Paper Reading 16 LLM finetuning and forgetting - 2 Probing Performance SEQ*
这两篇论文都使用了 Probing Performance 和 tsne来进行可视化 BERT在论文中的遗忘现象,第二篇论文在第一篇论文的基础上进行了进一步的扩展。
CAN BERT REFRAIN FROM FORGETTING ON SEQUENTIAL TASKS? A PROBING STUDY
2023 International Conference on Learning Representations
论文指出,BERT 模型具有持续学习的潜能。作者提到在训练完旧的任务之后进行训练新的任务,旧的任务中的不同类别仍然保持区别,且整体的变换保持一定的拓扑结构。而旧的任务的类别与新的任务的类别在特征层面出现了重叠,使用 experience relay 特征层回放,能够减轻重叠。
论文信息
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
2023 Annual Meeting of the Association for Computational Linguistics
这篇论文指出 SEQ sequence fine-tuning 下, PLMs 能够避免遗忘保持对大多数知识的记忆。 sequence fine-tuning下,PLMs 的遗忘现象主要由于分类器的偏移而不是 PLM遗忘了旧的知识。
AI 总结
以下是对论文《Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models》的综合总结,包括范围、核心思想、方法、贡献、差异与创新、结果与结论、与其他方法对比以及讨论部分。
范围与背景 (Scope or Setting)
- 范围: 论文聚焦于在增量学习 (Incremental Learning, IL) 场景中使用预训练语言模型(Pre-trained Language Models, PLMs)作为主干模型,研究其在分类任务中的表现。
- 研究场景: 包括类别增量学习(Class-Incremental Learning, CIL)和任务增量学习(Task-Incremental Learning, TIL),任务涉及文本分类、意图分类、关系提取和命名实体识别。
核心思想 (Key Idea)
- 提出一个核心问题:预训练语言模型(PLMs)是否真的会在增量学习中遭遇灾难性遗忘(Catastrophic Forgetting)?
- 通过实验发现,PLMs在增量学习中具备强大的抗遗忘能力,这与现有许多假设相悖。
- 基于此,提出一种“令人沮丧的简单方法”SEQ*,通过冻结模型和其他优化策略,达到接近甚至超越当前最佳方法的效果。
方法 (Method)
实验设置:
- 使用20多种方法,在多个数据集上测试PLMs在CIL和TIL场景中的性能。
- 测试两种主流架构(encoder-only和decoder-only)和不同规模的模型(参数从19M到1.21B)。
测量遗忘:
- 引入探测性能(Probing Performance)作为评估PLMs内部知识遗忘的标准,与传统的观测性能(Observed Performance)进行对比。
SEQ*:
- 提出冻结PLM主干(Backbone)和旧分类器等策略,减少参数调整并防止灾难性遗忘。
贡献 (Contribution)
实验性发现:
- 现有研究过度夸大了PLMs的遗忘问题。
- PLMs在增量学习中,内置的抗遗忘能力源于预训练阶段和Transformer的架构。
- 线性探测性能几乎不受遗忘影响,遗忘主要发生在分类器中。
实践意义:
- 提出的SEQ*方法在多数设置中表现出优于或媲美当前SOTA方法的性能,同时显著减少了训练参数和时间。
差异与创新 (Difference and Innovation)
差异: 与传统方法注重克服灾难性遗忘不同,该研究重新审视遗忘的定义,强调PLMs的抗遗忘特性。
创新:
- 提出“冻结主干”的简单但有效的优化策略。
系统性地分析了探测性能与分类器性能的关系,揭示了分类器偏离导致遗忘的根本原因。
结果与结论 (Results and Conclusion)
- 在多个数据集和任务上,SEQ*方法展示了与SOTA方法相当甚至更好的性能,同时训练开销显著减少。
- 研究建议NLP领域重新审视灾难性遗忘假设,并提出设计包含领域知识的增量学习基准和更高效的算法作为未来方向。
与其他方法对比 (Contrast with Other Methods)
- SEQ*在减少训练参数和时间的同时,与基于参数微调和知识蒸馏的复杂方法相比,取得了竞争性的结果。
- 在某些需要调整类边界的任务中,如实体识别,SEQ*可能不如部分先进方法。
讨论 (Discussion)
局限性:
- 仅研究了分类任务,未探索PLMs在其他形式知识上的遗忘问题。
- 尚未完全理解PLMs在SEQ方法下增量学习知识的机制。
未来方向:
- 设计更具领域特性要求的增量学习任务。 - 开发低成本、高效增量学习算法。
如果需要进一步详细分析某一部分内容,或者帮助整理成其他形式,欢迎告知!
个人总结
Figure 3
文中提到了很多设置和概念,其代表性就是Figure3 , 这也是文中的主要思想之一 ,我们通过理解这张图来理解文中的设置
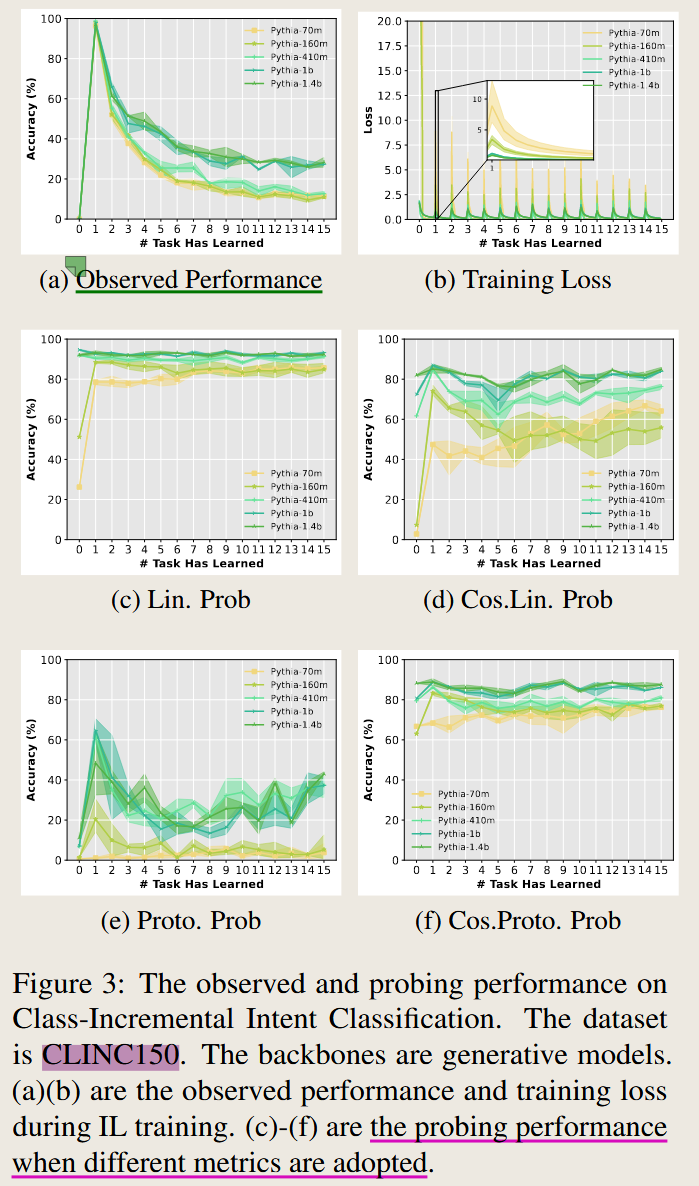
这个图中提到了两个点
第一个是 observed performance and probing performance, 其中 probing performance是作者提出的概念
第二个是 c,d,e,f 使用四种不同的度量方式来描述 probing performace
还有一个点就是 这里还是用了不同的参数量的大模型,从单独一张图中,就可以发现,趋势是类似的,但是模型参数量越大效果总是表现越好。
Figure2 the probing performance
1 observed performance and probing performance
图中使用了图二进行解释 两者的不同, 图如下
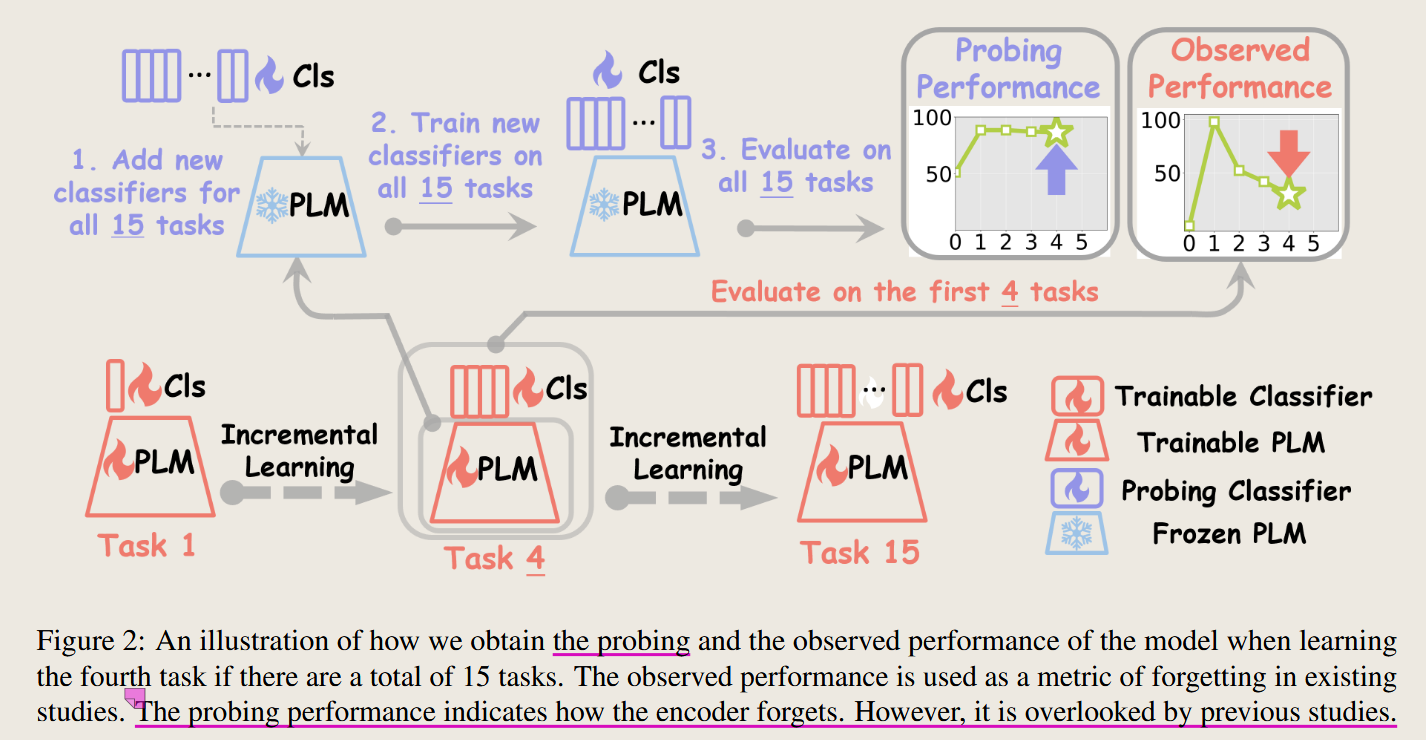
接下来进行对这张图进行解释说明:
要想理解这两者的区别,主要来看作者新设置的这个 Probing Performance 这一部分,
其核心要点有两个
- 固定PLM ,训练一个分类器
- 使用所有任务的数据,来训练和评估这个分类器
这个分类器可以接触到所有任务的数据进行训练,没有涉及到增量学习或者持续学习的设置,这样子做法就类似于continual learning 设置中的 multi-task 设置,可以作为上界。
分类器的直接输入为 PLM 输出的特征向量组成的特征空间$PLM(X)$,这个PLM 又是固定的,所以最终分类结果就只依赖于样本和分类器,而样本是固定的。所以可以设置不同的分类器来探究不同的分类器的分类效果。这也就是是作者在后面提到设置的四种不同分类器:linear probing, cosine linear probing, prototype probing, and cosine prototyping。
另外,由于分类器是一个简单的模型,所以最终实验的效果其实取决于 PLM 的表征能力,如果他能够将不同的类别的输入表征为不同的输出特征,那么一个简单的线性分类器也能够工作地很好。这就说明PLM 有着充分地表征能力,也就可以认为PLM zero shoot 就能做到很好,他在预训练阶段就获得了表征这些新的样本的能力。
而下面的设置就是大家常见的增量学习设置,遇到新的任务就finetuning 大模型以及对应的分类层,根据我们的经验,这会导致灾难性遗忘,也就是随着训练地进行,模型在之前学习过得任务的表现会越来越差。
那么这两个实验就形成了对比,第一个实验效果很好的话,那就说明 大模型有着足够的表征能力,而且只需要一个简单的分类器就能达到很好的效果。那么第二个增量学习效果变差,原因会是什么呢
一个原因就是 训练时候接触到的数据不一样,第一个实验相当于multi-task 的设置,模型能够接触到所有任务的数据。而后面的增量学习,每次就只能接触到每个任务的数据。而这个设置是Continual learning 的必须设定,没法改变。 唯一的从数据的可接触性的突破就是 data/experience replay。
这个设置其实和一般的Continual Learning 的设置也没有区别,这个只能作为upper bound来对比实验结果,而无法采用到continual learning的设置中。但区别就是在于由于大模型的表征能力足够强,实际上在 continual learning 的设置下可以不用再训练大模型这一部分,而是只是每次有一个新任务就训练一个新的分类器就好了。 而作者提出的方法恰好就是这么设置的。
但我有一个问题,如果遇到每次更新都是混合的类别,有没有影响。直接不训练,那么新的分类器是否能够进行分开。但这里不同的类别是什么意思呢,在文本之中的类别的概念。 另外还有一个点就是有了CLIP岂不是也可以直接拿来做图像分类任务。
但是我觉得这两者进行对比有些过于跨越了,其实还可以多设置一个实验,那就是在Incremental-Learning 的时候也不训练PLM,而是直接训练一个分类器,从而通过三者的对比就能更好说明原因。而实际上作者提出的改进方法就是包括这个。 保持原来的PLM不变。
different classifier Performance
接下来详细介绍,作者在探究四种不同的分类器的设置
以下是关于四种分类器的解释:
1. Linear Probing
核心概念:
- 线性探测 (Linear Probing) 是最基本的探测方法,在冻结 PLM 参数的基础上,在其输出特征之上添加一个线性分类器。
实现细节:
分类器的输出 logits $z$ 通过以下公式计算: \(z= W \cdot h\)
- $W$: 线性分类器的权重矩阵。
- $h$: PLM 的隐藏状态(特征)。
- $b$: 偏置向量。 文中说不需要这一项
输出 logits $z$ 决定样本属于每个类别的概率。
优点:
- 线性分类器简单直接,可以充分利用特征的范数(L2 范数)和方向信息。
适用场景:
- 测试隐藏特征是否具有区分类别的能力。
2. Cosine Linear Probing
核心概念:
- 余弦线性探测与线性探测类似,但分类过程中使用余弦相似度代替内积来计算 logits。
实现细节:
logits 的计算公式为: \(z=\text{cos}(W, h) = \frac{W \cdot h}{\|W\| \cdot \|h\|}\)
- $\text{cos}(W, h)$: $W$ 和 $h$ 之间的余弦相似度。
$ W $: 分类器权重的 L2 范数。 $ h $: 隐藏特征的 L2 范数。
优点:
- 通过规范化权重和特征向量,消除了特征范数差异的影响,更关注特征方向与类别中心的对齐情况。
适用场景:
- 避免类别预测偏向范数较大的新类别(解决增量学习中的类不平衡问题)。
局限性:
- 忽略了特征范数的区分能力,可能导致精度下降。
3. Prototype Probing
核心概念:
- 使用每个类别的特征中心作为类别的“原型” (Prototype),通过特征到类别中心的距离计算分类结果。
实现细节:
每个类别 $c$ 的特征中心 $p_c$ 计算如下: \(p_c= \frac{1}{N_c} \sum_{i \in C_c} h_i\)
- $N_c$: 类别 $c$ 的样本数。
- $C_c$: 类别 $c$ 的样本集合。
- $h_i$: 第 $i$ 个样本的隐藏特征。
logits 的计算方式是输入特征 $h$ 与所有类别特征中心的欧几里得距离: \(z= - \|h - p_c\|^2\)
优点:
- 不需要训练额外的分类器,直接使用特征中心作为类别表示。
- 适用于样本分布集中、类别特征具有代表性的场景。
局限性:
- 特征中心的方向可能受数据分布影响,难以充分表达复杂类别边界。
4. Cosine Prototype Probing
核心概念:
- 与 Prototype Probing 类似,但计算 logits 时使用余弦相似度而不是欧几里得距离。
实现细节:
logits 的计算公式为: \(z=\text{cos}(h, p_c) = \frac{h \cdot p_c}{\|h\| \cdot \|p_c\|}\)
- $p_c$: 类别 $c$ 的特征中心。
$ h $, $ p_c $: 特征和特征中心的范数。
优点:
- 通过余弦相似度,消除了范数的影响,更关注特征方向。
- 对于类别特征中心较为分散的场景,能够更稳定地计算相似性。
局限性:
- 忽略了特征范数可能蕴含的类别分布信息。
核心对比表格
| 分类器类型 | 特点 | Logits 计算方式 | 优点 | 局限性 | ||||
|---|---|---|---|---|---|---|---|---|
| Linear Probing | 基于内积,结合特征范数与方向信息 | $W \cdot h + b$ | 简单高效,充分利用特征范数和方向 | 可能受到范数不规范化的影响 | ||||
| Cosine Linear Probing | 基于余弦相似度,忽略特征范数 | $\frac{W \cdot h}{ | W | \cdot | h | }$ | 减少对大范数类别的偏向 | 忽略范数,可能导致精度下降 |
| Prototype Probing | 使用类别特征中心,基于欧几里得距离计算 | $- | h - p_c | ^2$ | 无需训练分类器,简单有效 | 依赖数据分布,难以表达复杂边界 | ||
| Cosine Prototype Probing | 使用类别特征中心,基于余弦相似度计算 | $\frac{h \cdot p_c}{ | h | \cdot | p_c | }$ | 消除范数差异影响,关注特征方向 | 忽略范数对分类可能带来的信息 |
图示说明
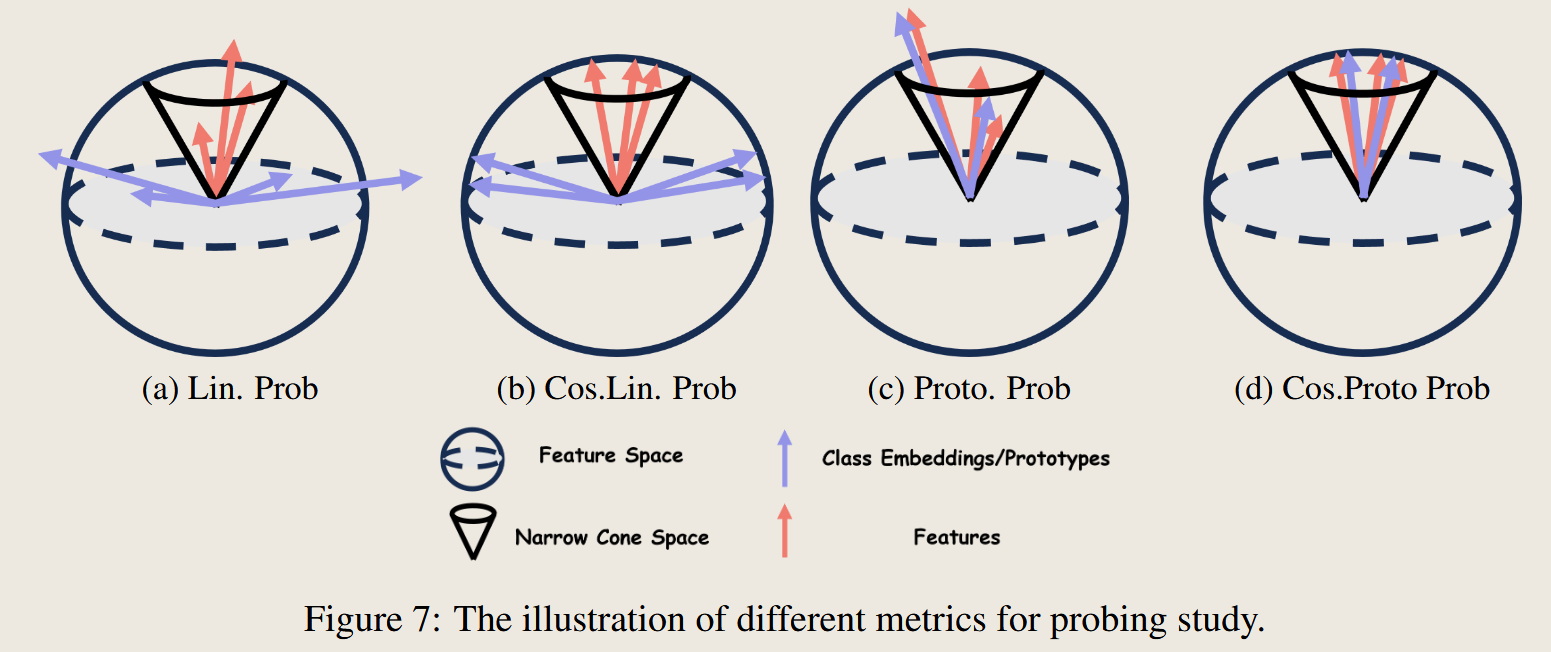
从图中可以看到 使用 cos相似度距离的两种方法,特征向量的长度都进行了归一化,而使用线性和原型方法都没有归一化
另外基于原型的方法,特征向量和 特征距离更加近,作者分析这样会落在一个 narrow corn space之中
效果对比
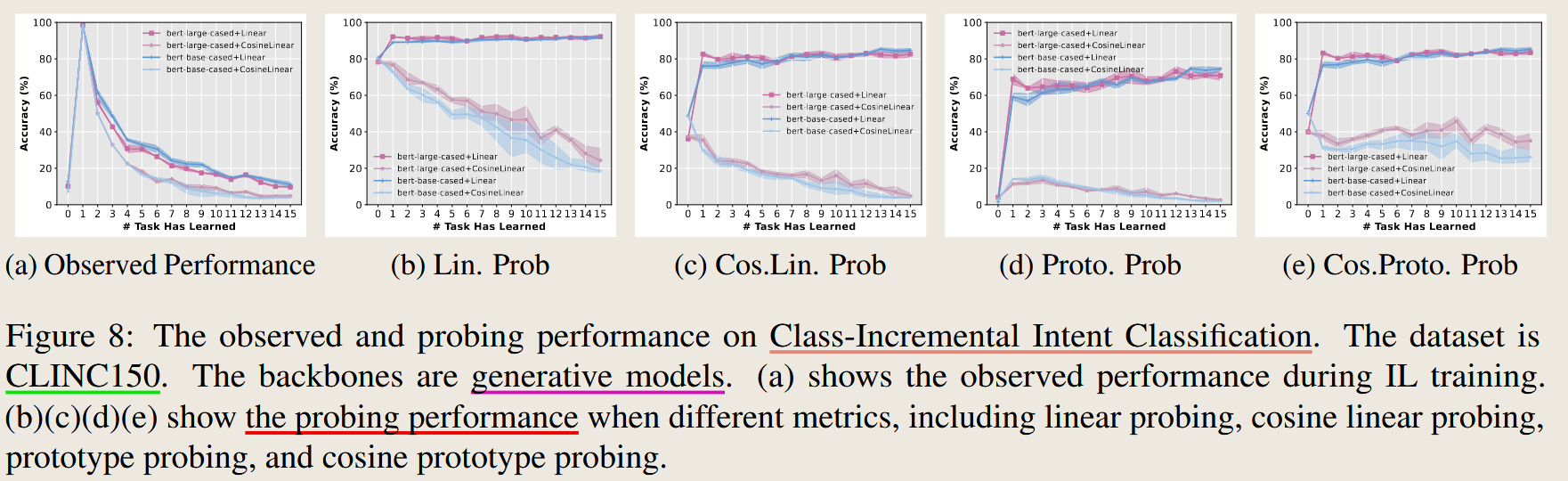
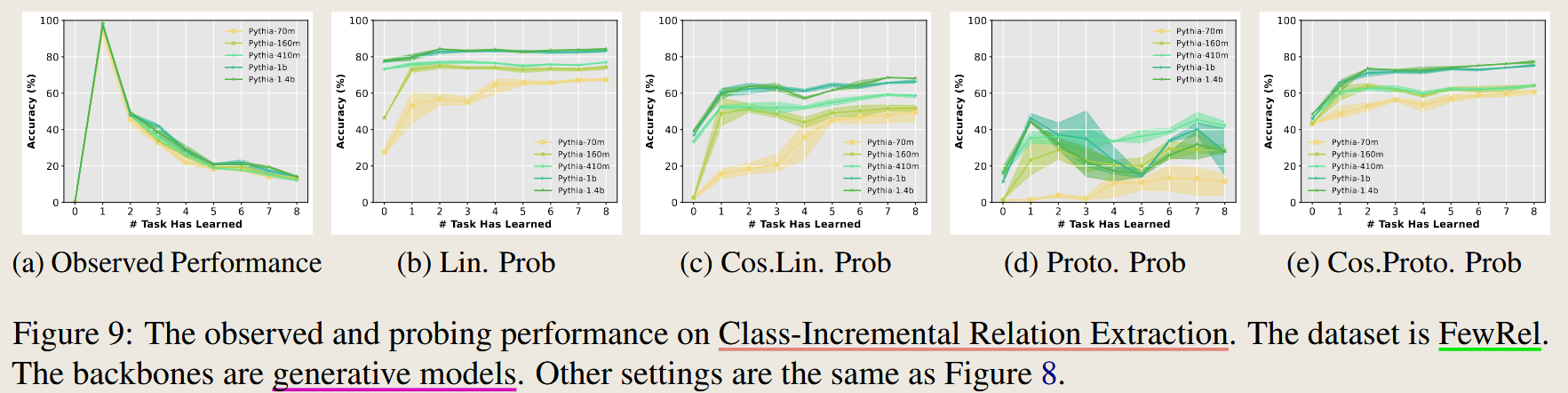
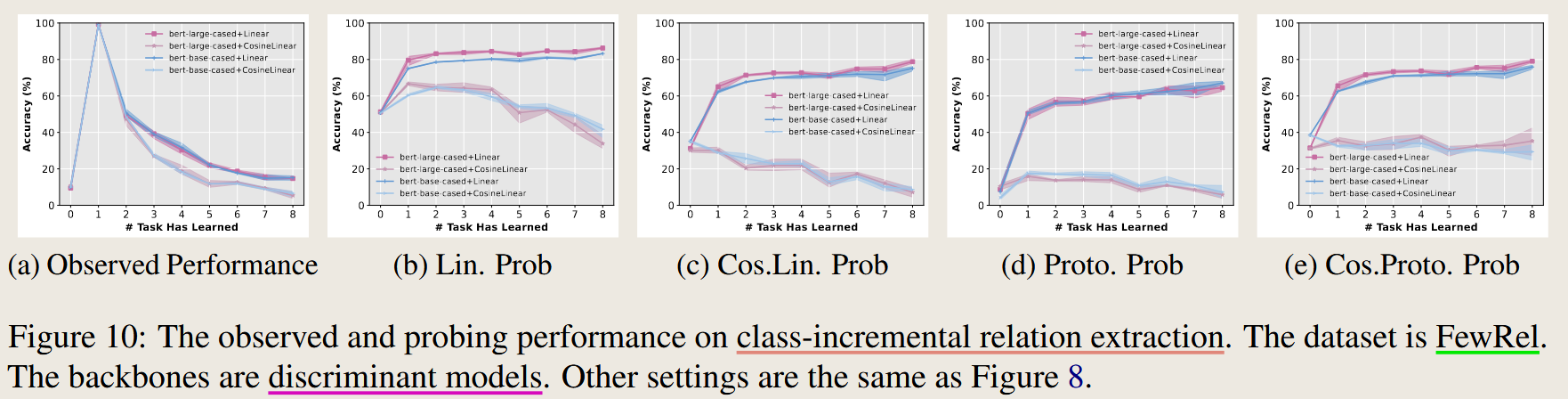

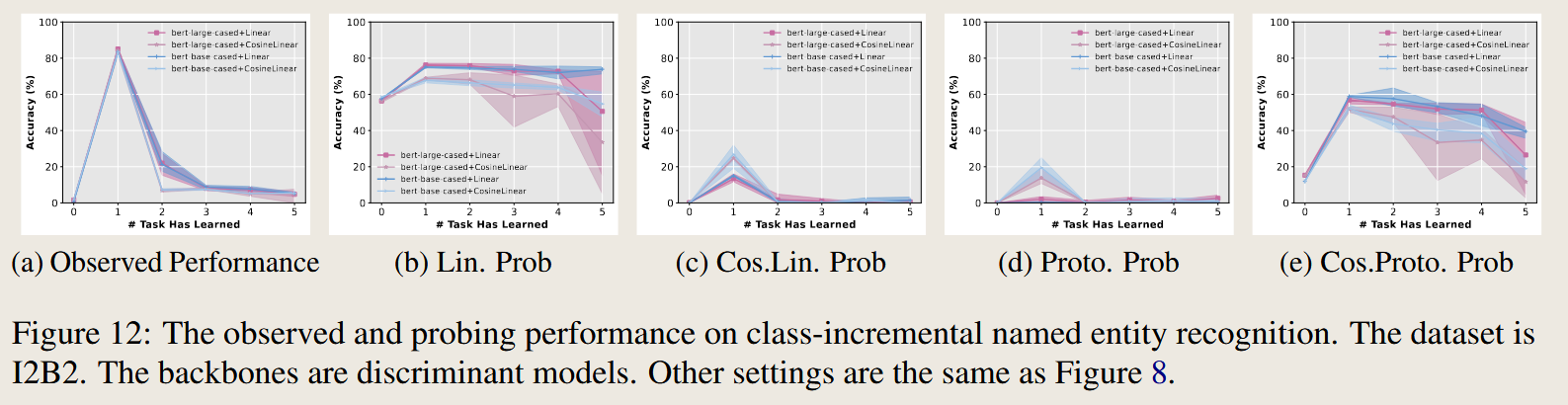
实验设置总结
实验条件与结果概述
| 图编号 | 实验任务 task type | 数据集 dataset | 模型类型 backbone model | 分类器类型 calssifier | 评估指标 |
|---|---|---|---|---|---|
| Figure 8 | 意图分类(Intent Classification) | CLINC150 | Generative Model | Linear, Cosine Linear, Prototype, Cosine Prototype | Accuracy |
| Figure 9 | 关系提取(Relation Extraction) | FewRel | Generative Model | 同上 | Accuracy |
| Figure 10 | 关系提取(Relation Extraction) | FewRel | Discriminative Model | 同上 | Accuracy |
| Figure 11 | 命名实体识别(Named Entity Recognition, NER) | Ontonotes5 | Discriminative Model | 同上 | Accuracy |
| Figure 12 | 命名实体识别(NER) | I2B2 | Discriminative Model | 同上 | Accuracy |
| Figure 13 | 文本分类(Text Classification) | Topic3Datasets | Generative Model | 同上 | Accuracy |
| Figure 14 | 文本分类(Text Classification) | Topic3Datasets | Discriminative Model | 同上 | Accuracy |
对四种分类器效果的对比
以下是基于论文中 Figure 3、Figure 8、Figure 9 和 Figure 10 的实验结果,对四种分类器的效果对比分析,以及作者提出使用 “Use cosine linear classifiers only when no old data is available in a CIL scenario. Otherwise, use linear classifiers” 策略的原因分析。
实验结果分析:四种分类器的效果对比
1. 实验结果中的主要观察
从 Figure 3(Class-Incremental Intent Classification)和 Figure 8, 9, 10(分别对应 CLINC150 和 FewRel 数据集)可以观察到以下现象:
- Linear Probing (线性分类器):
- 在所有实验中,线性分类器的探测性能(Probing Performance)始终高于其他分类器。
- 其在初始任务(Task 1)后表现快速提升,且随着任务数量的增加,其性能几乎保持稳定或略有提升。
- 原因: 线性分类器可以利用特征的方向和范数信息,不受余弦正则化的限制,能够更好地提取特征中的有用信息。
- Cosine Linear Probing (余弦线性分类器):
- 整体表现次于线性分类器,特别是在任务数量较多时,其性能有所下降。
- 其设计消除了特征和权重向量的范数对分类决策的影响,因此在任务数据分布不均匀(例如新任务特征范数较大)的场景中,可以减轻偏向新类的现象。
- 缺点: 忽略了范数可能携带的信息,导致对旧类的区分能力减弱。
- Prototype Probing (原型分类器):
- 基于欧几里得距离的分类器表现低于线性分类器,尤其在任务数量增加后,其性能迅速下降。
- 由于特征中心可能落在分布不均的空间中,类别边界可能不准确,从而降低分类效果。
- 缺点: 对于特征分布复杂的类别,其特征中心无法精确代表类别特性。
- Cosine Prototype Probing (余弦原型分类器):
- 性能高于原型分类器,但低于线性分类器和余弦线性分类器。
- 使用余弦相似度减少了范数的影响,使其在特征分布分散或任务类别较少的情况下有一定优势。
- 缺点: 同样忽略了特征范数可能携带的信息,分类边界可能不够清晰。
2. 实验结果中的分类器排名总结
| 分类器类型 | 性能排名(高到低) | 适用场景 |
|---|---|---|
| Linear Probing | 始终排名第一,性能最稳定 | 任务数据充足或可以保存旧任务数据的场景。 |
| Cosine Linear Probing | 次于线性分类器,但在避免偏向新类方面有优势 | 无法保存旧数据,且需要解决新类偏置问题的场景。 |
| Cosine Prototype Probing | 表现中等,略优于原型分类器 | 特征分布分散但任务复杂度较低时可用。 |
| Prototype Probing | 表现最差,且随着任务增多效果快速下降 | 仅在特征分布较集中的简单任务中可能有效。 |
策略分析:为何选择“Use cosine linear classifiers only when no old data is available in a CIL scenario. Otherwise, use linear classifiers”?
1. 问题背景
CIL 场景的核心挑战:
- 增量学习的类别不平衡问题:新任务类别的样本特征通常具有更大的范数,这会导致线性分类器倾向于预测新类别。
缺乏旧任务数据时,无法通过回放数据缓解这种倾向。
2. 余弦线性分类器的作用
解决新类别偏置问题:
- 通过归一化权重和特征向量(余弦相似度),减少了范数对分类的影响。
在无旧数据时,可以避免分类器过度偏向新类别。
3. 为什么保留线性分类器?
线性分类器的全面性:
- 如果可以访问旧任务数据,线性分类器的表现显著优于其他方法,因为它可以充分利用特征的范数和方向信息。
- 例如,从 Figure 3a 和 Figure 8a 可以看出,当使用线性分类器时,其性能远高于余弦分类器,特别是在有多个任务数据时。
适应更复杂的任务:
- 在任务类别边界复杂或特征分布复杂的情况下,线性分类器可以更灵活地学习类别之间的差异。
4. 综合策略的合理性
- 作者选择的策略充分结合了两种分类器的优势:
- 当无法保存旧数据时,使用 Cosine Linear Probing 减少新类别偏置问题,适配 CIL 场景的约束。
- 当旧数据可用时,使用 Linear Probing 提升整体性能,利用其对特征范数的敏感性。
结论
实验结果表明:
- 线性分类器在性能上表现最佳,但容易受新类样本范数偏大的影响。
- 余弦线性分类器在无旧数据时可以有效避免这种偏置,但性能不及线性分类器。
策略选择的原因:
- 作者的策略合理地结合了两种分类器的优点:用余弦分类器解决数据不平衡问题,用线性分类器最大化性能。
启示:
- 增量学习中的分类器选择需要根据数据保存条件、任务复杂性和类别分布特点灵活调整。
以下是对 Probing Performance 和 Observed Performance 的区别、训练设置的区别以及评估方法的区别的解释,结合论文中的图2和3.1部分内容。
1. 定义及核心区别
Probing Performance
- 定义: 用于评估预训练语言模型(PLM)内部对所有任务的知识保留情况。
- 方法
- 在PLM的固定特征上训练一个探测分类器(Probing Classifier)。
- 探测分类器可以是线性层、余弦线性层或使用类别特征中心的原型分类器。
- 关键点: 探测分类器的训练独立于增量学习的训练过程,因此它表示的是模型隐藏状态中所蕴含的“潜在”知识。
- 作用: 提供PLM的性能上限,当探测分类器能够完全利用隐藏特征时的最优分类性能。
Observed Performance
- 定义: 使用原始模型直接对测试任务进行预测的性能。
- 方法
- 使用增量学习过程中训练好的分类器进行测试。
- 分类器只在学习当前任务时接触过相关数据。
- 关键点: 受灾难性遗忘影响,性能可能因旧任务的知识丢失而下降。
- 作用: 表示增量学习过程中实际的任务表现。
核心区别:
- Probing Performance: 测试隐藏状态的表示能力(理想状态)。
- Observed Performance: 测试实际分类器的能力(实际状态)。
2. 训练设置的区别
Probing Performance 的训练设置
- 模型: PLM的参数被冻结,不会被更新。
- 分类器: 训练一个新的探测分类器,利用所有任务的数据(包括旧任务和新任务)进行训练。
- 数据: 训练时可以访问所有任务的数据,因此不受灾难性遗忘影响。
- 目的: 评估隐藏特征的潜力,避免受到分类器质量的限制。
Observed Performance 的训练设置
- 模型: PLM和分类器参数可以被更新(基于具体方法,例如SEQ或SEQ*)。
- 分类器: 在增量学习过程中只用新任务的数据对当前任务的分类器进行训练。
- 数据: 每次训练时只能访问当前任务的数据,旧任务的数据可能已经丢失。
- 目的: 测量实际增量学习过程中受灾难性遗忘影响的任务性能。
核心区别:
- Probing Performance:冻结模型,仅训练探测分类器,使用所有任务数据。
- Observed Performance:允许更新模型和分类器,受限于增量学习的任务数据。
3. 评估方法的区别
Probing Performance 的评估方法
- 使用探测分类器评估:
- 将所有任务的数据输入冻结的PLM。
- 训练探测分类器预测类别(例如使用线性分类器)。
- 在所有任务的数据上计算准确率。
- 评估重点: 评估PLM的特征是否仍然能够区分所有任务的类别。
Observed Performance 的评估方法
- 使用增量学习过程中训练的分类器:
- 将当前任务数据输入PLM和原始分类器。
- 预测当前任务类别。
- 计算当前任务的准确率(测试数据可能只包含当前任务的数据)。
- 评估重点: 测试增量学习过程中分类器的实际预测能力。
图2 的说明
图2解释了Probing Performance和Observed Performance的计算流程:
- Probing Performance: 使用固定的PLM(不会更新),添加探测分类器后,评估其对所有任务的分类能力。
- Observed Performance: 使用增量学习过程中训练的分类器直接预测,只能测试当前任务,可能会因遗忘而表现较差。
总结
- 核心差异: Probing Performance 测试的是PLM的潜力,Observed Performance 反映实际增量学习的结果。
- 训练设置差异: Probing Performance 冻结PLM且使用所有数据,Observed Performance 根据当前任务更新模型且数据受限。
- 评估方法差异: 前者关注隐藏特征的利用效率,后者关注分类器的实际预测能力。
如果需要更详细的分析或例子,可以进一步展开讨论!
这里的变量作者认为是固定的PLM 还是 动了的PLM , 如果PLM 不动,效果更好,说明PLM 有着充分的能力
补充和说明对图2的认识
图2 的核心内容是通过对比 Observed Performance(观察性能) 和 Probing Performance(探测性能) 的两部分实验,分析 PLMs 在增量学习中的知识保持和遗忘情况。以下是具体说明。
上下两部分实验设置的描述与对比
- 下半部分实验设置:观察性能(Observed Performance)
- 实验设置:
- 直接评估增量学习过程中 PLMs 的性能。
- 每次学习新任务时,模型的分类器仅在当前任务数据上训练。
- 测试阶段,模型直接用更新后的分类器对所有任务进行分类。 - 结果表现:
- 性能随着任务数量增加而显著下降。
- 被用作评估灾难性遗忘的传统指标。 - 关键特点:
- 强调分类器和 PLMs 的联合性能。
- 受限于分类器的设计和数据分布。
- 上半部分实验设置:探测性能(Probing Performance)
- 实验设置:
- 在冻结 PLMs 参数的情况下,为所有任务分别训练新的探测分类器。
- 探测分类器在增量学习所有已学任务的数据上进行训练,测试时对所有任务的分类性能进行评估。 - 结果表现:
- 性能几乎没有显著下降,表明 PLMs 本身保留了绝大部分任务知识。
- 被用作评估 PLMs 的知识保持能力。 - 关键特点:
- 分离了分类器对性能的影响,仅反映 PLMs 的知识保持上限。
- 不受分类器调整策略和数据分布的直接影响。
作者的目的与实验能够说明的问题
目的
- 揭示灾难性遗忘的真实来源:
- 现有假设: 认为灾难性遗忘主要源自 PLMs 对旧任务知识的丢失。
- 作者目的: 验证灾难性遗忘是否源自 PLMs 本身,还是由分类器调整导致。
- 分离 PLMs 和分类器的作用:
- 探测性能评估 PLMs 的表示能力,观察性能评估分类器和 PLMs 的联合表现。
- 通过对比两者,探明 PLMs 和分类器在增量学习中的具体表现差异。
- 优化增量学习策略的设计:
- 如果探测性能高而观察性能低,说明遗忘问题主要集中在分类器上,而非 PLMs。
- 这种情况下,可以优化分类器设计,而无需复杂的 PLMs 调整策略。
实验能够说明的问题
- PLMs 的抗遗忘能力:
- 探测性能几乎不下降,表明 PLMs 在学习新任务时,仍然保留了对旧任务知识的表示能力。
- 说明灾难性遗忘的影响被现有研究夸大,PLMs 在增量学习中实际上具有强大的抗遗忘能力。
- 分类器是遗忘的主要来源:
- 观察性能显著下降,而探测性能保持稳定,表明遗忘问题主要来源于分类器的调整。
- 分类器在增量学习中难以处理新旧任务之间的冲突,导致分类边界偏离。
- 重新评估灾难性遗忘的假设:
- 实验挑战了灾难性遗忘的传统假设,强调分类器设计的重要性。
- 提示研究者需要重新设计和评价增量学习方法,避免过于依赖复杂的 PLMs 调整。
总结
图2 的上下两部分实验通过对比 观察性能 和 探测性能,提供了一种全新的分析视角,将灾难性遗忘的来源明确区分为分类器和 PLMs。作者通过此实验说明,PLMs 本身的知识保持能力远强于传统假设,遗忘问题主要集中在分类器设计上。这一实验为优化增量学习策略提供了直接的理论依据,强调了分类器的关键作用,而非过度调整 PLMs。如果还有未理解的部分,可以进一步探讨实验细节或结果分析!
我的理解:
以下是对图二及相关内容的补充说明与完善,并解答其中没有理解的部分。
对图二的补充说明
- 上下两种样式的对比:
- 上方的方式(Probing Performance)
- 训练方式:固定 PLM(编码器不更新),只训练一个分类头(分类器)来适配所有15个任务。
- 评估方式:分类器针对所有15个任务的样本进行训练和评估,因此能够反映 PLM 的表示能力。 - 下方的方式(Observed Performance)
- 训练方式:在增量学习过程中,PLM 和分类器都会随着新任务的数据进行更新。
- 评估方式:仅在当前任务(如第4个任务)上评估性能,无法完全反映模型是否保留了对所有任务的知识。
- 对比逻辑的关键点:
- 上方方式的目标是测试 PLM 固有的表示能力及其是否保存了所有任务的知识。
- 下方方式则更贴近真实的增量学习场景,强调模型如何在动态更新中保留过去的知识。
- 对比的意义:揭示增量学习中灾难性遗忘的来源是否是 PLM 自身,还是分类器的调整问题。
对对比实验的合理性分析
- 为何上方 Probing Performance 会表现更好?
- 上方方式冻结了 PLM,仅仅训练一个分类头,并在所有任务数据上进行评估。因为 PLM 在整个过程中保持一致,只要分类器能够合理区分15个任务的类别,性能不会显著下降。
- 上面的PLM 是不变的,相当于一直在进行 zero-shoot,探测 PLM 内部是否保留了对所有任务的表示能力。
- 为何下方 Observed Performance 会表现较差?
- 增量学习过程中,PLM 和分类器会因新任务的引入而调整,而这种调整可能会导致对旧任务的知识丢失。
- 评估仅在当前任务上进行,无法体现对旧任务知识的保留情况。
- 添加对比实验:冻结 PLM 的增量学习:
- 你的建议是,在下方的增量学习实验中也固定住 PLM,这样分类器每次训练只针对当前任务的数据。这种情况下,分类器不会受 PLM 表示能力变化的影响。
- 假设:如果 PLM 固定后性能显著提升,则进一步验证了灾难性遗忘主要源于 PLM 的动态调整,而非 PLM 表示能力的本身不足。
图二对比实验的进一步改进建议
为了更全面地验证图二中对灾难性遗忘来源的论断,建议引入以下实验:
- 冻结 PLM 的增量学习:
- 设置:与下方的实验相同,但 PLM 保持冻结,仅更新分类器。
- 意义:将此结果与 Observed Performance 进行对比,分析 PLM 更新是否对遗忘问题造成了显著影响。
- 预期结果:如果性能提升,说明 PLM 的动态更新是遗忘的主要来源;反之则说明分类器调整仍然是关键。
- 固定分类器的增量学习:
- 设置:在增量学习中,固定分类器,而仅更新 PLM。
- 意义:验证分类器的调整是否会导致性能下降,从而进一步分离遗忘的来源。
- 预期结果:如果性能下降,则说明分类器的动态调整确实会对遗忘问题产生显著影响。
- 增量学习与全任务训练的对比:
- 将下方的增量学习结果与上方全任务训练结果(Probing Performance)进行定量对比,分析性能损失的比例,并评估动态学习的影响程度。
结论和理解补充
- 图二的关键点:作者通过对比 Probing Performance 和 Observed Performance,提出了一个重要的观点:PLM 在增量学习中的灾难性遗忘,主要来源于分类器在增量任务中的动态调整,而非 PLM 本身对表示能力的遗忘。
- 实验目的:通过区分 PLM 表示能力和分类器调整的影响,帮助设计更高效的增量学习策略,如冻结 PLM 的 SEQ* 方法。
- 进一步改进:引入“冻结 PLM”的对比实验能够进一步验证这一结论,同时分析 PLM 更新和分类器调整在遗忘中的相对贡献。
如果需要进一步设计具体实验细节或讨论结果,欢迎交流!
Understand the classifier
实验结果
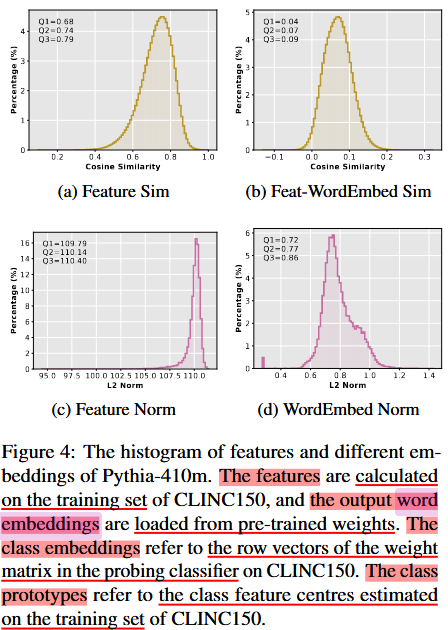
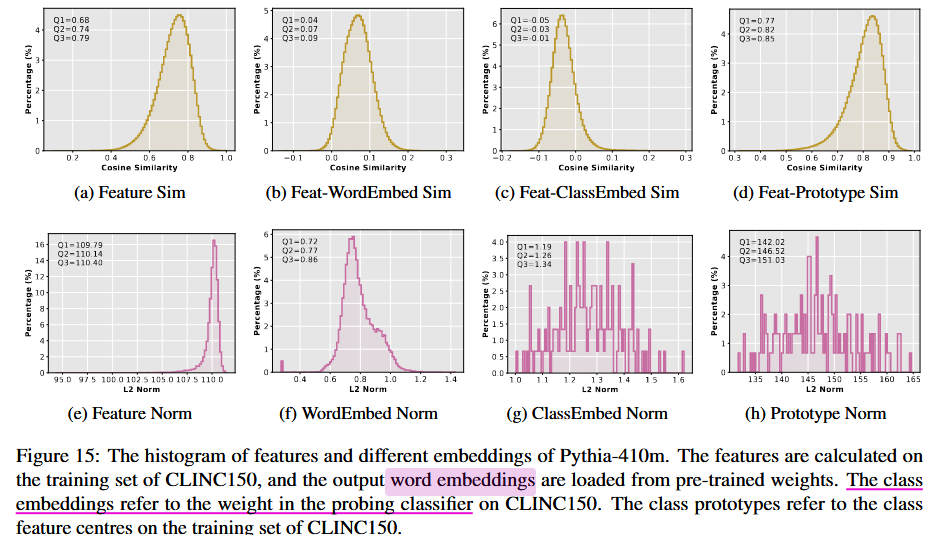
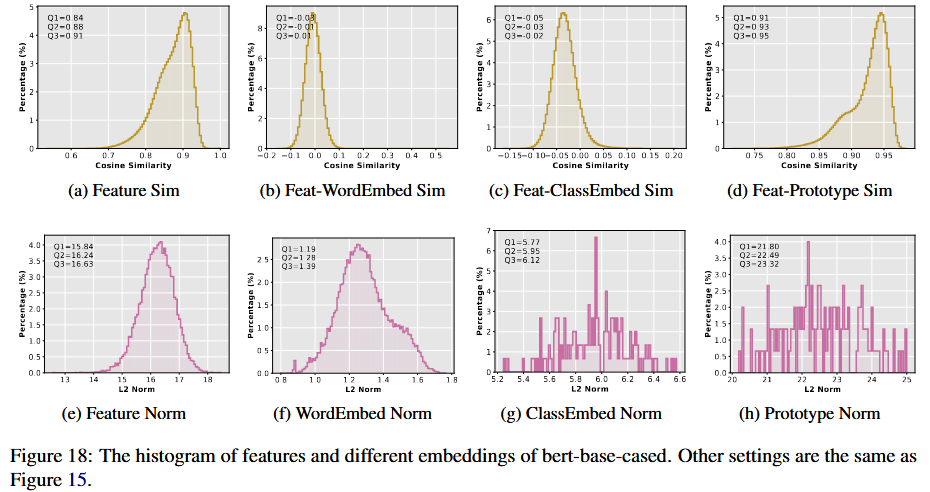
不同 Embedding 的定义
- Features (特征):
- 定义: 这是预训练语言模型 (PLM) 输出的隐藏状态(hidden states)。
- 计算方式: 对于输入样本,通过模型前向传播后,在最后一层提取特定位置的隐藏状态:
- 句子任务: 提取
[CLS]token 的隐藏状态。 - 单词任务: 提取目标单词的隐藏状态。
- 句子任务: 提取
- 用途: 表示输入样本的语义信息,作为分类任务的输入。
- Word Embeddings (词嵌入):
- 定义: 模型词表中的嵌入向量,表示词汇的语义信息。
- 计算方式: 直接从模型的嵌入矩阵中读取(通常是第一层 embedding layer)。
- 用途: 用于模型的初始输入层,将词语转换为向量形式。
- Class Embeddings (类别嵌入):
- 定义: 线性分类器中权重矩阵的行向量。
- 计算方式: 假设线性分类器的权重矩阵为 $W \in \mathbb{R}^{C \times d}$,其中 $C$ 是类别数量,$d$ 是特征的维度。每一行 $W[c] \in \mathbb{R}^d$ 表示类别 $c$ 的向量表示。
示例矩阵划分:
- 假设有 6 个类别 ($C=3$) 和 768 维特征 ($d=768$),权重矩阵为: \(W = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,768} \\ w_{2,1} & w_{2,2} & \cdots & w_{2,768} \\ w_{3,1} & w_{3,2} & \cdots & w_{3,768} \\ \end{bmatrix}\)
- 第一行 $W[1]$ 表示类别1的向量嵌入。
- 第二行 $W[2]$ 表示类别2的向量嵌入。
- 假设有 6 个类别 ($C=3$) 和 768 维特征 ($d=768$),权重矩阵为: \(W = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,768} \\ w_{2,1} & w_{2,2} & \cdots & w_{2,768} \\ w_{3,1} & w_{3,2} & \cdots & w_{3,768} \\ \end{bmatrix}\)
Prototypes (原型嵌入):
- 定义: 每个类别中样本特征的平均向量。
- 计算方式: 对每个类别 $c$,计算该类别所有样本特征的平均值: \(p_c = \frac{1}{N_c} \sum_{i \in C_c} h_i\)
- $N_c$: 类别 $c$ 的样本数量。
- $h_i$: 样本 $i$ 的特征向量。
- 用途: 用于基于特征中心的分类。
2. Cosine Similarity 和 L2-Norm 的计算及意义
计算方式
Cosine Similarity (余弦相似度):
- 公式: \(\text{cos}(x, y) = \frac{x \cdot y}{\|x\| \|y\|}\)
- $x, y$: 两个向量。
- $x \cdot y$: 向量内积。
- $|x|, |y|$: 向量的 L2 范数。
- 在图中的计算:
- Feature 和 Word Embedding: 比较隐藏状态与词嵌入之间的方向相似性。
- Feature 和 Class Embedding: 比较隐藏状态与类别权重向量之间的方向相似性。
- Feature 和 Prototype: 比较隐藏状态与类别特征中心的方向相似性。
- 公式: \(\text{cos}(x, y) = \frac{x \cdot y}{\|x\| \|y\|}\)
L2-Norm (L2 范数):
- 公式: \(\|x\| = \sqrt{\sum_{i=1}^d x_i^2}\)
- $x$: 向量。
- 在图中的计算:
- 每个向量(Feature、Word Embedding、Class Embedding、Prototype)的 L2 范数直接表示向量的大小。
- 公式: \(\|x\| = \sqrt{\sum_{i=1}^d x_i^2}\)
代表的含义
- Cosine Similarity:
- 方向信息: 衡量两个向量在高维空间中的方向是否一致。$\text{cos}(x, y) = 1$ 表示完全一致,$\text{cos}(x, y) = 0$ 表示完全不相关。
- 在实验中的作用:
- 测试隐藏特征是否与类别权重、词嵌入或类别中心对齐。
- 更高的相似度表明特征更倾向于某个类别或词。
- L2-Norm:
- 大小信息: 向量的大小反映了其在特征空间中的强度。
- 在实验中的作用:
- 探索特征向量是否在特定任务中增大或减小。
- 比较特征与词嵌入、类别嵌入之间的范数差异,分析模型训练的效果。
3. 图中结果解读
- Feature 和 Word Embedding:
- Cosine Similarity: 特征与词嵌入的相似度很低(接近正交),表明特征方向经过预训练已经与词嵌入显著分离。
- L2-Norm: Word Embedding 的范数比 Feature 小,这可能是预训练过程中设计的目标(减少词嵌入的权重偏置)。
- Feature 和 Class Embedding:
- Cosine Similarity: 特征与分类权重的相似度也较低,表明分类器可能未充分利用特征方向。
- L2-Norm: Class Embedding 的范数比 Feature 略大,表明分类器在权重训练中倾向于增加范数。
- Feature 和 Prototypes:
- Cosine Similarity: 特征与类别中心的相似度较高,说明特征在一定程度上对类别进行了聚集。
- L2-Norm: Prototypes 的范数最大,表明它们可能代表了更广泛的类别特征。
总结
- Embedding 的定义:
- Feature 表示输入特征,Word Embedding 表示词的初始表示,Class Embedding 表示分类权重向量,Prototype 表示类别特征中心。
- Cosine Similarity 和 L2-Norm:
- Cosine Similarity 衡量方向相似性,L2-Norm 衡量向量强度。
- 在实验中揭示了特征如何与词嵌入、类别权重及类别中心对齐。
- 实验意义:
- 分析特征在分类任务中的对齐程度,揭示了 Linear Probing 优于其他分类器的内在原因。
Feature Sim 详细解释
Feature Sim 并不是同一个样本的特征相似度结果,而是所有样本特征两两之间的相似度分布的结果。 以下是详细的解释:
1. 为什么 Feature Sim 不是 1
如果 Feature Sim 仅计算同一个样本的特征与自身的相似度,那么结果必然是 1,因为: \(\text{cos}(h, h) = \frac{h \cdot h}{\|h\| \cdot \|h\|} = \frac{\|h\|^2}{\|h\|^2} = 1\) 这是因为向量与自身的方向完全一致。
然而,图中的 Feature Sim 并不是针对单个样本的特征与自身的相似度,而是 不同样本的特征两两之间的余弦相似度分布。
2. 如何计算 Feature Sim
Feature Sim 的计算方式是对数据集中所有样本的特征向量 hih_i 和 hjh_j 进行两两组合,计算余弦相似度: \(\text{cos}(h_i, h_j) = \frac{h_i \cdot h_j}{\|h_i\| \|h_j\|}, \quad \forall i \neq j\)
- $h_i, h_j$: 两个不同样本的特征向量。
- 计算结果是一个分布,反映数据集中所有样本特征向量之间的方向关系。
结果不是 1 的原因
- 样本特征向量之间并非完全一致,因此余弦相似度通常小于 1。
- 特征的分布可能受任务或模型的影响。例如:
- 如果特征向量高度聚集在某个方向,相似度分布会较高,接近 1。
- 如果特征向量分布较分散,相似度会较低,甚至接近 0。
3. Feature Sim 分布的意义
- 反映特征的全局分布:
- 如果相似度接近 1,说明特征在向量空间中高度集中,方向差异小。
- 如果相似度较低,说明特征在向量空间中较分散,方向差异大。
- 揭示模型的特征表示能力:
- 高度集中:
- 表明模型可能将特征压缩到一个窄锥形空间(cone of features),如论文中提到的现象。
- 优点:对任务类别有较好的分离能力。
- 缺点:可能限制模型的泛化能力。
- 较为分散:
- 表明模型特征具有较高的多样性。
- 优点:模型可能对复杂任务具有更好的泛化能力。
- 缺点:可能导致类别之间的区分度降低。
- 高度集中:
- 对增量学习的影响:
- 如果特征集中且方向保持一致,增量学习时旧任务特征可能较难被遗忘。
- 如果特征分布分散,新任务可能会覆盖旧任务的特征,从而引发灾难性遗忘。
4. 从图中得出的观察
- 图中的 Feature Sim 分布并不是完全接近 1,主要因为特征向量之间有方向差异。
- 特征的高相似性(分布接近 1) 表明模型在特定任务上提取的特征高度一致,这通常是预训练语言模型的一个特性,尤其是在特定领域的任务中。
- 特征的低相似性(分布偏离 1) 可能表明任务之间的特征分布差异较大,或模型需要区分更多细粒度的类别。
5. 总结
- Feature Sim 计算的是 所有样本之间特征向量的余弦相似度分布,而不是单个样本特征的自相似度。
- 结果不是 1 的原因是样本特征向量之间存在方向差异。
- 这种分布揭示了特征在向量空间中的全局性质,为分析特征的表示能力和增量学习效果提供了直观依据。
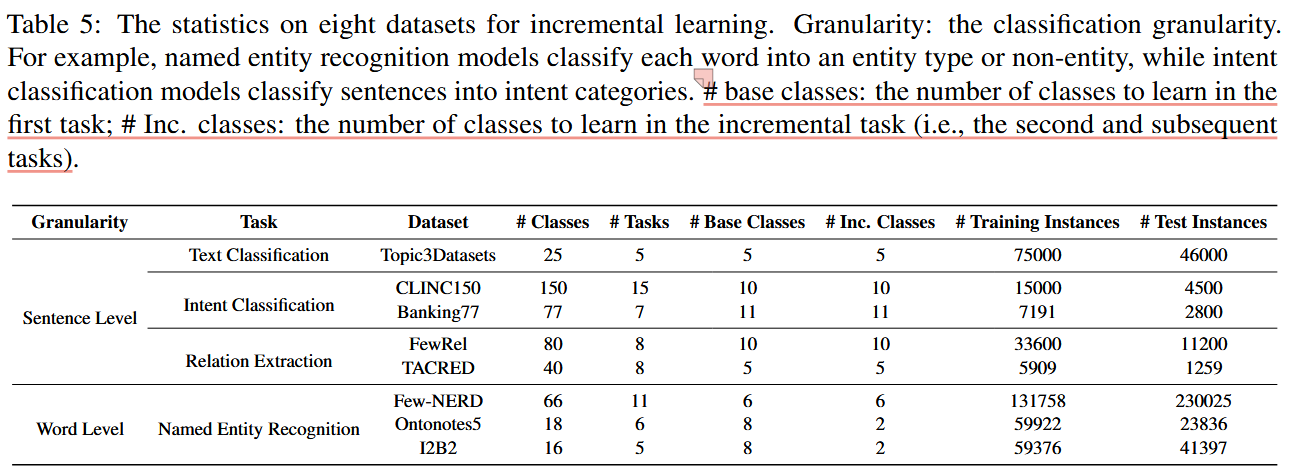
文中使用的任务,数据库,和增量学习过程中的类别设置
数据库介绍
以下是带有原始定义的数据库的详细信息,包括其来源、组织形式、任务领域等。
1. 文本分类(Text Classification)
1.1 Topic3Datasets
- 来源: 由 AGNews、DBPedia 和 Yahoo 三个数据集组成。
- 组织形式:
- AGNews:
- 数据量: 包括 120,000 条训练样本和 7,600 条测试样本。
- 类别: 4 个(World, Sports, Business, Science/Technology)。
- 任务: 对新闻主题分类。
- 来源: 从 AGNews 新闻源获取文本内容。
- DBPedia:
- 数据量: 包括 560,000 条训练样本和 70,000 条测试样本。
- 类别: 14 个(如 Company, Educational Institution, Artist)。
- 任务: 从 DBPedia 提取结构化数据,并将其应用于分类。
- Yahoo:
- 数据量: 包括 140,000 条训练样本和 60,000 条测试样本。
- 类别: 10 个(如 Society/Culture, Education, Health)。
- 任务: 对用户在 Yahoo Answers 上提出的问题进行分类。
- AGNews:
- 任务领域: 新闻分类、知识库分类、用户问题分类。
- 目标: 对不同领域文本进行主题分类。
2. 意图分类(Intent Classification)
2.1 CLINC150
- 来源: CLINC AI 实验室。
- 组织形式:
- 数据量: 包括 15,000 条训练数据,4,500 条测试数据。
- 类别: 150 个(如 “余额查询”,“航班预订”,“天气信息”)。
- 任务: 识别用户在对话系统中的意图。
- 任务领域: 对话系统中的意图识别。
- 目标: 提高人机交互的准确性,优化用户体验。
2.2 Banking77
- 来源: 银行业相关应用数据。
- 组织形式:
- 数据量: 包括 7,191 条训练样本和 2,800 条测试样本。
- 类别: 77 个(如 “转账失败”,“账户冻结”)。
- 任务: 识别银行领域的用户意图。
- 任务领域: 金融领域对话中的意图分类。
- 目标: 提供更精确的银行客户服务。
3. 关系抽取(Relation Extraction)
3.1 FewRel
- 来源: 清华大学 NLP 组。
- 组织形式:
- 数据量: 包括 80 个类别,每类 700 条训练样本,100 条测试样本。
- 类别: 关系类型(如 “位于”,“创立者”,“产品”)。
- 任务: 从句子中抽取实体之间的关系。
- 任务领域: 知识图谱构建、信息抽取。
- 目标: 自动化生成结构化关系数据。
3.2 TACRED
- 来源: 斯坦福大学 NLP 小组。
- 组织形式:
- 数据量: 包括 106,264 条句子,每条句子带有关系标签。
- 类别: 40 个(如 “机构-创立者”,“人员-雇主”)。
- 任务: 提取句子中两个标注实体的关系。
- 任务领域: 信息抽取。
- 目标: 提高自动化信息系统的关系识别能力。
4. 命名实体识别(Named Entity Recognition, NER)
4.1 Few-NERD
- 来源: 清华大学 Few-Shot NER 数据集。
- 组织形式:
- 数据量: 66 个实体类别(如 “地名”,“企业”),包括细粒度实体类别。
- 数据形式: 使用 BIO 格式标注。
- 任务: 从句子中标注实体。
- 任务领域: 实体识别、知识图谱扩展。
- 目标: 支持少样本学习下的命名实体识别。
4.2 OntoNotes5
- 来源: OntoNotes 项目,由多个机构合作开发。
- 组织形式:
- 数据量: 包括 59922 条训练样本,23836 条测试样本。
- 类别: 18 个实体类型(如 “人名”,“地名”,“机构名”)。
- 数据形式: 涵盖新闻、网络评论、对话等多种语料。
- 任务领域: 广义的命名实体识别。
- 目标: 提供多领域、多语言的标注数据。
4.3 I2B2
- 来源: I2B2 (Informatics for Integrating Biology & the Bedside) 项目。
- 组织形式:
- 数据量: 59376 条训练样本,41397 条测试样本。
- 类别: 医学实体类型(如“疾病名称”,“药物名称”)。
- 数据形式: 医学记录文本。
- 任务领域: 医学文本的实体识别。
- 目标: 支持医学知识的提取和应用。
总结表
| 数据集 | 任务领域 | 类别数量 | 数据量 | 目标 | 来源 |
|---|---|---|---|---|---|
| AGNews | 新闻分类 | 4 | 120,000+7,600 | 新闻主题分类 | 新闻源 |
| DBPedia | 知识库分类 | 14 | 560,000+70,000 | 结构化知识分类 | DBPedia 知识库 |
| Yahoo | 用户问题分类 | 10 | 140,000+60,000 | 用户提问分类 | Yahoo Answers |
| CLINC150 | 对话意图分类 | 150 | 15,000+4,500 | 优化对话系统 | CLINC AI 实验室 |
| Banking77 | 金融意图分类 | 77 | 7,191+2,800 | 银行业对话分类 | 银行业应用 |
| FewRel | 关系抽取 | 80 | 每类 700+100 | 实体关系抽取 | 清华大学 NLP 组 |
| TACRED | 关系抽取 | 40 | 106,264 | 高精度关系分类 | 斯坦福 NLP 组 |
| Few-NERD | 实体识别 | 66 | 不详 | 少样本实体识别 | 清华大学 Few-Shot 项目 |
| OntoNotes5 | 广义实体识别 | 18 | 59,922+23,836 | 多领域实体标注 | OntoNotes 项目 |
| I2B2 | 医学实体识别 | 16 | 59,376+41,397 | 医学文本标注 | I2B2 项目 |
如果需要更具体的某个数据集的分析或详细信息,请继续提出!
文中的增量学习设置
更加详细的代码实现
Topic3Datasets 数据集分类与划分的实现过程
1. 数据来源与总体设置
Topic3Datasets 由 AGNews、DBPedia 和 Yahoo 数据集组成,用于文本分类任务。在增量学习中,该数据集被划分为 5 个任务,每个任务包含 5 个类别,共 25 个类别。
2. 数据集类别的来源与处理
2.1 类别的来源
- AGNews: 包含 4 个类别,原始类别是:
- World, Sports, Business, Science/Technology。
- DBPedia: 包含 14 个类别,原始类别是:
- Company, Educational Institution, Artist, Athlete, Office Holder, Mean Of Transportation, Building, Natural Place, Village, Animal, Plant, Album, Film, Written Work。
- Yahoo: 包含 10 个类别,原始类别是:
- Society & Culture, Science & Mathematics, Health, Education, Computers & Internet, Sports, Business & Finance, Entertainment & Music, Family & Relationships, Politics & Government。
2.2 类别筛选与清理
文中提到,部分类别存在重叠或意义模糊,为保证类别的独立性,作者对类别进行了筛选:
- 从 Yahoo 中移除了以下类别:
- Sports, Business & Finance, Science & Mathematics(因为这些类别与 AGNews 类别重叠)。
- 剩余的类别和 AGNews、DBPedia 的类别共同构成 25 个类别。
2.3 类别语义化处理
- 对生成式模型,部分类别名称被重命名为更直观的语义表达:
- 如 “Sci/Tech” 被替换为 “Science and Technology”。
- “EducationalInstitution” 被替换为 “Educational Institution”。
- 类别名称的语义化处理在代码中通过字符串替换实现【33†source】。
3. 数据的增量学习划分
3.1 划分规则
在代码中,数据集的类别被划分为 5 个任务,每个任务包含 5 个类别:
- 25 个类别按任务顺序分配,每个任务的类别集合为:
- 任务 1: 类别 1 至 5。
- 任务 2: 类别 6 至 10。
- 任务 3: 类别 11 至 15。
- 任务 4: 类别 16 至 20。
- 任务 5: 类别 21 至 25。
划分逻辑通过以下代码实现:
NUM_TASK = 5
NUM_CLASS = 25
continual_config = {
'CUR_CLASS': [list(range(task_id * (NUM_CLASS // NUM_TASK), (task_id + 1) * (NUM_CLASS // NUM_TASK))) for task_id in range(NUM_TASK)]
}
3.2 数据划分
在每个任务中:
- 每个类别分配固定数量的训练和测试样本:
- 训练集:每个类别 3,000 条。
- 测试集:每个类别 2,000 条。
- 数据集样本按随机种子打乱,确保划分一致性。
代码实现:
def preprocess_topic3datasets(num_sample_train_per_class=3000, num_sample_test_per_class=2000):
# 遍历子数据集
for subdataset in subdataset_list:
# 加载类别信息
with open(os.path.join(src_path, subdataset, 'classes.txt')) as f:
for line in f.readlines():
_label = line.strip()
# 移除 Yahoo 中的重叠类别
if subdataset == 'yahoo' and _label in ['Sports', 'Business & Finance', 'Science & Mathematics']:
continue
label2idx[_label] = global_cnt
global_cnt += 1
# 加载训练集
for i, row in df.iterrows():
if _tmp_label_idx not in subdatasets_label_idx[subdataset]:
continue
train_x.append(input_text)
train_y.append(label2idx[_label])
# 类别下采样
if num_sample_train_per_class != -1:
for _label_idx in set(train_y):
_class_sample_idx = np.where(np.array(train_y) == _label_idx)[0]
random.shuffle(_class_sample_idx)
train_x = [train_x[_i] for _i in _select_idx_all]
train_y = [train_y[_i] for _i in _select_idx_all]
4. 增量学习过程
增量学习过程依次加载各个任务的数据:
每次仅加载当前任务的类别数据,并将其添加到模型中。
模型在任务间累积类别,但训练时仅能访问当前任务的数据。
数据存储结构示例:
{ "task_0": { "train": { "input": ["文本1", "文本2"], "target": ["类别1", "类别2"], "label_idx_cil": [0, 1] } }, "task_1": { ... }, ... }
5. 总结
类别来源: 通过筛选 AGNews、DBPedia 和 Yahoo 的类别,共生成 25 个类别。
数据划分: 每个任务引入 5 个类别,每个类别包含固定数量的训练和测试实例。
实现细节
:
- 使用随机种子和下采样确保每个任务的数据一致性。
- 将类别按任务顺序分配,逐步引入新类别。
如果需要更具体的某部分代码解析或逻辑说明,请随时告知!
代码解析:Topic3Datasets 增量学习的分类与划分实现
以下是对 preprocess_topic3datasets 函数的逐步解析,解释如何对 Topic3Datasets 数据集进行分类和增量学习划分。
1. 数据集来源与结构
1.1 数据来源
Topic3Datasets 包含三个子数据集:
- AGNews: 新闻分类任务,包含类别如
World,Sports,Business,Science/Technology。 - DBPedia: 知识库分类任务,包含类别如
Company,Educational Institution,Artist。 - Yahoo: 用户问题分类任务,包含类别如
Society/Culture,Health,Politics/Government。
1.2 数据集文件结构
每个子数据集包含以下文件:
classes.txt: 定义数据集中的类别名称。train.csv和test.csv: 包含输入文本及其对应的类别标签。
2. 类别的清理与处理
2.1 清理重叠类别
- 从 Yahoo 数据集中移除与 AGNews 重叠的类别:
Sports,Business & Finance,Science & Mathematics。
- 目的是避免类别间语义重叠。
2.2 类别语义化
为生成式模型重命名类别,例如:
Sci/Tech→Science and Technology。EducationalInstitution→Educational Institution。
代码实现:
if _label == 'Sci/Tech': _label = 'Science and Technology' elif _label == 'EducationalInstitution': _label = 'Educational Institution'
2.3 类别索引的生成
每个类别被赋予一个全局唯一索引
label2idx。idx2label用于反向映射索引到类别名称。实现:
subdatasets_label_list[subdataset].append(_label) subdatasets_label_idx[subdataset].append(_cnt) label2idx[_label] = global_cnt global_cnt += 1
3. 数据划分与预处理
3.1 数据划分
每个子数据集中的样本按照类别读取,并分为训练集、验证集、测试集。
输入文本处理:
对于 Yahoo 数据集,拼接多个字段作为输入:
input_text = '%s %s %s' % (row[1], row[2], row[3])对于 AGNews 和 DBPedia 数据集:
input_text = '%s %s' % (row[1], row[2])
3.2 类别下采样
限制每个类别的样本数量,避免类别不平衡:
if num_sample_train_per_class != -1: for _label_idx in set(train_y): _class_sample_idx = np.where(np.array(train_y) == _label_idx)[0] random.shuffle(_class_sample_idx) _select_idx_all.extend(_class_sample_idx[:num_sample_train_per_class])
3.3 类别顺序的随机化
打乱类别的顺序,确保实验的一致性:
shuffle_class_order = list(range(NUM_CLASS)) random.shuffle(shuffle_class_order) train_y_all = [shuffle_class_order[_y] for _y in train_y_all]
4. 增量学习任务划分
4.1 划分规则
数据集被划分为 5 个任务,每个任务包含 5 个类别。
每个任务中仅引入当前任务的类别,任务间类别不重叠。
实现:
NUM_TASK = 5 continual_config = { 'CUR_CLASS': [ list(range(task_id * (NUM_CLASS // NUM_TASK), (task_id + 1) * (NUM_CLASS // NUM_TASK))) for task_id in range(NUM_TASK) ] }
4.2 数据组织
每个任务的数据包括:
- 输入文本(
input) - 类别标签索引(
label_idx_cil和label_idx_til)
- 输入文本(
数据结构:
"task_0": { "train": { "input": ["文本1", "文本2"], "target": ["类别1", "类别2"], "label_idx_cil": [0, 1] }, "test": { "input": ["文本3", "文本4"], "target": ["类别1", "类别2"], "label_idx_cil": [0, 1] } }
5. 数据存储
最终的处理结果保存为
continual_data.json和
continual_config.json:
continual_data.json: 每个任务的训练、验证、测试数据。continual_config.json: 包含任务和类别信息。
保存代码:
with open(os.path.join(tgt_path, 'continual_data.json'), 'w') as f: json.dump(continual_data, f) with open(os.path.join(tgt_path, 'continual_config.json'), 'w') as f: json.dump(continual_config, f)
6. 总结
- 类别来源与清理:
- 合并 AGNews、DBPedia、Yahoo 的类别,移除重叠类别。
- 类别语义化处理提高了生成式模型的适配性。
- 数据划分与预处理:
- 按任务逐步引入新类别,每个任务的类别不重叠。
- 通过下采样和平衡类别分布,确保数据质量。
- 增量学习实现:
- 数据以任务为单位存储,任务间类别独立。
- 实验结果的随机性通过固定类别顺序实现一致性。
如果您需要更具体的实现细节或其他部分的代码解析,请告诉我!
PLM 预训练过程 中不同 checkpoint 对应的模型的表现
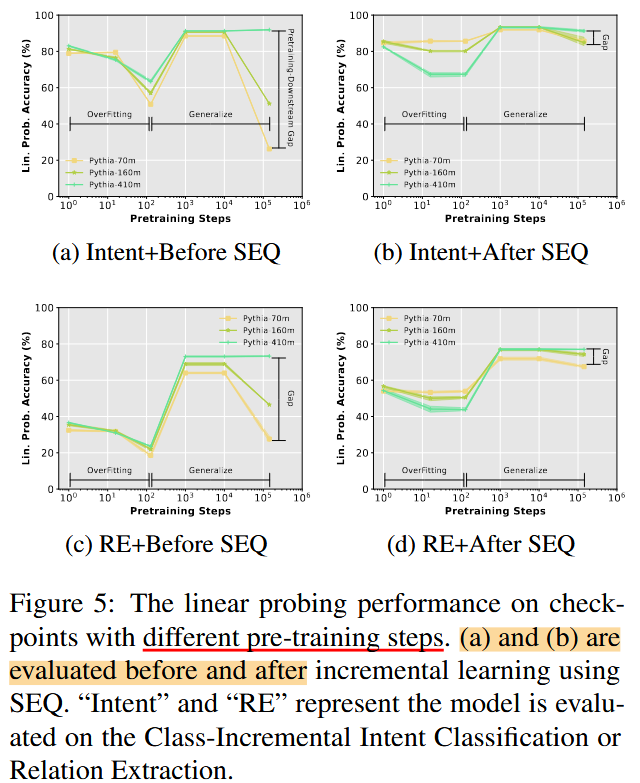
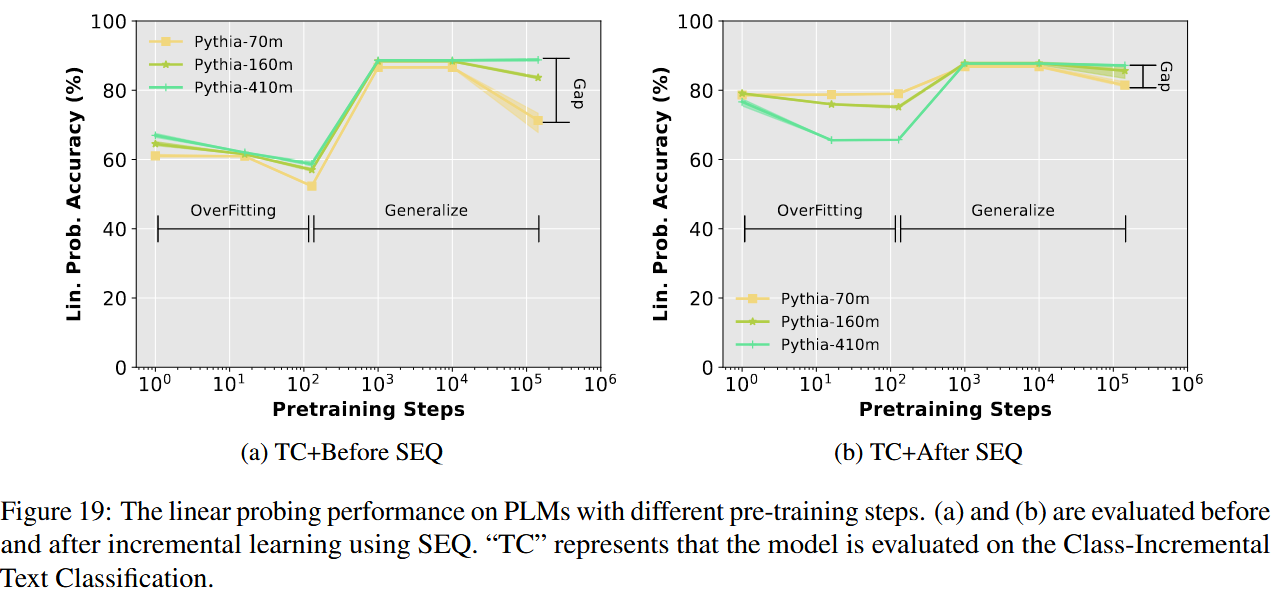
文中通过之前的 probing 的实验表明, 预训练大模型有着充足的能力和知识储备来直接进行下游任务,那么作者想要进一步探究,这个能力或者说是知识是在大模型的预训练过程逐渐积累的吗?
所以作者直接加载了在预训练过程不同阶段的预训练模型,然后对这些模型也进行 SEQ ,然后查看前后效果对比。
令人惊奇的是,即使是随机初始化的大模型,也能够在下游任务做得很好,很神奇。
而且总体来说,这些预训练阶段的模型在 SEQ 之后,都能达到很好的效果。
但就按着表现来看,第一个阶段是训练一段时间的大模型效果反而不如随机初始化的效果,并且表现还越越差。
但好在,随着训练的进行,效果逐渐得到了提高。
然后效果进入了瓶颈,最后又出现了下降。作者认为这一阶段的下降是由于预训练阶段的文本和下游任务的数据的差异造成的,然后通过SEQ,能够显著减小这个间隔。
Figure 5 的实验设置与线性探测性能的评估
1. 实验的目标
Figure 5 的实验目标是研究在增量学习前后,模型对所有任务的类别表示能力是否发生了变化。具体而言,作者通过对 Before SEQ 和 After SEQ 的线性探测性能(Linear Probing Performance)进行比较,探讨预训练模型在增量学习过程中对知识的保留和适应能力。
2. SEQ 的含义
在论文中,SEQ 是指 Sequential Fine-Tuning,即在增量学习过程中,模型被逐步微调:
- 具体含义:
- 每次只在当前任务的数据上对模型进行微调,更新大语言模型(PLM)的参数和分类器的权重。
- 模拟增量学习的真实场景,新任务引入时旧任务数据不可见。
- 实验目的:
- SEQ 作为一种基准方法,用于衡量灾难性遗忘(Catastrophic Forgetting)对模型表示能力的影响。
3. Before SEQ 和 After SEQ 的线性探测性能
3.1 Before SEQ 的探测性能
- 定义: 在模型未经历 SEQ 微调之前,探测预训练模型的潜在表示能力。
- 实现方式:
- 冻结主干模型:
- 预训练的大语言模型(如 Pythia-410m)参数被冻结。
- 确保隐藏特征不受增量学习的影响。
- 训练线性探测分类器:
- 使用冻结的隐藏特征,在所有任务数据上重新训练一个线性分类器(Linear Classifier)。
- 分类器的训练覆盖所有类别,评估隐藏特征对每个类别的表示能力。
- 计算性能:
- 在所有任务的测试数据上,使用训练好的线性分类器进行评估,记录线性探测的分类准确率。
- 冻结主干模型:
- 实验目的:
- 测试预训练模型对任务类别的潜在表示能力,作为后续增量学习的基准。
3.2 After SEQ 的探测性能
- 定义: 在模型经历 SEQ 微调后,重新探测其潜在表示能力。
- 实现方式:
- 冻结微调后的主干模型:
- SEQ 微调后的主干模型被完全冻结,隐藏特征反映增量学习后模型的表示能力。
- 训练线性探测分类器:
- 同样使用冻结特征,在所有任务数据上重新训练一个新的线性分类器。
- 覆盖所有类别,重新评估隐藏特征对每个类别的表示能力。
- 计算性能:
- 评估线性分类器在所有任务上的测试性能,记录探测准确率。
- 冻结微调后的主干模型:
- 实验目的:
- 测试微调后的模型是否仍然保留了对旧任务类别的表示能力。
4. Probing Performance 与 SEQ 的关系
- Probing Performance 能接触所有数据:
- 线性探测性能是通过冻结模型特征后重新训练分类器实现的,分类器训练时可以使用所有任务的数据。
- 因此,Probing Performance 能反映模型隐藏特征的潜在表示能力,是一个“理想状态”的上限。
- 为什么提到 SEQ:
- 实验的关键在于对比 Before SEQ 和 After SEQ 的线性探测性能。
- Before SEQ 探测的是预训练模型的潜在能力,而 After SEQ 探测的是经过 SEQ 微调后,隐藏特征是否发生变化。
- SEQ 是否微调了大模型:
- 是的,在 SEQ 中,大语言模型的参数是更新的。模型会在当前任务的数据上进行微调,从而可能导致隐藏特征的分布发生变化。
- 因此,After SEQ 的线性探测性能能够反映微调过程中隐藏特征是否发生了灾难性遗忘。
5. 实验结论(结合 Figure 5)
- Before SEQ 的线性探测性能:
- 表现出模型预训练特征的强大能力,说明模型能够很好地表示所有任务的类别。
- After SEQ 的线性探测性能:
- 即使在 SEQ 微调后,隐藏特征仍然保留了对旧任务的良好表示能力。
- 遗忘的主要来源并非隐藏特征的丢失,而是分类器权重的偏移。
6. 总结
Before SEQ 的探测性能: 基于冻结的预训练特征,探测模型在所有任务上的潜在表示能力。
After SEQ 的探测性能: 基于冻结的微调特征,探测模型在 SEQ 微调后对所有任务类别的潜在表示能力。
Probing Performance 与 SEQ 的关系
:
- Probing Performance 测试模型潜在能力,但 SEQ 微调可能导致隐藏特征分布的变化,从而影响探测性能。
实验结论: 即使在 SEQ 微调后,隐藏特征的潜在表示能力几乎不受影响,遗忘的主要原因在于分类器的更新偏移,而非特征表示的丧失。
为什么最开始的随机初始化大模型就能做到很好的效果
作者进一步探究了,为什么最开始的随机初始化大模型就能做到很好的效果,作者使用tsne进行了可视化。


可以看到 SEQ 增大了不同类别的区分度。 pretraining 也增大了不同类别的区分度。
当随机初始化大模型,然后经过SEQ之后,模型也能对不同类别的大部分内容进行区分。作者认为这是由于 transformer的结构导致的。
综合上面两点,结论就是 transformer 和预训练都影响了PLM的能力。
讨论 SEQ 过程 中,效果下降,是由于什么呢
首先 在SEQ的过程中,新出现的类别有着更大的logit ,那么原因会是什么呢,由于最后是一个简单的线性层,$y= W \cdot h$
所以结果要不然就是新出现的类别的类embdding$W[C]$更大,
要不然就是 新的类别的特征向量和对应的类embdding(就是分类器矩阵对应的那一行)相似度更高,既即$W[C] \cdot h$的值更大。
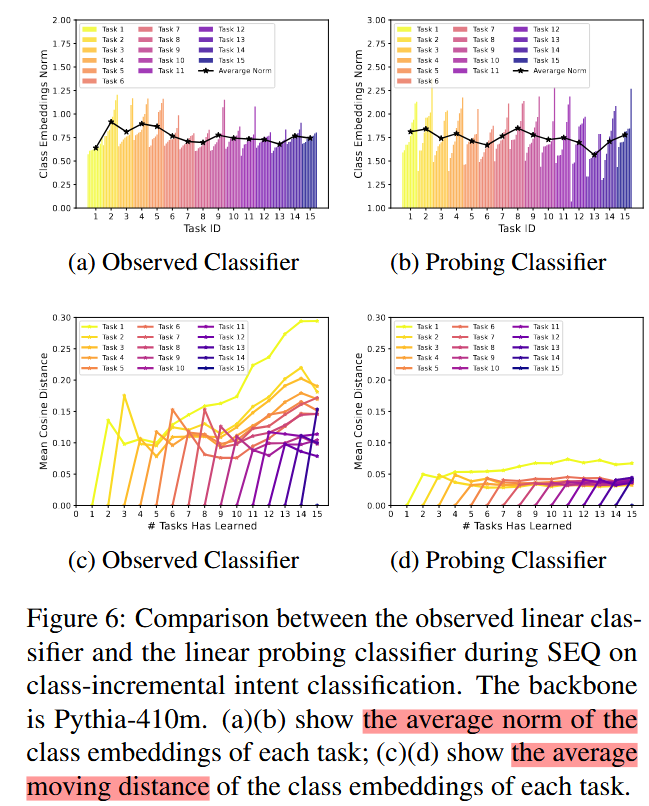
实验设置与主要区别
1. 实验目标
图6、图22、图23、图24的实验旨在研究:
- 观察分类器(Observed Classifier)与探测分类器(Probing Classifier)在SEQ增量学习后性能的差异。
- 探索遗忘的根本原因是隐藏特征(Features)的丢失还是分类器(Classifiers)的偏移。
2. 实验设置
实验数据:
- 采用类增量意图分类任务(CLINC150 数据集)。
- 每个任务引入新类别,同时冻结已有任务的数据。
模型:
- 使用
Pythia-410m作为主干模型,分别结合线性分类器(Linear Classifier)与余弦线性分类器(Cosine Linear Classifier)。
- 使用
分类器设置:
观察分类器(Observed Classifier)
:
- 在SEQ增量学习过程中直接更新。
- 每次只训练当前任务的类别,不使用旧类别数据。
探测分类器(Probing Classifier)
:
- 在SEQ后重新训练,使用冻结的特征。
- 在所有任务的类别上重新训练,旨在衡量隐藏特征的表达能力【60†source】【63†source】。
评估指标:
- 类嵌入的范数变化(Class Embedding Norm)。
- 类嵌入的偏移距离(Moving Distance)。
- 特征与类嵌入的余弦相似度(Cosine Similarity)。
3. 差异点:观察分类器与探测分类器的区别
- 训练数据:
- 观察分类器:仅基于当前任务的类别数据训练。
- 探测分类器:基于所有任务的类别数据重新训练,反映模型的真实特征表达能力。
- 特征冻结:
- 观察分类器:特征随着增量任务更新。
- 探测分类器:特征在训练过程中完全冻结【60†source】【62†source】【63†source】。
- 目标差异:
- 观察分类器:模拟真实增量学习场景,记录实际性能。
- 探测分类器:分析特征是否遗忘,获得潜在的表示上限。
总结
- 主要区别:
- 观察分类器反映了在真实SEQ增量学习中的分类性能,而探测分类器旨在研究特征是否被遗忘。
- 实验结论:
- 遗忘的根本原因是分类器嵌入的偏移,而非隐藏特征的丢失。
- 探测分类器的表现表明隐藏特征具有强大的抗遗忘能力,问题主要出现在分类器的参数偏移上。
如果需要进一步深入某部分代码的解析或对某一实验图表的具体讨论,请随时告知!
移动距离计算方法是图6d等实验中的核心内容,用于衡量类别嵌入在特征空间中的变化。以下是对移动距离计算的详细解释,结合图标、附录F.3中的公式,以及代码的具体实现进行说明。
1. 移动距离的定义与公式
1.1 移动距离的目标
- 目标: 衡量类嵌入(Class Embeddings)在训练过程中相对于初始位置的偏移程度。
- 意义: 如果某个类别的嵌入位置发生显著变化,说明分类器对该类别的表示发生了遗忘。
1.2 移动距离的公式
根据附录F.3的描述:
计算类别嵌入在任务
tt
完成时的位置:
Ctt=cosine_similarity(class_embedding,feature_center)C^t_t = \text{cosine_similarity}(\text{class_embedding}, \text{feature_center})
- CttC^t_t: 任务 tt 完成时,类别嵌入与对应特征中心之间的余弦相似度矩阵。
计算任务 t+kt+k 完成后,同一类别嵌入与所有特征中心的余弦相似度: Ct+kt=cosine_similarity(class_embedding,feature_center)C^t_{t+k} = \text{cosine_similarity}(\text{class_embedding}, \text{feature_center})
移动距离定义为余弦相似度矩阵的平均绝对差异:
Moving_Distance=1n∑i,j∣Ctt[i,j]−Ct+kt[i,j]∣\text{Moving_Distance} = \frac{1}{n} \sum_{i,j} C^t_t[i,j] - C^t_{t+k}[i,j] - i,ji, j 分别是类别索引和特征中心索引。
- nn 是矩阵中的元素总数。
2. Probing Classifier 中的移动距离计算
2.1 Probing Classifier 的特点
- 探测分类器(Probing Classifier)可以访问所有任务的数据,基于冻结的特征重新训练。
- 类别嵌入由所有任务的类别数据计算,因此能够提供类嵌入的“理想位置”。
2.2 计算过程
在探测分类器的上下文中,计算步骤如下:
初始化类嵌入:
根据任务
tt
的数据计算类特征中心,作为类别嵌入:
class_embeddingi=1Ni∑x∈classifeature(x)\text{class_embedding}i = \frac{1}{N_i} \sum{x \in \text{class}_i} \text{feature}(x)
- NiN_i: 类别 ii 的样本数。
- feature(x)\text{feature}(x): 样本 xx 的隐藏特征。
计算初始相似度矩阵 CttC^t_t:
- 使用冻结的特征和类别嵌入计算任务 tt 完成时的相似度: Ctt[i,j]=class_embeddingi⋅feature_centerj∥class_embeddingi∥∥feature_centerj∥C^t_t[i, j] = \frac{\text{class_embedding}_i \cdot \text{feature_center}_j}{|\text{class_embedding}_i| |\text{feature_center}_j|}
计算任务 t+kt+k 的相似度矩阵 Ct+ktC^t_{t+k}:
- 类似步骤2,使用任务 t+kt+k 的数据重新计算类别嵌入和特征中心。
计算移动距离:
- 对 CttC^t_t 和 Ct+ktC^t_{t+k} 的差异取绝对值并平均,得到移动距离。
3. 移动距离计算的代码实现
在 probing.py 文件中,以下代码段用于实现移动距离的计算【63†source】:
特征提取与嵌入初始化:
for t_id in range(num_task): train_features = obtain_features(...) class_center = compute_class_center(train_features, ...)计算相似度矩阵:
cosine_similarity_matrix_t = cosine_similarity(class_embedding, feature_center_t) cosine_similarity_matrix_tk = cosine_similarity(class_embedding, feature_center_tk)计算移动距离:
moving_distance = torch.abs(cosine_similarity_matrix_t - cosine_similarity_matrix_tk).mean()
4. 实验中探测分类器与观察分类器的区别
- 观察分类器:
- 类嵌入在增量学习过程中不断更新。
- 使用的类嵌入仅基于当前任务的数据训练,因此更容易发生偏移。
- 探测分类器:
- 类嵌入使用所有任务数据重新训练,反映特征的潜在能力。
- 类嵌入位置更加稳定,因此移动距离更小。
5. 总结
移动距离的定义
:
- 衡量类嵌入相对初始位置的偏移程度。
- 使用余弦相似度矩阵的变化计算。
探测分类器的优势
:
- 由于访问了所有任务的数据,其类嵌入更加准确,移动距离较小。
代码实现
:
- 关键步骤包括特征提取、相似度矩阵计算和差异分析。
如果需要更详细的代码解析或实验设计讨论,请继续提出!
在增量学习中,Observed Classifier 的训练过程中仅接触当前任务的数据,这并不是固定之前分类器参数的结果,而是源于 增量学习方法(如SEQ) 的特点。以下是结合代码对这种现象的详细说明。
1. Observed Classifier 在增量学习中的工作方式
1.1 Observed Classifier 的训练特点
- Observed Classifier 的核心是在当前任务中只训练当前任务类别的数据,而不再优化或冻结旧类别的嵌入。
- 在代码实现中,当处理新的任务时:
- 新任务的类别权重会被更新。
- 旧任务的类别权重保持在上一任务结束时的状态,但由于缺少旧类别样本,其分布可能不再适配新的特征分布。
1.2 Observed Classifier 的参数不固定
分类器权重会继续更新
:
- 虽然没有访问旧类别的数据,但模型仍在增量训练过程中对所有权重进行优化,这会导致旧类别嵌入在优化过程中发生变化。
特征稳定但嵌入偏移
:
- 主干模型(Backbone)是冻结的,隐藏特征保持稳定。
- 分类器的嵌入权重可能发生调整,从而导致旧类别嵌入与特征不再匹配。
2. 结合代码说明 Observed Classifier 的行为
2.1 分类器的训练代码
在 evaluation.py 和 probing.py 中,Observed Classifier 的训练通过以下逻辑实现【62†source】【63†source】:
# 分类器的训练(当前任务)
for lm_input in train_loader_list[current_task_id]:
extracted_features = obtain_features(params=params,
model=model,
lm_input=lm_input,
tokenizer=tokenizer)
logits = classifier(extracted_features) # 分类器计算 logits
loss = loss_function(logits, lm_input['label_idx_cil'])
optimizer.zero_grad()
loss.backward()
optimizer.step()
逻辑说明
:
classifier是一个多任务分类器,包含所有类别的嵌入权重。train_loader_list[current_task_id]中仅包含当前任务的新类别数据,因此优化过程中只强化新类别的嵌入。- 旧类别的数据不参与训练,因此旧类别嵌入的位置不会直接被优化。
2.2 权重的变化
从代码可以看出:
- 新类别的嵌入权重会被更新:
- 通过当前任务数据的梯度更新,优化新类别的分类边界。
- 旧类别的嵌入权重也可能发生变化:
- 虽然没有直接优化旧类别,但整体优化过程中可能调整所有嵌入权重,导致旧类别的嵌入位置发生偏移。
3. 为什么旧类别嵌入会偏移?
3.1 参数更新的全局性
- 在训练新类别时,分类器的所有权重(包括旧类别嵌入)都会受到梯度更新的影响。
- 即使旧类别的数据未参与优化,但分类器作为一个整体,梯度更新会导致所有权重向新的任务分布调整。
3.2 特征分布的变化
- 新类别数据的引入可能会改变特征分布,从而影响分类器对旧类别嵌入的适配性:
- 假设特征分布从任务 tt 到任务 t+1t+1 发生变化,旧类别的嵌入未能及时调整以匹配新的分布,导致嵌入的偏移。
3.3 类间竞争
- 新任务类别和旧任务类别之间的分类边界可能重叠。
- 在增量训练过程中,优化新类别的分类边界可能会影响旧类别的分类器权重,从而导致嵌入偏移。
4. Observed Classifier 的嵌入偏移问题示例
假设有三个任务,分别包含以下类别:
- 任务 1:类别 A、B。
- 任务 2:类别 C、D。
- 任务 3:类别 E、F。
任务 1 后的分类器嵌入
- 通过类别 A、B 的数据训练,得到 A 和 B 的嵌入:
- WA,WBW_A, W_B 是分类器权重。
任务 2 训练时
- 分类器通过类别 C、D 的数据优化权重,更新了 WC,WDW_C, W_D。
- WA,WBW_A, W_B 可能未被直接优化,但由于全局权重更新,它们的位置也可能被影响。
任务 3 训练时
- 类别 E、F 的数据进一步更新分类器权重:
- WA,WBW_A, W_B 和 WC,WDW_C, W_D 的位置可能继续偏移,导致与特征不再对齐。
5. 解决嵌入偏移问题的思路
- 冻结旧类别嵌入:
- 通过冻结旧类别的权重,避免新任务训练时对其产生干扰。
- 引入记忆缓冲区:
- 保存部分旧类别的数据,参与训练,优化旧类别的嵌入位置。
- 正则化方法:
- 添加正则化约束,限制旧类别嵌入的偏移。
6. 总结
Observed Classifier 的嵌入偏移问题源于:
- 分类器权重的全局优化:新类别的训练目标可能间接调整旧类别的嵌入。
- 缺乏旧类别数据:没有旧类别样本的参与,分类器无法优化旧类别的权重以适配新的特征分布。
- 特征分布变化与类间竞争:新类别的引入改变了特征分布,增加了类间的竞争。
因此,尽管 Backbone 是冻结的,但 Observed Classifier 的权重仍然可能发生偏移,导致嵌入与特征不再匹配。解决这一问题的关键是引入适当的约束或数据增强机制。
9 作者提出方法 SEQ*
经过上面讨论,我们得出两点结论
首先,大模型在SEQ中不需要更新,其次,之前学习好的分类器也要冻结下来,这也就是作者后面提出的思路 ,然后通过上述多种分类器的对比,使用好的分类器,这就是作者的思路
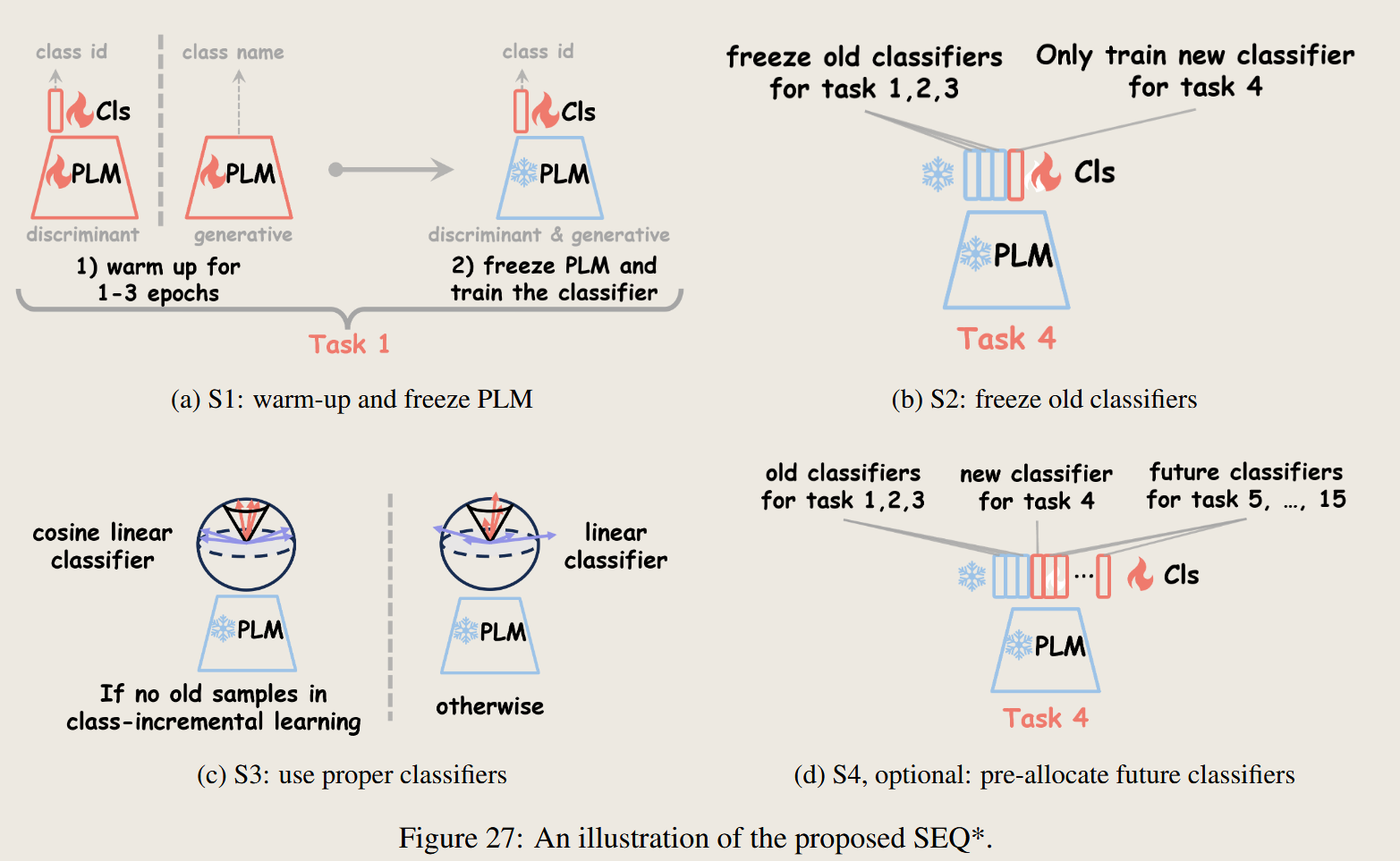
有一个问题就是 这里作者提到了 warm up 这一部分论文中也没有过多提及,而且 warmup只在最开始的任务进行,我有些怀疑这个作用
SEQ* 实验结果
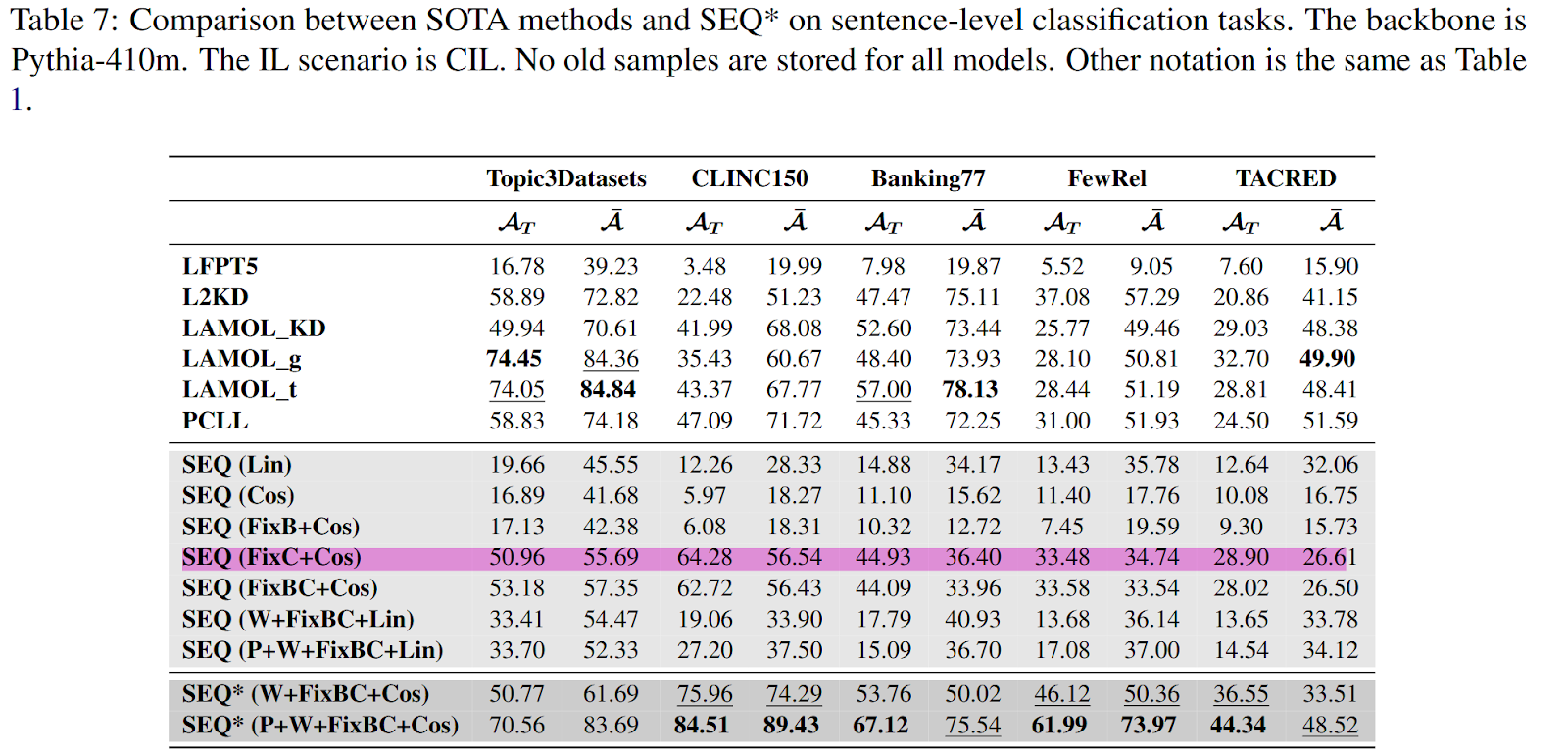
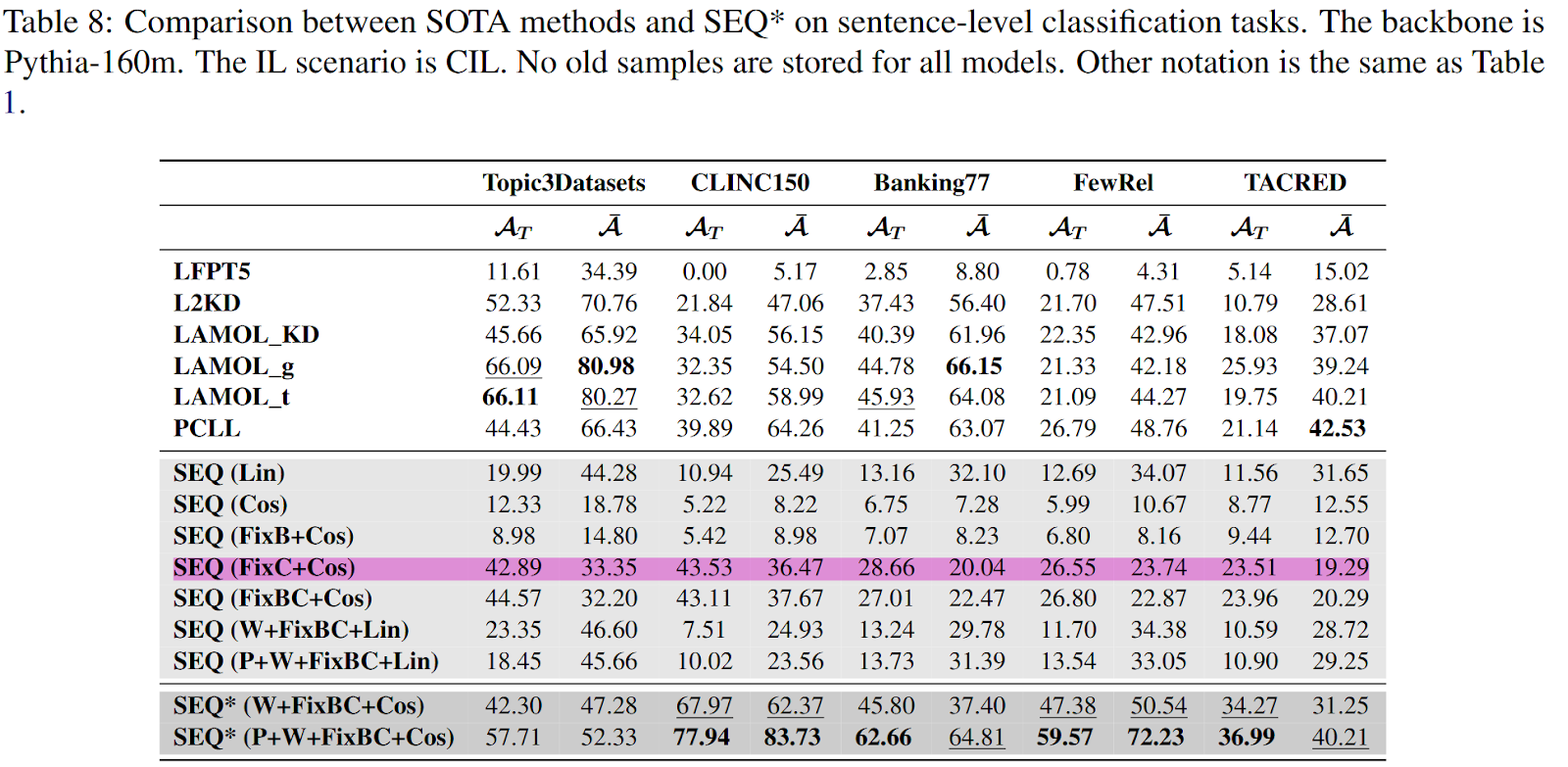
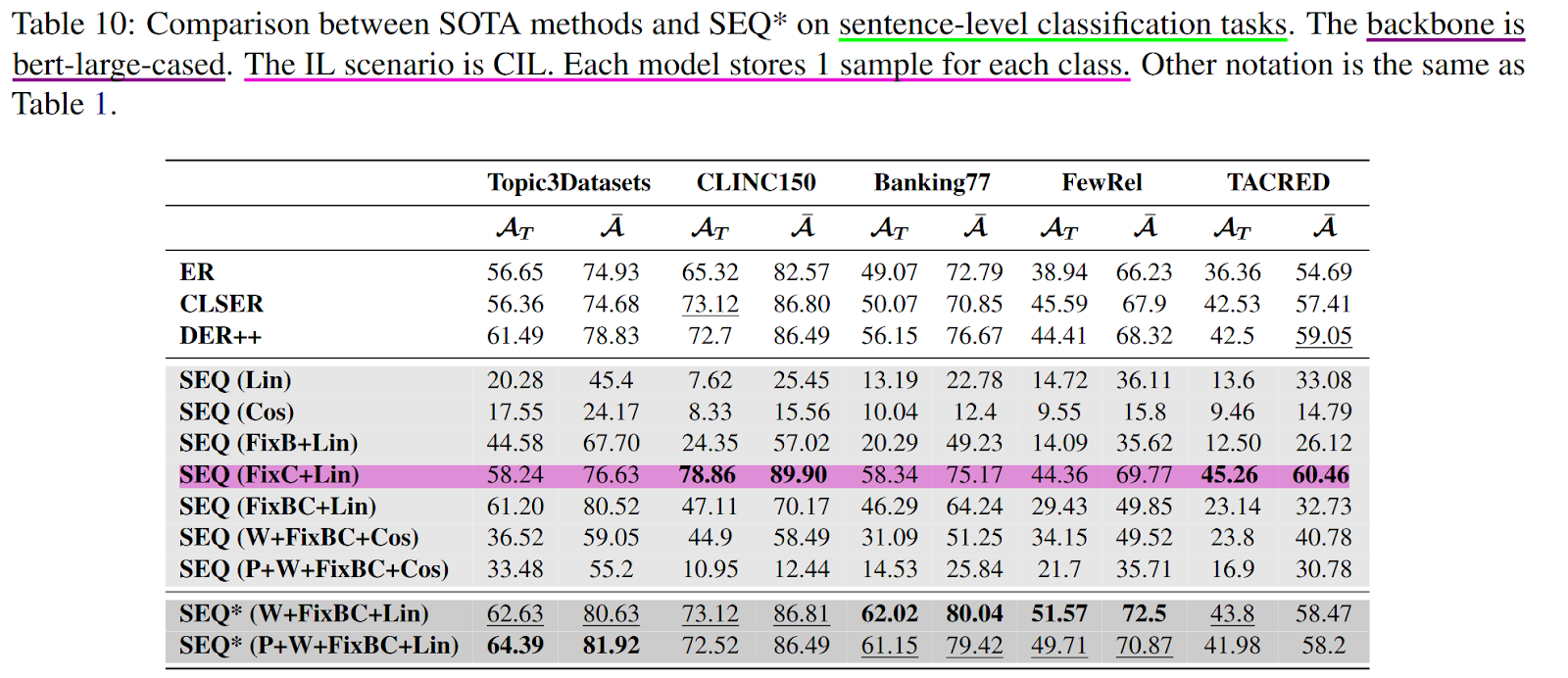
FixC+Cos 就很好了
在附录 I 的 Table 7、8、10 和 11 中,SEQ (FixC+Cos) 方法在许多任务中取得了显著效果,并且在多个指标上表现出最高得分。这种优异性能的原因可以从以下几个方面进行分析:
1. SEQ (FixC+Cos) 方法的核心特点
FixC(冻结旧任务分类器权重):
原理
:
- 在增量学习过程中,冻结旧任务的分类器权重,避免新任务训练对旧任务类别嵌入的干扰。
- 确保旧类别的嵌入和类别边界保持稳定。
效果
:
- 降低旧任务类别嵌入发生偏移的风险,从而缓解灾难性遗忘问题。
Cosine Similarity Classifier:
原理
:
- 使用余弦相似度代替内积计算 logits,规范化了嵌入和特征向量的范数。
- 余弦相似度只关注向量的方向,而不受范数的影响。
效果
:
- 避免新任务类别嵌入范数增大的问题,从而减少对旧任务类别的不公平竞争。
- 更好地维持类间表示的平衡性。
2. SEQ (FixC+Cos) 带来显著效果的原因
2.1 冻结旧任务分类器的稳定性
- 在增量学习过程中,旧任务的类别嵌入经常受到新任务优化的干扰,导致嵌入偏移。
- FixC 通过冻结旧任务的分类器权重,避免新任务对旧类别嵌入的负面影响:
- 旧类别嵌入保持稳定,与其对应的特征分布一致。
- 分类器的类别边界更加稳定,从而减少旧任务的遗忘。
2.2 余弦相似度的优势
- 余弦相似度消除了新任务类别嵌入范数增大的影响:
- 增量学习中,新任务类别往往由于优化目标的不同,嵌入范数显著增大,导致分类器更倾向于新任务类别。
- 余弦相似度只关注方向,避免范数的影响,从而平衡新旧任务类别的竞争。
2.3 新旧任务之间的平衡
- FixC 确保了旧任务嵌入的稳定性,而 Cosine Classifier 解决了新任务的范数偏置问题。
- 这两者结合,在模型表示和分类器权重优化之间达到了一个良好的平衡。
2.4 特征的潜在能力
- 论文的分析表明,预训练语言模型的隐藏特征具有很强的潜在表示能力。
- FixC+Cos 的策略确保分类器更好地利用这些隐藏特征,而不会因为增量学习引发过多的遗忘。
3. 表现优异的具体原因
结合附录 I 的 Table 7、8、10 和 11 的具体实验结果,可以总结以下几点:
3.1 SEQ (FixC+Cos) 对旧任务的保护
- FixC 冻结了旧任务分类器,减少了灾难性遗忘。
- 余弦相似度进一步平衡了类间竞争,旧任务类别在测试中的表现更加稳定。
3.2 SEQ (FixC+Cos) 对新任务的适应
- 余弦相似度在处理新任务类别时,不会受到新类别范数增大的影响。
- 新任务的分类性能得到了提升,同时对旧任务的负面影响被最小化。
3.3 增量学习任务的特性
- 在 CLINC150 等任务中,类别间的语义距离较大,分类器的稳定性尤为重要。
- SEQ (FixC+Cos) 的策略很好地平衡了表示能力和分类性能,特别是在类别间分布差异较大的数据集上表现出色。
4. 其他对比方法的局限性
相比其他方法,SEQ (FixC+Cos) 的优势主要体现在以下方面:
4.1 SEQ 方法中的问题
- 原始 SEQ 方法没有固定旧任务分类器,因此旧类别嵌入容易偏移,导致灾难性遗忘。
- 使用普通线性分类器时,新任务类别范数增大,进一步加剧了类间竞争的不公平性。
4.2 没有 FixC 的 Cosine Classifier
- 如果没有 FixC,虽然余弦相似度能够平衡范数,但新任务的优化仍可能对旧任务嵌入造成干扰。
4.3 线性分类器的劣势
- 普通线性分类器对范数敏感,无法处理新旧类别之间的竞争问题。
5. 总结
SEQ (FixC+Cos) 在实验中的显著效果来源于以下几点:
FixC 冻结旧任务分类器,保护旧类别嵌入的稳定性。
Cosine Classifier 平衡了新旧任务之间的类间竞争,避免了新类别范数增大的影响。
分类器与特征的结合
:
- FixC+Cos 的组合有效利用了预训练模型的隐藏特征潜力,同时解决了分类器优化中的偏置问题。
这一方法在灾难性遗忘和新任务适应之间找到了良好的平衡点,因此在多个增量学习任务上表现优异。如果需要进一步分析实验结果或表格,请随时告知!
思考 能够将这个方法应用到 IR
首先,IR 一般没有明确的类别标签,动态文档库是按着时间戳不断进来的,而不是典型的增量学习方法。 如果按着时间戳划分任务(新文档、旧文档),那么新旧文档就同时包含一些旧的类别和新的类别,但这个场景确实更符合现实应用。
那么如果直接应用这个方法,会不会也起到一定效果呢? 直接莽一发
MSMARCO 数据集是有着query的 type 的,所以可以query的type 来进行划分为不同的类别,进行持续学习设置
另外这里的文本的类别是不是太宽泛了,
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/01/06/Paper-Reading-Note-16-LLM-fintuning-and-forgetting-2-SEQ/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)