Paper Reading 15 LLM finetuning and forgetting
问题一:大语言模型的遗忘与小模型的遗忘有什么区别?
1.1 模型规模与遗忘的关系
模型规模是否影响遗忘程度?
是否存在规模临界点(如10亿参数以上),遗忘率会显著降低?
更大的模型参数是否本质上只是增加了存储能力,而非记忆的质量?
预训练规模对遗忘的影响?
数据集覆盖度:是否覆盖更多的概念,减少需要迁移的部分?
训练时间的影响:长时间训练的模型是否更容易产生知识冲突?
相关参考论文
1 EFFECT OF MODEL AND PRETRAINING SCALE ON CATASTROPHIC FORGETTING IN NEURAL NETWORKS
EFFECT OF MODEL AND PRETRAINING SCALE ON CATASTROPHIC FORGETTING IN NEURAL NETWORKS
2022
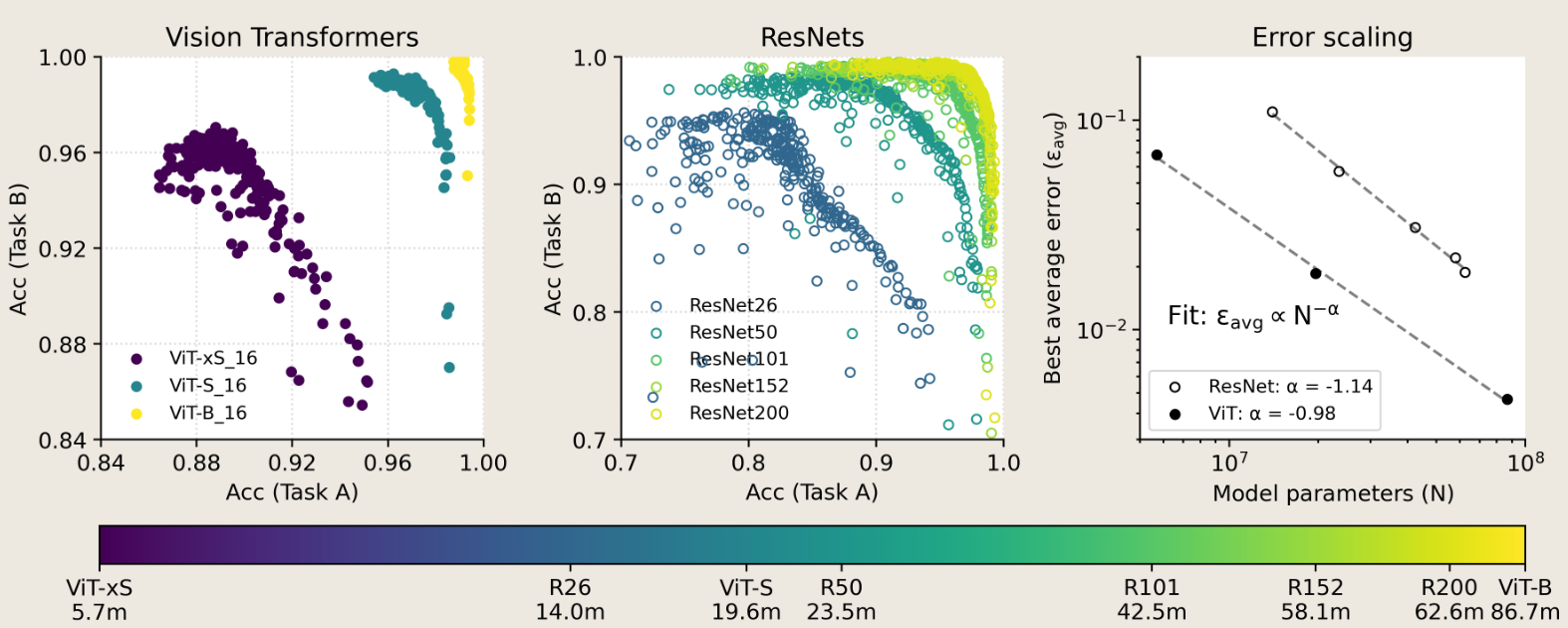
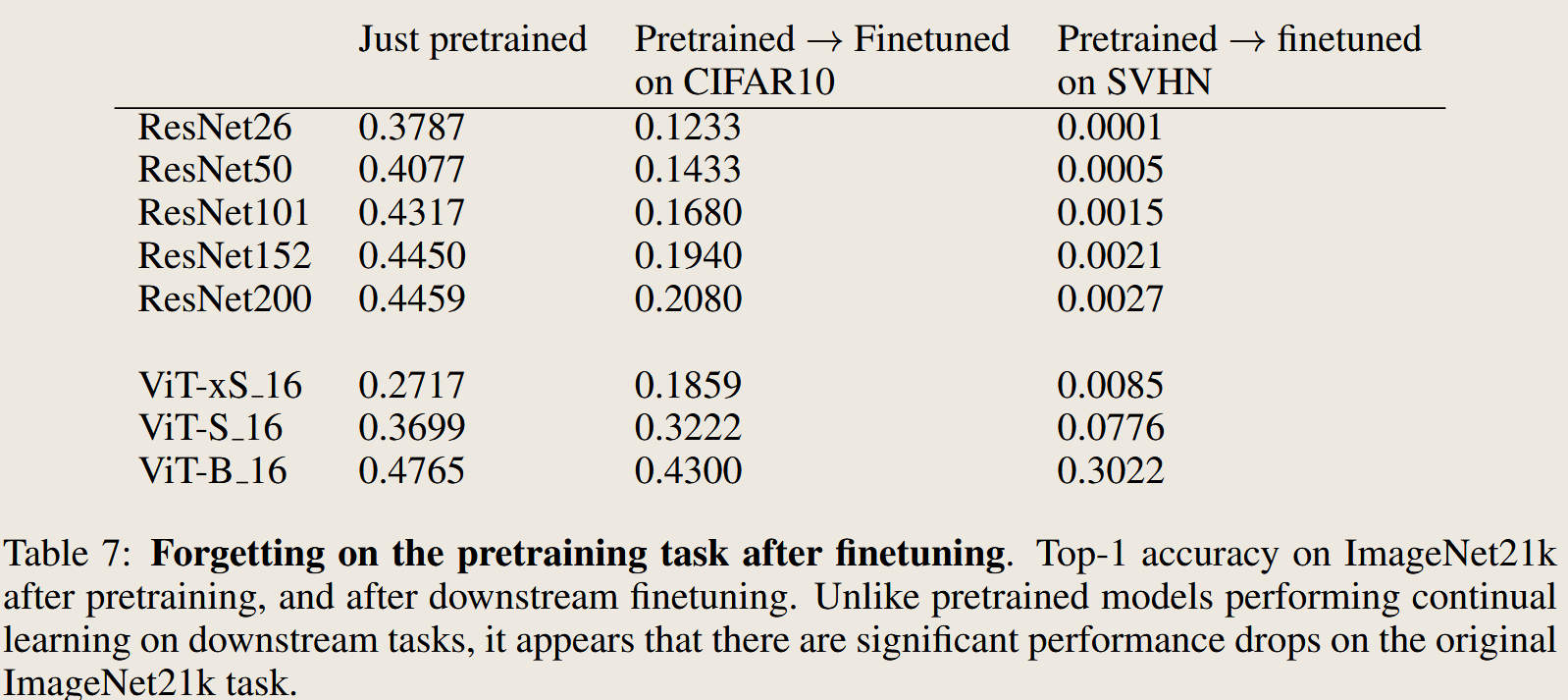
large, pretrained ResNets and Transformers are significantly more resistant to forgetting than randomly-initialized, trained-from-scratch models; this robustness systematically improves with scale of both model and pretraining dataset size.
看起来,模型越大,神经网络参数越多,所对应的数据数据集合也就越大,从而导致 遗忘越小。 其在 zero-shoot 和 finetuned 之后的效果也都表现更好。
2 Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
2023 Annual Meeting of the Association for Computational Linguistics
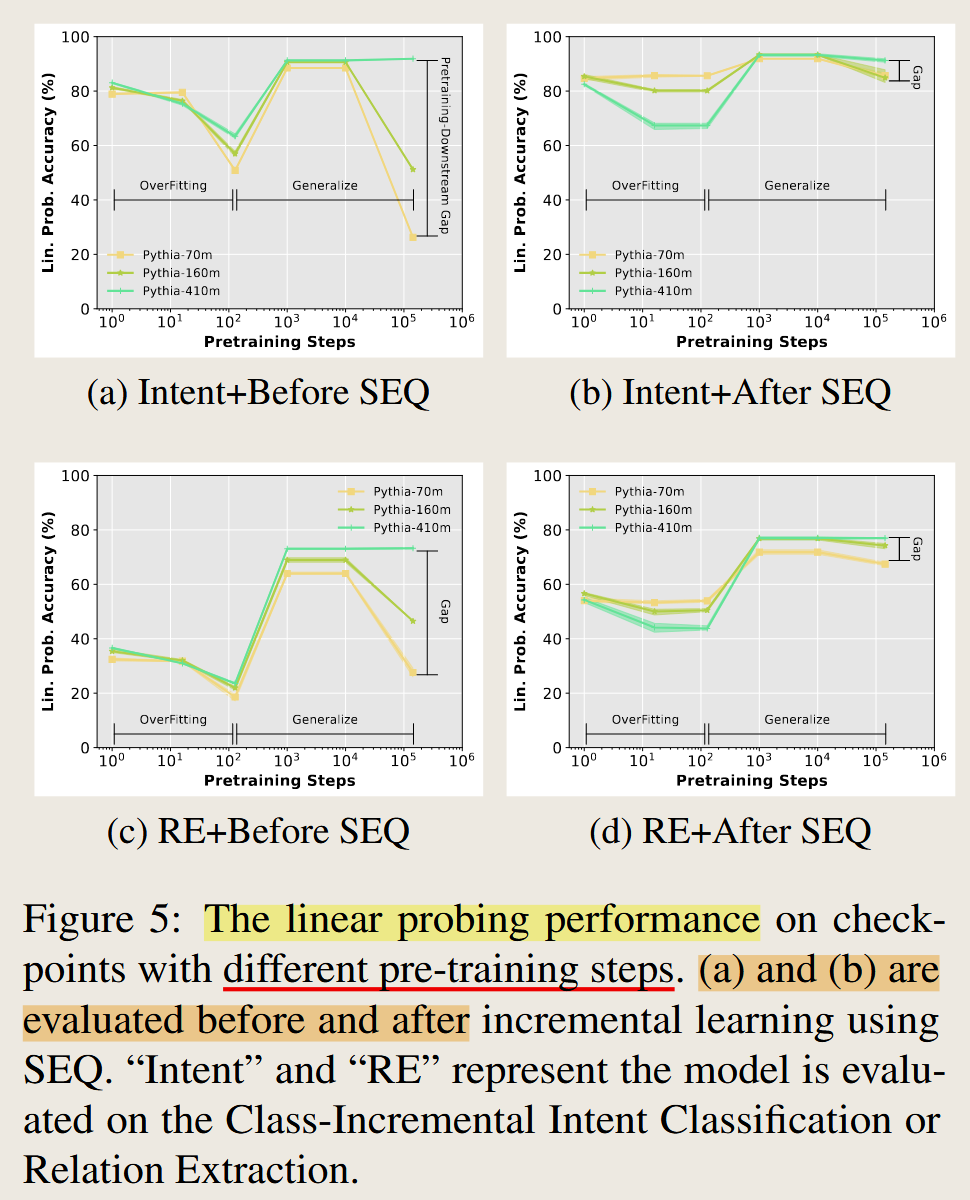
预训练对模型的影响:
即使是随机初始化的大模型,在zero-shot 和经过finetuning也能到的一个很好的效果,
在预训练初期阶段,预训练后的大模型 在下游任务的 zero-shot 能力变差,经过finetuning的效果也变差
在预训练后期,预训练的大模型 在下游任务的 zero-shot 能力变强,经过finetuning的效果也变强
继续预训练,预训练的大模型 在下游任务的 zero-shot 能力又变差,作者推断这可能是由于预训练的文本和下游任务的文本不一致所致的,在下游任务finetune之后同样能够实现很好的效果
还有就是模型的大小不一样,但出现拐点的时间是类似的,也就是说经过同样轮数的训练
1.2 数据集特性与遗忘
数据集中冗余对遗忘的影响?
重复样本或相似样本是否会降低遗忘率?
数据集是否越稀疏,越容易导致灾难性遗忘?
数据分布变化
长尾数据是否更容易被遗忘?
逐步学习中,数据顺序对遗忘的影响有多大?
训练顺序的不同会影响大模型的效果
1.3 网络架构与遗忘
架构复杂性对遗忘的作用
Transformer相较于RNN是否更具抗遗忘能力?
模块化设计(如MoE)是否有助于减少知识干扰?
记忆机制的加入
可微记忆网络(如DNC)是否对抗遗忘有效?
是否可以通过增加外部记忆模块(如RAG框架中的检索模块)减少遗忘?
相关参考论文
CAN BERT REFRAIN FROM FORGETTING ON SEQUENTIAL TASKS? A PROBING STUDY
CAN BERT REFRAIN FROM FORGETTING ON SEQUENTIAL TASKS? A PROBING STUDY
2023 International Conference on Learning Representations
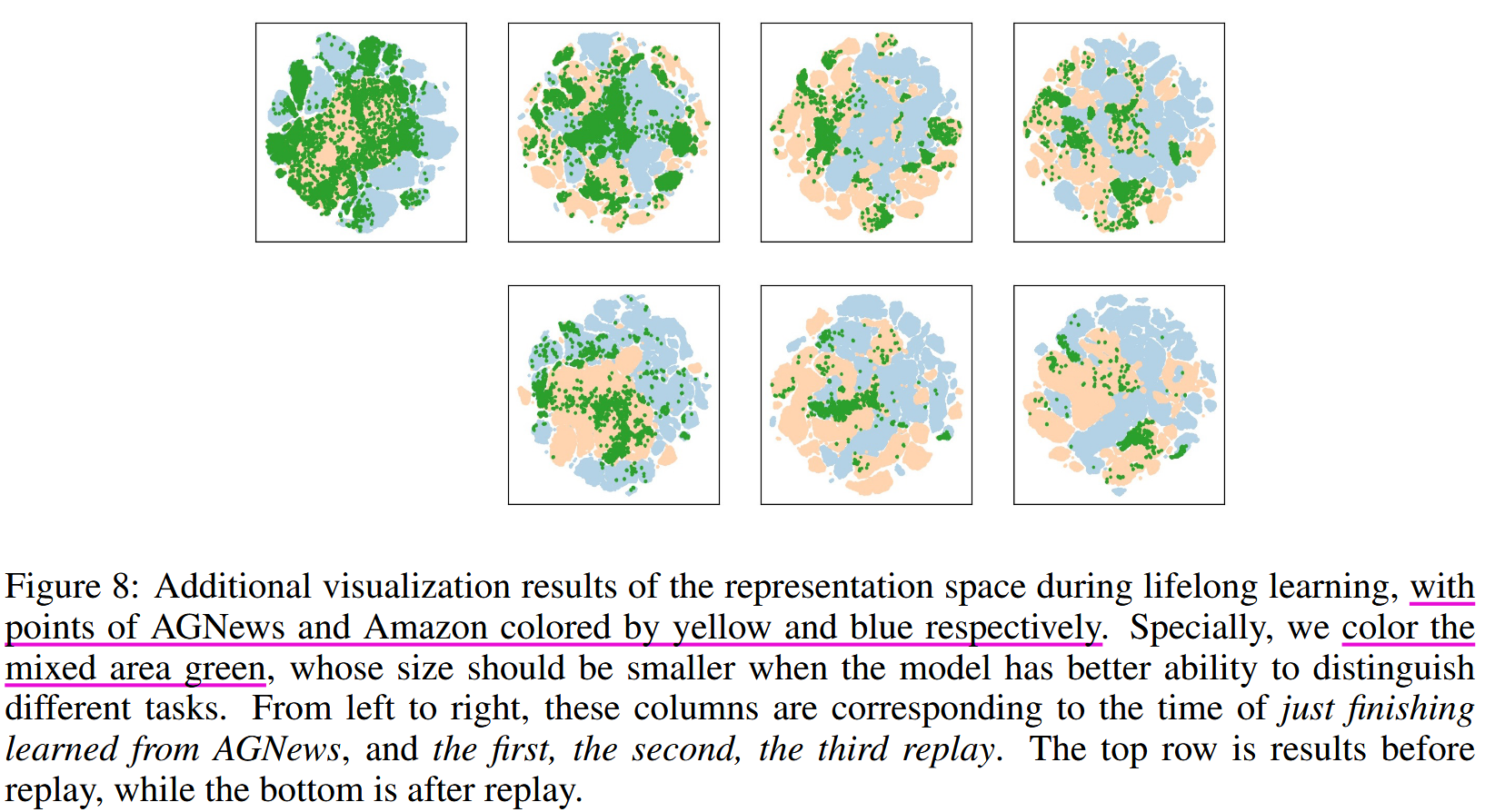
论文指出,BERT 模型具有持续学习的潜能。作者提到在训练完旧的任务之后进行训练新的任务,旧的任务中的不同类别仍然保持区别,且整体的变换保持一定的拓扑结构。而旧的任务的类别与新的任务的类别在特征层面出现了重叠,使用 experience relay 特征层回放,能够减轻重叠。
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
2023 Annual Meeting of the Association for Computational Linguistics
这篇论文指出 在文本分类任务下 SEQ sequence fine-tuning 下, PLMs 的遗忘现象主要由于分类器的偏移而不是 PLM遗忘了旧的知识。
PLM 在经过预训练之后就已经具备区分不同类别文本的能力和知识,这主要来源于PLM的 transformer 结构和预训练过程。
在固定PLM的情况下,应当也固定旧类别的classifer,否则classifier经过训练会导致就旧类别对应的 分类权重得到更新,造成 分类权重的漂移,这是表现下降的原因。
问题二:当前大语言模型的微调方法有哪些?效果如何?
2.1 微调方法分类
基于参数微调
全参数微调:是否适用于特定任务,但更容易遗忘?
参数冻结+微调:冻结底层网络,仅更新上层。
LoRA或Adapter的使用是否有效减少灾难性遗忘?
基于增量学习的微调
在线微调:数据分布变化时如何平衡新旧知识?
知识蒸馏:是否可以通过蒸馏模型避免遗忘?
基于迁移学习的微调
- 迁移学习中的反向迁移:微调后原始任务性能的退化是否是遗忘?
2.2 微调的缺点与不足
泛化能力
微调是否导致模型对未见任务的泛化能力下降?
数据不平衡是否会加剧微调时的灾难性遗忘?
数据效率
- 数据利用率是否影响微调的效果?少样本场景下灾难性遗忘是否更严重?
2.3 新兴微调技术
Prompt-tuning方法
Prompt工程能否减少微调带来的遗忘?
Prompt与RAG相结合是否提升对知识的稳定性?
问题三:持续学习方法在大语言模型中的应用
3.1 已应用方法与场景
任务隔离方法
EWC、MAS等正则化方法在模型中是否有效?
模型分支策略(如多任务分层)在实际场景的效果?
记忆回放方法
使用少量历史数据进行微调是否对抗遗忘有效?
模拟历史数据生成的回放技术能否提高泛化能力?
3.2 持续学习面临的挑战
知识冲突
在跨领域任务微调时,知识冲突的解决机制是否足够高效?
是否需要动态调整网络结构以适应多样任务?
长期依赖问题
在长时间序列任务中,如何确保早期知识不会被遗忘?
是否需要动态适应模型权重,确保关键知识点的长期稳定性?
3.3 效果评价
评价指标
评价灾难性遗忘的标准是什么?任务性能下降的幅度?
持续学习方法是否在实际工业场景有量化的收益?
对实际场景的影响
知识更新需求强烈的场景(如法律、医疗),哪种持续学习方法效果最佳?
多模态任务(如视频+文本)中的遗忘是否存在跨模态影响?
应用领域
1 判断隐私数据是否被大模型训练使用
LLM Dataset Inference Did you train on my dataset?
LLM Dataset Inference Did you train on my dataset?
2024 arXiv.org
这个设定就很想是continual learning 设置。 设置两个数据集,用PLMs提取特征,然后训练一个分类器,这个分类器用来区分不同的类别。然后测试在这两个数据集上的表现。 区别就是这里的两个数据库不是分类类别,而是数据库是来自同一部分的不同数据,大概可以类比为 迪士尼中的布鲁斯 和 高迪的概念。 背后的逻辑是大模型的表征能力来自于训练集,训练集和测试集对于大模型来说是不一致的,但最终效果并不显著
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/01/06/Paper-Reading-Note-15-LLM-fintuning-and-forgetting-Question/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)