Paper Reading 13 Retrieval-Augmented Generation for AI-Generated Content: A Survey
论文信息
Retrieval-Augmented Generation for AI-Generated Content: A Survey
个人总结
本文是一篇综述,介绍了 RAG 在多个领域的应用,包括文本, Code, 结构性文本(也就是文中提到的 konwledge,包括表格和图结果),图像,视频,音频等。
文中将RAG结构划分为 retrieval 和 generator 两部分,而从RAG 中 retrieval 和 generator 的结合方式,分为了四种 分别是 query RAG ,Latent Representation-Based RAG,
其中 query RAG 是我们最熟悉的RAG 模式,就是根据 qury 检索到一些内容,然后把query 和 检索到的结果一起给 generator 生成最终结果,这是文本的结合
Latent Representation-Based RAG 是实现了 query 和 检索结果 在特征向量层面的结果
Logit-based RAG 这个好像很奇怪,我应该看一下相关论文再来看一下,结合典型代表knn-LM的论文一看就很清楚了,这里的结合是在最终结果输出之前的一部,将参考答案结合生成答案作为最后的输出概率。
Speculative是使用 retrieval 来代替一些 generator的过程
对于不同的 RAG提升方式分为了 input enhancement, retrieval enhancement, generator enhancement, result enhancement 和 pipeline enhancement 。 这种划分方法和之前的另一篇综述*(Paper Reading 8 LLM-IR(Information Retrieval) — 英飞)的划分是大体一致的 ,但是这里没有提到 rerank 的概念。 我也是问了一下 gpt, 回答大概就是 retrieval 一般指 document retrieval 找的相关的内容,而 rerank 而是根据检索到的内容进行精细的排序,增加准确性。
文章的另一个主打点就是 介绍了RAG在各种不同领域的应用,但在不同的领域RAG起到的作用是类似的,
一个主要功能就是搜索相关知识,填充generator 所缺乏的知识空白,也就是 Knowledge Gap Bridging, 这可以理解为从0到1,为generator 提供必不可少的支持。另一个角度看就是 增强结果的全面性,使得结果描述更加丰富,可以理解为从10到100,让回答更加全面。 这两个角度也就是为什么可以RAG可以应用到各种不同的领域,既是必不可缺的,又能提高效果、
还有一个就是 可以提供模板和示例,使得回答更加有组织。除此之外,还能在图像和视频领域,对齐文本和图像提供丰富的多模态信息,
其中在图像领域的应用是很有意思的,因为CLIP之后的图像生成,很多都是需要以来文本提示词来控制图像生成结果,而这些文本图像对也能进行检索,从未为图像生成最终结果提供很多参考。
一个例子如下
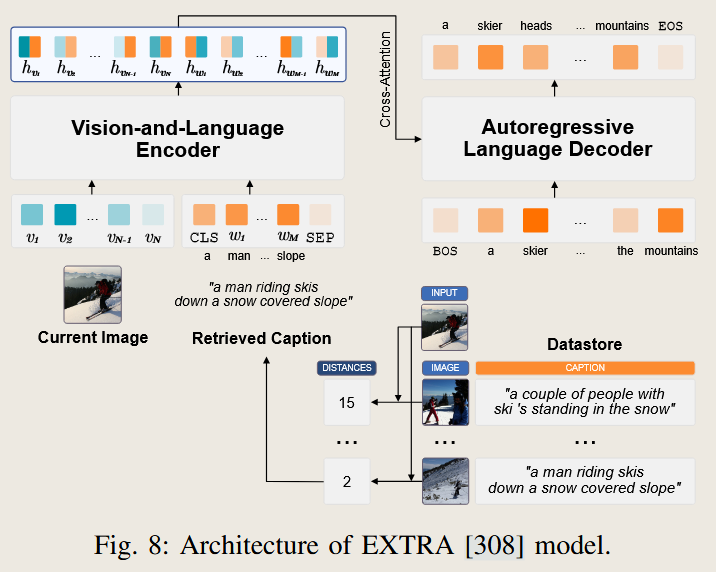
在这里面从数据库中检索的的就是 根据图像的匹配程度检索对应的描述
AI 总结
Analysis of the Survey: “Retrieval-Augmented Generation for AI-Generated Content”
1. Scope or Setting
This survey focuses on Retrieval-Augmented Generation (RAG) techniques, a paradigm that enhances Artificial Intelligence Generated Content (AIGC) by integrating information retrieval processes. The paper systematically categorizes, reviews, and analyzes RAG methodologies and their applications across various AI tasks and modalities such as text, code, image, video, audio, 3D, and biomedical informatics.
2. Key Idea
The core idea of RAG is to augment generative models with retrieved, relevant external data. By introducing a retrieval component, RAG addresses limitations in AIGC such as:
- Outdated or insufficient training data.
- Inability to handle long-tail data.
- Risks of training data leakage.
- High computational costs of training and inference.
3. Methodology
The survey organizes RAG techniques into foundational paradigms based on how retrieval interacts with generation:
- Query-Based RAG: Integrates retrieved content into the input query for the generator.
- Latent Representation-Based RAG: Incorporates retrieved objects as latent representations in the model.
- Logit-Based RAG: Combines retrieval results with generative logits at the decoding stage.
- Speculative RAG: Utilizes retrieval to replace certain generation steps for efficiency.
Enhancement techniques span the retrieval process, generator design, and the entire pipeline. Notable methods include:
- Recursive and hybrid retrieval.
- Prompt engineering.
- Adaptive and iterative RAG pipelines.
4. Contributions
The survey provides:
- A comprehensive categorization of RAG paradigms and techniques.
- A detailed review of applications across diverse modalities and tasks.
- Benchmarks for evaluating RAG systems.
- A discussion of RAG’s limitations and potential directions for future research.
5. Difference and Innovation
Compared to prior works that narrowly focus on specific RAG techniques or text-based applications:
- This survey extends to diverse modalities, including image, video, and audio generation.
- It emphasizes the flexibility of RAG in handling long-tail and real-time knowledge, setting the stage for adaptive and scalable systems.
- The study bridges gaps by exploring foundational augmentation methods and enhancements that are often overlooked.
6. Results and Conclusion
- Effectiveness: RAG improves performance in various applications, from QA systems to creative content generation.
- Challenges: Noises in retrieval, system complexity, and overhead costs limit practicality.
- Future Directions: Highlighted areas include flexible RAG pipelines, domain-specific adaptations, and integration with other advanced AI techniques.
7. Contrast with Other Methods
- RAG provides modularity and scalability, addressing data gaps that purely generative models cannot.
- Unlike standalone retrieval or generative methods, RAG combines their strengths for enhanced performance.
8. Discussion
The paper highlights:
- Trade-offs in retrieval precision vs. noise robustness.
- The potential of RAG in real-time, low-latency applications.
- Open research questions about aligning retrieval and generation processes for optimal results.
9. Proofs
The authors provide benchmarks and examples across various modalities to substantiate RAG’s utility:
- Case studies in domains like text summarization, code repair, and 3D asset generation demonstrate RAG’s adaptability.
- Evaluations emphasize metrics such as retrieval accuracy, contextual relevance, and generation quality.
Would you like further breakdowns of specific sections or applications from the survey?
文中主要图表以及AI 问题回答

Why RAG Divide into Retrieval and Generation
The authors categorize the RAG (Retrieval-Augmented Generation) structure into two core modules: retrieval and generation, forming the foundation of the RAG process. This division reflects the fundamental workflow and dependencies of RAG systems:
1. Why Divide into Retrieval and Generation?
- Modular Design:
- Retrieval and generation serve distinct purposes, making this division natural and logical.
- Retrieval focuses on identifying and supplying relevant information from external data sources.
- Generation uses this retrieved data to produce coherent and contextually accurate outputs.
- Task Specialization:
- Retrievers excel at finding relevant objects from large-scale repositories, typically leveraging techniques like sparse retrieval (e.g., BM25) or dense retrieval (e.g., ANN-based methods).
- Generators specialize in synthesizing the retrieved knowledge into meaningful content, using models such as transformers, LSTMs, or diffusion models.
- Alignment with Workflow:
- RAG’s entire pipeline revolves around the interaction between these two components:
- Retrieval: Extract relevant data based on input queries.
- Generation: Incorporate the retrieved data to create responses.
- RAG’s entire pipeline revolves around the interaction between these two components:
- General Applicability:
- This two-part structure allows flexibility and adaptability across various modalities (e.g., text, images, audio) while maintaining a unified framework.
2. How Are Retrieval and Generation Characterized?
- Retrieval:
- Focuses on locating external knowledge through specific similarity functions or indices.
- Categorized into methods like sparse, dense, or specialized retrieval (e.g., using knowledge graphs or NER-based techniques).
- Generation:
- Converts retrieved knowledge into desired outputs using generative models.
- Adaptable to task requirements, whether text-to-text, text-to-image, or other modalities.
3. Rationale for Not Adding More Modules
The two-part division aligns with the RAG process’s core objective: to combine external knowledge retrieval with content generation. While there are additional steps, such as preprocessing, enhancement, and postprocessing, these are seen as enhancements rather than core functionalities, and thus they do not define separate modules.
This simplicity also ensures that RAG systems are modular, scalable, and interpretable across diverse applications and domains.
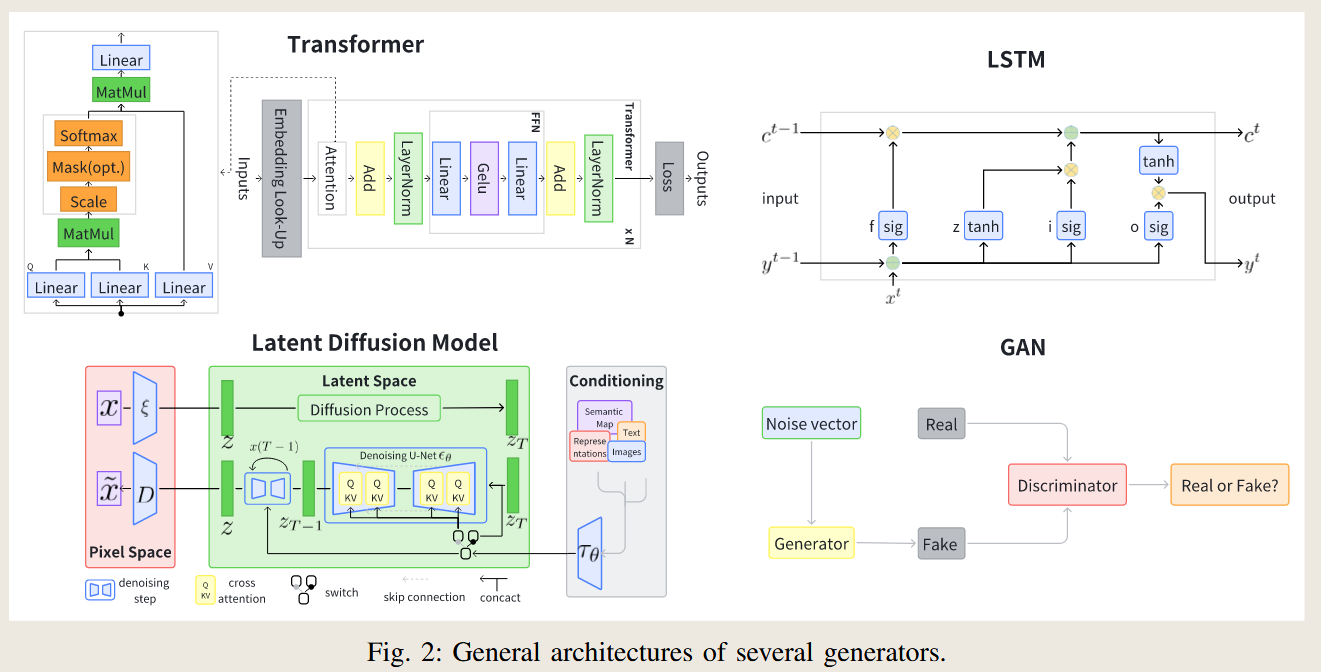
Summary of Different Generators in RAG Systems
1. Transformer Models
- Main Idea: Utilize self-attention mechanisms to process sequences, excelling in text-to-text tasks and other sequence-to-sequence applications.
- Pros:
- Strong performance in natural language processing (NLP) tasks.
- Scalable to long sequences with efficient attention mechanisms.
- Pretrained transformer models like BERT and GPT offer robust capabilities.
- Cons:
- Limited context length.
- High computational cost.
- Applications:
- Question answering, summarization, human-machine conversation, and code generation.
2. Long Short-Term Memory (LSTM)
- Main Idea: Employ a form of Recurrent Neural Network (RNN) that uses cell states and gating mechanisms to process sequences while preserving long-term dependencies.
- Pros:
- Effective for smaller datasets and tasks requiring long-term memory.
- Handles vanishing and exploding gradients better than standard RNNs.
- Cons:
- Struggles with very long sequences compared to transformers.
- Less efficient due to sequential computation.
- Applications:
- Text summarization, audio captioning, and sequential data tasks.
3. Diffusion Models
- Main Idea: Gradually add noise to data and then reverse the process to generate new data, often guided by probabilistic models and neural networks.
- Pros:
- Capable of generating high-quality, diverse outputs, including images, audio, and 3D assets.
- Effective in handling multimodal tasks.
- Cons:
- High computational requirements.
- Training and inference are slow compared to GANs or transformers.
- Applications:
- Text-to-image generation, molecular generation, 3D motion synthesis, and audio generation.
4. Generative Adversarial Networks (GANs)
- Main Idea: Use a two-part system—a generator and a discriminator—that competes during training to produce realistic outputs.
- Pros:
- Excellent for generating realistic images, videos, and audio.
- Fast inference once trained.
- Cons:
- Difficult to train due to instability and mode collapse.
- Limited in flexibility compared to diffusion models.
- Applications:
- Image synthesis, image-to-image translation, and video generation.
Comparative Analysis
| Generator Type | Strengths | Weaknesses | Key Applications |
|---|---|---|---|
| Transformer Models | Robust for NLP tasks, scalable, pretrained availability | High cost, limited context length | QA, summarization, code generation |
| LSTM | Effective for smaller datasets, long-term memory | Inefficient with very long sequences | Audio captioning, sequence generation |
| Diffusion Models | High-quality, multimodal generation | Slow, computationally expensive | Text-to-image, audio, 3D generation |
| GANs | Realistic outputs, fast inference | Training instability, less flexibility | Image and video synthesis |
These generators provide flexibility to RAG systems, allowing for application-specific optimization across diverse tasks and modalities.

Taxonomy of RAG Foundations
1. Query-Based RAG
- Main Idea: Retrieve relevant information and directly append it to the input query for the generator.
- Pros:
- Modular and easy to integrate with pre-trained models (e.g., GPT).
- Effective across various modalities and tasks.
- No additional training required for many setups.
- Cons:
- Lengthens the input query, leading to higher memory and computational costs.
- Can degrade performance if irrelevant or noisy data is retrieved.
- Representative Methods:
- REALM, DPR+BART, REPLUG, IC-GAN.
- Applications:
- Text summarization, question answering, image captioning, code generation, and text-to-3D generation.
2. Latent Representation-Based RAG
- Main Idea: Integrate retrieved objects as latent representations within the generator’s layers.
- Pros:
- Combines retrieval and generation at a deeper level for better alignment.
- Supports sophisticated augmentation strategies (e.g., chunked cross-attention).
- Effective in long-context scenarios.
- Cons:
- Requires additional training for aligning latent spaces of retrievers and generators.
- More complex to implement than query-based RAG.
- Representative Methods:
- FiD, RETRO, ReMoDiffuse.
- Applications:
- Open-domain QA, knowledge graph QA, 3D motion generation, and video captioning.
3. Logit-Based RAG
- Main Idea: Incorporate retrieval results at the logit level during the generation process, influencing token probabilities directly.
- Pros:
- Fine-grained control over the generation process.
- Improves performance in long-tail and domain-specific tasks.
- Cons:
- Limited applicability to sequence-based tasks.
- Complex integration with pre-trained models.
- Representative Methods:
- kNN-LM, TRIME, kNN-Diffusion.
- Applications:
- Long-tail QA, code summarization, image captioning.
4. Speculative RAG
- Main Idea: Replace parts of the generation process with retrieval to save computational costs and reduce latency.
- Pros:
- Faster inference compared to purely generative approaches.
- Resource-efficient, especially for large-scale applications.
- Cons:
- Retrieval quality directly impacts the final results.
- May struggle with tasks requiring deep reasoning or creative outputs.
- Representative Methods:
- REST, GPTCache, COG.
- Applications:
- Real-time dialogue systems, low-latency QA, API-based code generation.
Comparative Summary
| RAG Foundation | Strengths | Weaknesses | Representative Methods | Applications |
|---|---|---|---|---|
| Query-Based | Easy integration, effective across modalities | Computationally expensive with long queries | REALM, DPR+BART, IC-GAN | QA, summarization, image captioning, code gen |
| Latent Representation-Based | Deeper integration, robust for long-context tasks | Requires retriever-generator alignment, complex setup | FiD, RETRO, ReMoDiffuse | Open-domain QA, motion generation, video tasks |
| Logit-Based | Fine-grained generation control | Limited to sequence tasks, complex integration | kNN-LM, TRIME | Code generation, captioning, domain QA |
| Speculative | Low latency, resource-efficient | Heavily dependent on retrieval quality | REST, GPTCache, COG | Real-time QA, low-latency applications |
This taxonomy reflects RAG’s versatility and highlights how different foundations are tailored to specific tasks and challenges in AI-generated content.
Logit-Based RAG: Overview, Concept, Representative Methods, and Distinction
1. What Does Logit-Based RAG Represent?
Logit-based RAG integrates retrieval into the generation process at the logit level, where logits represent the unnormalized probabilities for each token or output in a generative model. Instead of directly influencing the input or intermediate latent representations, this approach modifies or combines the logits of the generator with those derived from retrieval results.
2. Basic Idea of Logit-Based RAG
- Core Concept:
- During generation, retrieved information is integrated into the model by modifying or combining the logits of the generator at each decoding step.
- This approach provides fine-grained control over the generative process by influencing token probabilities directly.
- How It Works:
- Retrieve relevant data (e.g., text snippets or code examples) based on the input query.
- Compute logits from the retrieved data (e.g., similarity scores, token probabilities from a language model).
- Combine these logits with the generator’s logits, using methods like weighted summation or confidence-based merging.
- Generate the final output based on the adjusted logits.
- Advantages:
- Directly impacts the generation probabilities, improving alignment with retrieved knowledge.
- Well-suited for sequence-based tasks, especially those requiring step-by-step generation.
3. Representative Methods
3.1 kNN-LM
- Overview:
- Uses a nearest neighbor search to retrieve tokens from an external datastore and combines their logits with those from the generator.
- How It Works:
- A key-value datastore is built from the training corpus, where each token and its context are stored.
- During generation, the model retrieves the nearest neighbors for the current context and computes logits based on their similarity scores.
- Combines these logits with the generator’s logits to guide the next token prediction.
- Applications:
- Text generation, especially in scenarios requiring long-tail knowledge or rare token prediction.
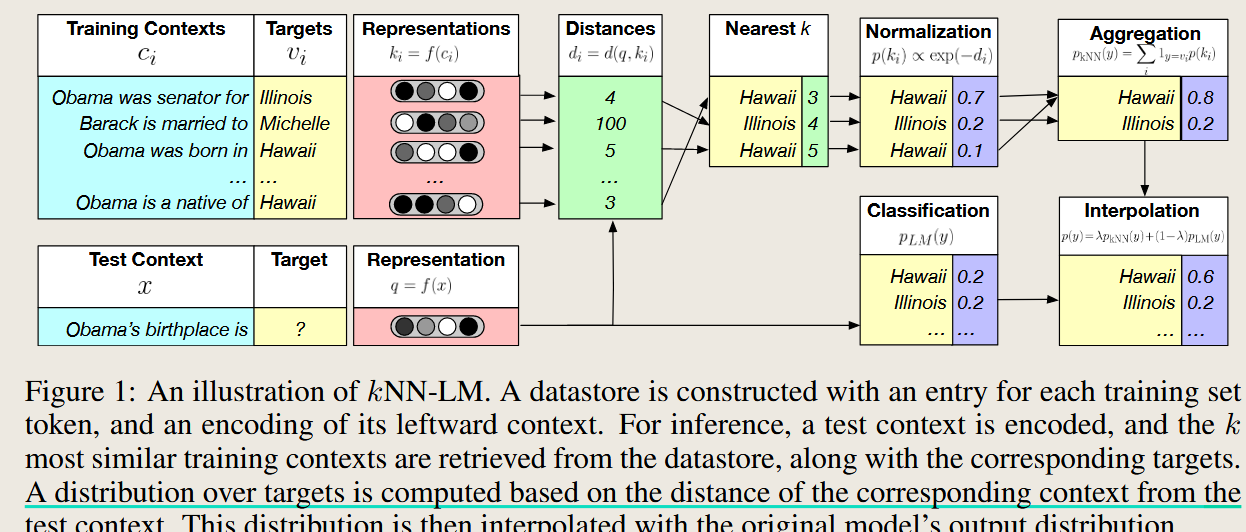
3.2 TRIME
- Overview:
- Enhances kNN-LM by jointly training the retrieval system and the generator for improved synergy.
- How It Works:
- Retrieval results are used to dynamically adjust the logits during training, ensuring alignment between the retrieval and generation components.
- Applications:
- Long-tail QA and sequence generation tasks requiring rare or unseen contexts.
3.3 EDITSUM
- Overview:
- Applies logit-level integration in code summarization by combining logits from retrieved summaries with those generated by the model.
- How It Works:
- Retrieved code-summary pairs contribute logits that are combined with the generative logits, improving alignment with existing examples.
- Applications:
- Code summarization and domain-specific text generation.
4. Differences Between Logit-Based RAG and Other RAG Types
| Aspect | Logit-Based RAG | Query-Based RAG | Latent Representation-Based RAG | Speculative RAG |
|---|---|---|---|---|
| Integration Stage | Logit level (generation step) | Input stage (before generation) | Latent space (intermediate model states) | Replaces parts of generation with retrieval |
| Focus | Fine-grained control over token probabilities | Augments the model’s input | Enhances comprehension in latent space | Improves efficiency and speed |
| Use Case | Rare token prediction, sequence-based tasks | Open-domain QA, summarization | Long-context tasks, cross-modal generation | Low-latency applications |
| Complexity | Requires retrieval-logit integration | Simpler, relies on input augmentation | Demands alignment in latent space | Requires minimal generator modifications |
| Representative Methods | kNN-LM, TRIME, EDITSUM | REALM, DPR+BART, IC-GAN | FiD, RETRO, ReMoDiffuse | REST, GPTCache |
5. Key Takeaways
- Core Innovation: Logit-based RAG directly adjusts the generative process by modifying token probabilities, offering granular control over the output.
- Strengths: Effective for tasks requiring rare token prediction or long-tail distribution handling.
- Challenges: Logit integration can be computationally intensive and requires careful design to balance retrieval and generation probabilities.
- Comparison: Unlike query-based or latent representation-based RAG, logit-based methods operate at the decoding stage, allowing real-time influence on token selection. This makes it uniquely suited for sequence-driven applications.
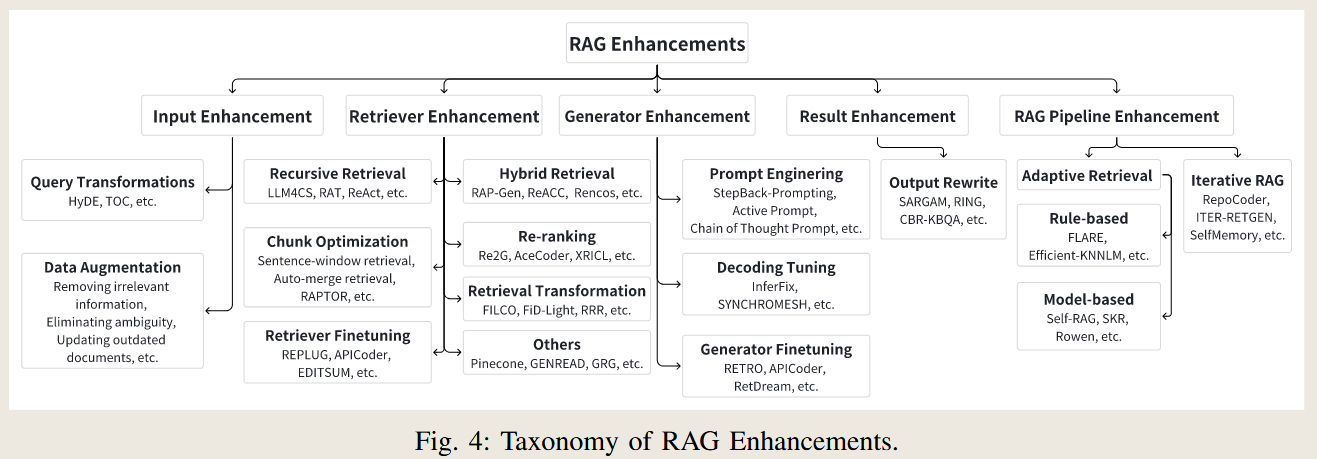
Taxonomy of RAG Enhancements
RAG enhancements improve the effectiveness and efficiency of the retrieval-augmented generation pipeline. They target specific components or the entire system.
1. Input Enhancement
Main Idea: Enhance the query or data before retrieval to improve the quality of retrieved results.
Techniques:
Query Transformation:
Modify the input query for better retrieval accuracy.
- Example Methods:
- Query2Doc: Generate pseudo-documents from the query for richer retrieval contexts.
- HyDE: Generate hypothetical documents to improve retrieval quality.
- Example Methods:
Data Augmentation:
Enhance retrieval data by synthesizing, updating, or filtering content.
- Example Methods:
- LESS: Optimize dataset selection for targeted tasks.
- Make-An-Audio: Captioning and augmenting audio data to address sparsity.
- Example Methods:
2. Retriever Enhancement
Main Idea: Improve the retrieval process for better accuracy, efficiency, and relevance of the results.
Techniques:
Recursive Retrieval:
Perform iterative searches to refine results.
- Example Methods:
- ReACT: Break down queries using chain-of-thought reasoning for deeper retrieval.
- Example Methods:
Hybrid Retrieval:
Combine multiple retrieval methods (e.g., sparse and dense).
- Example Methods:
- BlendedRAG: Combines semantic and lexical retrieval techniques.
- Example Methods:
Re-ranking:
Reorder retrieved results to prioritize relevance.
- Example Methods:
- Re2G: Apply a re-ranker model after initial retrieval.
- Example Methods:
Retriever Fine-tuning:
Adapt retrievers to specific domains.
- Example Methods:
- ReACC: Fine-tune retrievers for code completion.
- Example Methods:
3. Generator Enhancement
Main Idea: Improve the generation process by optimizing model inputs, decoding strategies, or model training.
Techniques:
Prompt Engineering:
Refine prompts to guide the generator effectively.
- Example Methods:
- Chain-of-Thought Prompting: Add reasoning steps to enhance logical outputs.
- LLMLingua: Compress prompts to accelerate inference.
- Example Methods:
Decoding Tuning:
Adjust decoding parameters (e.g., temperature) for quality and diversity.
- Example Methods:
- InferFix: Balance result quality and diversity using temperature adjustments.
- Example Methods:
Generator Fine-tuning:
Train generators with domain-specific data for improved relevance.
- Example Methods:
- RETRO: Train a generator using chunked cross-attention for integrating retrieval.
- Example Methods:
4. Result Enhancement
Main Idea: Refine or post-process the generated output for better accuracy or alignment with task requirements.
Techniques:
Output Rewrite:
Modify generated outputs to meet specific requirements.
- Example Methods:
- SARGAM: Use classifiers for better alignment with real-world code contexts.
- Example Methods:
Error Correction: Adjust the output to address inconsistencies or hallucinations.
5. RAG Pipeline Enhancement
Main Idea: Optimize the overall interaction between retrievers and generators for better efficiency and results.
Techniques:
Adaptive Retrieval:
Dynamically decide whether retrieval is necessary.
- Example Methods:
- Self-RAG: Use a model to determine if retrieval is required.
- Example Methods:
Iterative RAG:
Refine results through repeated retrieval and generation cycles.
- Example Methods:
- RepoCoder: Iteratively improve code completion by updating retrieval inputs.
- Example Methods:
Pipeline Customization:
Design task-specific workflows for RAG.
- Example Methods:
- FLARE: Decide the timing and need for retrieval during generation.
- Example Methods:
Comparative Summary
| Enhancement | Purpose | Representative Methods |
|---|---|---|
| Input Enhancement | Improve input queries or data for better retrieval | Query2Doc, HyDE, LESS |
| Retriever Enhancement | Optimize retrieval processes and relevance | ReACT, BlendedRAG, Re2G, ReACC |
| Generator Enhancement | Refine generation through prompts or tuning | Chain-of-Thought, RETRO, InferFix |
| Result Enhancement | Post-process outputs for accuracy | SARGAM, Output Rewrite |
| Pipeline Enhancement | Enhance RAG workflow for efficiency | Self-RAG, RepoCoder, FLARE |
These enhancements provide modular improvements to RAG systems, enabling tailored optimizations for various tasks and domains.
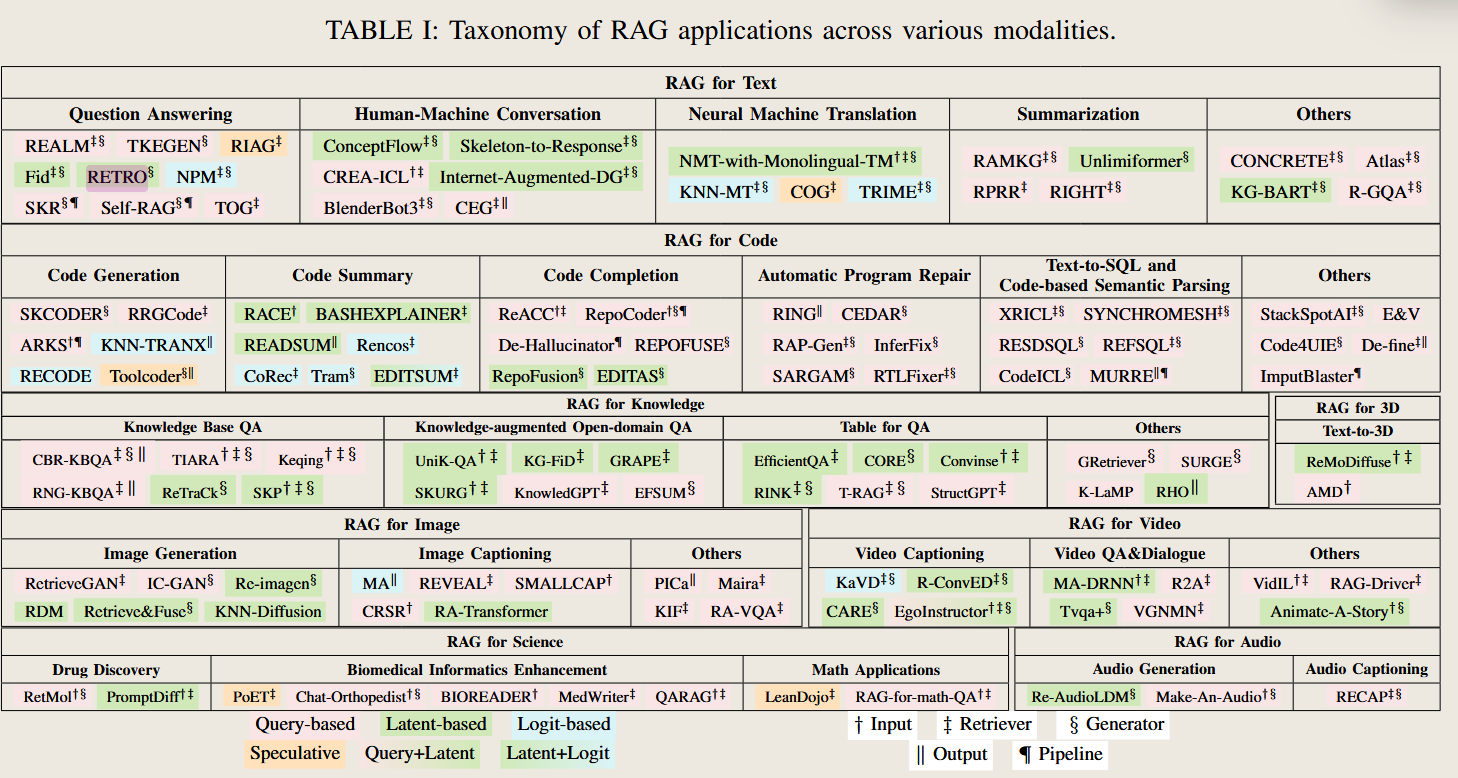
RAG for Text 的应用场景有哪些,区别是什么
Comprehensive Analysis of the Seven Scenarios in RAG for Text
The seven scenarios in RAG for Text include 1. Question Answering (QA), 2. Fact Verification, 3. Commonsense Reasoning, 4. Human-Machine Conversation, 5. Event Extraction, 6. Neural Machine Translation (NMT), and 7. Summarization. While all scenarios share the goal of integrating retrieval with generation, their specific objectives, challenges, and requirements differ.
1. Question Answering (QA)
- Task Objective: Provide precise answers to user queries by leveraging external knowledge.
- Problem Addressed:
- Locating the most relevant information in large document collections.
- Synthesizing multiple pieces of evidence for complex questions.
- Core Characteristics: Requires direct integration of retrieved content into input queries for the generator.
- Unique Challenge: The retrieval stage must ensure high recall to provide all necessary information.
- Representative Methods: REALM, FiD.

2. Fact Verification
- Task Objective: Determine the truthfulness of a claim by comparing it with retrieved evidence.
- Problem Addressed:
- Matching retrieved information with the claim for semantic consistency.
- Detecting inaccuracies or contradictions.
- Core Characteristics: Involves evidence-based verification rather than direct answer generation.
- Unique Challenge: High precision in retrieval is essential to ensure factual correctness.
- Representative Methods: CONCRETE, Atlas.
3. Commonsense Reasoning
- Task Objective: Answer complex, open-ended questions using commonsense knowledge and reasoning.
- Problem Addressed:
- Inferring implicit relationships and causal connections.
- Integrating external commonsense knowledge with the model’s internal understanding.
- Core Characteristics: Retrieval supplements generative reasoning rather than directly forming the output.
- Unique Challenge: Retrieved information may lack direct relevance, requiring more sophisticated reasoning.
- Representative Methods: KG-BART.
4. Human-Machine Conversation
- Task Objective: Generate meaningful, contextually grounded responses in dialogue systems.
- Problem Addressed:
- Producing engaging, factually grounded, and context-aware responses.
- Addressing hallucinations by grounding generation in retrieved knowledge.
- Core Characteristics: Retrieval integrates conversational history and external knowledge to enhance response quality.
- Unique Challenge: Balancing coherence, engagement, and factual accuracy in real-time dialogues.
- Representative Methods: BlenderBot3, ConceptFlow.
5. Event Extraction
- Task Objective: Identify structured information about events (e.g., participants, locations) from textual data.
- Problem Addressed:
- Extracting event-related details accurately and comprehensively.
- Linking extracted information to external knowledge for validation and enrichment.
- Core Characteristics: Retrieval enhances extraction by providing context and supplementary details.
- Unique Challenge: Integrating retrieved information into structured output formats like timelines or databases.
- Representative Methods: R-GQA.
6. Neural Machine Translation (NMT)
- Task Objective: Translate text between languages with high accuracy and contextual consistency.
- Problem Addressed:
- Addressing ambiguities in translation through retrieval of similar sentence structures.
- Improving translation quality for low-resource languages.
- Core Characteristics: Retrieved examples provide context or serve as templates for translation.
- Unique Challenge: Ensuring retrieved data aligns linguistically and semantically with the input text.
- Representative Methods: TRIME, kNN-MT.
7. Summarization
- Task Objective: Create concise and coherent summaries from lengthy documents.
- Problem Addressed:
- Overcoming input length constraints of transformers by retrieving relevant document segments.
- Improving the quality of abstractive summaries with additional context.
- Core Characteristics: Retrieval narrows focus to key portions of the input, enhancing the generation process.
- Unique Challenge: Ensuring coherence and relevance while maintaining a concise output.
- Representative Methods: RIGHT, Unlimiformer.
Comparative Analysis
| Scenario | Task Objective | Problem Solved | Unique Challenge | Representative Methods |
|---|---|---|---|---|
| 1. QA | Provide direct answers | Retrieve relevant and sufficient evidence | High recall in retrieval | REALM, FiD |
| 2. Fact Verification | Verify claim truthfulness | Semantic consistency and factual correctness | High precision in retrieval | CONCRETE, Atlas |
| 3. Commonsense Reasoning | Infer relationships using commonsense | Supplement reasoning with background knowledge | Handling implicit knowledge gaps | KG-BART |
| 4. Human-Machine Conversation | Generate context-aware dialogue | Improve engagement and factual accuracy | Balancing coherence and engagement | BlenderBot3, ConceptFlow |
| 5. Event Extraction | Extract structured event information | Enrich and validate extracted events | Formatting retrieved content as structured data | R-GQA |
| 6. NMT | Translate text between languages | Address ambiguity and improve low-resource languages | Aligning retrieved data with input text | TRIME, kNN-MT |
| 7. Summarization | Generate concise summaries | Address input length limitations | Maintaining coherence and conciseness | RIGHT, Unlimiformer |
Key Similarities:
- Integration of Retrieval and Generation: All scenarios rely on external retrieval to enhance the generative process.
- Focus on Accuracy and Context: Whether generating answers, verifying facts, or translating text, ensuring contextual relevance is central.
- Addressing Knowledge Gaps: Retrieval helps fill gaps in model training data or internal knowledge.
Key Differences:
- Output Type:
- QA and Fact Verification focus on specific answers or evaluations.
- Commonsense Reasoning and Human-Machine Conversation require more nuanced and open-ended outputs.
- Event Extraction emphasizes structured outputs, while Summarization condenses information.
- NMT involves transforming text into another language.
- Role of Retrieval:
- In QA and Fact Verification, retrieved content directly informs the generation.
- In Commonsense Reasoning, retrieved knowledge complements reasoning.
- In Summarization, retrieval narrows focus to the most relevant document portions.
- Reasoning Complexity:
- Commonsense Reasoning and Human-Machine Conversation require advanced reasoning and contextual understanding.
- QA and Fact Verification involve more direct information alignment and validation.
Conclusion:
The seven scenarios illustrate the flexibility and broad applicability of RAG. By adapting retrieval and generation to the specific needs of each task, RAG systems can address diverse challenges, from reasoning and validation to language translation and summarization.
RAG for code
RAG for Code: Scenario-by-Scenario Summary
1. Code Generation
- Objective: Convert natural language (NL) descriptions into executable code.
- Problem Addressed:
- Generating syntactically correct and functionally accurate code.
- Handling unseen APIs or complex requirements.
- Representative Methods:
- DocPrompting: Retrieves API documentation or relevant code snippets to construct prompts for code generation. This enhances the model’s ability to generate accurate and API-compliant code.
- SKCODER: Retrieves similar code snippets to provide a “sketch” template for generating the final code. This approach reduces ambiguity and improves accuracy.
- How It Works: Retrieved data supplements NL inputs to provide context or templates, guiding the generation process.
2. Code Summarization
Objective: Generate concise and human-readable descriptions of code functionality.
Problem Addressed:
- Bridging the gap between complex technical code and human understanding.
- Summarizing verbose or unfamiliar code effectively.
Representative Methods:
- EditSum: Retrieves similar code and corresponding summaries, encoding them along with the input code to guide summarization.
- Re2Com: Leverages examples of similar code-comment pairs and uses an attention mechanism to refine generated comments.

How It Works: Retrieved examples act as guiding references, enabling the model to produce summaries that align with known patterns and improve interpretability.
3. Code Completion
- Objective: Predict and complete partially written code snippets.
- Problem Addressed:
- Generating context-aware completions, especially in large codebases with in-file and cross-file dependencies.
- Handling multi-step completion for complex projects.
- Representative Methods:
- ReACC: Uses both sparse and dense retrieval to retrieve similar functions or projects, providing additional context for code prediction.
- RepoCoder: Implements an iterative refinement approach where previously generated code is used for subsequent retrieval and completion.
- How It Works: The model retrieves relevant functions or snippets to complete partial code accurately, considering both local and global project contexts.
4. Automatic Program Repair
- Objective: Identify and fix bugs in code automatically.
- Problem Addressed:
- Locating errors in code and generating targeted, accurate fixes.
- Resolving issues in a time-efficient and scalable manner.
- Representative Methods:
- InferFix: Retrieves similar bug patterns and fixes to construct prompts, then refines the generated patch through iterative feedback.
- RAP-Gen: Uses retrieval of buggy code-fix pairs to guide the generation of patches, ensuring that fixes are grounded in real-world examples.
- How It Works: Retrieved examples of bugs and fixes help the model understand error patterns and generate corrections that align with common practices.
5. Text-to-SQL and Semantic Parsing
- Objective: Translate NL queries into structured queries or domain-specific languages like SQL.
- Problem Addressed:
- Aligning NL descriptions with database schemas and structures.
- Generating syntactically correct and semantically relevant SQL queries.
- Representative Methods:
- SYNCHROMESH: Retrieves NL-SQL pairs to guide generation and enforces constraints during decoding to ensure the generated query aligns with schema requirements.
- XRICL: Retrieves multilingual NL-SQL examples, enabling the generation of SQL queries that work across languages and domains.
- How It Works: Retrieval provides schema-aligned examples, helping the model handle out-of-domain queries and complex table relationships effectively.
6. Other Applications
- Objective: Address domain-specific tasks such as static analysis, semantic extraction, or improving software quality.
- Problem Addressed:
- Analyzing and enhancing code quality through semantic understanding and execution simulations.
- Representative Methods:
- E&V (Execution and Verification): Uses retrieved pseudo-code and execution specifications to verify program correctness during static analysis.
- Code4UIE: Leverages code snippets for information extraction tasks, ensuring accurate and domain-specific outputs.
- How It Works: Retrieval aids in augmenting domain-specific models with examples or simulations, enabling robust analysis and interpretation of code.
Key Takeaways
- Scenario-Specific Retrieval: RAG adapts retrieval techniques to suit the requirements of each scenario, whether generating, summarizing, completing, or repairing code.
- Leveraging Existing Data: Retrieved examples, templates, or documentation improve model performance by grounding outputs in real-world patterns and contexts.
- Iterative Refinement: For tasks like code completion or program repair, iterative retrieval-generation cycles enhance accuracy and adaptability.
- Domain Specialization: In semantic parsing and static analysis, retrieval supports domain-specific challenges by aligning with schema or execution logic.
This scenario-wise breakdown highlights how RAG transforms code-related tasks by combining retrieval and generation to address unique challenges effectively.
RAG for knowledge (structured data)
Differences Between RAG for Knowledge and RAG for Text
| Aspect | RAG for Knowledge | RAG for Text |
|---|---|---|
| Input Data | Structured knowledge (e.g., graphs, tables, schemas) | Unstructured text documents or sequences |
| Task Focus | Semantic reasoning, entity-linking, schema alignment | Contextual understanding, text generation |
| Challenges | Navigating structured data formats | Handling large-scale unstructured datasets |
| Output Requirements | Often structured (e.g., SPARQL, SQL queries) | Typically unstructured or textual responses |
| Applications | Knowledge graphs, databases, and table queries | QA, reasoning, translation, summarization |
RAG for Knowledge: Scenario-by-Scenario Summary
1. Knowledge Base Question Answering (KBQA)
- Objective:
- Answer questions using structured knowledge bases (e.g., knowledge graphs) by generating queries like SPARQL.
- Problem Addressed:
- Aligning NL queries with structured knowledge (e.g., entities, relations).
- Multi-hop reasoning across graph nodes to handle complex questions.
- Representative Methods:
- Uni-Parser:
- Retrieves relevant entities, relations, and database tables.
- How It Works: Decomposes complex questions into multi-hop paths and feeds structured knowledge into the generator, enabling precise SPARQL query generation.
- CBR-KBQA:
- Leverages case-based reasoning by retrieving examples of (query, logical form) pairs.
- How It Works: Aligns the retrieved logical forms with input queries to ensure accuracy in SPARQL generation.
- Uni-Parser:
2. Knowledge-Augmented Open-Domain QA
Objective:
- Answer open-ended questions by supplementing unstructured text with structured knowledge sources like triplets or tables.
Problem Addressed:
- Integrating structured knowledge into text-based QA.
- Performing multi-hop reasoning with both structured and unstructured data.
Representative Methods:
- UniK-QA:
- Uses fusion-in-decoder to incorporate triplet-based documents into the QA process.
- How It Works: Retrieves relevant triplets from knowledge graphs and fuses them with text inputs to improve generation accuracy.
- GRAPE:
- Constructs a bipartite graph of questions and passages.
- How It Works: Performs graph traversal for multi-hop reasoning and integrates retrieved evidence into QA responses.
- KG-FID
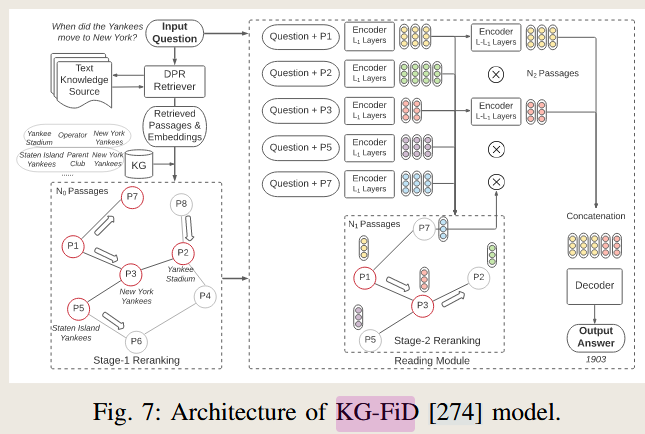
- UniK-QA:
3. Table Question Answering
- Objective:
- Answer questions based on structured tabular data, often requiring numerical reasoning or data aggregation.
- Problem Addressed:
- Mapping NL queries to tabular structures (e.g., rows, columns).
- Performing calculations or reasoning over retrieved tabular data.
- Representative Methods:
- OmniTab:
- Retrieves relevant table rows or sections and integrates them with NL queries.
- How It Works: Concatenates retrieved tabular segments with the input query, ensuring alignment between structured data and generation.
- RINK:
- Uses a re-ranking mechanism to prioritize relevant table segments.
- How It Works: Improves the precision of retrieval by scoring table segments for relevance, enabling more accurate table-based reasoning.
- OmniTab:
4. Other Applications
4.1 Knowledge Graph Completion
- Objective:
- Enrich existing knowledge graphs by predicting missing entities or relations.
- Representative Methods:
- ReSKGC:
- Retrieves relevant triplets from the graph and generates new entities or relations.
- How It Works: Uses a fusion-in-decoder mechanism to integrate retrieved graph segments into the output generation.
- ReSKGC:
4.2 Query Generation
- Objective:
- Generate structured queries (e.g., SQL or SPARQL) from NL inputs.
- Representative Methods:
- StructGPT:
- Retrieves from multiple structured sources (e.g., knowledge graphs, tables) to create unified queries.
- How It Works: Combines heterogeneous data formats into structured outputs, like SQL or SPARQL, for diverse reasoning tasks.
- StructGPT:
4.3 Multi-hop Question Answering
- Objective:
- Handle multi-hop questions requiring reasoning across structured and unstructured sources.
- Representative Methods:
- Retrieve-Rewrite-Answer:
- Retrieves subgraphs and rewrites them into NL to improve reasoning.
- How It Works: Bridges structured knowledge with NL queries, improving interpretability and accuracy.
- Retrieve-Rewrite-Answer:
Conclusion
By tailoring RAG techniques to structured knowledge, each scenario addresses unique challenges like entity alignment, schema understanding, and multi-hop reasoning. Representative methods like Uni-Parser (KBQA), GRAPE (Open-Domain QA), and OmniTab (Table QA) demonstrate how RAG enables accurate, structured knowledge integration to enhance generative tasks across domains.
RAG in Image Scenarios: Applications, Core Focus, Challenges, and Implementation
Retrieval-Augmented Generation (RAG) in image-related tasks enhances generative and reasoning capabilities by integrating external knowledge or examples through retrieval. It addresses challenges like contextual grounding, diversity, and factual correctness across various scenarios.
1. Image Generation
- Core Focus:
- Generate high-quality and contextually relevant images guided by text or other visual inputs.
- Problems Solved:
- Relevance and Diversity: Improves the quality of generated images, especially for rare or complex subjects.
- Efficiency: Reduces the size of generative models by leveraging external image resources.
- RAG Usage:
- Retrieves image patches, embeddings, or multimodal pairs based on text prompts or partial image representations.
- Conditions the generation process on retrieved examples to align outputs with input contexts.
- Representative Methods:
- RetrieveGAN: Retrieves image patches from a database to guide GAN-based generation, ensuring precise and visually relevant outputs.
- KNN-Diffusion: Retrieves similar images or embeddings to condition diffusion models, enabling zero-shot image stylization and diverse outputs.
- Example Task:
- Generate an image of “a futuristic cat sitting on a sofa” by retrieving related image patches or embeddings to enhance visual accuracy.
2. Image Captioning
Core Focus:
- Generate accurate and descriptive captions for input images.
Problems Solved:
- Contextual Accuracy: Reduces hallucinations by grounding captions in retrieved real-world examples.
- Descriptive Richness: Provides external knowledge to improve the detail and precision of captions.
RAG Usage:
- Retrieves visually similar images or captions from caption-image databases.
- Incorporates retrieved data as prompts or embeddings to enrich the caption generation process.
Representative Methods:
- SMALLCAP: Retrieves relevant captions as in-context examples, enabling the model to generate richer and more aligned descriptions.
- REVEAL: Combines retrieved multimodal knowledge (text-image pairs) to enhance caption grounding and factual accuracy.
- EXTRA
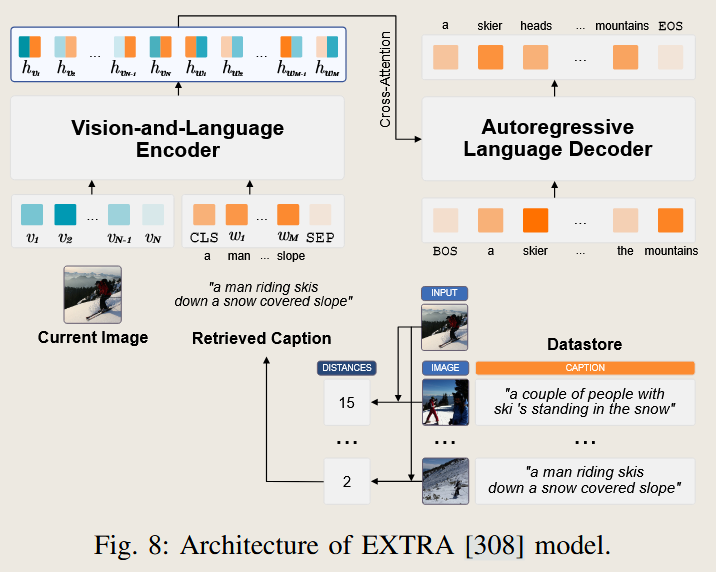
Example Task:
- Generate a caption for a wildlife photo (e.g., “A lion resting under a tree”) by retrieving and aligning similar captions from a multimodal database.
3. Visual Question Answering (VQA)
- Core Focus:
- Answer questions about images using both visual content and external knowledge.
- Problems Solved:
- Knowledge Gaps: Addresses questions requiring external factual knowledge not present in the image (e.g., identifying landmarks or historical events).
- Reasoning Complexity: Handles multi-hop and reasoning-intensive queries by integrating relevant text or visual data.
- RAG Usage:
- Retrieves textual or multimodal evidence based on the question and visual features.
- Combines retrieved knowledge with the visual context to generate precise answers.
- Representative Methods:
- PICa: Converts visual content into textual descriptions and retrieves additional textual information to guide QA responses.
- RA-VQA: Uses differentiable retrieval to incorporate external evidence for more accurate and relevant answers.
- Example Task:
- Answer “What is the landmark in the background?” for an image of a cityscape by retrieving related descriptions from a knowledge database.
4. Visually Grounded Dialogue
- Core Focus:
- Enable coherent and factually grounded dialogues based on image content.
- Problems Solved:
- Conversational Coherence: Ensures dialogue aligns with the visual context and external knowledge.
- Engagement: Enhances dialogue quality by retrieving relevant multimodal examples.
- RAG Usage:
- Retrieves multimodal examples (e.g., previous dialogues, visual-text pairs) based on the input image and dialogue history.
- Uses retrieved examples to ground and inform response generation.
- Representative Methods:
- Maria: Combines visual features and dialogue history to retrieve contextually relevant examples, enriching the model’s responses.
- KIF: Retrieves visual-textual pairs and past dialogues to align responses with both the image and conversational flow.
- Example Task:
- Respond to “What can you tell me about this painting?” by retrieving similar paintings and their descriptions to provide informed and engaging replies.
Core Differences Across Scenarios
| Scenario | Core Focus | Problems Solved |
|---|---|---|
| Image Generation | Enhancing relevance and diversity | Aligning generated visuals with input prompts |
| Image Captioning | Improving caption accuracy | Reducing hallucinations, enriching descriptive detail |
| Visual QA | Combining visual and textual reasoning | Filling knowledge gaps, multi-hop reasoning |
| Visually Grounded Dialogue | Grounding conversations in visual content | Ensuring coherence, aligning with external knowledge |
Summary of RAG’s Role
- Enhanced Contextual Understanding: RAG retrieves external data to bridge knowledge gaps and ground generated outputs.
- Task-Specific Adaptations: The type of retrieval input (e.g., visual embeddings, textual queries) and database (e.g., image-caption pairs, knowledge bases) varies with the scenario.
- Improved Accuracy and Diversity: By conditioning outputs on retrieved information, RAG ensures precision, contextual relevance, and diversity across tasks.
This multi-faceted application of RAG highlights its transformative potential in handling complex image-related tasks.
RAG for Video: Applications, Core Focus, Challenges, and Implementation
Retrieval-Augmented Generation (RAG) for video tasks builds on the foundation of multimodal understanding by combining retrieval with video content to handle challenges like temporal dependencies, complex reasoning, and multi-modal integration. Below are the main scenarios, their core focuses, challenges, and representative methods.
1. Video Captioning
- Objective:
- Generate detailed and contextually accurate textual descriptions for video content.
- Core Focus:
- Temporal understanding of video frames.
- Integration of external knowledge to enhance the richness of captions.
- Problems Solved:
- Temporal Dependencies: Resolves challenges of generating coherent descriptions across video frames.
- Contextual Enhancement: Enriches captions with retrieved information relevant to the video’s content or theme.
- RAG Usage:
- Retrieves semantically similar video-caption pairs or textual descriptions based on video features.
- Conditions the caption generation process on retrieved data.
- Representative Methods:
- CARE: Combines frame, audio, and retrieved textual data for global and local semantic guidance, ensuring contextually rich captions.
- R-ConvED: Retrieves video-sentence pairs and uses a convolutional encoder-decoder to integrate retrieved textual data with video features.
- Example Task:
- Describe a sports video by retrieving similar captions or video summaries to inform the generated description (e.g., “A soccer player scores a goal after dribbling past defenders.”).
2. Video Question Answering (Video QA)
- Objective:
- Answer questions about video content by combining video features with external knowledge or context.
- Core Focus:
- Aligning visual and temporal content with question context.
- Integrating external retrieval for reasoning and factual grounding.
- Problems Solved:
- Knowledge Gaps: Addresses questions that require knowledge not explicitly present in the video.
- Temporal Reasoning: Resolves multi-step reasoning across video events and frames.
- RAG Usage:
- Retrieves relevant textual or multimodal data based on the question and video features.
- Combines retrieved content with video representations to generate answers.
- Representative Methods:
- R2A: Retrieves semantically similar textual data for questions and combines them with video features to answer queries.
- MA-DRNN: Utilizes external memory to store and retrieve useful information for long-term visual-textual dependencies.
- Example Task:
- Answer “What happened after the car crash?” by retrieving event sequences or textual descriptions of similar scenarios to inform the answer.
3. Video-Grounded Dialogue
- Objective:
- Engage in conversations based on video content, requiring multi-modal integration and coherence in dialogue.
- Core Focus:
- Combining video features with dialogue history to generate contextually grounded responses.
- Leveraging external retrieval for enriching conversations.
- Problems Solved:
- Engagement and Coherence: Ensures dialogue is aligned with both video content and conversational context.
- External Knowledge Integration: Improves response quality by incorporating relevant multimodal data.
- RAG Usage:
- Retrieves related video-dialogue pairs or textual descriptions based on video content and conversational context.
- Conditions the response generation on retrieved examples.
- Representative Methods:
- VGNMN: Extracts visual cues from video content and retrieves relevant textual data for dialogue grounding.
- EgoInstructor: Focuses on egocentric videos by retrieving exocentric video-text pairs to enhance conversational coherence.
- Example Task:
- Respond to “What is the character doing in this scene?” by retrieving similar video-dialogue pairs to ensure accurate and engaging responses.
4. Other Applications
4.1 Video Future Prediction
Objective:
- Predict future events or actions based on video content.
Representative Method:
VidIL
- How It Works: Retrieves relevant temporal sequences and integrates them into the generative model to predict plausible future scenarios.
4.2 Autonomous Driving
Objective:
- Explain driving decisions based on video inputs.
Representative Method:
RAG-Driver
- How It Works: Grounds explanations in retrieved expert demonstrations, ensuring trustworthy and interpretable driving action explanations.
4.3 Video Synthesis
Objective:
- Generate video content based on text or existing visual prompts.
Representative Method:
Animate-A-Story
- How It Works: Retrieves storyboards or motion templates from a database to guide video synthesis.
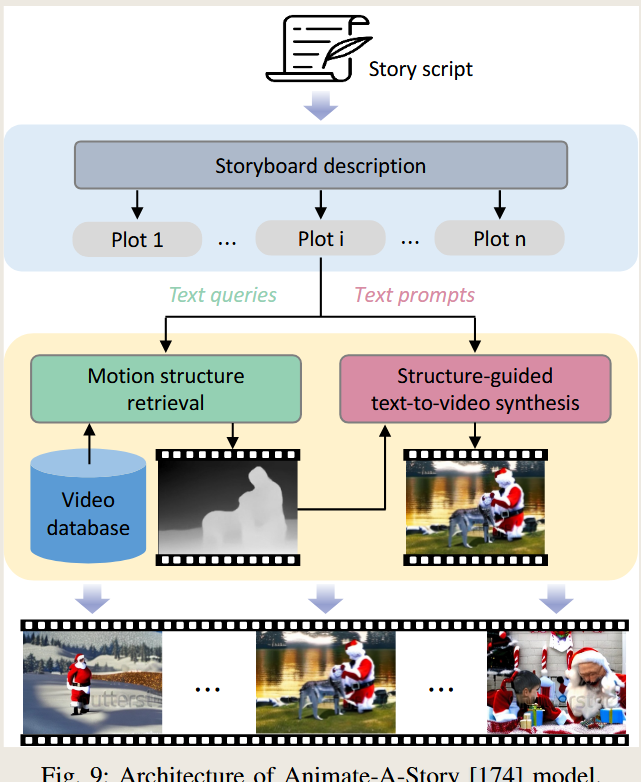
Core Differences Across Scenarios
| Scenario | Core Focus | Problems Solved |
|---|---|---|
| Video Captioning | Temporal understanding, contextual richness | Coherent descriptions, integration of external knowledge |
| Video QA | Temporal reasoning, external knowledge alignment | Multi-hop reasoning, addressing implicit information gaps |
| Video-Grounded Dialogue | Coherence and engagement in dialogue | Contextual alignment, enriching conversational responses |
| Future Prediction | Predicting plausible events | Aligning temporal patterns and reasoning |
| Autonomous Driving | Explaining driving decisions | Trustworthy action explanations |
| Video Synthesis | Generating visually accurate videos | Leveraging motion templates and visual prompts |
Summary of RAG’s Role in Video Applications
- Temporal and Contextual Understanding:
- RAG retrieves relevant temporal and multimodal data to enhance understanding of video events.
- Grounding and Coherence:
- By integrating external knowledge, RAG ensures outputs are contextually grounded and accurate.
- Task-Specific Adaptation:
- Each scenario utilizes task-specific retrieval inputs (e.g., video features, textual questions) and databases (e.g., video-caption pairs, motion templates).
RAG’s flexibility in handling temporal, multimodal, and knowledge-intensive tasks makes it an indispensable tool for solving video-related challenges.
Analysis: Similarities and Differences Between Video, Image, and Text Applications in RAG
RAG applications across video, image, and text domains share overlapping objectives and methodologies due to their reliance on retrieval to enhance generative outputs. However, they differ in core challenges, task requirements, and the types of data they process.
1. Similarities Across Domains
1.1 Knowledge Gap Bridging
- Commonality:
- All three domains rely on retrieval to fill knowledge gaps that generative models alone cannot address.
- Example:
- Text: QA systems retrieve documents to answer fact-based questions (e.g., “Who discovered penicillin?”).
- Image: Visual QA retrieves textual descriptions for objects or landmarks in images.
- Video: Video QA retrieves external textual knowledge or similar event sequences for reasoning (e.g., “What happens after a fire starts?”).
1.2 Contextual Grounding
- Commonality:
- Retrieval provides contextual grounding to reduce hallucinations and improve accuracy.
- Example:
- Text: Summarization tasks retrieve related text to ensure coherence and relevance.
- Image: Captioning retrieves image-caption pairs for descriptive richness.
- Video: Captioning retrieves video-caption pairs for temporal coherence and enriched descriptions.
1.3 Multimodal Integration
- Commonality:
- Both image and video applications heavily involve multimodal retrieval to align visual and textual data.
- Example:
- Image: Visual QA combines visual embeddings with textual knowledge.
- Video: Video QA uses video frames and textual questions to retrieve relevant data for complex queries.
1.4 Generative Assistance
- Commonality:
- Retrieval supports generative models by narrowing the solution space or providing templates/examples.
- Example:
- Text: Code generation retrieves similar code snippets to improve accuracy.
- Image: Image generation retrieves visual patches or embeddings for alignment.
- Video: Video synthesis retrieves motion templates or storyboards for structured generation.
2. Key Differences Across Domains
2.1 Temporal Dynamics (Unique to Video)
- Video Specificity:
- Video tasks require handling temporal dependencies, which are absent in static image and text tasks.
- Example:
- Video Captioning: Describes sequences of events across frames.
- Image Captioning: Focuses on static content without temporal reasoning.
- Text Summarization: Addresses long text inputs but lacks temporal constraints.
2.2 Data Complexity
- Video > Image > Text:
- Videos combine spatial, temporal, and multimodal data, making retrieval and generation more complex.
- Example:
- Video QA: Requires integration of temporal reasoning, visual embeddings, and textual retrieval.
- Image QA: Primarily involves visual-text alignment.
- Text QA: Relies on document retrieval without spatial or temporal reasoning.
2.3 Retrieval Input and Database
- Text:
- Input: Textual queries or sentences.
- Database: Document collections, knowledge bases.
- Image:
- Input: Visual embeddings, textual prompts.
- Database: Image-caption pairs, visual datasets.
- Video:
- Input: Video frame features, textual queries, temporal embeddings.
- Database: Video-caption datasets, motion templates, event sequences.
2.4 Task Granularity
- Text: Focused on precise reasoning or synthesis (e.g., QA, summarization).
- Image: Enriches descriptive or generative tasks (e.g., captioning, generation).
- Video: Expands into temporal tasks (e.g., future prediction, grounded dialogue).
2.5 Output Complexity
- Text: Outputs are typically structured or concise (e.g., answers, summaries).
- Image: Outputs are visual or descriptive (e.g., captions, generated images).
- Video: Outputs involve temporal alignment, often requiring dynamic descriptions or event predictions.
3. Comparative Summary Table
| Aspect | Text | Image | Video |
|---|---|---|---|
| Core Challenge | Semantic reasoning, QA alignment | Visual-text alignment | Temporal reasoning, multi-frame tasks |
| Retrieval Input | Textual queries | Visual features, textual prompts | Video frame features, textual queries |
| Database | Documents, knowledge bases | Image-caption pairs, visual datasets | Video-caption datasets, motion templates |
| Output Type | Text-based answers, summaries | Image captions, visual outputs | Dynamic captions, event sequences |
| Unique Focus | Factual and logical reasoning | Contextual richness and grounding | Temporal coherence and integration |
4. Example Tasks Comparing Domains
| Task | Text Example | Image Example | Video Example |
|---|---|---|---|
| QA | “Who discovered gravity?” | “What is in the background of this image?” | “What happened after the car crash?” |
| Captioning | Summarizing a document | Describing an image | Generating a timeline-based description of a video |
| Generative Assistance | Generating code snippets | Generating realistic images | Synthesizing video motion based on a storyboard |
5. Conclusion
- Connections: All three domains leverage RAG to bridge knowledge gaps, ground outputs, and enhance generative tasks through retrieval.
- Differences: Video tasks introduce temporal complexity, requiring more sophisticated retrieval and reasoning mechanisms than text or image tasks. Additionally, video scenarios often involve integrating multi-frame information, a requirement not present in static image or text tasks.
- Strengths of RAG: Its ability to adapt retrieval inputs, databases, and integration methods makes it versatile for solving unique challenges in each domain.
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/01/02/Paper-Reading-Note-13-Retrieval-Augmented-Generation-for-AI-Generated-Content/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)