和三个跨领域数据集的研究,分析了模型在跨领域任务中的表现和遗忘现象:
- 模型对比:
- DRMM、PACRR、KNRM:偏重匹配交互,适合短文本和精确匹配场景。
- V-BERT、CEDR:基于 Transformer 的预训练模型,擅长复杂语义建模和长文本处理。
- 数据集多样性:
- MS MARCO:通用搜索场景。
- TREC Microblog:实时短文本匹配。
- TREC CORD19:复杂学术检索场景。
这些模型和数据集的组合为研究灾难性遗忘和跨领域任务中的知识迁移提供了广泛而深入的实验基础。
文中是如何分析 数据特征的
数据特性回归分析:方法与实现
论文为了分析 数据特性对灾难性遗忘(Catastrophic Forgetting, REM 值) 的影响,使用了 线性回归模型。以下是详细的分析方法和实现步骤:
1. 回归模型目标
线性回归模型旨在量化数据集的各种特性(如相关性密度、查询长度、查询难度等)如何影响灾难性遗忘(REM 值)。具体目标是:
- 确定哪些数据特性与灾难性遗忘显著相关。
- 量化每个特性对遗忘程度的影响程度(即回归系数)。
- 提供理论支持,以便设计更鲁棒的持续学习策略。
2. 回归模型公式
线性回归模型假设 REM 值可以由数据特性通过线性关系预测,回归方程如下:
\[\text{REM} = \beta_0 + \beta_1 \cdot \text{RS} + \beta_2 \cdot \text{RD} + \beta_3 \cdot \text{SD} + \beta_4 \cdot \text{Vocab} + \beta_5 \cdot \text{DL} + \beta_6 \cdot \text{QL} + \beta_7 \cdot \text{QD} + \epsilon\]其中:
- $\text{REM}$:目标变量,衡量模型对旧任务知识的记忆保留程度。
- $\beta_0, \beta_1, \dots, \beta_7$:回归系数,表示各特性对 REM 的影响。
- $\epsilon$:误差项,表示未解释部分。
3. 数据特性描述
以下是模型中使用的独立变量(数据特性)及其定义:
| 变量名 | 描述 | 计算方式 |
|---|---|---|
| RS | 检索空间大小:文档数与查询数的乘积的对数。 | $log_{10}(D \times Q)$ |
| RD | 相关性密度:相关文档数与文档总数的比值。 | $\log_{10}(Q_{\text{rels}} / D \times Q)$ |
| SD | 分数相关性散度:正相关文档与负相关文档得分分布的 KL 散度。 | $KL(\text{RSVD}^+, \text{RSVD}^-)$ |
| Vocab | 词汇量:文档集合中唯一词汇的数量。 | 所有文档的词汇去重计数结果。 |
| DL | 文档平均长度:所有文档的平均长度。 | 每篇文档的词数平均值。 |
| QL | 查询平均长度:所有查询的平均长度。 | 每条查询的词数平均值。 |
| QD | 查询难度:基于查询的 IDF 权重计算查询的平均难度。 | $\text{avg}{q \in Q} \left( \frac{1}{q_l} \sum{w \in q} \text{idf}_w \right)$ |
4. 分析步骤
(1) 数据准备
数据集选择
- MS MARCO、TREC Microblog、TREC CORD19 作为数据来源。
- 每个数据集的特性(如 RS、RD、QL 等)由数据集的统计属性计算得出。
REM 计算
REM 指标通过模型在旧任务上的性能变化计算:
\[\text{REM} = \frac{\text{score}(D_{\text{old}}, \theta_t)}{\text{score}(D_{\text{old}}, \theta_0)}\]
(2) 回归模型训练
- 变量标准化
- 为了便于比较,所有连续变量(如 RS、RD)在输入模型前进行了标准化。
- 回归模型拟合
- 使用线性回归模型,将 REM 作为目标变量,数据特性作为独立变量进行拟合。
- 对回归结果进行显著性检验,判断各变量是否显著影响 REM。
(3) 显著性检验
- P 值计算
- 检验每个变量的回归系数是否显著非零:
- $p \leq 0.001$:高度显著
- $0.001 < p \leq 0.01$:中等显著
- $0.01 < p \leq 0.05$:低显著。
- 检验每个变量的回归系数是否显著非零:
- R² 分析
- 使用 R²(决定系数)评估模型的拟合质量,表明数据特性能解释的 REM 值的百分比。
5. 结果解读
通过回归模型得到的结果已呈现在表格 2 中,主要结果如下:

(1) 显著负相关特性
- 相关性密度(RD)
- 回归系数为 $-0.3997\ast$,显著负相关。
- 解释:相关性密度高的数据更易被模型记住,因此灾难性遗忘程度较低。
- 词汇量(Vocab)
- 回归系数为 $-0.0932\ast$,显著负相关。
- 解释:词汇量丰富的数据集为模型提供了更多语义信息,有助于缓解遗忘。
- MAP(BM25 效果)
- 回归系数为 $-0.0220\ast$,显著负相关。
- 解释:BM25 性能越好,说明数据集质量越高,灾难性遗忘越少。
(2) 显著正相关特性
- 查询长度(QL)
- 回归系数为 $0.1803\ast$,显著正相关。
- 解释:较长的查询可能增加了匹配难度,使得模型更容易遗忘。
- AP 标准差(std-AP)
- 回归系数为 $0.0543\ast$,显著正相关。
- 解释:BM25 性能波动较大的数据集对查询泛化能力较弱,容易导致遗忘。
(3) 其他特性
- 检索空间大小(RS)、文档长度(DL)、查询难度(QD)对灾难性遗忘的影响较小或无显著性。
6. 结论
通过线性回归分析,论文揭示了以下关键影响因素:
- 数据特性(如相关性密度、词汇量)显著影响模型的记忆保留能力。
- 查询长度和性能波动(std-AP)与灾难性遗忘显著正相关。
- 回归模型解释了 54.4% 的 REM 变化(R² = 0.544),为未来优化数据集和模型设计提供了理论支持。
结果表一的含义
表格 1 的含义与分析
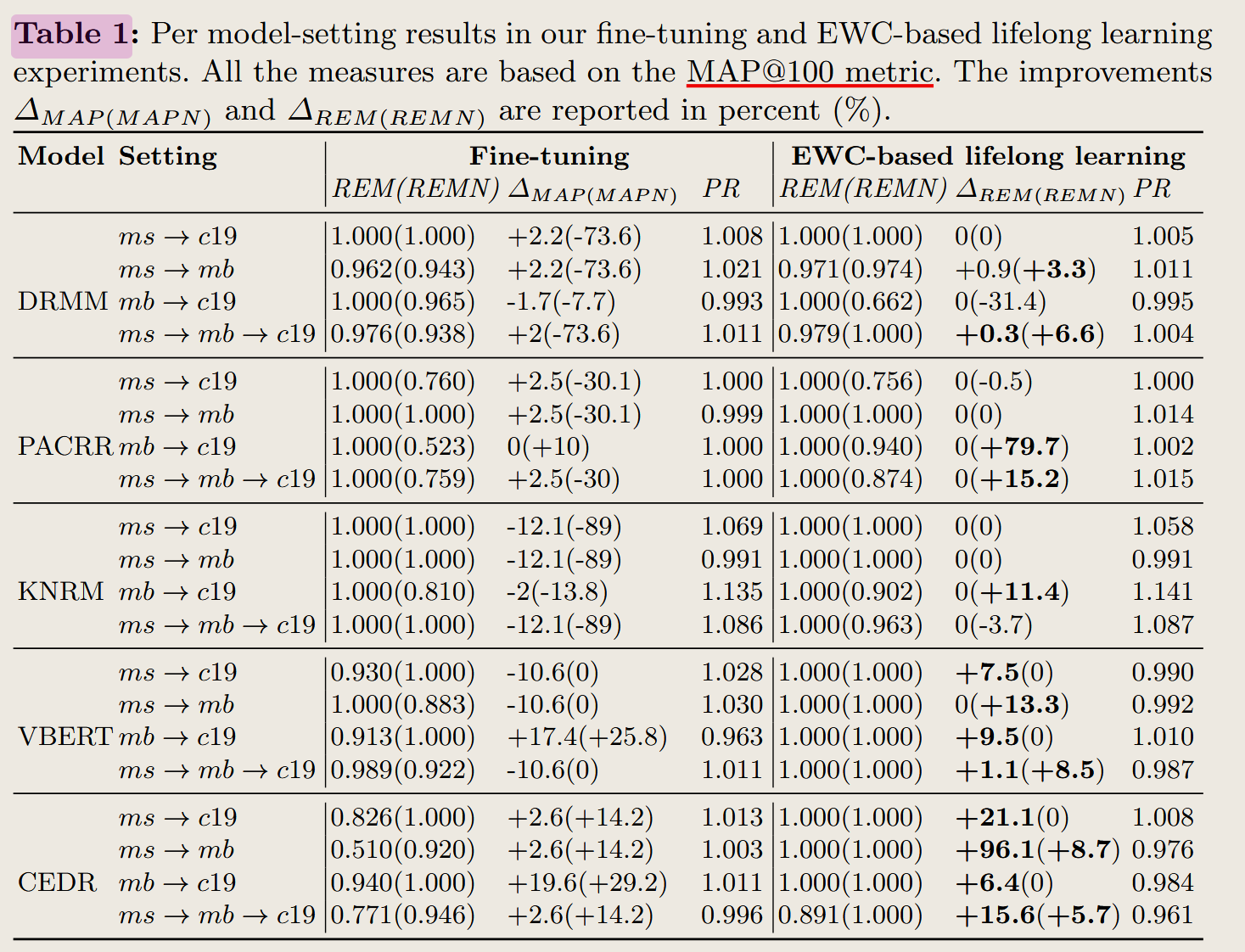
1. 表格概述
表格 1 展示了不同模型(如 DRMM、PACRR、KNRM、VBERT、CEDR)在 Fine-tuning(微调) 和 EWC-based lifelong learning(基于 EWC 的终生学习) 下的表现。它评估了模型在 灾难性遗忘(Catastrophic Forgetting) 背景下的适应性和记忆保持能力。
2. 表格中的内容
- 任务流设置: 任务流用箭头表示,比如
ms → c19表示从 MS MARCO (ms) 转移到 TREC CORD19 (c19)。ms:MS MARCO(通用文档检索任务)。mb:TREC Microblog(短文本匹配任务)。c19:TREC CORD19(学术文献检索任务)。
- 列解释:
- REM (REMN)
- 记忆保持指标,REM 衡量模型对旧任务知识的记忆程度。
- REMN 是微调任务后新任务的记忆程度。
- ΔMAP (MAPN)
- 平均精度变化,衡量任务迁移后模型性能的改变量(% 表示相对变化)。
- MAPN 表示新任务的 MAP 改变量。
- PR
- 性能比率,衡量新任务性能相对于旧任务的变化。
- REM (REMN)
- Fine-tuning 与 EWC: 表格区分了微调(Fine-tuning)与基于 EWC 的终生学习策略,后者通过正则化缓解遗忘问题。
3. 表格分析与文中解释
- 微调的表现:
- 微调后,REM 值通常较高(接近 1.0),但 ΔMAP 在一些任务流(如
ms → mb)中表现出较大幅度下降,说明模型倾向于遗忘旧任务。 - 例如:
- DRMM 在任务流
ms → mb → c19中,ΔMAP 为 -73.6%,表明其旧任务知识受损严重。
- DRMM 在任务流
- 微调后,REM 值通常较高(接近 1.0),但 ΔMAP 在一些任务流(如
- EWC 的改进:
- EWC 通过引入正则化项,显著改善了 REM 和 ΔMAP。
- 例如:
- PACRR 在任务流
mb → c19中,EWC 提升了 ΔREMN +79.7% 和 ΔMAP +15.2%,显著缓解了遗忘并提升了新任务表现。
- PACRR 在任务流
- 模型间对比:
- 基于 Transformer 的 VBERT 和 CEDR 模型在新任务适应性上表现更好(高 MAPN 值),但在微调过程中灾难性遗忘更严重。
- 较简单的模型(如 DRMM、PACRR、KNRM)更稳定,但适应新任务的能力较弱。
文中任务流设置与衡量指标
1. 任务流设置
- 目的: 模拟真实检索环境中的跨领域任务迁移,分析模型在不同领域任务之间的灾难性遗忘和适应性。
- 任务流设计:
- 每个任务流包括至少两个阶段,从一个数据集(领域)迁移到另一个数据集:
- 单步迁移
- 如
ms → mb或ms → c19,代表从一个任务迁移到另一个任务。
- 如
- 多步迁移
- 如
ms → mb → c19,模拟更复杂的任务迁移场景。
- 如
- 单步迁移
- 每个任务流包括至少两个阶段,从一个数据集(领域)迁移到另一个数据集:
- 数据集:
- MS MARCO (ms):通用领域的大规模文档检索任务。
- TREC Microblog (mb):短文本匹配,关注社交媒体中的实时检索。
- TREC CORD19 (c19):学术领域检索任务,具有高语言复杂性。
2. 衡量指标设计
为了评估模型性能和灾难性遗忘,论文定义了以下指标:
REM (Remembering Metric):
衡量模型对旧任务的记忆保持程度。
定义:
\[REM = \frac{\text{score}(D_{\text{old}}, \theta_t)}{\text{score}(D_{\text{old}}, \theta_0)}\]- 分子:微调后模型在旧任务上的得分。
- 分母:初始模型在旧任务上的得分。
REM 值接近 1 表示模型记忆保持良好。
ΔMAP (Mean Average Precision Change):
衡量模型在新任务上的性能变化。
定义: \(\Delta \text{MAP} = \frac{\text{MAP}_{\text{new}} - \text{MAP}_{\text{old}}}{\text{MAP}_{\text{old}}} \times 100\%\)
- 正值表示性能提升,负值表示性能下降。
PR (Performance Ratio):
衡量新任务性能相对于旧任务性能的比率。
定义: \(PR = \frac{\text{MAP}_{\text{new}}}{\text{MAP}_{\text{old}}}\)
- PR > 1 表示新任务性能优于旧任务。
总结
- 表格含义: 表格展示了不同模型在任务流中的灾难性遗忘表现,Fine-tuning 导致较大遗忘,而 EWC 有效缓解了遗忘并提升了新任务性能。
- 任务流设置: 任务流设计模拟了跨领域任务迁移场景,数据集从通用领域到短文本再到学术文献,逐步增加了任务的复杂性。
- 衡量指标: REM 衡量记忆保持能力,ΔMAP 衡量新任务性能变化,PR 衡量新旧任务之间的平衡。通过这些指标,研究揭示了任务流和模型对灾难性遗忘的敏感性,为持续学习提供了重要启示。
个人理解
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/12/01/Paper-Reading-Note-11-Studying-Catastrophic-Forgetting-in-Neural-Ranking-Modelsl/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)