Coding – mteb package
mteb
GitHub
https://github.com/embeddings-benchmark/mteb
论文
主要内容
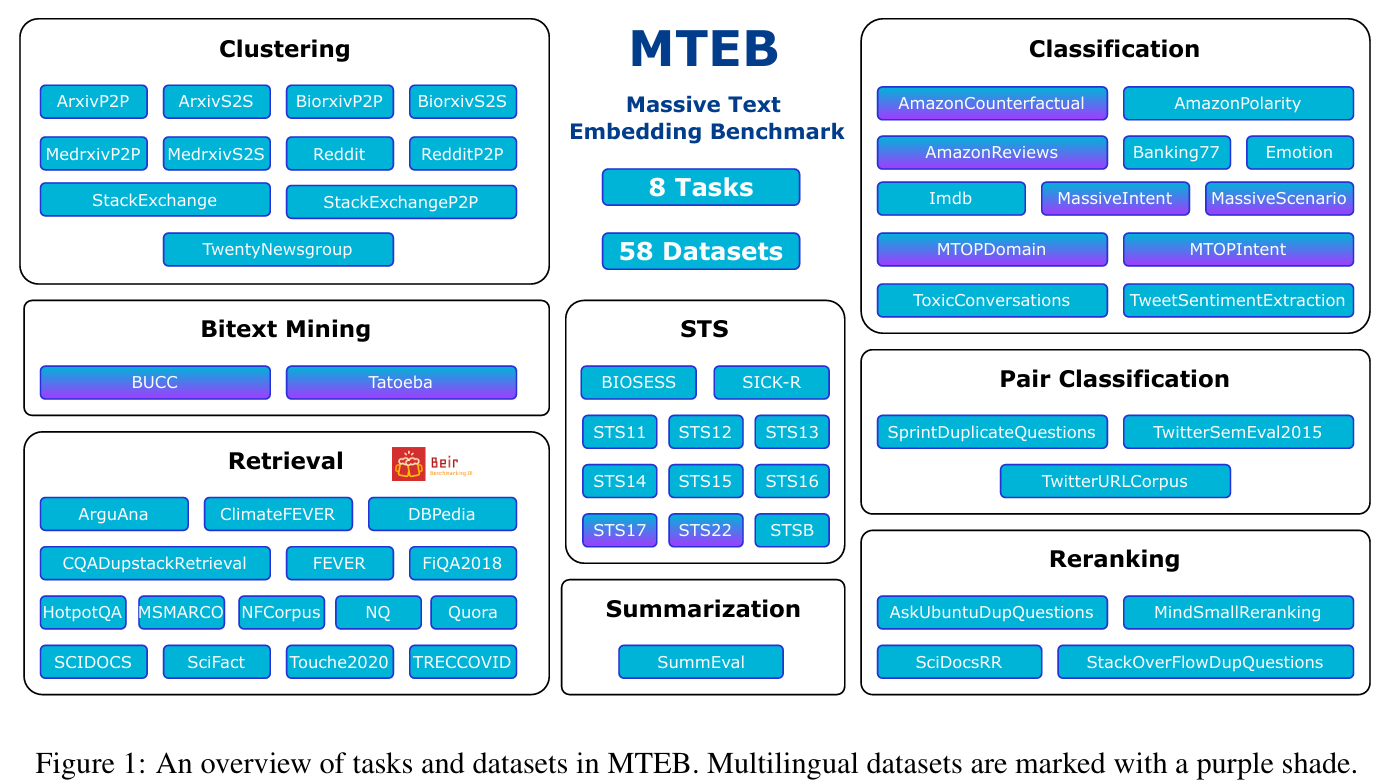
架构
RetrievalEvaluator
https://github.com/beir-cellar/beir/blob/f062f038c4bfd19a8ca942a9910b1e0d218759d4/beir/retrieval/evaluation.py#L9
核心代码解析 search 函数
代码所在路径

def search(
self,
corpus: dict[str, dict[str, str]],
queries: dict[str, str],
top_k: int,
score_function: str,
return_sorted: bool = False,
**kwargs,
) -> dict[str, dict[str, float]]:
# Create embeddings for all queries using model.encode_queries()
# Runs semantic search against the corpus embeddings
# Returns a ranked list with the corpus ids
if score_function not in self.score_functions:
raise ValueError(
"score function: {} must be either (cos_sim) for cosine similarity or (dot) for dot product".format(
score_function
)
)
logger.info("Encoding Queries...")
# 提取查询的 ID 列表
query_ids = list(queries.keys())
# 初始化结果字典 self.results,为每个查询预留存储空
self.results = {qid: {} for qid in query_ids}
# 按照查询 ID 提取查询文本,生成查询列表
queries = [queries[qid] for qid in queries]
# 调用模型的 encode_queries 方法将其编码为嵌入表示
query_embeddings = self.model.encode_queries(
queries,
batch_size=self.batch_size,
show_progress_bar=self.show_progress_bar,
convert_to_tensor=self.convert_to_tensor,
**kwargs,
)
logger.info("Sorting Corpus by document length (Longest first)...")
# 按文档长度(标题 + 内容的字符数)对文档排序,优先处理长文档
corpus_ids = sorted(
corpus,
key=lambda k: len(corpus[k].get("title", "") + corpus[k].get("text", "")),
reverse=True,
)
# 按排序结果重新组织文档集合,提取文档的内容
corpus = [corpus[cid] for cid in corpus_ids]
logger.info("Encoding Corpus in batches... Warning: This might take a while!")
logger.info(
"Scoring Function: {} ({})".format(
self.score_function_desc[score_function], score_function
)
)
# 将文档分成块(每块大小为 self.corpus_chunk_size),逐块处理以节省内存
itr = range(0, len(corpus), self.corpus_chunk_size)
# 初始化一个 小顶堆(heapq)用于每个查询,存储前 k 个相关文档
result_heaps = {
qid: [] for qid in query_ids
} # Keep only the top-k docs for each query
for batch_num, corpus_start_idx in enumerate(itr): #遍历每个文档块的起始索引
logger.info("Encoding Batch {}/{}...".format(batch_num + 1, len(itr)))
# 确保处理的文档块不会超过文档集合的范围
corpus_end_idx = min(corpus_start_idx + self.corpus_chunk_size, len(corpus))
# 如果启用了 save_corpus_embeddings 并缓存了文档块嵌入,则直接加载缓存
# Encode chunk of corpus
if (
self.save_corpus_embeddings
and "qid" in kwargs
and len(self.corpus_embeddings[kwargs["qid"]])
):
sub_corpus_embeddings = torch.tensor(
self.corpus_embeddings[kwargs["qid"]][batch_num]
)
else: # 否则,调用模型的 encode_corpus 方法对当前文档块进行编码
# Encode chunk of corpus
sub_corpus_embeddings = self.model.encode_corpus(
corpus[corpus_start_idx:corpus_end_idx],
batch_size=self.batch_size,
show_progress_bar=self.show_progress_bar,
convert_to_tensor=self.convert_to_tensor,
)
if self.save_corpus_embeddings and "qid" in kwargs:
self.corpus_embeddings[kwargs["qid"]].append(sub_corpus_embeddings)
# Compute similarites using either cosine-similarity or dot product
# 使用指定的评分函数("cos_sim" 或 "dot")计算查询嵌入和文档块嵌入的相似度
cos_scores = self.score_functions[score_function](
query_embeddings, sub_corpus_embeddings
)
cos_scores[torch.isnan(cos_scores)] = -1
# Get top-k values
# 按查询嵌入计算的相似度,找到每个查询的前 top_k 文档
# 返回分数(cos_scores_top_k_values)
# 和对应文档的索引(cos_scores_top_k_idx)
cos_scores_top_k_values, cos_scores_top_k_idx = torch.topk(
cos_scores,
min(
top_k + 1,
len(cos_scores[1]) if len(cos_scores) > 1 else len(cos_scores[-1]),
),
dim=1,
largest=True,
sorted=return_sorted,
)
cos_scores_top_k_values = cos_scores_top_k_values.cpu().tolist()
cos_scores_top_k_idx = cos_scores_top_k_idx.cpu().tolist()
# 更新小顶堆
for query_itr in range(len(query_embeddings)):
query_id = query_ids[query_itr]
for sub_corpus_id, score in zip(
cos_scores_top_k_idx[query_itr], cos_scores_top_k_values[query_itr]
):
corpus_id = corpus_ids[corpus_start_idx + sub_corpus_id]
if corpus_id != query_id:
if len(result_heaps[query_id]) < top_k:
# 如果堆未满,直接插入
# Push item on the heap
heapq.heappush(result_heaps[query_id], (score, corpus_id))
else:
# 如果堆已满,插入新的元素并移除最小的元素(保持堆大小为 top_k)。
# If item is larger than the smallest in the heap, push it on the heap then pop the smallest element
heapq.heappushpop(
result_heaps[query_id], (score, corpus_id)
)
# 将每个查询对应堆中的文档和分数整理到 self.results 中
for qid in result_heaps:
for score, corpus_id in result_heaps[qid]:
self.results[qid][corpus_id] = score
return self.results
核心代码解析 _evaluate_split 函数
代码所在路径

def _evaluate_split(
self, retriever, corpus, queries, relevant_docs, lang=None, **kwargs
):
start_time = time()
# 调用 retriever 的 search() 方法:
# 输入文档集合 corpus 和查询集合 queries。
# 返回每个查询的检索结果,格式为 {query_id: {doc_id: score}}
results = retriever(corpus, queries)
end_time = time()
logger.info(
"Time taken to retrieve: {:.2f} seconds".format(end_time - start_time)
)
# 尝试改成true 查看这个预测结果是什么,
# if kwargs.get("save_predictions", False):
if kwargs.get("save_predictions", True):
output_folder = kwargs.get("output_folder", "predictions_results")
if not os.path.isdir(output_folder):
os.makedirs(output_folder)
top_k = kwargs.get("top_k", None)
if top_k is not None:
for qid in list(results.keys()):
doc_ids = set(
sorted(
results[qid], key=lambda x: results[qid][x], reverse=True
)[:top_k]
)
results[qid] = {
k: v for k, v in results[qid].items() if k in doc_ids
}
if lang is None:
qrels_save_path = (
f"{output_folder}/{self.metadata_dict['name']}_predictions.json"
)
else:
qrels_save_path = f"{output_folder}/{self.metadata_dict['name']}_{lang}_predictions.json"
with open(qrels_save_path, "w") as f:
json.dump(results, f)
调用 evaluate 方法:
# 使用标注的相关性数据(relevant_docs)和检索结果(results)计算以下指标:
# NDCG(归一化折损累计增益): 衡量排序质量。
# MAP(平均准确率): 衡量多个查询的准确率均值。
# Recall: 衡量相关文档的检索覆盖率。
# Precision: 衡量检索结果的相关性。
# 参数:# retriever.k_values: 指定评估时的 k 值列表(如 top-1、top-10 等)。
# ignore_identical_ids: 是否忽略查询和文档 ID 相同的情况。
ndcg, _map, recall, precision = retriever.evaluate(
relevant_docs,
results,
retriever.k_values,
ignore_identical_ids=kwargs.get("ignore_identical_ids", True),
)
# evaluate_custom 方法:
# 使用 relevant_docs 和 results 计算自定义指标。
# mrr(平均倒数排名):
# 衡量第一个相关文档出现在检索结果中的平均排名
mrr = retriever.evaluate_custom(
relevant_docs, results, retriever.k_values, "mrr"
)
scores = {
**{f"ndcg_at_{k.split('@')[1]}": v for (k, v) in ndcg.items()},
**{f"map_at_{k.split('@')[1]}": v for (k, v) in _map.items()},
**{f"recall_at_{k.split('@')[1]}": v for (k, v) in recall.items()},
**{f"precision_at_{k.split('@')[1]}": v for (k, v) in precision.items()},
**{f"mrr_at_{k.split('@')[1]}": v for (k, v) in mrr.items()},
}
return scores
其中上述代码调用了
evaluate 和 evaluate_custom 函数
路径为

MSMARCO
https://microsoft.github.io/msmarco/
Pytrec_eval
上面的 evaluate 中的下一行代码
scores = evaluator.evaluate(results)
调用了 pytrec_eval 函数,代码库如下
其中的cpp 文件如下,首先调用了函数 static PyObject* RelevanceEvaluator_evaluate
static PyObject* RelevanceEvaluator_evaluate(RelevanceEvaluator* self, PyObject* args) {
PyObject* object_scores = NULL;
if (!PyArg_ParseTuple(args, "O", &object_scores) ||
!PyDict_Check(object_scores)) {
PyErr_SetString(
PyExc_TypeError,
"Argument object scores should be of type dictionary.");
return NULL;
}
ResultRankingBuilder builder;
int64 num_queries = 0;
ResultRankingBuilder::QueryType* queries = NULL;
if (!builder(object_scores, num_queries, queries)) {
PyErr_SetString(
PyExc_TypeError,
"Unable to extract query/object scores.");
return NULL;
}
CHECK_NOTNULL(queries);
for (size_t query_idx = 0; query_idx < num_queries; ++query_idx) {
TEXT_RESULTS_INFO* const text_results_info = (TEXT_RESULTS_INFO*) queries[query_idx].q_results;
ResultRankingBuilder::QueryDocumentPairType* const text_results = text_results_info->text_results;
const long num_text_results = text_results_info->num_text_results;
std::sort(
text_results, text_results + num_text_results,
query_document_pair_compare);
}
ALL_RESULTS all_results;
TREC_EVAL q_eval;
all_results.num_q_results = num_queries;
all_results.results = queries;
TREC_EVAL accum_eval;
#ifdef _MSC_VER
accum_eval = TREC_EVAL {"all", 0, NULL, 0, 0};
#else
accum_eval = (TREC_EVAL) {"all", 0, NULL, 0, 0};
#endif
for (std::set<size_t>::iterator it = self->measures_->begin();
it != self->measures_->end(); ++it) {
const size_t measure_idx = *it;
// re-apply default arg values
if (te_trec_measures[measure_idx]->meas_params != NULL) {
Free(te_trec_measures[measure_idx]->meas_params);
PARAMS* params = new PARAMS();
params->printable_params = default_meas_params[measure_idx].printable_params;
params->num_params = default_meas_params[measure_idx].num_params;
params->param_values = default_meas_params[measure_idx].param_values;
te_trec_measures[measure_idx]->meas_params = params; /* {
default_meas_params[measure_idx].printable_params,
default_meas_params[measure_idx].num_params,
default_meas_params[measure_idx].param_values};*/
}
te_trec_measures[measure_idx]->init_meas(
&self->epi_,
te_trec_measures[measure_idx],
&accum_eval);
}
/* Reserve space and initialize q_eval to be copy of accum_eval */
q_eval.values = Malloc(
accum_eval.num_values, TREC_EVAL_VALUE);
CHECK_NOTNULL(q_eval.values);
memcpy(q_eval.values, accum_eval.values,
accum_eval.num_values * sizeof (TREC_EVAL_VALUE));
q_eval.num_values = accum_eval.num_values;
q_eval.num_queries = 0;
// Holds the result.
PyObject* const result = PyDict_New();
for (size_t result_query_idx = 0;
result_query_idx < num_queries;
++result_query_idx) {
const std::string qid = all_results.results[result_query_idx].qid;
std::map<std::string, size_t>::iterator it = self->query_id_to_idx_->find(qid);
if (it == self->query_id_to_idx_->end()) {
// Query not found in relevance judgments; skipping.
continue;
}
const size_t eval_query_idx = it->second;
q_eval.qid = all_results.results[result_query_idx].qid;
PyObject* const query_measures = PyDict_New();
for (std::set<size_t>::iterator it = self->measures_->begin();
it != self->measures_->end(); ++it) {
const size_t measure_idx = *it;
// Empty buffer.
for (int32 value_idx = 0; value_idx < q_eval.num_values; ++value_idx) {
q_eval.values[value_idx].value = 0;
}
// Compute measure.
te_trec_measures[measure_idx]->calc_meas(
&self->epi_,
&self->all_rel_info_.rel_info[eval_query_idx],
&all_results.results[result_query_idx],
te_trec_measures[measure_idx],
&q_eval);
CHECK_GE(te_trec_measures[measure_idx]->eval_index, 0);
if (te_trec_measures[measure_idx]->print_single_meas == &te_print_single_meas_a_cut) {
for (int32 param_idx = 0;
param_idx < te_trec_measures[measure_idx]->meas_params->num_params;
++param_idx) {
PyDict_SetItemAndSteal(
query_measures,
PyUnicode_FromString(
q_eval.values[te_trec_measures[measure_idx]->eval_index + param_idx].name),
PyFloat_FromDouble(
q_eval.values[te_trec_measures[measure_idx]->eval_index + param_idx].value));
}
} else {
PyDict_SetItemAndSteal(
query_measures,
PyUnicode_FromString(te_trec_measures[measure_idx]->name),
PyFloat_FromDouble(
q_eval.values[te_trec_measures[measure_idx]->eval_index].value));
}
// Add the measure value to the aggregate.
// This call is probably unnecessary as we don't rely on trec_eval's averaging mechanism.
te_trec_measures[measure_idx]->acc_meas(
&self->epi_,
te_trec_measures[measure_idx],
&q_eval,
&accum_eval);
if (__DEVELOPMENT) {
// Print.
te_trec_measures[measure_idx]->print_single_meas(
&self->epi_,
te_trec_measures[measure_idx],
&q_eval);
}
accum_eval.num_queries++;
}
PyDict_SetItemAndSteal(
result,
PyUnicode_FromString(qid.c_str()),
query_measures);
}
for (std::set<size_t>::iterator it = self->measures_->begin();
it != self->measures_->end(); ++it) {
const size_t measure_idx = *it;
// Cleanup; nothing gets printed as self->epi_.summary_flag == 0.
te_trec_measures[measure_idx]->print_final_and_cleanup_meas
(&self->epi_, te_trec_measures[measure_idx], &accum_eval);
}
// Clean.
builder.cleanup(num_queries, queries);
Free(q_eval.values);
Free(accum_eval.values);
te_form_res_rels_cleanup();
return result;
}
根据gpt总结,其主要功能为
计算流程概括
- 输入准备:
qrels(查询相关性标注): 指定每个查询对应的相关文档及其相关性得分。results(检索结果): 系统为每个查询返回的文档及其匹配得分。
- 数据解析:
- 将 qrels和 results数据格式化为内部结构:
REL_INFO: 用于存储相关性标注数据。RESULTS: 用于存储检索结果数据。- 对
results中的每个查询结果按匹配得分降序排序。
- 逐查询计算指标:
针对每个查询 (
query_id),将系统返回的检索结果与标注进行对比。计算以下指标(按 k值,如 top-1, top-10等):
NDCG (Normalized Discounted Cumulative Gain): 衡量检索结果的排序质量。
\(NDCG@k = \frac{DCG@k}{IDCG@k}\) 其中:
\(DCG@k = \sum_{i=1}^k \frac{rel_i}{\log_2(i+1)}\) $relirel_i$ 是第 ii 个文档的相关性得分。 IDCG@kIDCG@k 是理想排序下的 DCGDCG。
MAP (Mean Average Precision): 衡量多个查询的准确率均值。
\(QMAP@k = \frac{\sum_{q=1}^Q AP(q)}{Q}\) 其中: $$ AP(q) = \frac{\sum_{k=1}^n P(k) \cdot rel(k)}
P(k)P(k) $$
$P(k) $是前 $k$个结果的精确率,$rel(k)$ 是第 $k $个文档的相关性标注。
Recall: 衡量相关文档的检索覆盖率。 \(Recall@k = \frac{\text{RelevantRetrieved}@k}{\text{Relevant}}\)
Precision: 衡量返回文档的相关性。 \(Precision@k = \frac{\text{RelevantRetrieved}@k}{k}\)
- 累积结果并求均值:
- 对所有查询的指标值累加。
- 求平均以得到整体表现。
- 返回结果:
- 返回一个嵌套字典,包含每个查询的各指标值,以及最终的平均结果。
总结
- 流程
- 数据格式化。
- 排序检索结果。
- 按查询逐一计算指标。
- 累积并平均化结果。
- 主要计算公式
- NDCG: 排序质量。
- MAP: 查询的平均准确率。
- Recall: 覆盖率。
- Precision: 精确率。
这些指标是评估信息检索系统性能的核心标准,适用于各种检索任务。
上面的 evaluate_custom 中的下一行代码
return mrr(qrels, results, k_values)
调用了 mrr 函数,

代码如下
https://github.com/beir-cellar/beir/blob/f062f038c4bfd19a8ca942a9910b1e0d218759d4/beir/retrieval/custom_metrics.py#L4
# From https://github.com/beir-cellar/beir/blob/f062f038c4bfd19a8ca942a9910b1e0d218759d4/beir/retrieval/custom_metrics.py#L4
def mrr(
qrels: dict[str, dict[str, int]],
results: dict[str, dict[str, float]],
k_values: List[int],
) -> Tuple[Dict[str, float]]:
"""
计算查询的平均倒数排名(Mean Reciprocal Rank)。
测量第一个相关文档出现在检索结果中的排名的倒数。
"""
MRR = {}
# 为每个 k 值(k_values 中的前 k 个文档)初始化 MRR@k 为 0.0。
for k in k_values:
MRR[f"MRR@{k}"] = 0.0
# 计算 k_values 中的最大值 k_max,后续只需计算 top_k 文档。
# 初始化 top_hits 用于存储每个查询的 top_k 文档。
k_max, top_hits = max(k_values), {}
logging.info("\n")
# 对每个查询 query_id 的文档得分进行排序,按分数从高到低取前 k_max 个文档。
for query_id, doc_scores in results.items():
top_hits[query_id] = sorted(
doc_scores.items(), key=lambda item: item[1], reverse=True
)[0:k_max]
for query_id in top_hits:
# 提取查询的相关文档 query_relevant_docs
query_relevant_docs = set(
[doc_id for doc_id in qrels[query_id] if qrels[query_id][doc_id] > 0]
)
# 遍历 k 值,对于每个查询:
# 如果第一个相关文档出现在第 rank + 1 位,则累加其倒数排名到 MRR@k。
for k in k_values:
for rank, hit in enumerate(top_hits[query_id][0:k]):
if hit[0] in query_relevant_docs:
MRR[f"MRR@{k}"] += 1.0 / (rank + 1)
break
# 对每个 k 值,取查询的平均倒数排名
for k in k_values:
MRR[f"MRR@{k}"] = round(MRR[f"MRR@{k}"] / len(qrels), 5)
logging.info("MRR@{}: {:.4f}".format(k, MRR[f"MRR@{k}"]))
return MRR
def recall_cap(
qrels: dict[str, dict[str, int]],
results: dict[str, dict[str, float]],
k_values: List[int],
) -> Tuple[Dict[str, float]]:
"""
测量检索系统是否能够检索到所有相关文档,考虑文档数量的限制。
"""
# 初始化 R_cap@k 为 0.0
capped_recall = {}
for k in k_values:
capped_recall[f"R_cap@{k}"] = 0.0
# 找到 k_values 中的最大值 k_max
k_max = max(k_values)
logging.info("\n")
for query_id, doc_scores in results.items():
# # 对每个查询,取前 k_max 个文档
top_hits = sorted(doc_scores.items(), key=lambda item: item[1], reverse=True)[
0:k_max
]
# 提取查询的所有相关文档
query_relevant_docs = [
doc_id for doc_id in qrels[query_id] if qrels[query_id][doc_id] > 0
]
# 计算前 k 个文档中检索到的相关文档数,并归一化为 1
for k in k_values:
retrieved_docs = [
row[0] for row in top_hits[0:k] if qrels[query_id].get(row[0], 0) > 0
]
denominator = min(len(query_relevant_docs), k)
capped_recall[f"R_cap@{k}"] += len(retrieved_docs) / denominator
for k in k_values:
capped_recall[f"R_cap@{k}"] = round(capped_recall[f"R_cap@{k}"] / len(qrels), 5)
logging.info("R_cap@{}: {:.4f}".format(k, capped_recall[f"R_cap@{k}"]))
# 对所有查询取平均,得到最终的 R_cap@k
return capped_recall
def hole(
qrels: dict[str, dict[str, int]],
results: dict[str, dict[str, float]],
k_values: List[int],
) -> Tuple[Dict[str, float]]:
"""
测量检索结果中未被标注的文档数量占比
"""
Hole = {}
for k in k_values:
Hole[f"Hole@{k}"] = 0.0
annotated_corpus = set()
for _, docs in qrels.items():
for doc_id, score in docs.items():
annotated_corpus.add(doc_id)
k_max = max(k_values)
logging.info("\n")
for _, scores in results.items():
top_hits = sorted(scores.items(), key=lambda item: item[1], reverse=True)[
0:k_max
]
for k in k_values:
hole_docs = [
row[0] for row in top_hits[0:k] if row[0] not in annotated_corpus
]
Hole[f"Hole@{k}"] += len(hole_docs) / k
for k in k_values:
Hole[f"Hole@{k}"] = round(Hole[f"Hole@{k}"] / len(qrels), 5)
logging.info("Hole@{}: {:.4f}".format(k, Hole[f"Hole@{k}"]))
return Hole
def top_k_accuracy(
qrels: dict[str, dict[str, int]],
results: dict[str, dict[str, float]],
k_values: List[int],
) -> Tuple[Dict[str, float]]:
"""
测量前 k 个文档中是否包含相关文档
"""
# 始化 Accuracy@k 为 0.0
top_k_acc = {}
# 找到 k_max,初始化 top_hits
for k in k_values:
top_k_acc[f"Accuracy@{k}"] = 0.0
k_max, top_hits = max(k_values), {}
logging.info("\n")
# 对每个查询,按得分排序,提取前 k_max 个文档
for query_id, doc_scores in results.items():
top_hits[query_id] = [
item[0]
for item in sorted(
doc_scores.items(), key=lambda item: item[1], reverse=True
)[0:k_max]
]
for query_id in top_hits:
# 提取查询的相关文档
query_relevant_docs = set(
[doc_id for doc_id in qrels[query_id] if qrels[query_id][doc_id] > 0]
)
# 检查前 k 个文档是否包含相关文档
for k in k_values:
for relevant_doc_id in query_relevant_docs:
if relevant_doc_id in top_hits[query_id][0:k]:
top_k_acc[f"Accuracy@{k}"] += 1.0
break
# 对所有查询取平均,得到 Accuracy@k
for k in k_values:
top_k_acc[f"Accuracy@{k}"] = round(top_k_acc[f"Accuracy@{k}"] / len(qrels), 5)
logging.info("Accuracy@{}: {:.4f}".format(k, top_k_acc[f"Accuracy@{k}"]))
return top_k_acc
gpt解析如下
检索评价指标的区别和联系
下面对 MRR、Capped Recall、Hole 和 Top-k Accuracy 四个评价指标的区别、联系以及计算公式进行总结。
1. Mean Reciprocal Rank (MRR)
描述
- MRR 主要评估第一个相关文档在检索结果中的排名质量。
- 它关注检索结果中第一个相关文档的排名倒数。
计算公式
\(\text{MRR} = \frac{1}{|Q|} \sum_{q \in Q} \frac{1}{\text{rank}_q}\)
其中:
- ( Q ) 是查询集合。
- ( \text{rank}_q ) 是第一个相关文档在查询 ( q ) 的检索结果中的排名(从 1 开始)。
特点
- 越靠前的相关文档对指标的贡献越大。
- 用于评估检索系统返回相关文档的及时性。
2. Capped Recall
描述
- Capped Recall 是一种归一化的召回率,限定了最多能检索到的相关文档数为 ( k )。
- 计算在检索结果的前 ( k ) 个文档中,检索到的相关文档数与 ( \min(k, \text{#Relevant}) ) 的比值。
计算公式
\(R_{\text{cap}@k} = \frac{|\text{RetrievedRelevant}@k|}{\min(k, |\text{Relevant}|)}\)
其中:
- ( \text{RetrievedRelevant}@k ) 是前 ( k ) 个文档中相关文档的数量。
- ( \text{Relevant} ) 是查询的总相关文档数量。
特点
- 如果相关文档总数少于 ( k ),则召回率被限制在 1。
- 强调在文档数量受限情况下的检索能力。
3. Hole
描述
- Hole 衡量检索结果中未被标注的文档比例。
- 它计算前 ( k ) 个文档中未被相关性标注的文档数占 ( k ) 的比例。
计算公式
\(\text{Hole@k} = \frac{|\text{UnannotatedDocs}@k|}{k}\)
其中:
- ( \text{UnannotatedDocs}@k ) 是前 ( k ) 个文档中未被标注的文档数量。
特点
- 表示模型输出中噪音的多少。
- 可用于评估标注数据的覆盖率。
4. Top-k Accuracy
描述
- Top-k Accuracy 衡量检索结果的前 ( k ) 个文档中是否包含相关文档。
- 它关注前 ( k ) 个文档中是否至少有一个文档是相关的。
计算公式
\(\text{Accuracy@k} = \frac{1}{|Q|} \sum_{q \in Q} \mathbb{I}(\text{RelevantDoc} \in \text{Top}@k)\)
其中:
- ( \mathbb{I}(\cdot) ) 是指示函数,表示前 ( k ) 个文档中是否存在相关文档。
特点
- 指标值只取决于前 ( k ) 个文档中是否有相关文档,不关注具体排名。
指标的区别和联系
| 指标 | 是否关注排名 | 是否关注相关文档数量 | 是否关注标注覆盖率 | 应用场景 |
|---|---|---|---|---|
| MRR | 是 | 否 | 否 | 用于评估第一个相关文档的位置是否足够靠前,适合对即时性要求较高的任务。 |
| Capped Recall | 否 | 是 | 否 | 用于评估检索系统在受限的文档数量内的召回能力,强调在限定文档数内检索到的相关文档比例。 |
| Hole | 否 | 否 | 是 | 用于评估检索结果中的噪音,即未被标注文档的数量占比,适合分析标注数据的覆盖率和检索输出的可靠性。 |
| Top-k Accuracy | 否 | 是(是否包含至少一个) | 否 | 用于评估前 ( k ) 个文档中是否包含相关文档,适合对结果相关性要求较低但覆盖性要求较高的任务。 |
总结
- 这四个指标从不同维度评估检索系统的性能。
- MRR 强调排名质量。
- Capped Recall 强调召回率,但限定了最大文档数。
- Hole 强调检索噪音和标注覆盖率。
- Top-k Accuracy 强调前 ( k ) 个文档是否包含相关文档。
- 在实际使用中,可以根据任务需求选择合适的指标组合来全面评估系统性能。
总结
代码流程和思想总结
基本思想
- 该代码通过对检索结果(
results)与标注数据(qrels)进行对比,使用多种检索评估指标对系统性能进行定量分析。 - 主要采用 Pytrec_eval 和 自定义指标(如
MRR、Capped Recall、Hole等)来衡量检索任务的多维表现。 - 代码模块化,核心由
search()函数实现检索,_evaluate_split()函数进行性能评估。
代码流程
1. 调用 search() 函数
- 通过
search()函数完成语义检索任务。 - 输入
corpus: 文档集合,格式{doc_id: {"title": ..., "text": ...}}。queries: 查询集合,格式{query_id: query_text}。top_k: 返回的文档数量。
- 过程
- 编码查询 (
encode_queries) 和文档 (encode_corpus)。 - 计算相似度分数(支持余弦相似度或点积)。
- 返回前
top_k个文档及其分数。
- 编码查询 (
- 输出
results,格式为{query_id: {doc_id: score}}。
2. 调用 _evaluate_split() 函数
- 使用 Pytrec_eval 和自定义指标对
results和qrels进行评估。 - 输入
results: 检索结果。qrels: 查询的相关性标注。k_values: 指定的k值列表(如top-1、top-10)。- 评估选项: 是否保存预测结果、忽略查询与文档 ID 相同的情况等。
- 过程
- 通过 Pytrec_eval 计算标准指标(NDCG、MAP、Recall、Precision)。
- 调用自定义指标函数计算 MRR、Capped Recall、Hole 和 Top-k Accuracy。
- 整理并输出所有指标值。
- 输出
- 一个字典,包含每个指标的评估结果(如
{ndcg_at_10: 0.85, mrr_at_10: 0.92})。
- 一个字典,包含每个指标的评估结果(如
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2024/12/06/Coding-mteb/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)