理解二阶曲率5 二阶泰勒展开 特征空间-logit空间-概率空间-损失函数
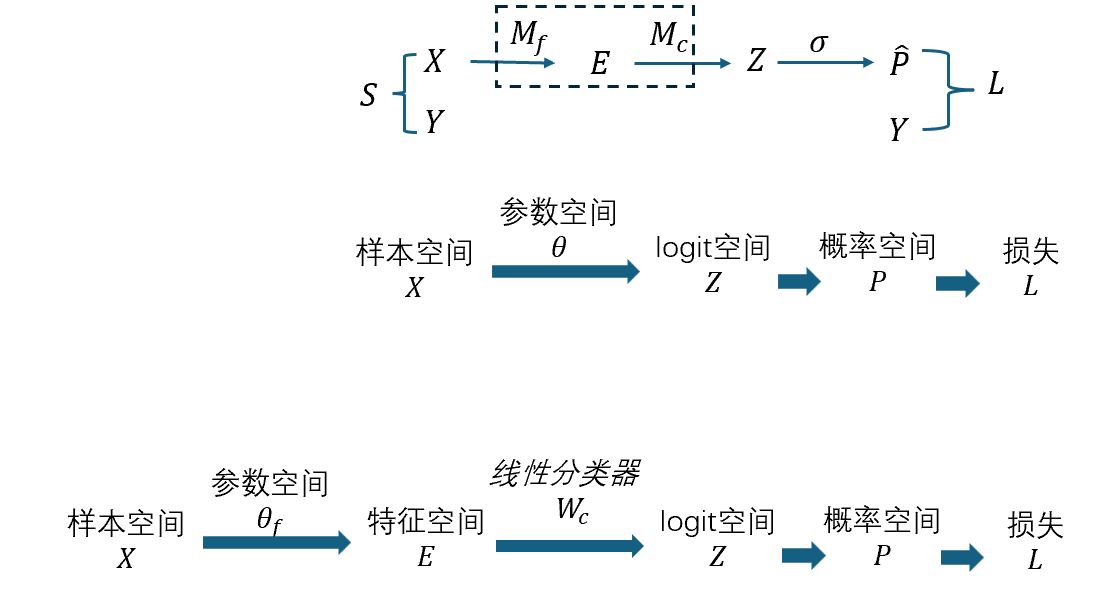
在上一节,我们梳理了 logit空间和概率空间的关系,并且给出了分别定义在权重的Fisher矩阵的定义和定义在特征空间上的fisher信息矩阵。接下来我们更进一步,将整个权重进行拆解为特征提取器部分$\theta_f$和最后的线性分类层,并且希望推导出从特征空间空间与权重空间的关系。
二 统一符号与规范定义
为了比较差别,我们分别给出三种不同的泰勒展开
一些通用的符号如下
损失函数为 $ L(\hat{p},y)$ , 经过分解的模型处理过程为
\[e = f(x;\theta_f), z=f(e;\theta_c)=W_c e, p= P (z)\]这里的函数$P$可以是softmax函数或者sigma函数,保持维度不变但能将输出进行归一化且满足概率的要求
合并在一起可以表示为
\[\hat{p}= \text{softmax}(f(f(x;\theta_f);\theta_c))= \text{softmax}(W_c \cdot f(x;\theta_f))\]对应的损失函数可以表示为 \(L=L(p,y)=L(\text{softmax}(W_c \cdot f(x;\theta_f)),y)\) 对于固定的输入$(x,y)$ , $L$ 的大小是由内部的所有参数 $\theta={\theta_f,W_c}$决定的,
对于固定的模型,输出是由输入$x$ 决定的,更近一步也可以看做是$z$决定的,甚至可以表示为由$e$决定
参数分块:$\theta=(\theta_f,W_c)$,
特征抽取:$e=f(x;\theta_f)\in\mathbb{R}^d$,雅可比 $J_e=\partial e/\partial\theta_f\in\mathbb{R}^{d\times \theta_f }$,二阶张量 $\mathcal H_e={\nabla^2{\theta_f} e_k}{k=1}^d$。 线性头:$z=W_c\,e\in\mathbb{R}^C$。。
概率映射:$p=P(z)$(softmax 或逐维 sigmoid;保维度)。
损失:$L=L(p,y)=L(P(z),y)$。
损失作为 $z$ 的函数, 损失在 $z$-空间的一/二阶: \(g_z:=\frac{\partial L}{\partial z}\in\mathbb{R}^C,\qquad H_{zz}:=\nabla_z^2 L\in\mathbb{R}^{C\times C}.\)
- softmax+CE:$g_z=p-y,\ \ H_{zz}=\mathrm{diag}(p)-pp^{\top}$;
- sigmoid+CE:$g_z=p-y,\ \ H_{zz}=\mathrm{diag}(p\odot(1-p))$
对输出作为 $\theta$ 的函数, 网络的一/二阶: \(J_z:=\frac{\partial z}{\partial\theta}\in\mathbb{R}^{C\times p},\qquad \mathcal{H}_z=\{\nabla_{\theta}^2 z_k\}_{k=1}^C\ (\text{二阶张量}).\) 对特征层再细化: \(J_e:=\frac{\partial e}{\partial\theta_f}\in\mathbb{R}^{d\times|\theta_f|}, \ \mathcal{H}_e:=\{\nabla_{\theta_f}^2 e_k\}_{k=1}^d\) 对线性分类层再细化
定义作用在增量 $\Delta W\in\mathbb{R}^{C\times d}$ 上的线性算子
\(\ J_{z,W}[\Delta W]\ :=\ \frac{\partial z}{\partial W_c}[\Delta W]\ =\ \Delta W\,e\ \in\ \mathbb{R}^{C}.\) 因为 $z=W_ce$ 对 $W_c$ 线性,所以 \(\ \mathcal{H}_{z,W}\equiv 0\ \quad(\text{即 }z\text{ 对 }W_c\text{ 的二阶张量为零}).\)
重要:始终区分 $H_{zz}=\nabla_z^2 L$(损失在 logit 空间的 Hessian)与 $\mathcal H_z$(logit 对参数的二阶张量)。
三、规范推导(分三段:$\theta\to L$,$\theta\to z\to L$,$e\to z\to L$)
1 $\theta \rightarrow L$
显然 损失函数是 $\theta$ 的函数,对于损失函数我们可以进行泰勒展开
令损失函数 $L:\mathbb{R}^d\to\mathbb{R}$ 在点 $\theta$ 处二阶可微,扰动向量 $\Delta \theta\in\mathbb{R}^d$。记
- $g \;=\; \nabla_\theta L(\theta)\in\mathbb{R}^d.$
- $ H_{\theta\theta}\;=\; \nabla^2_\theta L(\theta)\in\mathbb{R}^{d\times d}$
则
\[L(\theta+\Delta \theta) \approx L(\theta) + \nabla_\theta L(\theta)^{\top}\Delta \theta + \tfrac12\,\Delta \theta^{\top}\nabla^2_\theta L(\theta)_L\,\Delta \theta + R_3(\theta,\Delta \theta)\;\]2 $\theta \rightarrow z \rightarrow L$
我们可以对神经网络进行二阶泰勒展开
- $z=z(\theta)$:$\mathrm d z = J_z\,\mathrm d\theta,\quad \mathrm d^2 z = \mathcal H_z[\mathrm d\theta,\mathrm d\theta]$
\(z(\theta+\Delta \theta) \approx z(\theta) + J_z\Delta \theta + \tfrac12\,\Delta \theta^{\top}\mathcal H_z\Delta \theta + R_3(\theta,\Delta \theta)\) 将上式变形,我们有 \(\begin{aligned} \Delta z &= z(\theta+\Delta \theta) - z(\theta) \\ &\approx J_z\Delta \theta + \tfrac12\,\Delta \theta^{\top}\mathcal H_z\Delta \theta + R_3(\theta,\Delta \theta) \\ &\approx J_z \theta \end{aligned}\)
我们将损失函数在 $z$-空间进行展开有
- $L=L(z)$:$\mathrm d L = g_z^{\top}\mathrm d z,\quad \mathrm d^2 L=(\mathrm d z)^{\top}H_{zz}\,\mathrm d z$。
变形有
\[\,\Delta L\ \approx\ g_z^{\top}\Delta z\ +\ \tfrac12\,\Delta z^{\top}H_{zz}\Delta z\,\]将上面的式子得到的 $\Delta z \approx J_z \Delta \theta $ 带入得到 并只保留总二阶
把 $\Delta z$ 用上一步替换,并只保留总二阶(二次项里取 $\Delta z\approx J_z\Delta\theta$ 即可):
\[\; \Delta L\ \approx\ \underbrace{g_z^{\top}J_z\Delta\theta}_{\text{一阶}} \ +\ \frac12\,\underbrace{(J_z\Delta\theta)^{\top}H_{zz}(J_z\Delta\theta)}_{\text{GGN/Fisher 块}} \ +\ \frac12\,\underbrace{g_z^{\top}\mathcal H_z[\Delta\theta,\Delta\theta]}_{\text{模型非线性二阶}}\]把 $\Delta z$ 代入并逐项分解与定阶:
1) 线性项 $g_z^{\top}\Delta z$
$\begin{aligned} g_z^{\top}\Delta z &= g_z^{\top}\Big(J_z\Delta\theta+\tfrac12\,\mathcal H_z[\Delta\theta,\Delta\theta]\Big) + O(|\Delta\theta|^3)\ &=\underbrace{g_z^{\top}J_z\Delta\theta}{O(|\Delta\theta|)} \;+\;\underbrace{\tfrac12\,g_z^{\top}\mathcal H_z[\Delta\theta,\Delta\theta]}{O(|\Delta\theta|^2)} \;+\;O(|\Delta\theta|^3). \end{aligned}$
第一项是一阶($\propto |\Delta\theta|$)。
第二项是二阶($\propto |\Delta\theta|^2$)。
2) 二次项 $\tfrac12\,\Delta z^{\top} H_L\,\Delta z$
令 $a:=J_z\Delta\theta=O(|\Delta\theta|),\qquad b:=\tfrac12\,\mathcal H_z[\Delta\theta,\Delta\theta]=O(|\Delta\theta|^2),$
则 $\Delta z=a+b+O(|\Delta\theta|^3).$
用对称性($H_L^\top=H_L$)展开:
$\begin{aligned} \tfrac12\,\Delta z^{\top} H_L\,\Delta z &=\tfrac12\,(a+b)^{\top}H_L(a+b) + O(|\Delta\theta|^4)\ &=\tfrac12\,\underbrace{a^{\top}H_L a}{O(|\Delta\theta|^2)} +\underbrace{a^{\top}H_L b}{O(|\Delta\theta|^3)} +\tfrac12\,\underbrace{b^{\top}H_L b}_{O(|\Delta\theta|^4)} \;+\;O(|\Delta\theta|^4). \end{aligned}$
$a^{\top}H_L a$ 是二阶;
- 交叉项 $a^{\top}H_L b$ 是三阶(丢弃于“总二阶”近似);
- $b^{\top}H_L b$ 是四阶(同样丢弃)。
因此在“只保留总二阶”下:
$\tfrac12\,\Delta z^{\top} H_L\,\Delta z \;=\;\tfrac12\,(J_z\Delta\theta)^{\top} H_L (J_z\Delta\theta)\;+\;O(|\Delta\theta|^3).$
3) 汇总得到“只保留总二阶”的最终式
把 1) 与 2) 的保留项合并:
\[\Delta L \;\approx\; \underbrace{g_z^{\top}J_z\Delta\theta}_{\text{一阶}} \;+\;\tfrac12\,\underbrace{(J_z\Delta\theta)^{\top} H_L (J_z\Delta\theta)}_{\text{二阶(GN/Fisher 块)}} \;+\;\tfrac12\,\underbrace{g_z^{\top}\mathcal H_z[\Delta\theta,\Delta\theta]}_{\text{二阶(模型非线性)}} \;+\;O(\|\Delta\theta\|^3).\]这正是我们在正文中给出的式子;也解释了为什么在二次项里可以把 $\Delta z$ 用 $J_z\Delta\theta$ 近似:因为包含 $\mathcal H_z$ 的那一部分在二次型里只会产生三阶及以上的项(交叉项 $a^{\top}H_L b\sim O(|\Delta\theta|^3)$ 与 $b^{\top}H_L b\sim O(|\Delta\theta|^4)$),在“总二阶”近似中应当丢弃。
备注(等价的微分形式,一行见底)
用二阶复合函数微分公式也可一行得到相同结果: 对复合 $L(z(\theta))$,有
$\mathrm{d}L = g_z^{\top}\mathrm{d}z,\qquad \mathrm{d}^2L = (\mathrm{d}z)^{\top}H_L\,\mathrm{d}z + g_z^{\top}\mathrm{d}^2 z.$
沿方向 $\Delta\theta$ 代入 $\mathrm{d}z=J_z\Delta\theta$,$\mathrm{d}^2 z=\mathcal H_z[\Delta\theta,\Delta\theta]$,并取 $\Delta L \approx \mathrm{d}L+\tfrac12\,\mathrm{d}^2L$,即得
$\Delta L \approx g_z^{\top}J_z\Delta\theta +\tfrac12\,(J_z\Delta\theta)^{\top}H_L(J_z\Delta\theta) +\tfrac12\,g_z^{\top}\mathcal H_z[\Delta\theta,\Delta\theta].$
这与上面的按阶展开完全一致。
3 拆分模型:$e(\theta_f)$ 与 $z=W_c e$
我们把 (★) 中的 $J_z,\mathcal H_z$ 进一步写成特征与线性头的组合。
我们参照上面的思路进行继续拆分 模型内部的关系
我们根据上面的拆分思路,来仔细研究 模型输出$z$ 和损失函数的关系
具体地说,我们将模型里面的特征提取层和线性层进行分开
对于模型,
特征层输入为$x$ 输出为 $e=f(x;\theta_f) $ ,注意这里的$f$和上面的$f$并不一致,为了区别我们可以重新记作$e(x;\theta_f)$
线性分类层,输入为特征$e$ 进行线性变化到 Logit层 $z=W_c e$
得到模型输出后,然后
概率函数将输出从 $z \in \mathbb{R}^{C} $ 映射到概率 $p \in \mathbb{R}^{C}$
原式:$e=f(x;\theta_f),\ z=W_c e,\ L=L(z)$。
微分:$\mathrm d e=J_e\,\mathrm d\theta_f,\ \mathrm d^2 e=\mathcal H_e[\mathrm d\theta_f,\mathrm d\theta_f]$; $\mathrm d z=W_c\,\mathrm d e,\ \mathrm d^2 z=W_c\,\mathrm d^2 e$。
我们可以对特征提取器进行二阶泰勒展开 \(e(\theta_f+\Delta \theta_f) \approx e(\theta_f) + J_e\Delta \theta_f + \tfrac12 \mathcal H_e[\mathrm d\theta_f,\mathrm d\theta_f]\) 这样我们就得到了再扰动下 特征的变化 $$ \begin{aligned} \Delta e &= e(\theta_f+\Delta \theta_f) - e(\theta_f)
&\approx J_e\Delta \theta_f + \tfrac12 \mathcal H_e[\mathrm d\theta_f,\mathrm d\theta_f] \
\end{aligned} $$
1 如果我们假定 线性映射层不变,则,这个扰动会继续向前传到,于是有将$de,d^2e$带入于是有
\[\Delta z\approx W_cJ_e\Delta\theta_f+\tfrac12\,W_c\,\mathcal H_e[\Delta\theta_f,\Delta\theta_f]\]同样的,我们将损失函数在 $z$-空间进行展开有
- $L=L(z)$:$\mathrm d L = g_z^{\top}\mathrm d z,\quad \mathrm d^2 L=(\mathrm d z)^{\top}H_{zz}\,\mathrm d z$。
\(L(z+\Delta z) \approx L(z) + g_z \Delta z + \tfrac12\,\Delta \theta^{\top}H_{zz}\,\Delta \theta + R_3(\theta,\Delta \theta)\) 变形有 \(\,\Delta L\ \approx\ g_z^{\top}\Delta z\ +\ \tfrac12\,\Delta z^{\top}H_{zz}\Delta z\,\)
将上面的式子得到的 $\Delta z\approx W_cJ_e\Delta\theta_f$ 带入得到 并只保留总二阶 \(\Delta L\approx (W_c^{\top}g_z)^{\top}J_e\Delta\theta_f +\tfrac12\,(J_e\Delta\theta_f)^{\top}\underbrace{(W_c^{\top}H_{zz}W_c)}_{=:F_e}(J_e\Delta\theta_f) +\tfrac12\,g_z^{\top}W_c\,\mathcal H_e[\Delta\theta_f,\Delta\theta_f]\)
- 梯度:$\displaystyle \frac{\partial L}{\partial \theta_f}=J_e^{\top}W_c^{\top}g_z$。
- 特征空间 Fisher/GGN:$\displaystyle F_e=W_c^{\top}H_{zz}W_c$。
- 参数空间 Fisher/GGN(特征层):$\displaystyle F_{\theta_f}=J_e^{\top}F_eJ_e$。
- 最后一项是“非 GGN(模型二阶)”修正,工程上常忽略。
2 由于权重展开是包括了全部参数,于是在线性权重层同样有扰动发生
- 原式:$z=W_c e,\ L=L(z)$。
- 微分与二阶微分: $\mathrm d z=W_c\,\mathrm d e+(\mathrm dW_c)e,\qquad \mathrm d^2 z=\underbrace{(\mathrm dW_c)\,\mathrm d e}{\text{混合二阶}}+\underbrace{W_c\,\mathrm d^2 e}{\text{特征二阶}}.$
由于同时发生了扰动, \(\begin{aligned} \Delta z &= z(\theta+\Delta \theta) - z(\theta) \\ &\approx \mathrm d z + \tfrac12 \mathrm d^2 z \\ &\approx W_c\,\mathrm d e+(\mathrm dW_c)e + \tfrac12 \underbrace{(\mathrm dW_c)\,\mathrm d e}_{\text{混合二阶}}+\underbrace{W_c\,\mathrm d^2 e}_{\text{特征二阶}} \end{aligned}\) 我们将$de,d^2e$带入于是有,并且有$d W_c = \Delta W_c$
Δ 式(总二阶): \(\begin{aligned} \Delta z\ \approx\ &\underbrace{W_cJ_e\,\Delta\theta_f + \Delta W_c\,e}_{\text{一阶}}\\ &+\ \tfrac12\,\underbrace{\Big[\ \Delta W_c\,(J_e\Delta\theta_f)\ +\ W_c\,\mathcal H_e[\Delta\theta_f,\Delta\theta_f]\ \Big]}_{\text{二阶:混合 + 特征}}. \end{aligned}\) 更进一步
代回 $\Delta L \approx g_z^{\top}\Delta z+\tfrac12\,\Delta z^{\top}H_{zz}\Delta z$,保留总二阶,得到
$\begin{aligned} \Delta L\ \approx\ &\ g_z^{\top}\big(W_cJ_e\Delta\theta_f+\Delta W_c\,e\big)\ &+\ \tfrac12\,\big(W_cJ_e\Delta\theta_f+\Delta W_c\,e\big)^{!\top}H_{zz}\,\big(W_cJ_e\Delta\theta_f+\Delta W_c\,e\big)\ &+\ \tfrac12\,g_z^{\top}\Big[\ \Delta W_c\,(J_e\Delta\theta_f)\ +\ W_c\,\mathcal H_e[\Delta\theta_f,\Delta\theta_f]\ \Big]. \end{aligned}$
其中交叉二阶清晰可见:
$\underbrace{(\Delta W_c e)^{\top}H_{zz}(W_cJ_e\Delta\theta_f)}{\text{来自二次型}}\quad+\quad \underbrace{\tfrac12\,g_z^{\top}\,\Delta W_c(J_e\Delta\theta_f)}{\text{来自 } \mathrm d^2 z}.$
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2025/09/13/%E7%90%86%E8%A7%A3%E4%BA%8C%E9%98%B6%E6%9B%B2%E7%8E%875-%E4%BA%8C%E9%98%B6%E6%B3%B0%E5%8B%92%E5%B1%95%E5%BC%80-%E7%89%B9%E5%BE%81%E7%A9%BA%E9%97%B4-logit%E7%A9%BA%E9%97%B4-%E6%A6%82%E7%8E%87%E7%A9%BA%E9%97%B4-%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)