Paper Reading 16 LLM finetuning and forgetting - 3 Experiment Explore
EFFECT OF MODEL AND PRETRAINING SCALE ON CATASTROPHIC FORGETTING IN NEURAL NETWORKS
EFFECT OF MODEL AND PRETRAINING SCALE ON CATASTROPHIC FORGETTING IN NEURAL NETWORKS
2022
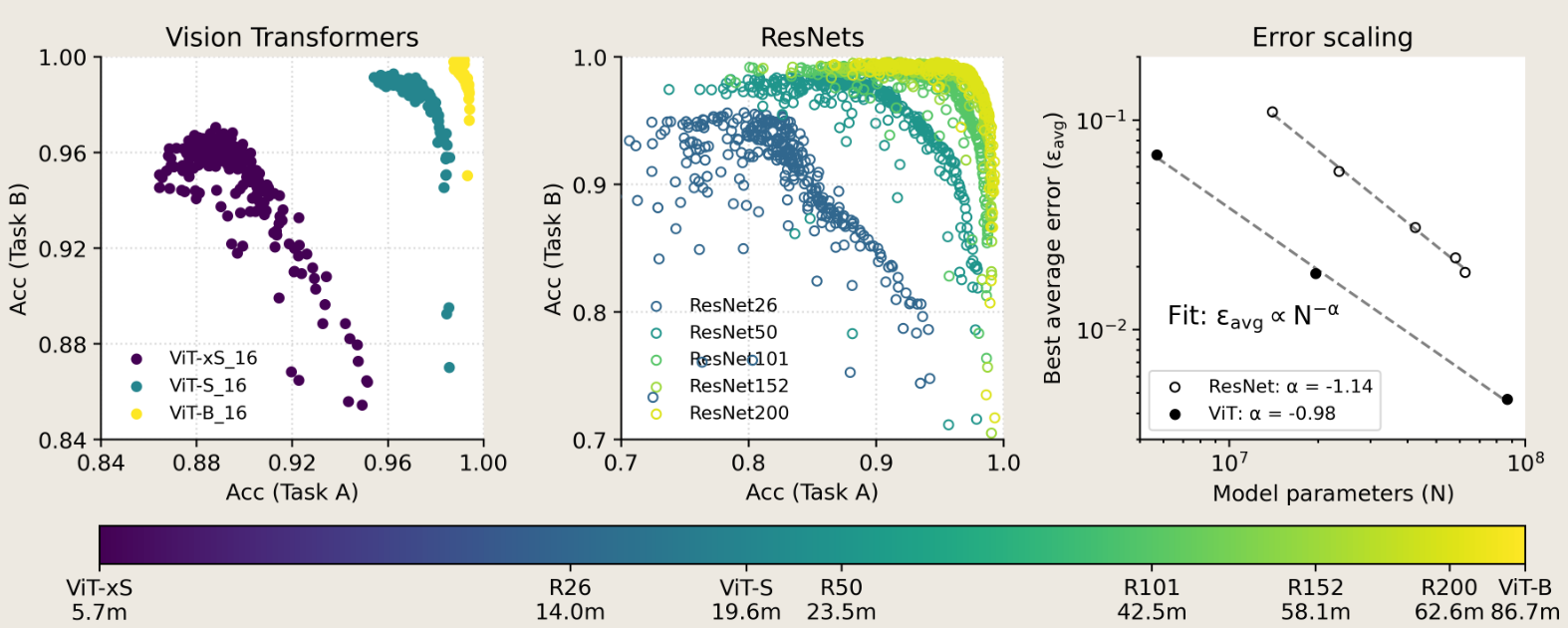

large, pretrained ResNets and Transformers are significantly more resistant to forgetting than randomly-initialized, trained-from-scratch models; this robustness systematically improves with scale of both model and pretraining dataset size.
看起来,模型越大,神经网络参数越多,所对应的数据数据集合也就越大,从而导致 遗忘越小。 其在 zero-shoot 和 finetuned 之后的效果也都表现更好。
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
2023 arXiv.org

文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/01/07/Paper-Reading-Note-17-LLM-fintuning-and-forgetting-3-Experiment-Explore/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)