Paper Reading 14 RAG- 方法介绍
综述中提到的不同的RAG 范式 的几篇代表作的介绍,主要介绍其大概思想,不仔细阅读
RAG fountation
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
2020
semanticscholarPaperarXiv

Query-based RAG
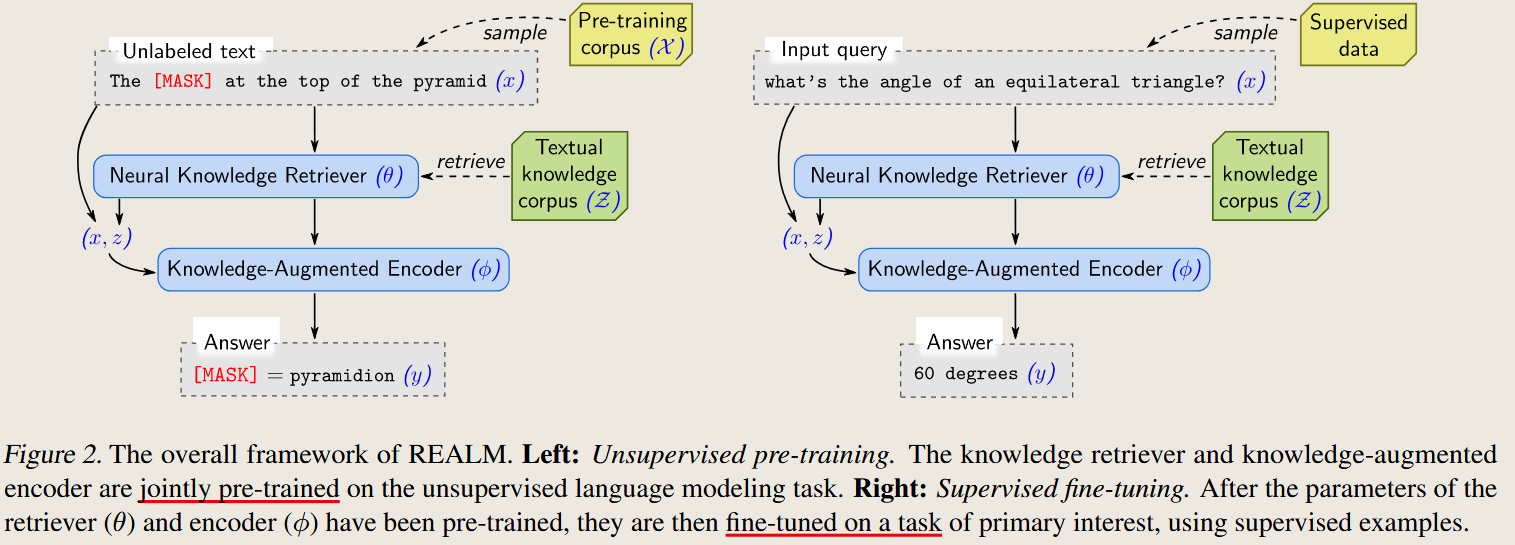
REALM REALM: Retrieval-Augmented Language Model Pre-Training
REALM: Retrieval-Augmented Language Model Pre-Training
2020
semanticscholarPaperarXiv
Latent Representation-based RAG
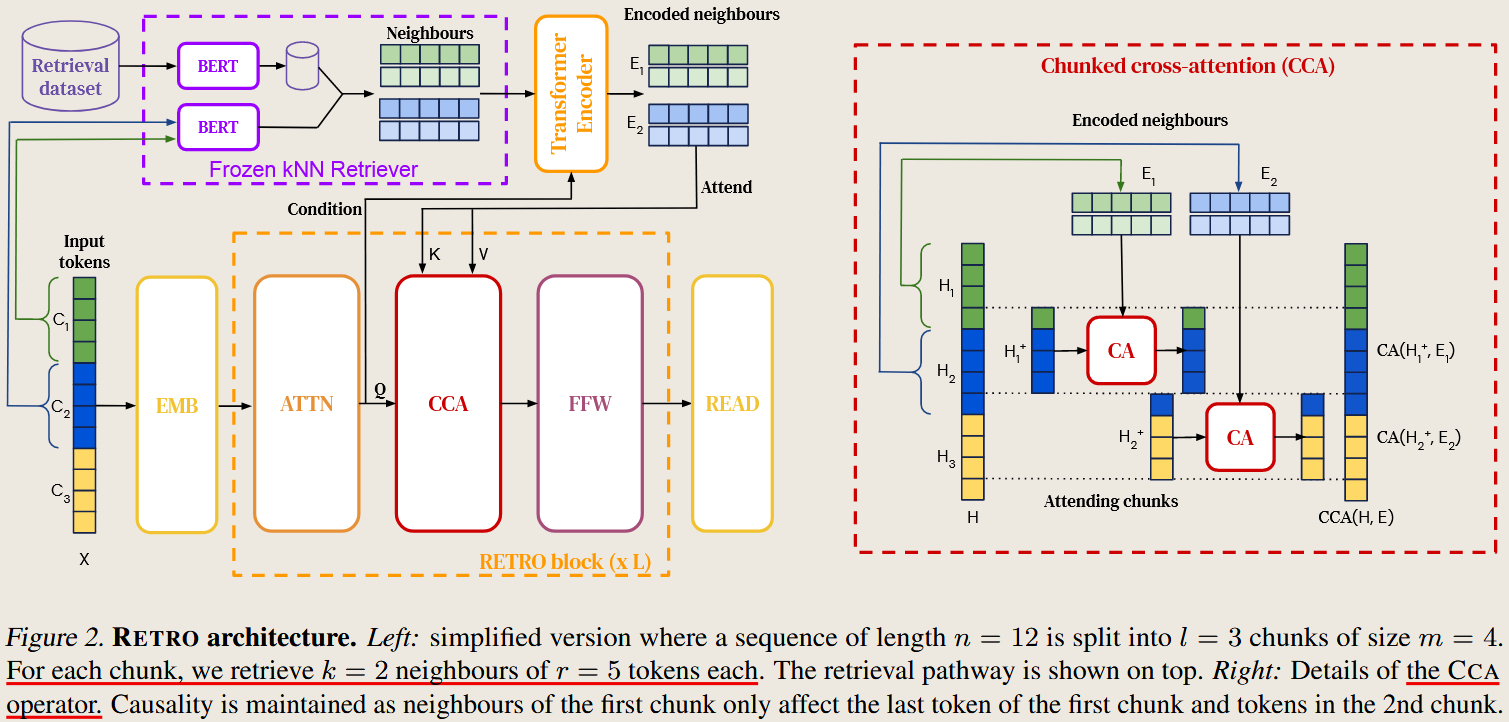
RETRO Improving Language Models by Retrieving from Trillions of Tokens
- RETRO Improving Language Models by Retrieving from Trillions of Tokens
None semanticscholar Paper
Logit-based RAG
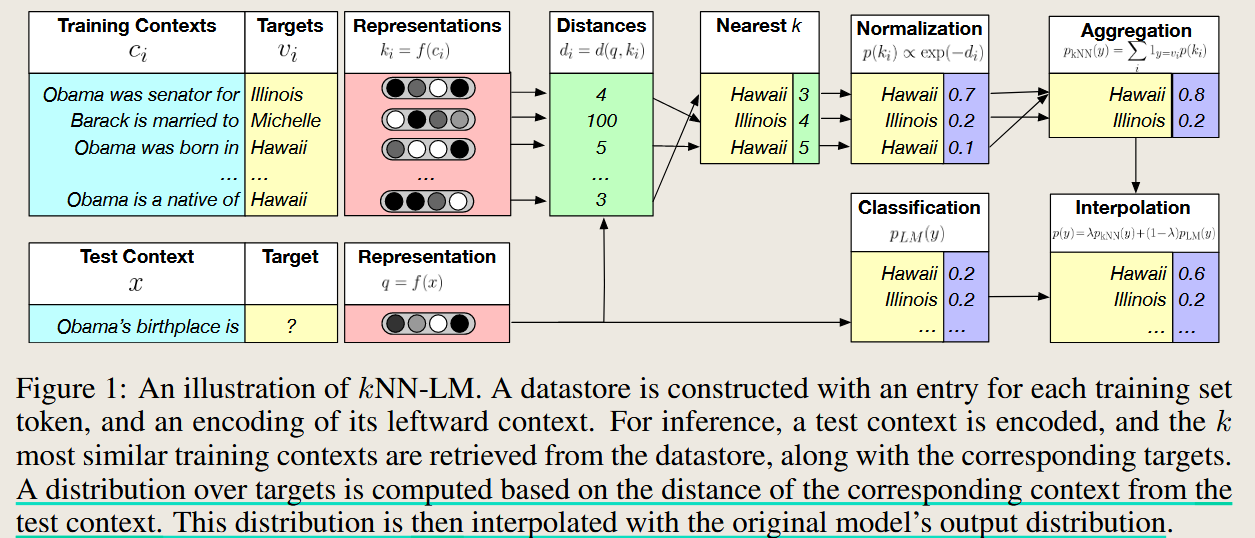
kNN-LMs GENERALIZATION THROUGH MEMORIZATION: NEAREST NEIGHBOR LANGUAGE MODELS
GENERALIZATION THROUGH MEMORIZATION: NEAREST NEIGHBOR LANGUAGE MODELS
kNN-LMs 2019
semanticscholarPaperarXiv
这里knn 用来检索相似问题的答案,并根据距离转为概率, 然后在最终输出结果的时候,将retrieval的概率输出与generator的概率输出进行融合得到最终结果。由于是在概率层面进行融合,所以不同于上述两种分别基于文本和特征的融合。
Speculative RAG
coG Copy Is All You Need
Copy Is All You Need
coG 2023
semanticscholarPaperarXivInternational Conference on Learning Representations
formulate text generation as progressively copying text segments (e.g., words or phrases) from an existing text collection.
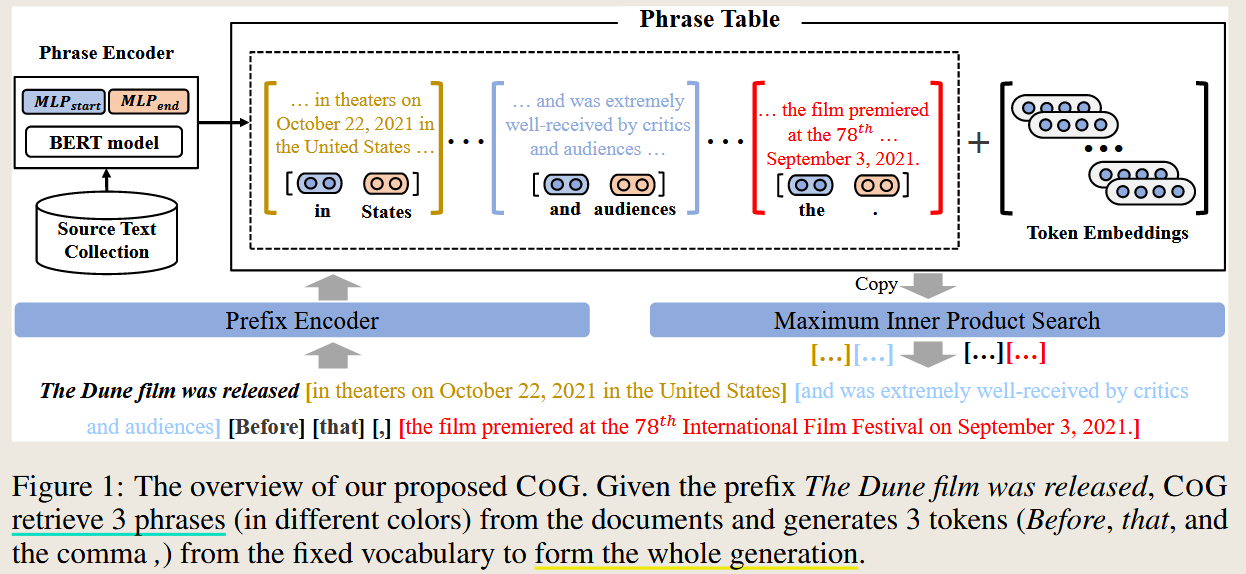
这个方法很邪典呀,我们不生产文章,我们只是文字的搬运工,哈哈哈。让我想起了自己写东西的经历,东拼西凑。
RETRIEVAL IS ACCURATE GENERATION
RETRIEVAL IS ACCURATE GENERATION
2024
semanticscholarPaperarXivInternational Conference on Learning Representations
selects contextaware phrases from a collection of supporting documents. 这个思路和上面是一致的,区别是 训练过程,初始化之后使用强化学习进行训练,我只能说好家伙
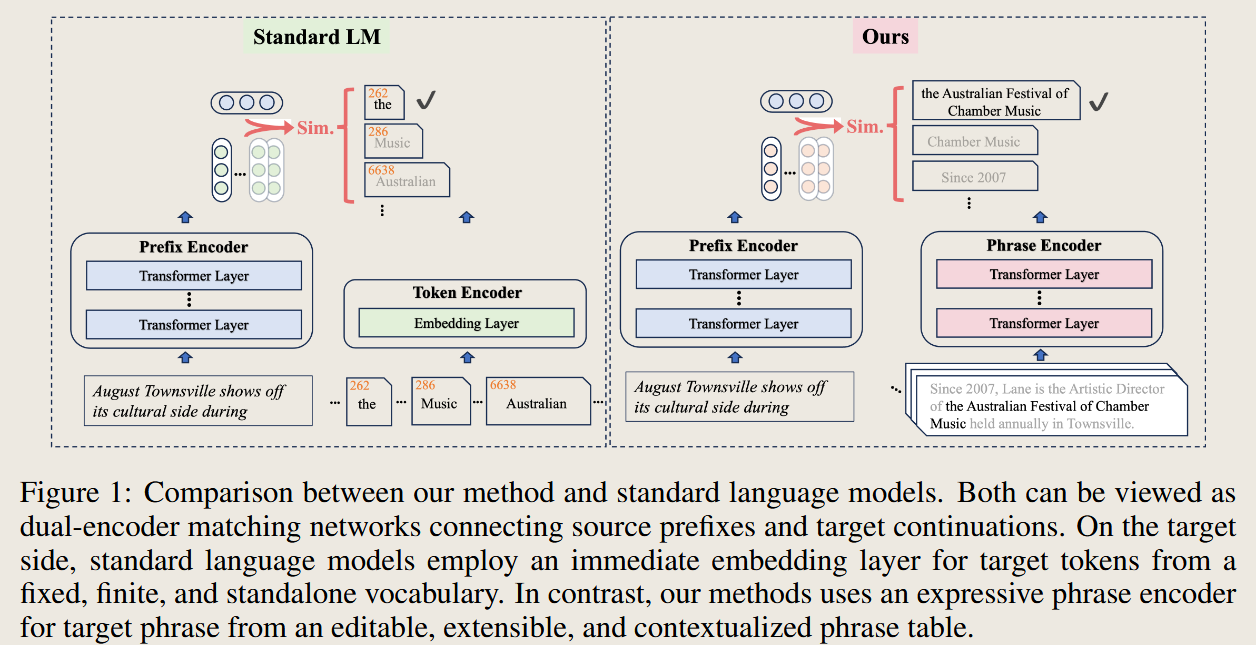

这个例子很奇怪呀,这个词段的链接还好,但是如果想要出现一些全新的是不是有些困难,还是说就不存在所谓全新的表达方式
RAG Enhancements
Input Enhancement
Query Transformation:
Query2doc: Query Expansion with Large Language Models
Query2doc: Query Expansion with Large Language Models
14 March 2023 Conference on Empirical Methods in Natural Language Processing
semanticscholarPaperarXiv
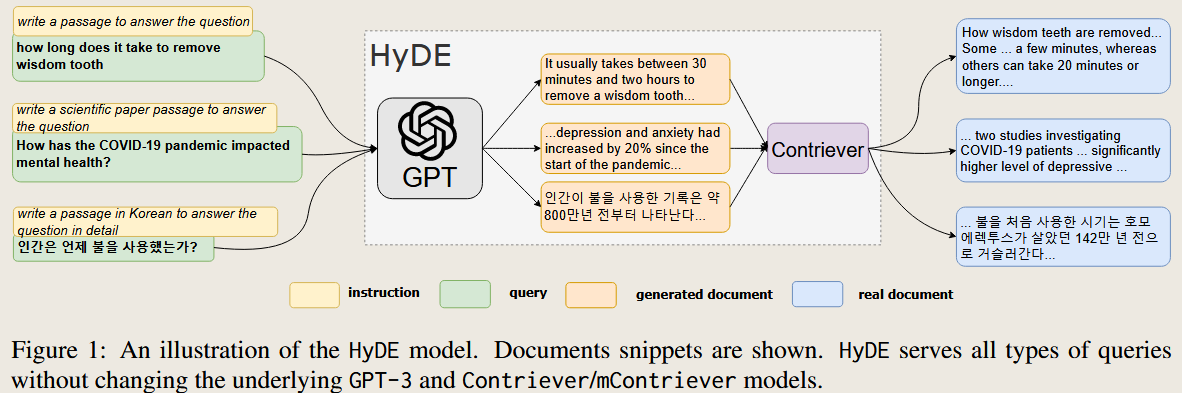
首先根据问题让LLM生成一些文档,然后这些生成文档就可以作为参考,原因是LLM在训练的时候就使用了大量互联网上的信息

HyDE Precise Zero-Shot Dense Retrieval without Relevance Labels
Precise Zero-Shot Dense Retrieval without Relevance Labels
HyDE 20 December 2022 Annual Meeting of the Association for Computational Linguistics
首先 生成 一系列的 伪文档,然后在真文档的特征空间周围搜索相似度高的伪文档
CoVe CHAIN-OF-VERIFICATION REDUCES HALLUCINATION IN LARGE LANGUAGE MODELS
CHAIN-OF-VERIFICATION REDUCES HALLUCINATION IN LARGE LANGUAGE MODELS
semanticscholarPaperarXivCoVe 20 September 2023 Annual Meeting of the Association for Computational Linguistics
The expanded queries undergo validation by LLM to achieve the effect of reducing hallucinations.

Data Augmentation
Lift Yourself Up: Retrieval-augmented Text Generation with Self-Memory
Lift Yourself Up: Retrieval-augmented Text Generation with Self-Memory
semanticscholarPaperarXiv3 May 2023 Neural Information Processing Systems
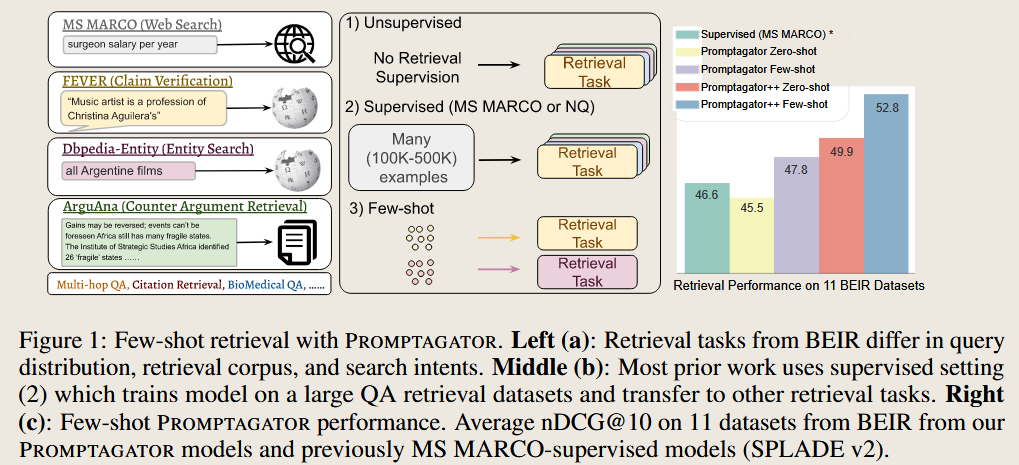
既然上面的方法行得通,LLM生成的伪文档包含一些信息,那么把这些信息放在一起岂不就是一个 数据库 。基于上述思路,这篇文章有了一个更大胆的想法,有了那么多伪文档,那可以从中选择一些较好地作为retrieval 的结果提供给后续生成。而上述 生成-挑选的过程可以不断进行,最终会得到一个非常大的数据,来代替固定内容的搜索备选数据库。 生成部分不断生成, 而 选择器是能够训练得到一个好的选择器的。

PROMPTAGATOR : FEW-SHOT DENSE RETRIEVAL FROM 8 EXAMPLES
PROMPTAGATOR : FEW-SHOT DENSE RETRIEVAL FROM 8 EXAMPLES
2022 International Conference on Learning Representations
通过给LLM 提示词来创造数据,从而训练一个 retrieval 。 这里创造数据的过程用到了少量示例 所以说是few-shot 的。
Retrieval Enhancement
Retriever Fine-tuning:
instruction fine-tuning Training language models to follow instructions with human feedback
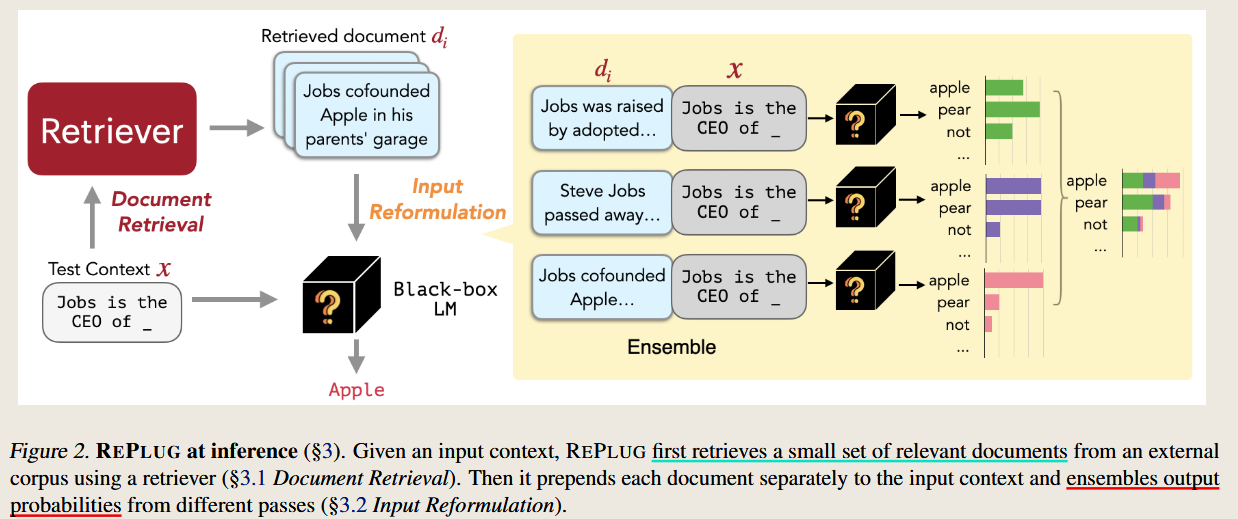
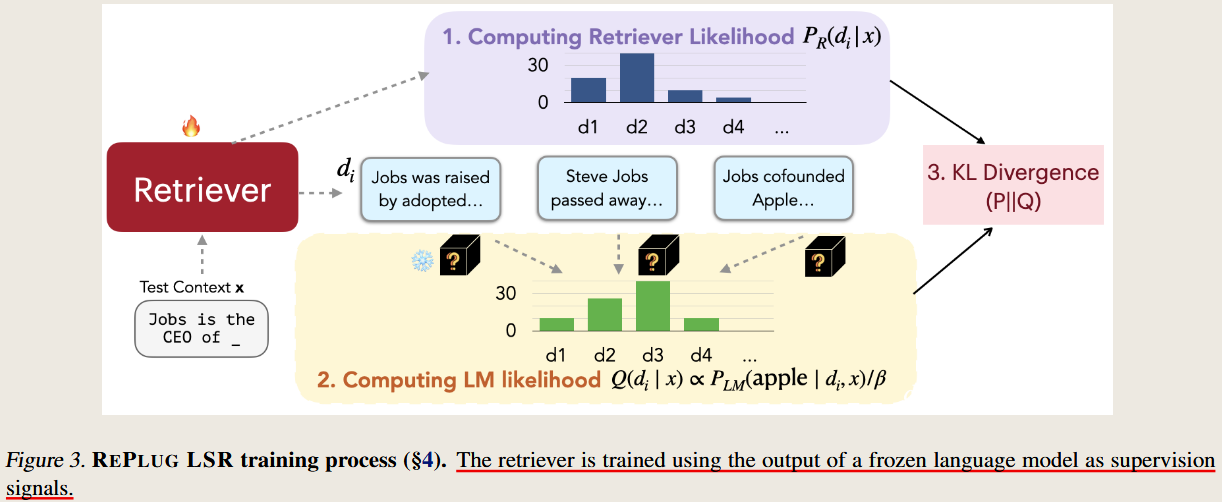
REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models
2023 North American Chapter of the Association for Computational Linguistics
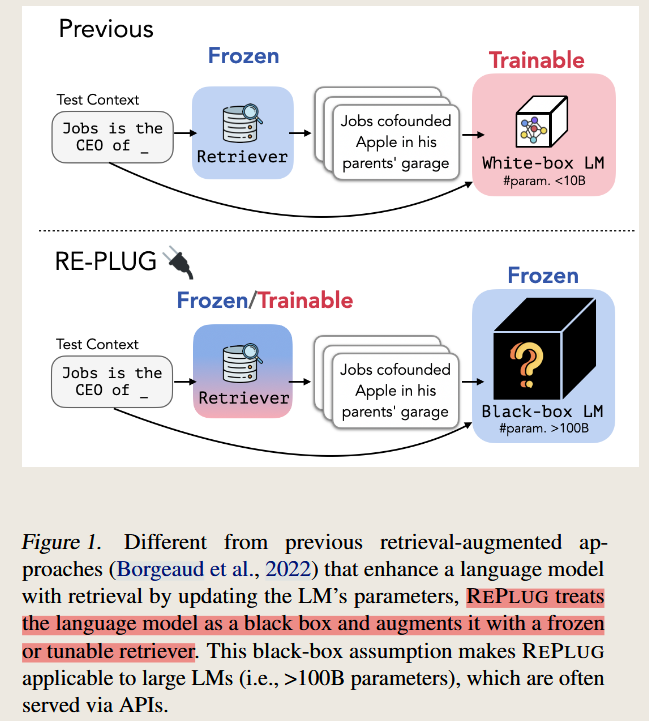
treats LM as a black box and update the retriever model based on the final results.
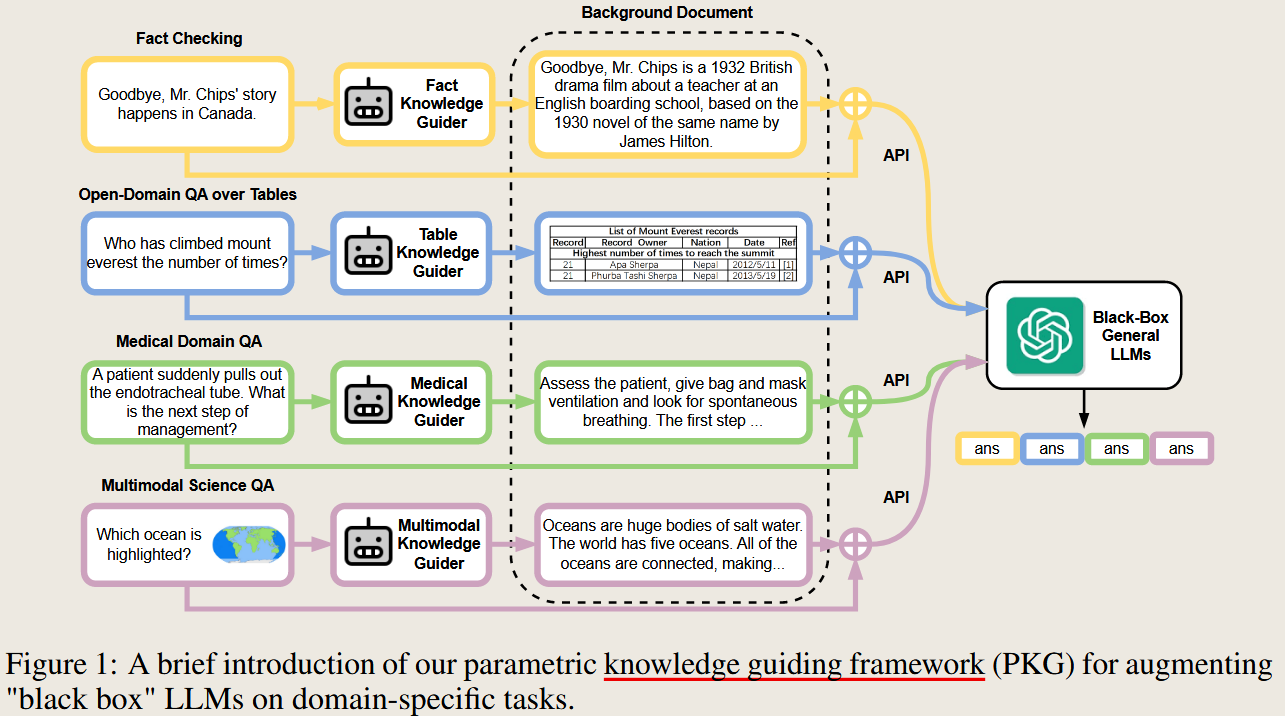
PKG Augmented Large Language Models with Parametric Knowledge Guiding
Augmented Large Language Models with Parametric Knowledge Guiding
PKG 2023 arXiv.org
首先在对应领域进行微调,然后 生成对应知识作为背景提供给 generator
Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data
Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data
可以用来检索结构型数据,使用对比学习 和 掩码实体预测来训练 retrieval

Re-ranking:
KARD Knowledge-Augmented Reasoning Distillation for Small Language Models in Knowledge-Intensive Tasks
Knowledge-Augmented Reasoning Distillation for Small Language Models in Knowledge-Intensive Tasks
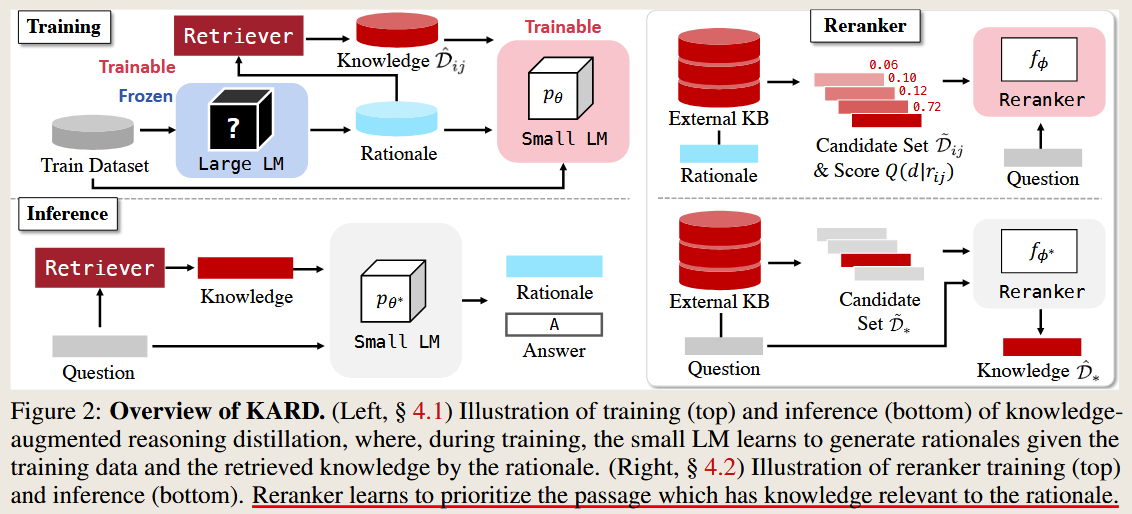
Recursive Retrieval
Query Rewriting for Retrieval-Augmented Large Language Models
Query Rewriting for Retrieval-Augmented Large Language Models
Rewrite-RetrieveRead

Bridging the Preference Gap between Retrievers and LLMs
Bridging the Preference Gap between Retrievers and LLMs
两头都不动,训练中间的,这要怎么训?强化学习,服了

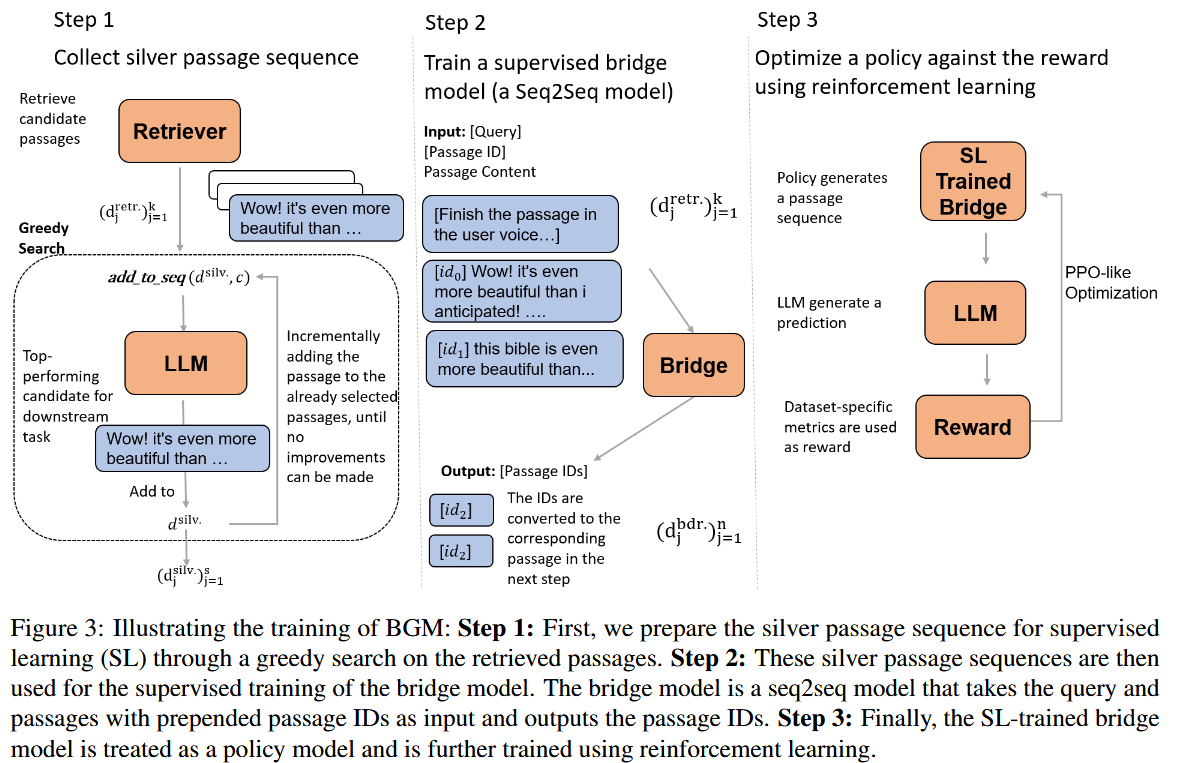
Hybrid Retrieval
ISEEQ: Information Seeking Question Generation Using Dynamic Meta-Information Retrieval and Knowledge Graphs
ISEEQ: Information Seeking Question Generation Using Dynamic Meta-Information Retrieval and Knowledge Graphs
2021 AAAI Conference on Artificial Intelligence
使用了知识图来进行询问,其次这里提到了一个应用场景就是对话形式来获得有效信息,比如医生对患者的对话。主要结合了两种方法,一种是问题的扩展,另一种是使用知识图来进行搜索
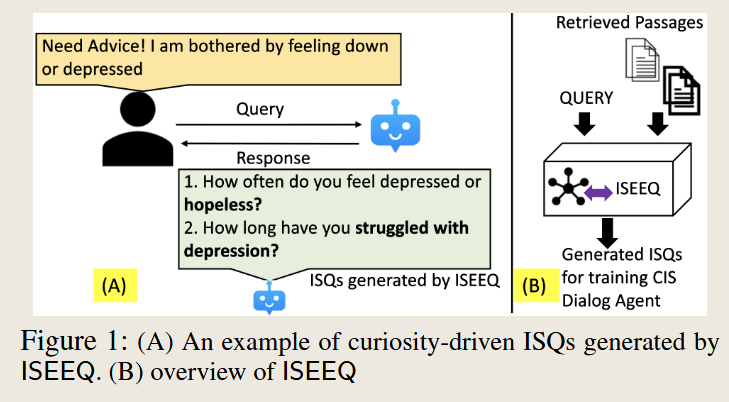
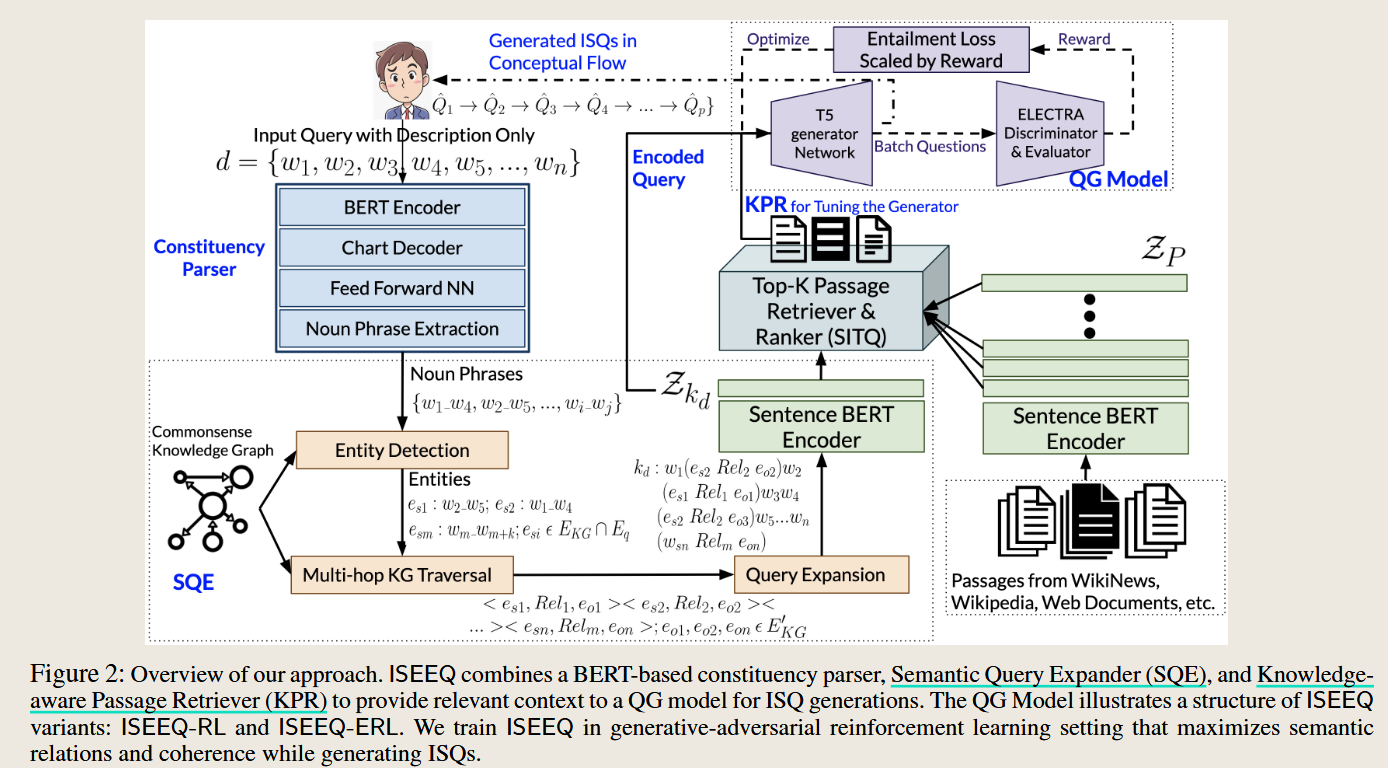
RAG application in Image
Image Generation
KNN-Diffusion: KNN-Diffusion: Image Generation via Large-Scale Retrieval
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Retrieves similar images or embeddings to condition diffusion models, enabling zero-shot image stylization and diverse outputs.
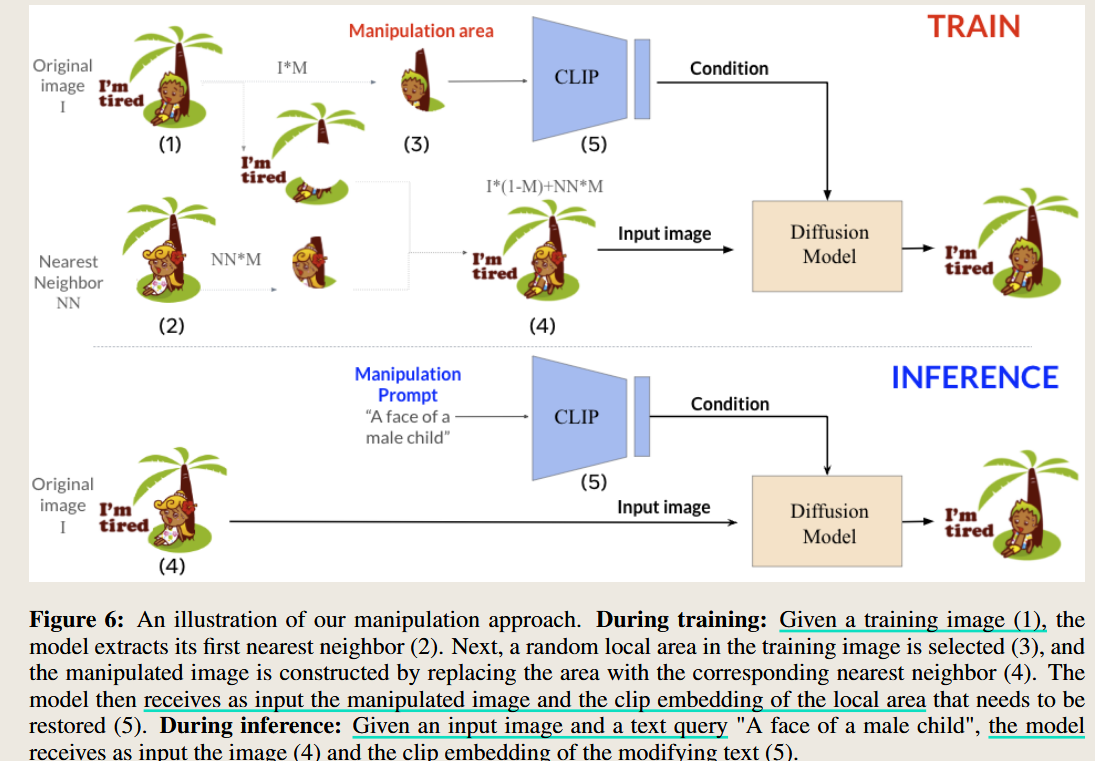
首先需要注意到的是这个方法的引用场景是图像编辑或者说是图像生成,所以会涉及到一个diffusion模型,这个模型接受原始image的输入 和编辑prompt 的描述。
编辑prompt的输入空间来自 CLIP ,由于CLIP 模型下的图像和文本是共享空间的,所以及时训练和推理时候CLIP的输入不同,但输出结果是可以用来和图像特征进行融合输入到Diffsusion model 里面的。
其次这个方法使用到了Knn 方法,但这里的knn 和之前论文的knn 搜索的内容有所不同,这里的knn 是搜索的与输入图像相似的图像。在训练的时候,编辑图像区域 从原始输入 与 最近邻居图像的替代。
这个文章的一个卖点就是 在训练的时候 不需要对应的图像文本对,而是 只需要图像即可,这一点其实是很神奇的。这一点是怎么做得到呢,其实是利用了CLIP 文本和图像共享空间的特性,把输入的文本提示转换为了图像输入来进行代替。
然后由于kNN只能搜索相似的图像,因此可以推测图像直接的相似性肯定很高,所以是适合做图像编辑任务的,保留了图像的大部分原始特征。(废话,不是说保留了原始特征,而是说他就根本不能变化,因为他的训练过程只遇到了和他相似的图像)
还有一个想法就是CLIP真的很强大,进行转换效果都这么好。
我觉得这是很好的思路,可以进行扩展
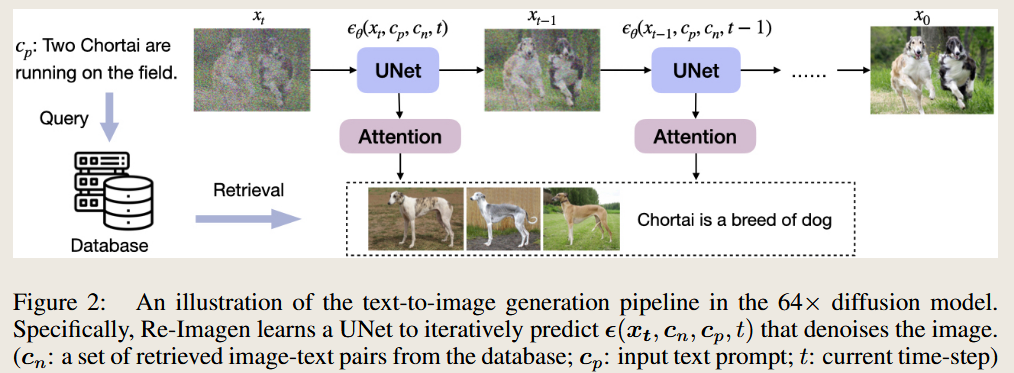
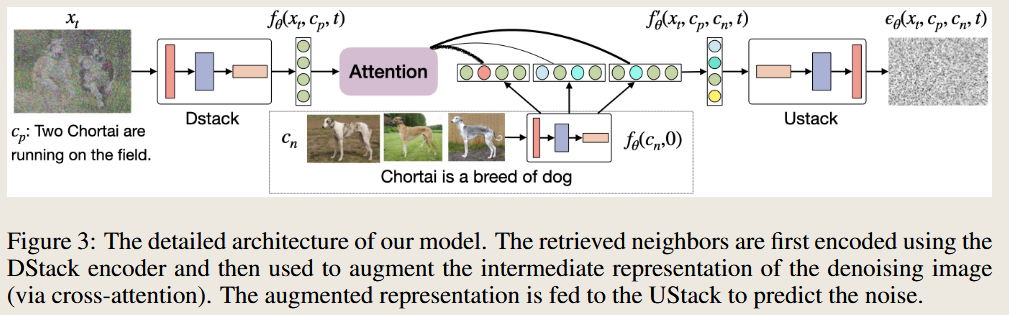
RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
Given a text prompt, Re-Imagen accesses an external multi-modal knowledge base to retrieve relevant (image, text) pairs and uses them as references to generate the image.
RAG application in Knowledge
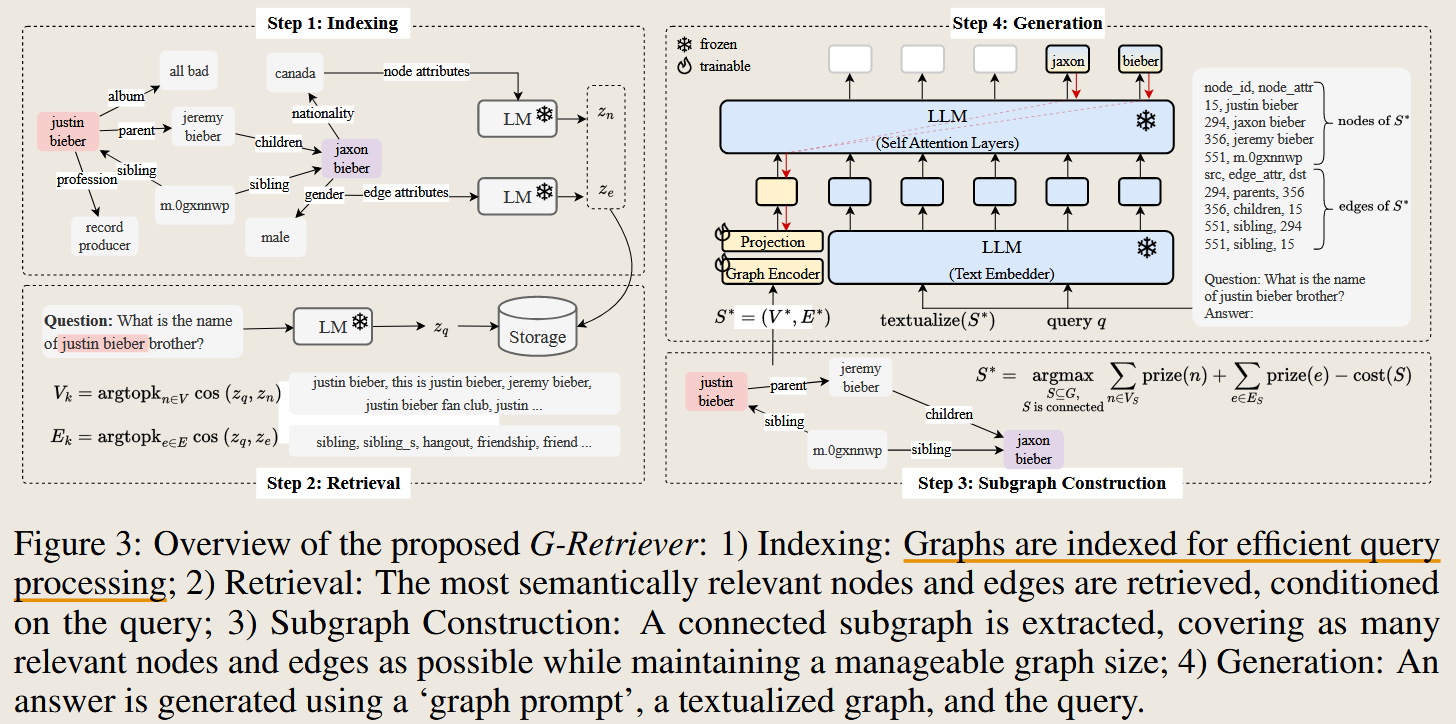
G-Retriever
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Evaluation
Benchmarking Large Language Models in Retrieval-Augmented Generation
Benchmarking Large Language Models in Retrieval-Augmented Generation

文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/01/02/Paper-Reading-Note-14-RAG-%E6%96%B9%E6%B3%95%E4%BB%8B%E7%BB%8D/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)