Paper Reading– CLIP
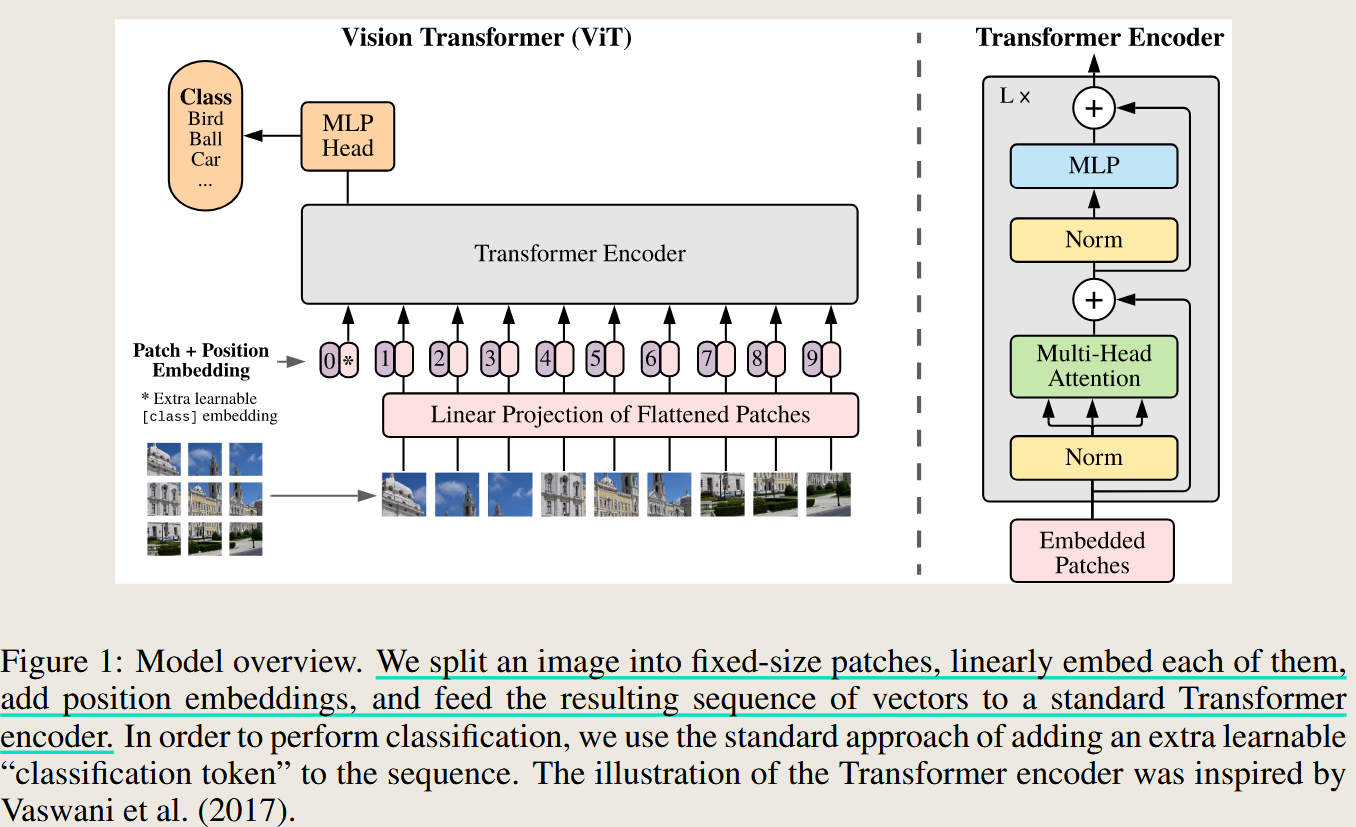
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
2020 International Conference on Learning Representations
Vit 使用 Transfoirmer 结构代替 cnn 结果
Learning Transferable Visual Models From Natural Language Supervision
2021 International Conference on Machine Learning
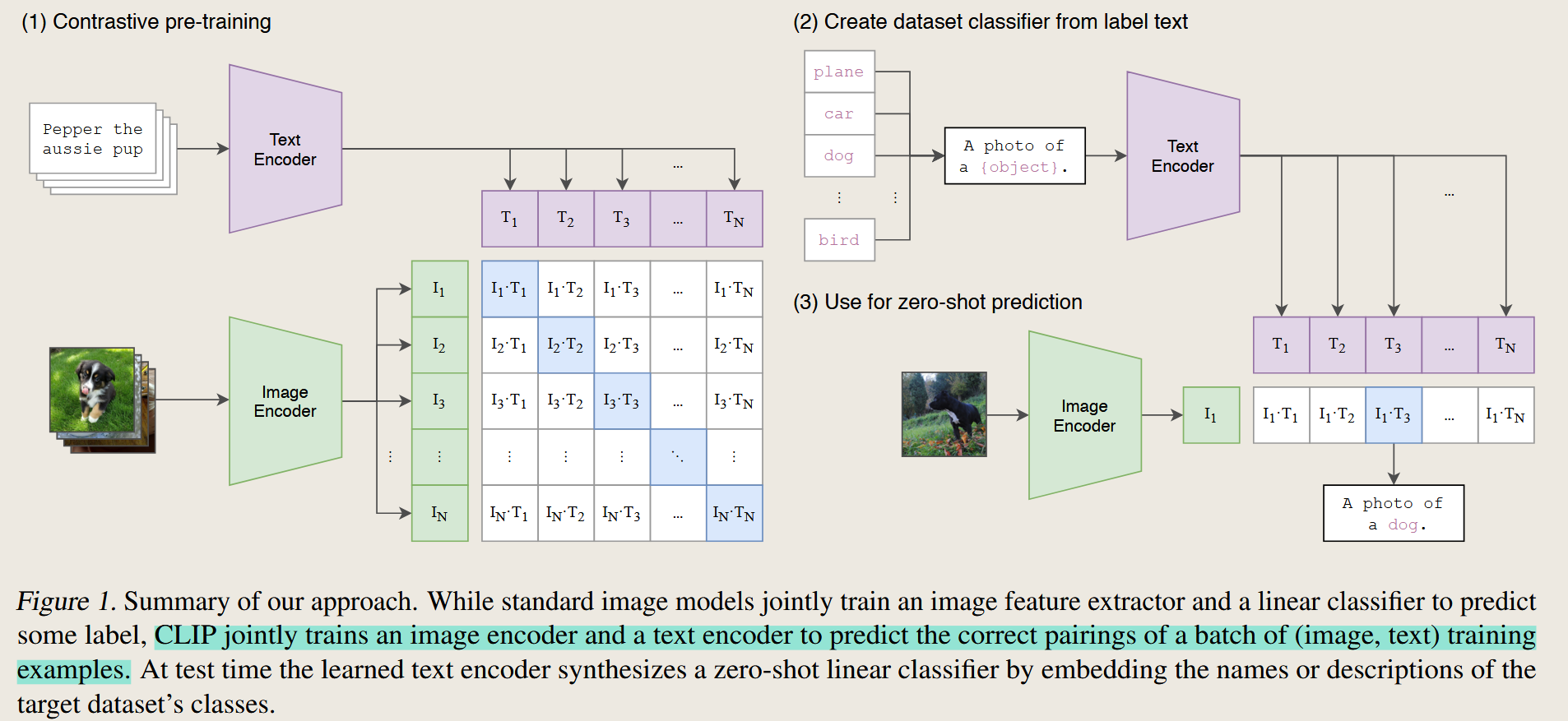
CLIP 将文本与图像进行对齐
Image-based CLIP-Guided Essence Transfer

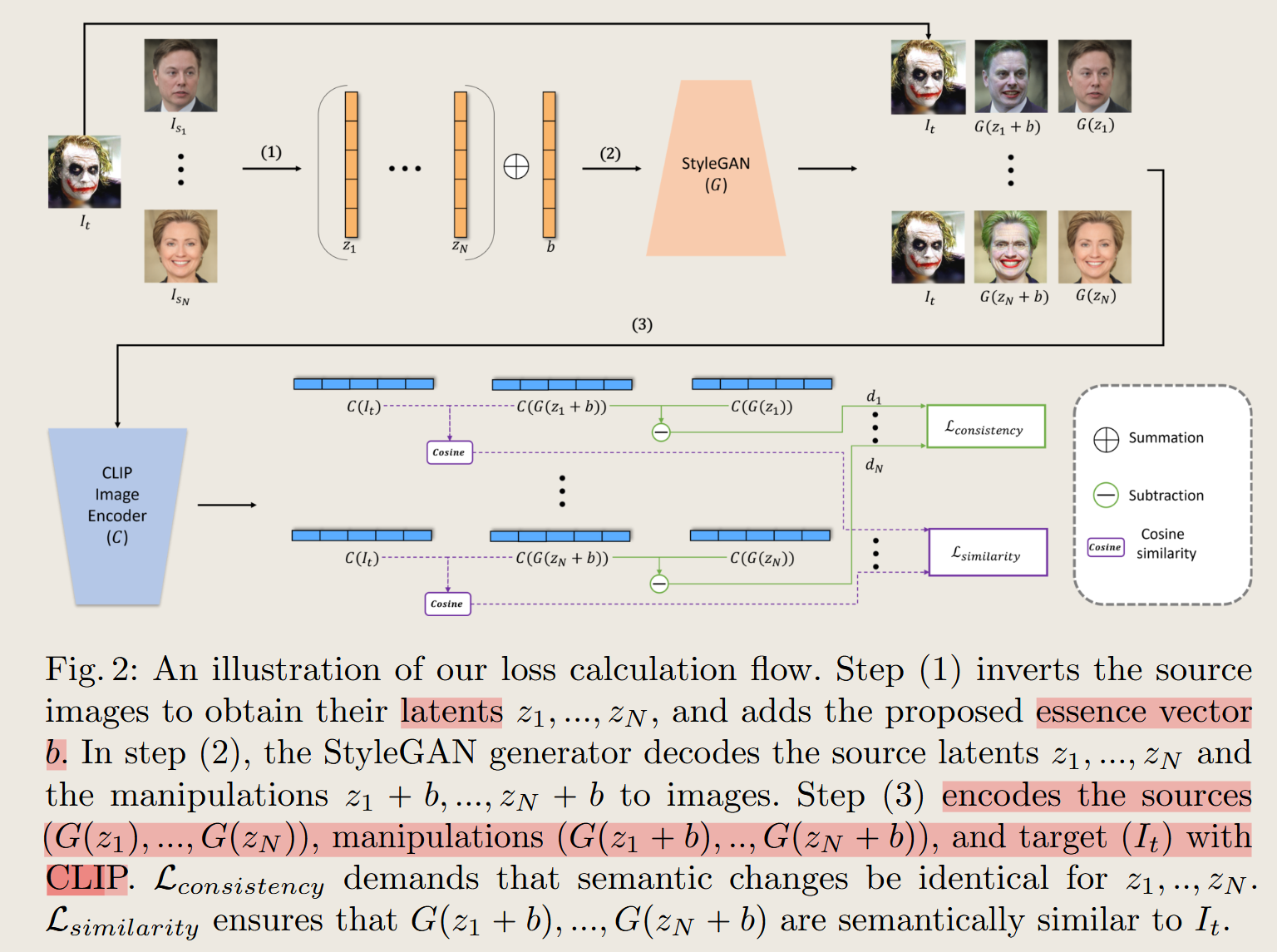
只优化转移图像之间的差异,使用预训练的固定的styleGAN和CLIP ,使用CLIP 确保前后变化一致
📌 这张图描述了三个步骤:
论文的方法需要在 StyleGAN 和 CLIP 的潜在空间中进行计算,以确保 Essence Transfer 过程是稳定的。 图 2 通过 三个步骤 展示了这个过程:
🔹 Step 1: Invert Source Images & Add Essence Vector
翻译:对源图像进行反演 (Inversion) 并添加 Essence 向量。 ✅ 通俗解释:
- **先把源图像 $I_s$ 转换成 StyleGAN 的“潜在向量” $z_s$ **。
- 这个过程叫做 GAN Inversion(GAN 反演),可以让 StyleGAN 重新生成源图像。
- 你可以理解为把 一张脸“编码”到 StyleGAN 里,这样后续可以修改它。
- 再在这个潜在空间里加上 Essence Vector $b$。
- $b$ 代表 目标图像 $I_t$ 和源图像 $I_s$ 之间的语义差异,比如年龄、性别、发型等特征。
- 💡 打比方:想象 StyleGAN 是一个会画画的机器人,而 GAN 反演 就像是让机器人记住你的一张照片(像素 → 数字代码)。 然后,我们加上 Essence Vector $b$ ,就像是在这张照片的代码里 加上一点点目标图像的感觉,比如变老、变年轻、变换发型。
🔹 Step 2: Decode with StyleGAN
翻译:使用 StyleGAN 生成变换后的图像。
✅ 通俗解释:
- 通过 StyleGAN 生成新的图像 ** $I_{s,t}$ **:$I_{s,t} = G(z_s + b)$
- 这意味着:
- 原图 $I_s$ 仍然保留了主要的面部身份信息。
- 但它开始带有目标图像 $I_t$ 的语义特征(比如发型、年龄、性别)。
- 这个阶段完成后,我们已经得到一个初步的 Essence Transfer 结果,但还需要进一步优化。💡 打比方:你给机器人说:“记住这张脸(源图像),然后给他加上目标图像的一点点感觉。” 机器人画出的新图像 看起来像源图像,但带有目标的特征。
🔹 Step 3: Encode with CLIP & Calculate Loss
翻译:用 CLIP 编码并计算损失。 ✅ 通俗解释:
把 源图像 $I_s$ **、目标图像 $I_t$ ** 和 变换后的图像 $I_{s,t}$ ** 都输入 **CLIP 进行特征提取。
计算两个关键的损失:
- Lsimilarity(相似性损失):
- 确保变换后的图像 ** $I_{s,t}$ ** 在 CLIP 语义空间里接近目标图像 $I_t$ 。
- Lconsistency(一致性损失):
- 确保 Essence Transfer 过程在 不同源图像上是一致的,不会因不同人脸导致风格不稳定。
💡 打比方:让 CLIP 充当“智能审查官”,它会检查:
- 这个变换后的图像 有没有成功吸收目标的语义?
- 这个变换 是不是在所有源图像上都表现一致?如果效果不理想,就调整 **Essence Vector $b$ **,再试一次,直到损失最小化。
📌 总结
步骤 主要任务 通俗理解 Step 1 反演源图像 + 添加 Essence Vector 让 StyleGAN 记住源图像,并加上目标图像的“感觉” Step 2 用 StyleGAN 生成变换后的图像 让 GAN 画出新图像,它看起来像源图像但带有目标特征 Step 3 用 CLIP 计算损失 让 CLIP 评估新图像是否符合目标,并调整 Essence Vector 📌 直观理解整个流程
可以把整个流程比作 “化妆+评价”:
- Step 1:选择化妆模板(选定 Essence Vector) → 目标图像 $I_t$ 告诉我们想要的变化(比如换发型)。
- Step 2:化妆(用 StyleGAN 生成新图像) → 让 StyleGAN 画出带有新特征的脸。
- Step 3:检查化妆效果(CLIP 计算损失) → 让 CLIP 评估是不是变得太多/太少,然后调整妆容,直到最完美。这样,既能保持原本的面部身份,又能精准提取目标的特征! 🎨✨
训练时更新的是哪个网络?StyleGAN 还是 CLIP?
在训练过程中,StyleGAN 和 CLIP 都不会被更新,论文的 训练目标是优化 Essence Vector $b^*$ **,即 **在 StyleGAN 的潜在空间 $W$ 或 $W^+$ 中找到合适的语义偏移量。
✅ 结论:训练过程中不会更新 StyleGAN 和 CLIP,只优化 Essence Vector $b$ 。
✅ 方法本质上是利用 StyleGAN 作为一个固定的生成器,CLIP 作为一个固定的评估器。
📌 训练时优化的部分
在 *训练时,论文优化的是 Essence Vector $b^$ **,具体来说:
- StyleGAN ( $G$ ) 是固定的 ❌ 不训练
- 论文的方法不会修改 StyleGAN 生成器的参数,而是直接在 StyleGAN 预训练的潜在空间 进行操作。
- 也就是说,StyleGAN 只是一个“变换函数”,它根据 **输入的潜在向量 $z$ ** 生成图像,但自身不变。
- CLIP ( $C$ ) 也是固定的❌ 不训练
- CLIP 的 Image Encoder 只是用来提取目标图像和源图像的语义嵌入(feature embeddings)。
- 论文的方法使用 CLIP 计算语义相似度,但不会修改 CLIP 的参数。
- 优化的变量是 Essence Vector $b^*$ ✅ 要训练
- 论文的方法训练的是 一个偏移向量 $b$ ,它位于 StyleGAN 的潜在空间,使得:$G(z_s + b^*) = I_{s,t}$
- 目标是找到最优的 $b^*$ ,使得 StyleGAN 生成的图像 既保留源图像的身份,又具有目标图像的语义特征。
📌 为什么不更新 StyleGAN?
- StyleGAN 已经是一个强大的生成器
- StyleGAN 本身已经在大规模人脸数据上训练好,它的潜在空间已经包含丰富的语义信息(年龄、性别、发型、表情等)。
- 直接在潜在空间调整 $b$ 比重新训练 StyleGAN 更高效。
- 修改 StyleGAN 可能会破坏生成能力
- 如果重新训练 StyleGAN,会导致整个模型偏向某些特定目标,不再适用于所有输入图像。
- 论文的方法希望 Essence Transfer 对不同目标图像都适用,所以让 StyleGAN 作为一个通用模型,而不做调整。
📌 为什么不更新 CLIP?
- CLIP 是一个通用的语义评估器
- CLIP 通过大规模图像-文本匹配训练,已经学习到丰富的高层语义信息。
- 论文的方法利用 CLIP 来衡量图像的语义特征,而不是让 CLIP 学习新的特征。
- 不修改 CLIP 确保方法的泛化性
- CLIP 提供的语义评估是通用的,适用于不同类型的图像和编辑任务。
- 如果训练 CLIP,可能会让它过拟合于特定数据集,降低泛化能力。
📌 训练流程
1️⃣ 计算目标图像与源图像的语义偏移
- 用 CLIP 提取 目标图像 $I_t$ 和源图像 $I_s$ 的特征:$\Delta c = C(I_t) - C(I_s)$
- 这里 CLIP 只是用来计算语义差异,CLIP 本身不会被更新。
*2️⃣ 训练 Essence Vector $b^$ **
- 在 StyleGAN 潜在空间优化 $b$ ,使得:$G(z_s + b^*) \approx I_{s,t}$
- 其中 $I_{s,t}$ 是变换后的图像。
- 优化目标:
- $L_{\text{similarity}}$ :确保变换后的图像语义接近目标图像 $I_t$ 。
- $L_{\text{consistency}}$ :确保 Essence Transfer 在不同源图像上表现一致。
- $L_{L2}$ :正则化,防止 $b$ 过度变化导致图像失真。
3️⃣ 反向传播 & 迭代优化
- 更新 $b$ ,而不是 StyleGAN 或 CLIP:$b^* = \arg\min (L_{\text{similarity}} + \lambda_{\text{consistency}} L_{\text{consistency}} + \lambda_{L2} |b|^2)$
- 通过 梯度下降(Adam 优化器) 迭代优化 $b$ ,直到生成的图像符合要求。
📌 总结
✅ 训练时不会更新 StyleGAN 或 CLIP,只优化 Essence Vector $b^*$ ** ✅ **StyleGAN 作为固定生成器,CLIP 作为固定评估器 ✅ 优化的目标是找到最优的 $b^*$ ,让 StyleGAN 生成符合目标语义的图像 这种方法的 最大优势是计算高效,避免了对大模型的额外训练,同时确保泛化性强! 🚀
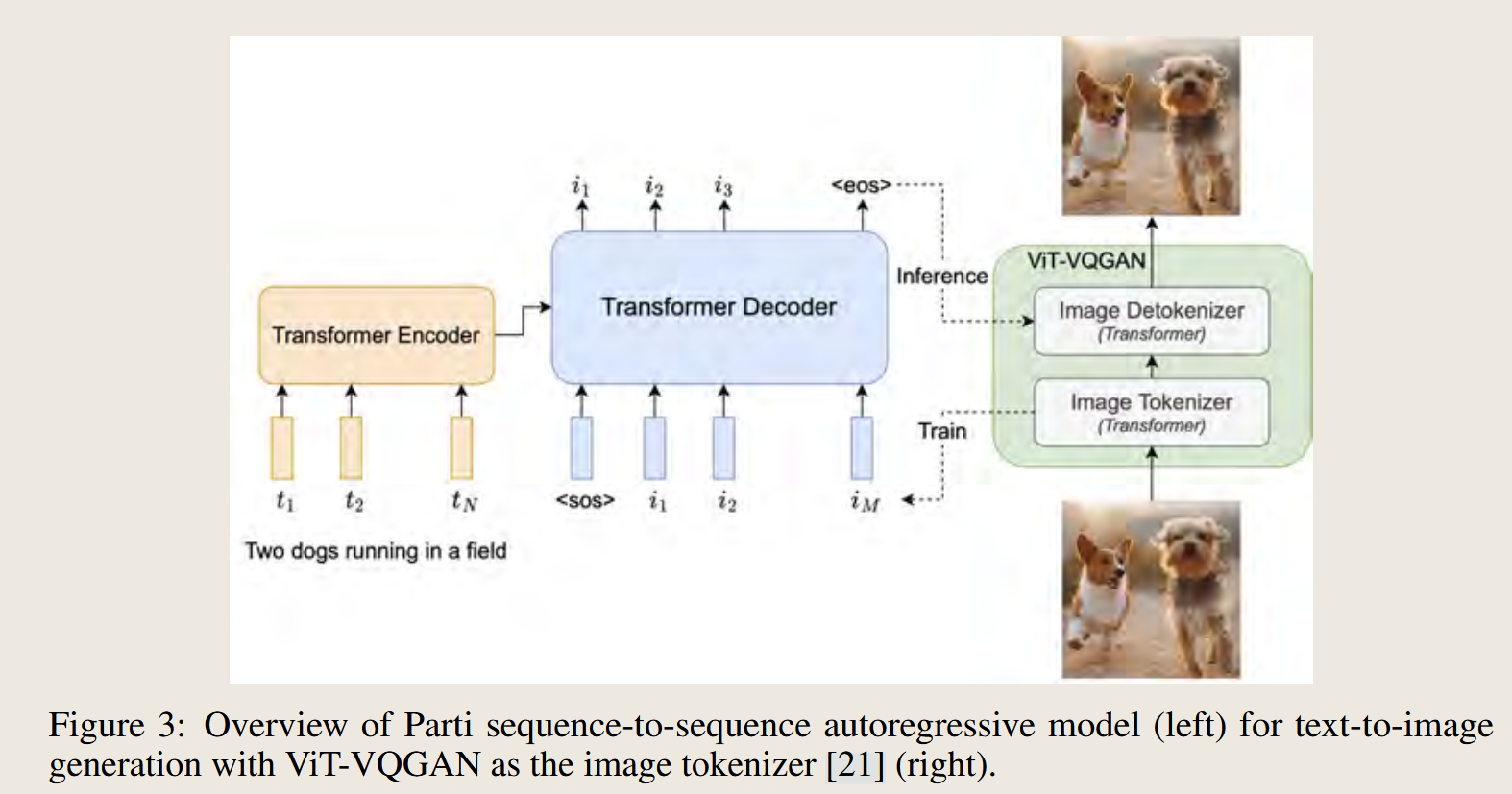
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
2022 Trans. Mach. Learn. Res.
Parti proves that autoregressive models remain competitive in text-to-image generation, particularly when scaled to 20B parameters.
输入一段文本,模型按“拼图”的方式逐步生成一张完整的图片!

Data Determines Distributional Robustness in Contrastive Language-Image Pre-training (CLIP)
The robustness of CLIP is determined by dataset diversity—not by contrastive learning or language supervision.
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
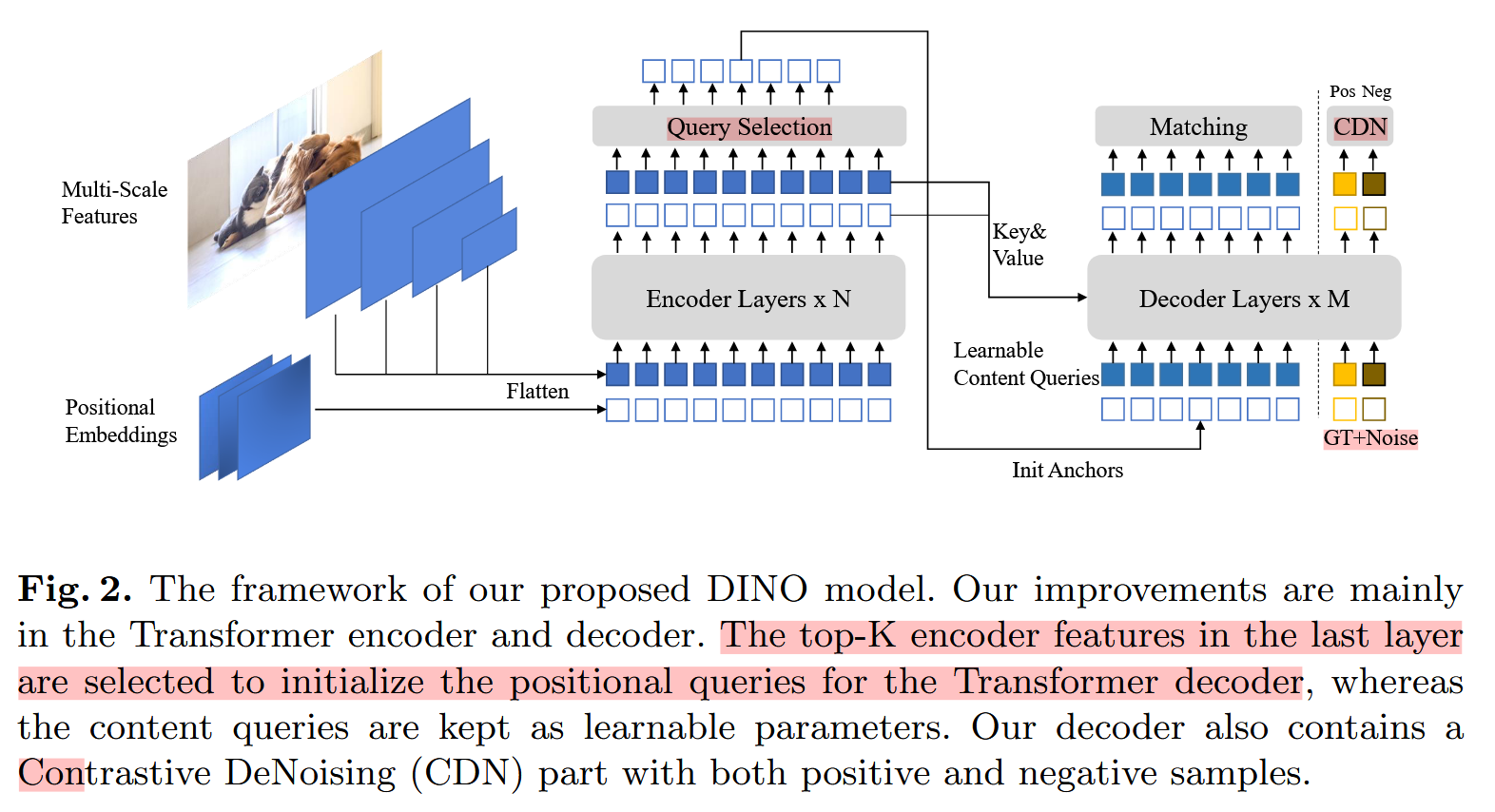
结合 Transformer 和 对比去噪进行学习
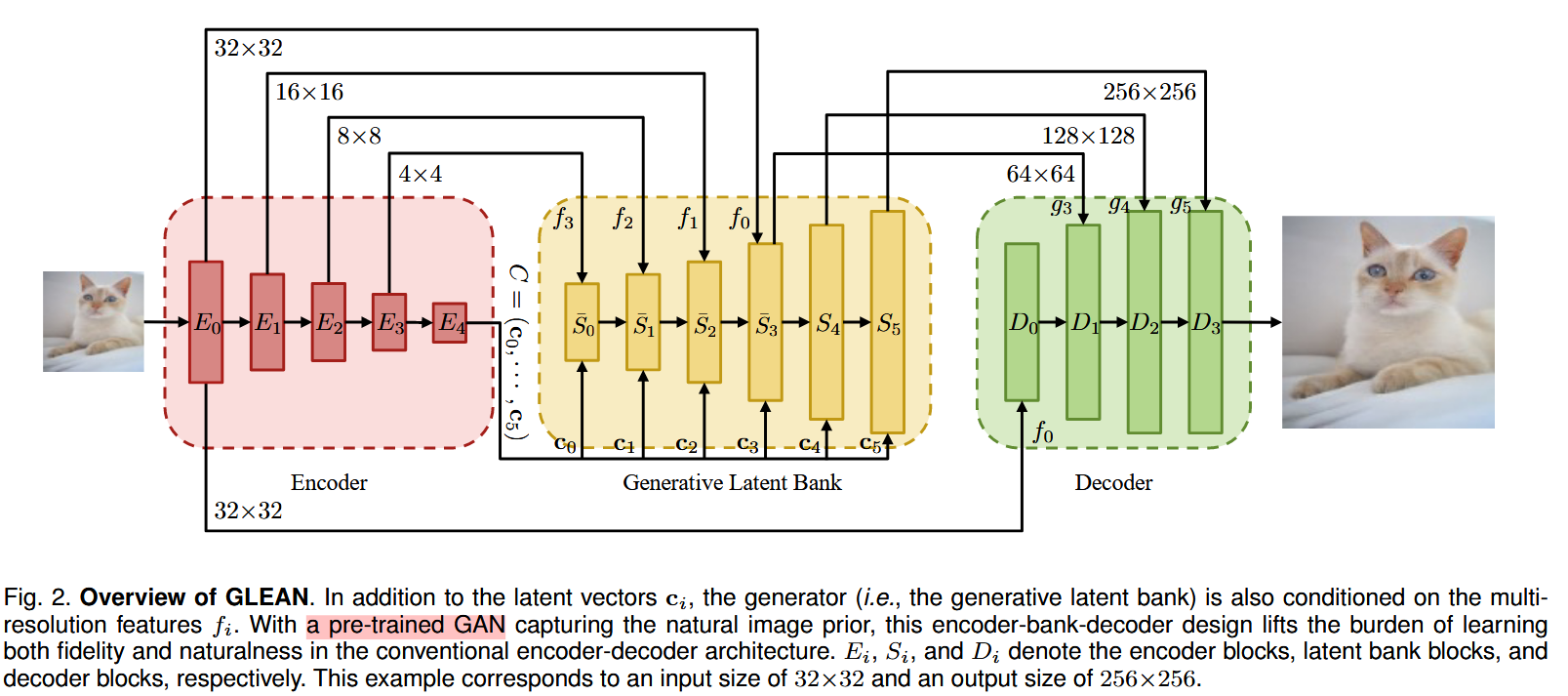
GLEAN: Generative Latent Bank for Image Super-Resolution and Beyond

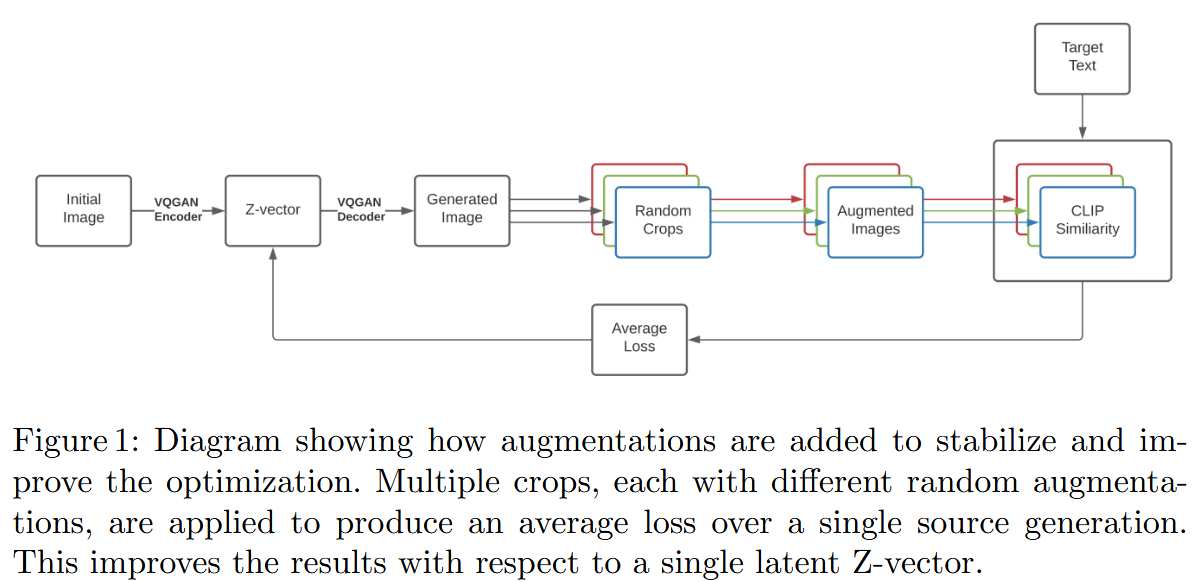
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
论文的核心思路是 利用已经训练好的 CLIP 作为“图像-文本匹配评分器”,来指导 VQGAN 生成符合文本描述的图像。
Language Driven Image Editing via Transformers
✅ 输入: 文本指令 + 源图像 token ✅ 模型处理方式: GPT-2 作为 Seq2Seq 模型,预测目标图像 token ✅ 输出: 目标图像的 token,经过 VQ-VAE 反向解码成最终的图像
GPT-2 作为 Transformer 不直接生成像素,而是生成图像 token,VQ-VAE 负责最终的图像重建。
Towards Counterfactual Image Manipulation via CLIP

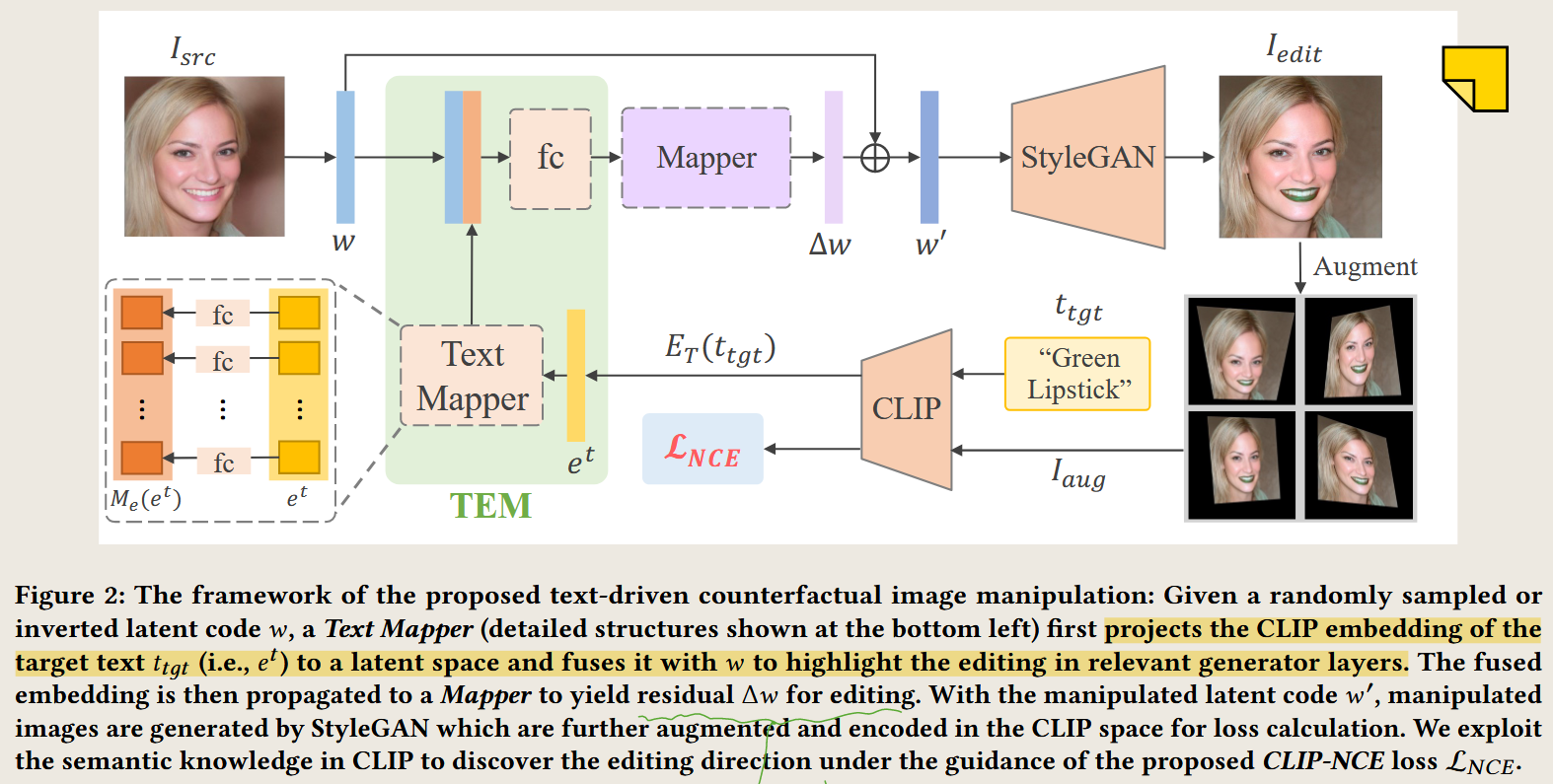
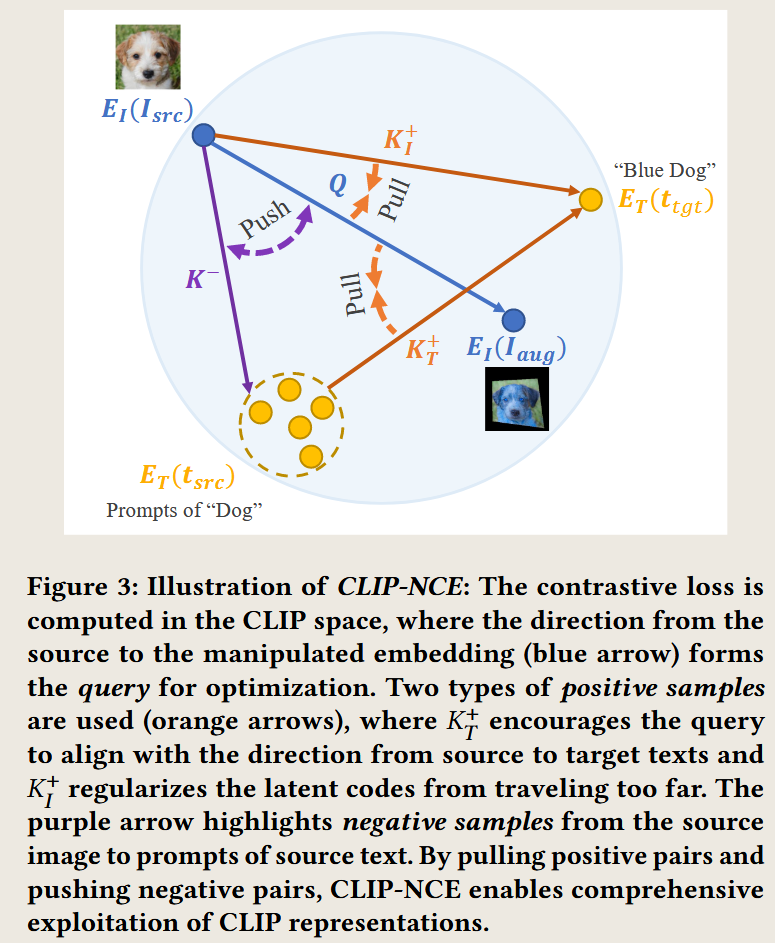
如何构造正样本和负样本进行对比学习?
在 CF-CLIP 论文中,Counterfactual Image Manipulation(反事实图像编辑)意味着数据库中可能没有直接对应的目标图像(例如“蓝色狗”)。那么,在没有真实数据的情况下,如何构造正样本(Positive Pairs)和负样本(Negative Pairs)来进行对比学习呢?
论文使用了对比损失(Contrastive Loss,CLIP-NCE)来优化文本-图像匹配,即确保编辑后的图像符合文本描述,同时避免不必要的修改。正样本和负样本的构造方式如下:
1. 如何构造正样本(Positive Pairs)
正样本的目标:让编辑后的图像和目标文本保持高度相似(即符合目标语义)。
(1) 生成的 Counterfactual 图像
由于数据库中不存在直接匹配的真实反事实图像(如“蓝色狗”),论文采用以下方法构造正样本:
- 使用当前迭代的 StyleGAN 生成的图像:
- 经过文本引导的 StyleGAN 生成的新图像 $ I’ $。
- 这个图像是由$ w’ = w + \delta w $ 生成的,理论上应该符合文本描述(但可能仍有部分偏差)。
- 计算新图像的 CLIP 嵌入: \(e_{\text{target}} = \text{CLIP}_{\text{image}}(I')\)
- 这个 $ e_{\text{target}} $ 作为正样本,希望它接近文本嵌入 $ e_{\text{text}} $。
(2) 使用 CLIP 作为监督
由于 CLIP 预训练过程中已经学习了大规模的视觉-文本关系,它能提供一定的监督信号:
- 直接计算目标文本 $ e_{\text{text}} $ 和当前生成的 $ e_{\text{target}} $ 之间的相似度,并进行优化。
2. 如何构造负样本(Negative Pairs)
负样本的目标:让未编辑的原始图像(或其他错误编辑的图像)远离目标文本。
(1) 未编辑的原始图像
- 原始图像 $ I_{\text{src}} $ 代表的是没有经过修改的原始样本,它的 CLIP 表征为: \(e_{\text{src}} = \text{CLIP}_{\text{image}}(I_{\text{src}})\)
- 由于原始图像不符合目标文本描述,因此它应该远离 $ e_{\text{text}} $。
- 计算其余的负样本相似度: \(\cos(e_{\text{src}}, e_{\text{text}})\)
- 目标是最小化这个相似度,使得原始图像的表征远离文本描述。
(2) 其他错误修改的样本
- 在训练过程中,可能会生成一些错误的编辑结果(例如颜色没变,或者变得过度极端)。
- 这些错误的图像也可以被用作负样本:
- 比如“蓝色狗”任务中,可能 StyleGAN 生成的是一只带蓝色光照的狗,而不是皮肤真的变蓝。
- 这种不完全符合文本描述的图像 $ I_{\text{wrong}} $ 也会被用作负样本: \(e_{\text{wrong}} = \text{CLIP}_{\text{image}}(I_{\text{wrong}})\)
- 目标是让 $ e_{\text{wrong}} $ 远离 $ e_{\text{text}} $。
3. CLIP-NCE 损失如何优化 Counterfactual 生成?
最终,使用 对比学习损失(CLIP-NCE Loss) 来优化 $ \delta w $,让模型更接近文本目标: \(\mathcal{L}_{\text{CLIP-NCE}} = - \log \frac{\exp(\cos(e_{\text{target}}, e_{\text{text}}))}{\sum_{n} \exp(\cos(e_{\text{neg}}^n, e_{\text{text}}))}\) 其中:
- $ e_{\text{target}} $(正样本)是经过 $ w’ $ 生成的最终图像,希望它最大化与文本的相似度。
- $ e_{\text{neg}}^n $(负样本)包括:
- $ e_{\text{src}} $(未编辑原图)
- $ e_{\text{wrong}} $(错误编辑图)
优化目标:
- 最大化 $ \cos(e_{\text{target}}, e_{\text{text}}) $,让目标图像更符合文本描述。
- 最小化 $ \cos(e_{\text{neg}}, e_{\text{text}}) $,让错误编辑和原图远离文本描述。
4. 总结
如何构造正样本?
✅ 正样本 = 由 StyleGAN 生成的新图像(符合目标文本)
- 直接使用 $ w’ = w + \delta w $ 生成的图像 $ I’ $ 作为正样本。
- 用 CLIP 计算其表征 $ e_{\text{target}} $ 并优化,使其接近文本嵌入 $ e_{\text{text}} $。
如何构造负样本?
✅ 负样本 = 不符合文本描述的图像,包括:
- 原始输入图像 $ I_{\text{src}} $(没有被修改)。
- 错误修改的图像 $ I_{\text{wrong}} $(编辑失败的样本)。
如何优化?
✅ CLIP-NCE 通过对比损失优化 $ \delta w $,确保:
- 目标图像 $ I’ $ 符合文本描述(提高相似度)。
- 原图和错误修改的图像远离文本描述(降低相似度)。
5. 这样做的优势
✅ 即使没有 ground truth(数据库里没有蓝色狗),也能进行反事实编辑!
✅ 避免 CLIP 作弊,确保编辑效果真实可见!
✅ 训练过程中不断迭代,最终生成符合文本描述的图像!🚀 CF-CLIP 通过 CLIP-NCE 成功地实现了 Counterfactual Image Manipulation,使得反事实编辑成为可能!
CLIP4IDC: CLIP for Image Difference Captioning
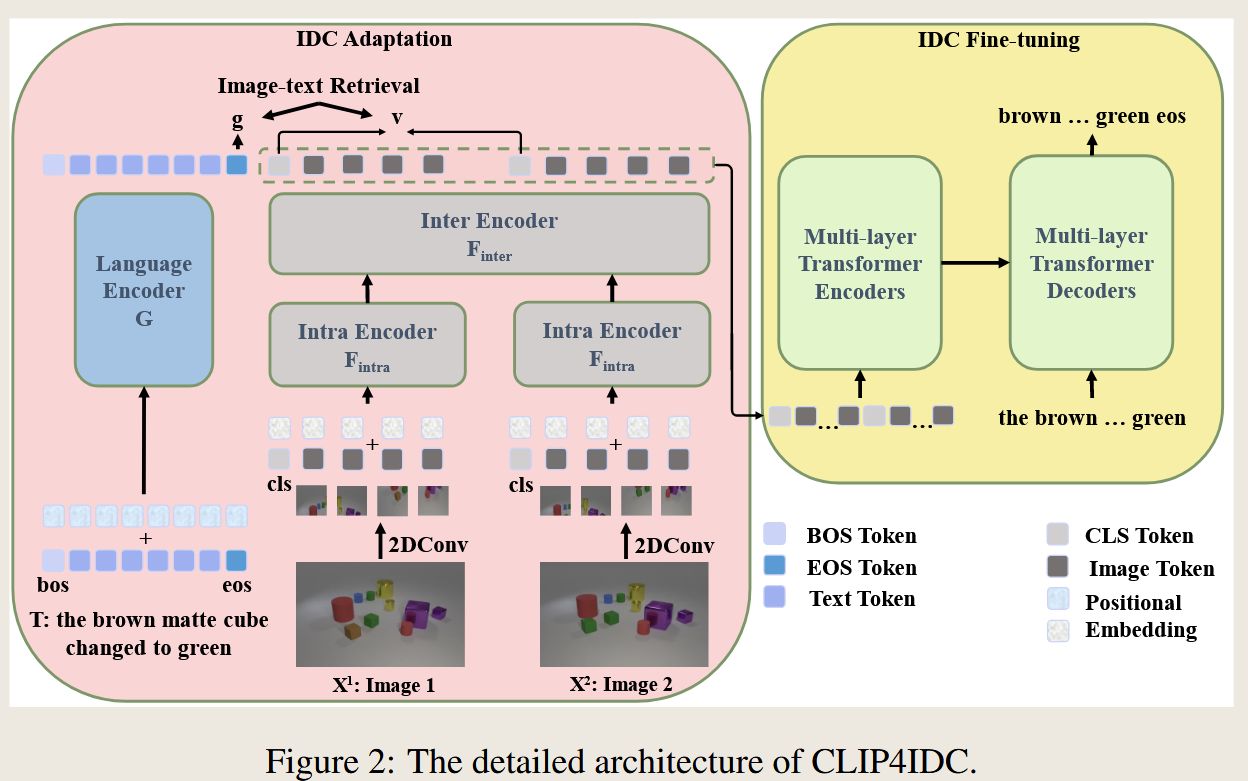
CLIP4IDC: Training and Inference Details
1. Training: Input, Output, and Updated Components
The training process of CLIP4IDC involves two main stages: Retrieval Pretraining (IDC-Specific Adaptation) and Fine-Tuning for Caption Generation.
Training Input and Output
- Input:
- A pair of images: $(I_{\text{before}}, I_{\text{after}})$ representing two versions of the same scene with slight differences.
A textual caption $T$ describing the difference between the two images.
- Output:
- A difference-aware embedding for the image pair, which aligns well with the textual description.
- A generated textual caption that describes the differences.
Updated Components During Training
- CLIP’s vision encoder: Fine-tuned to improve its capability in capturing fine-grained image differences.
- Text embedding space: Updated through contrastive learning to better associate text with image differences.
- Transformer-based captioning model: Trained from scratch to generate captions based on difference-aware embeddings.
2. Training Workflow: From Input to Output
Step 1: IDC-Specific Adaptation (Retrieval Pretraining)
- Image Difference Representation Extraction:
- The two images $(I_{\text{before}}, I_{\text{after}})$ are encoded using CLIP’s vision encoder.
- Their embeddings are combined to form a difference-aware embedding $v$.
- Contrastive Learning (Image-Pair-to-Text & Text-to-Image-Pair Retrieval):
- CLIP text encoder processes the difference caption $T$, producing an embedding $g$.
- Contrastive loss ensures that:
- The image difference embedding $v$ is closer to the corresponding text embedding $g$.
- Unrelated image-text pairs are pushed further apart.
The retrieval contrastive loss is defined as: \(\mathcal{L}_{\text{IP-T}} = -\frac{1}{B} \sum_{i=1}^{B} \log \frac{\exp(s(v_i, g_i)/\tau)}{\sum_{j=1}^{B} \exp(s(v_i, g_j)/\tau)}\) \(\mathcal{L}_{\text{T-IP}} = -\frac{1}{B} \sum_{i=1}^{B} \log \frac{\exp(s(v_i, g_i)/\tau)}{\sum_{j=1}^{B} \exp(s(v_j, g_i)/\tau)}\)
- Updating CLIP Embeddings:
- CLIP’s visual and text encoders are fine-tuned to ensure better alignment of image differences and textual descriptions.
Step 2: Fine-Tuning for Caption Generation
- Feature Extraction:
- The fine-tuned CLIP encoder processes the image pair $(I_{\text{before}}, I_{\text{after}})$ and outputs a difference-aware feature.
- Caption Generation:
- The extracted feature is fed into a Transformer-based captioning model, which generates a textual caption $T’$.
- Loss Optimization:
- A cross-entropy (XE) loss is applied to optimize the generated caption: \(\mathcal{L}_{\text{caption}} = -\sum_{t=1}^{T} \log P(y_t | y_{1:t-1}, v)\)
- This fine-tunes the Transformer decoder while keeping the updated CLIP embeddings.
3. Inference: Input and Output
After training, the model is used for inference (image difference captioning on new samples).
Inference Input and Output
- Input:
A pair of images $(I_{\text{before}}, I_{\text{after}})$.
- Output:
- A generated caption $T’$ describing the differences between the two images.
Inference Workflow
- Feature Extraction:
- The two images are passed through the fine-tuned CLIP visual encoder.
- A difference-aware embedding $v$ is computed.
- Caption Generation:
- The extracted feature $v$ is fed into the Transformer decoder.
- The decoder autoregressively generates the caption word by word.
- Final Output:
- The generated caption $T’$ is returned as the final output.
4. Summary
| Stage | Input | Updated Components | Output | | ————————- | ————————- | ————————– | ——————————— | | Retrieval Pretraining | Image pair + text caption | CLIP vision & text encoder | Improved image-text alignment | | Caption Fine-Tuning | Image pair | Transformer decoder | Generated caption | | Inference | Image pair | None (uses trained model) | Caption describing the difference |
🚀 CLIP4IDC effectively improves IDC tasks by fine-tuning CLIP for better image difference awareness and utilizing a Transformer decoder for high-quality caption generation.
Matryoshka Representation Learning
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
2023 Computer Vision and Pattern Recognition

Alpha 通道 在 Alpha-CLIP 中是一个 额外的输入通道,用于引导模型关注图像中的特定区域,从而增强 CLIP 在 区域感知任务(如目标识别、图像生成)上的能力。
1. 什么是 Alpha 通道?
在 计算机视觉和图像处理 中,常见的 RGB 图像 由 三个通道(Red, Green, Blue) 组成,每个通道表示像素的颜色信息。 Alpha 通道 是 第四个通道,用于表示图像的 透明度(Opacity) 或 权重掩码(Mask)。
在 Alpha-CLIP 中,Alpha 通道并不用于透明度,而是用于 标记模型应该关注的区域:
- Alpha 值为 1(白色) 的区域是 需要关注的目标区域。
- Alpha 值为 0(黑色) 的区域是 背景,模型不需要重点关注。
因此,Alpha 通道本质上是一个 “关注引导信号(Attention Map)”,告诉 CLIP 哪些部分更重要,从而提升模型的区域级理解能力。
2. Alpha 通道在 Alpha-CLIP 中的作用
在 原始 CLIP 中,模型会关注整个图像,并从整体上学习视觉特征,但它 无法区分哪些区域是重要的。Alpha-CLIP 通过 Alpha 通道 引导模型 专注于特定区域,避免对无关背景的干扰,从而提高模型在 区域级任务(如目标识别、Referring Expression、2D/3D 生成) 上的性能。
示例
假设有一张包含 猫和狗 的图片,而我们想让模型关注 猫:
- 普通 CLIP:会同时处理 猫和狗,可能会受到干扰。
- Alpha-CLIP:
- Alpha 通道 = 1(白色) → 选定的 “猫” 区域
- Alpha 通道 = 0(黑色) → “狗” 和背景区域
- 这样,模型在计算 CLIP 相似度时,就会优先关注猫,忽略狗和背景。
3. Alpha 通道的输入格式
在训练和推理时,Alpha-CLIP 的输入是 RGBA 图像,其中:
- RGB(3 通道):图像的颜色信息
- Alpha(1 通道):表示关注区域的掩码
通常,Alpha 通道的格式如下:
像素点位置 RGB 值(颜色) Alpha 值(关注度) 目标区域(猫) (255, 100, 50) 1.0(完全关注) 背景区域(狗) (120, 50, 200) 0.0(完全忽略) 边缘模糊部分 (180, 90, 40) 0.5(部分关注) 在模型训练时,Alpha 通道的信息会被输入到 Alpha Conv 层,用于调整 CLIP 关注的区域。
4. Alpha 通道 vs 其他方法
方法 方式 问题 裁剪(Cropping) 仅保留目标区域 损失背景信息,影响理解 像素级遮挡(Masking) 用黑色填充背景 丢失背景上下文,影响语义 红色圆圈(Red Circle) 在目标上加圈 改变原图,影响模型泛化 Alpha-CLIP(Ours) 额外输入 Alpha 通道 保留背景信息,同时强调目标区域 相比 裁剪、像素遮挡等方法,Alpha 通道的优势是:
- 不修改原始图像,仅增加额外引导信息。
- 可进行更细粒度的区域关注(不仅仅是矩形框,还能是任意形状的 mask)。
- 保持上下文信息,避免信息丢失
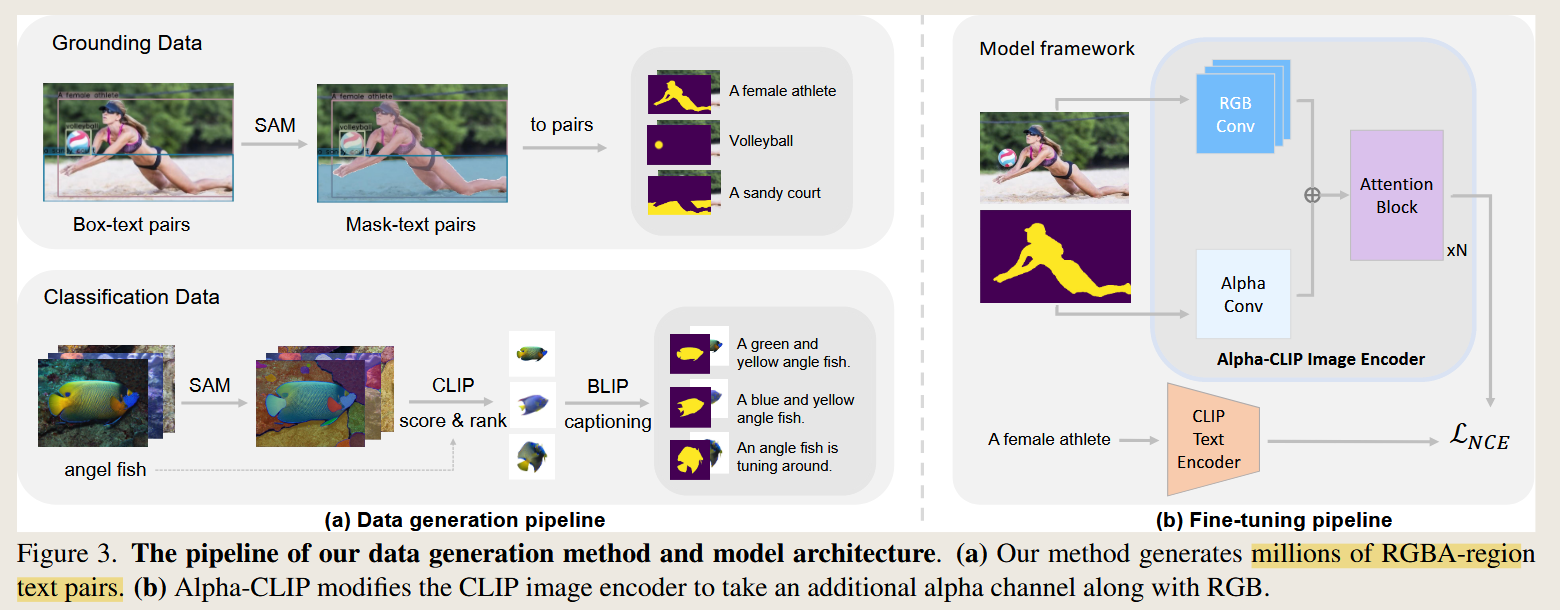
Alpha-CLIP 主要在 CLIP 的图像编码器(ViT) 结构上做了如下修改:
- 引入 Alpha 通道:在原本 RGB 输入 之外,增加 Alpha 通道,形成 RGBA 输入。
- Alpha Conv 层:增加一个 Alpha Conv(与原始 RGB Conv 并行),用于处理 Alpha 通道信息。
- Transformer 结构:继承原有 CLIP 的 Transformer 块,但对一部分进行 微调 以适应 Alpha 通道输入。
- 文本编码器不变:Alpha-CLIP 保持 CLIP 文本编码器不变,只微调图像编码器。
1.2 训练过程
训练输入:
- (RGBA 图像, 文本) 对(来自数据生成过程)
- Alpha 通道信息(标注目标区域)
- CLIP 文本嵌入向量(由 CLIP 文本编码器计算)
训练目标:
- 训练 Alpha-CLIP 的图像编码器使其:
- 仍能学习 全局图像特征
- 但能 更关注 Alpha 指定的区域 进行匹配
训练步骤:
文本编码器(固定权重) 计算 文本嵌入。
图像编码器(ViT + Alpha-Conv) 处理 RGBA 输入 生成 视觉特征。
计算
对比学习损失(Contrastive Loss):
\[\mathcal{L} = -\sum_{(I, T)} \log \frac{\exp(\text{sim}(F_I, F_T)/\tau)}{\sum_{j} \exp(\text{sim}(F_I, F_{T_j})/\tau)}\]
- 其中 $F_I$ 是 Alpha-CLIP 提取的图像特征,$F_T$ 是文本特征。
- 目标是让配对 (I, T) 的相似度最大化,而非配对的相似度最小化。
- 优化过程:
- 训练 Alpha-Conv 层权重
- 微调 ViT Transformer 部分权重
- 文本编码器保持冻结
- 混合数据训练策略:
- 设定 10% 训练数据 不带 Alpha 通道(即全 1),确保模型仍能进行 全局图像理解。
训练更新的部分:
- Alpha-Conv 层(新增)
- ViT Transformer 层(部分参数)
- 其余部分(文本编码器 & 预训练的 CLIP 参数)不变
训练输出:
- 更新后的 Alpha-CLIP 模型
- 具备 区域感知能力 的 图像编码器(能关注 Alpha 选定区域)
Tune-An-Ellipse: CLIP Has Potential to Find What You Want

- 提出了 可微视觉提示方法,使 CLIP 能够 无需外部目标检测器 即可进行 零样本对象定位。
- 通过 椭圆参数优化,本方法能够 逐步拟合目标区域,

GUIDING INSTRUCTION-BASED IMAGE EDITING VIA MULTIMODAL LARGE LANGUAGE MODELS
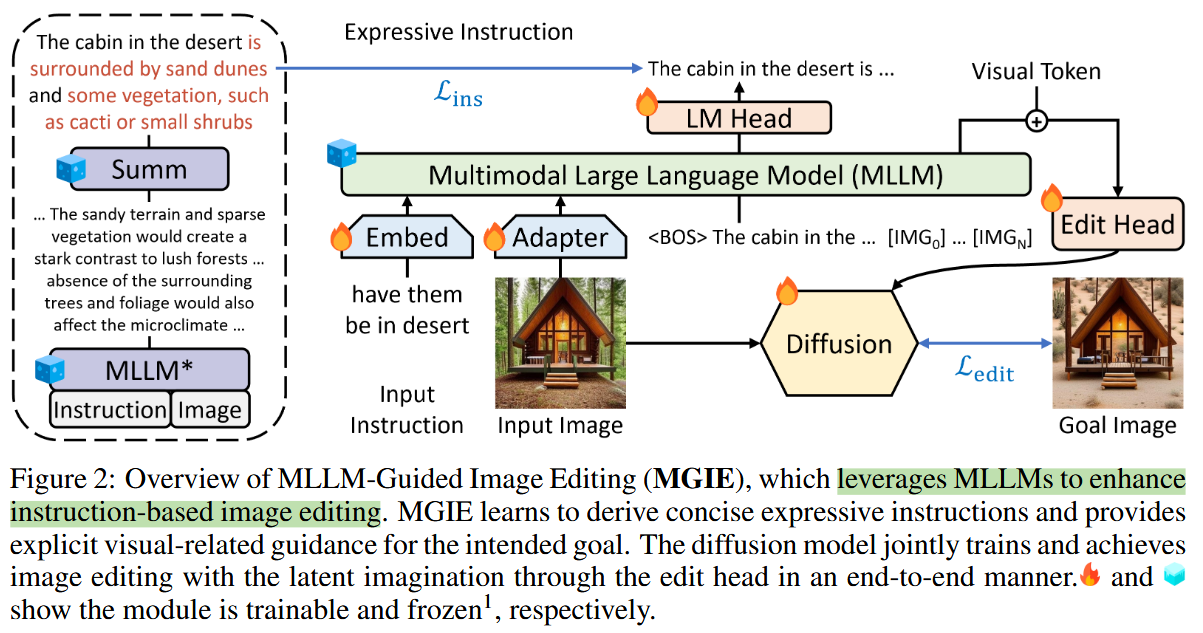

Training Model Architecture
Architecture Components:
- Multimodal Large Language Model (MLLM): Processes input text and generates refined expressive instructions.
- Edit Head (T): Converts textual instructions into latent visual features.
Stable Diffusion Model: Performs the actual image editing in a latent space.
Training Inputs and Outputs:
- Inputs: Input image $V$, initial instruction $X$, and ground-truth goal image $O$.
Outputs: Edited image $O’$ matching the goal image $O$ as closely as possible.
- Training Process:
Instruction Derivation: The MLLM refines $X$ into an expressive instruction $E$.
Latent Representation: The edit head transforms $E$ into a latent visual representation $U$.
Image Editing: The diffusion model generates $O’$ from $V$ using $U$ as a guiding condition.
Loss Computation:
\[L_{ins} = \sum_{t=1}^{l} CELoss(w'_t, w_t)\] \[L_{edit} = \mathbb{E}[||\epsilon - \epsilon_\theta(z_t, t, V, \{u\})||^2]\]Optimization:
\[L_{all} = L_{ins} + 0.5 \cdot L_{edit}\]Updates occur in:
- MLLM: Trains the word embeddings and LM head to refine instruction generation.
- Edit Head: Learns to map textual instructions to latent visual representations.
- Diffusion Model: Fine-tunes parameters for image editing based on guidance.
Inference Process
- Inputs:
- Image $V$.
- Instruction $X$.
- Outputs:
- Edited image $O’$.
- Inference Steps:
- Instruction Processing: The MLLM generates refined expressive instruction $E$.
- Latent Feature Transformation: The edit head converts $E$ into latent features $U$.
- Image Editing: The diffusion model generates $O’$ from $V$, guided by $U$.
- Final Output: The edited image $O’$ is decoded and presented.
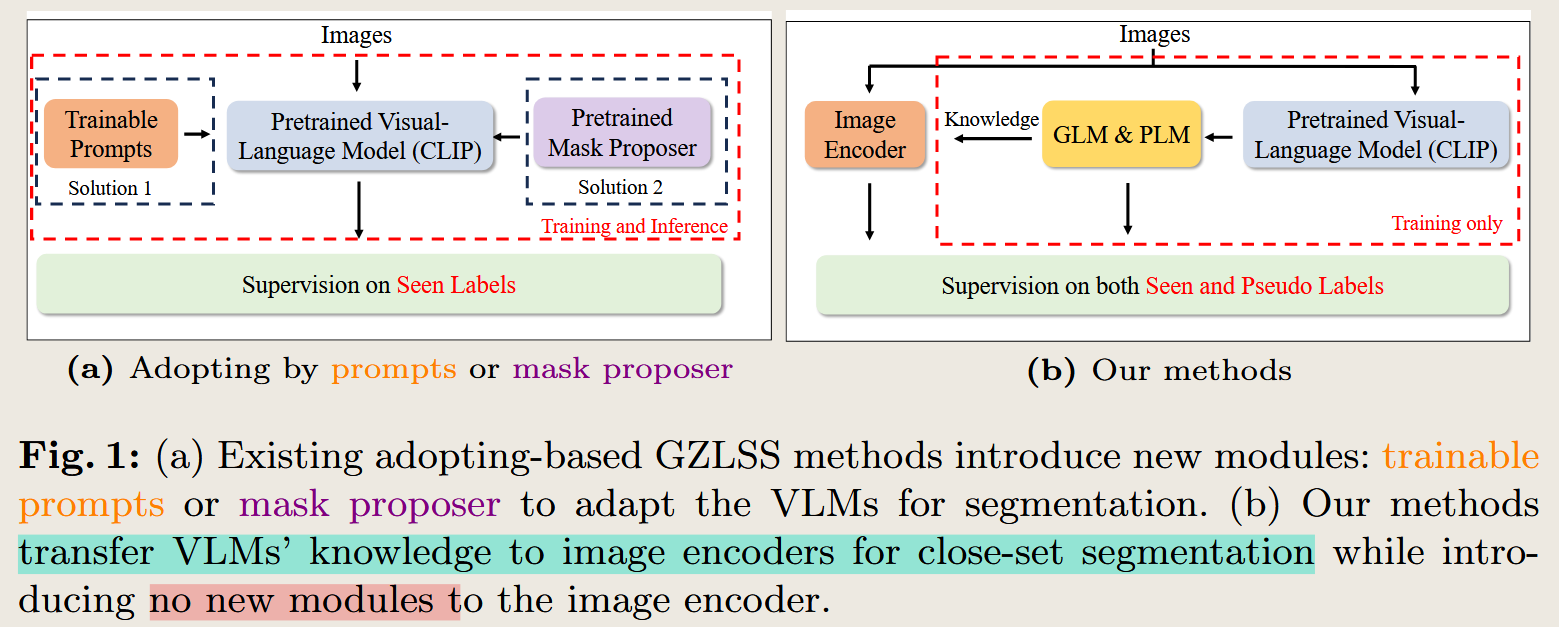
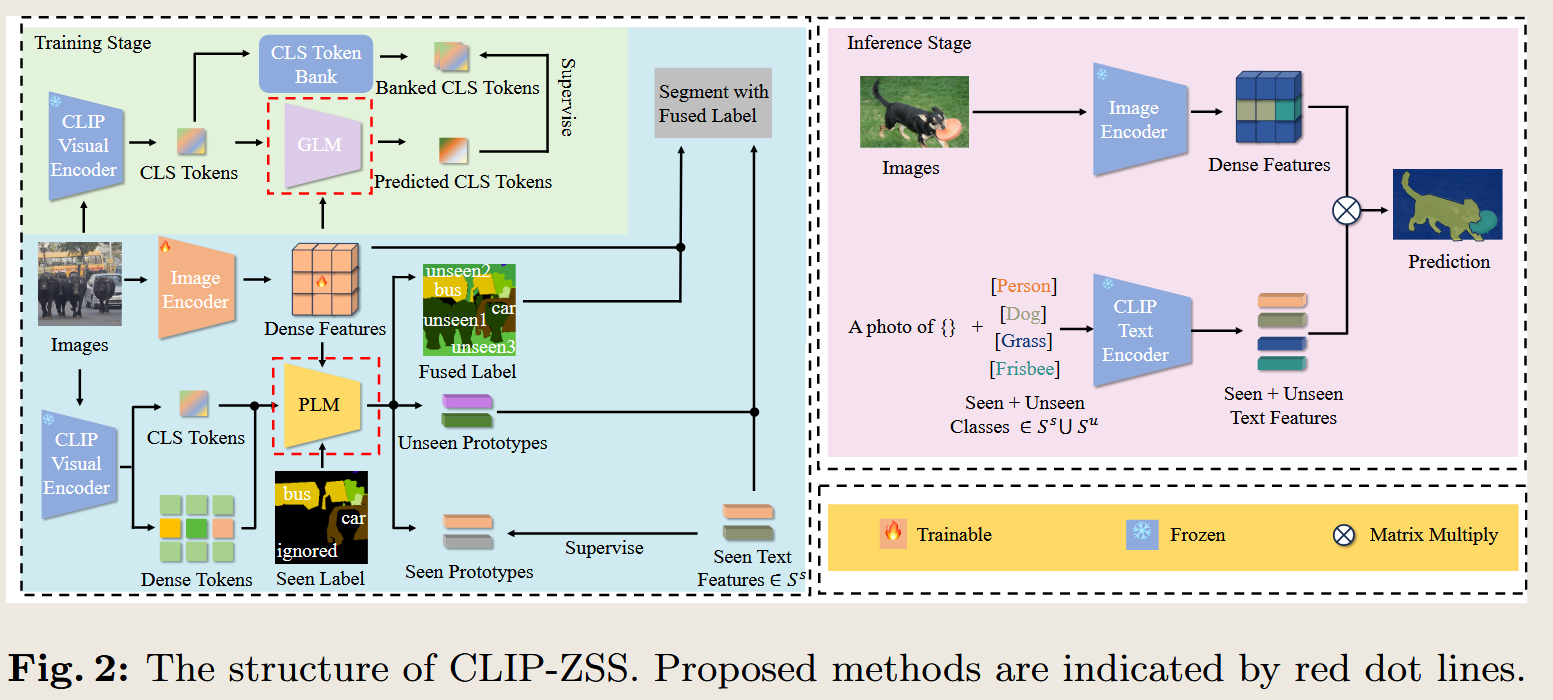
CLIP is Also a Good Teacher: A New Training Framework for Inductive Zero-shot Semantic Segmentation
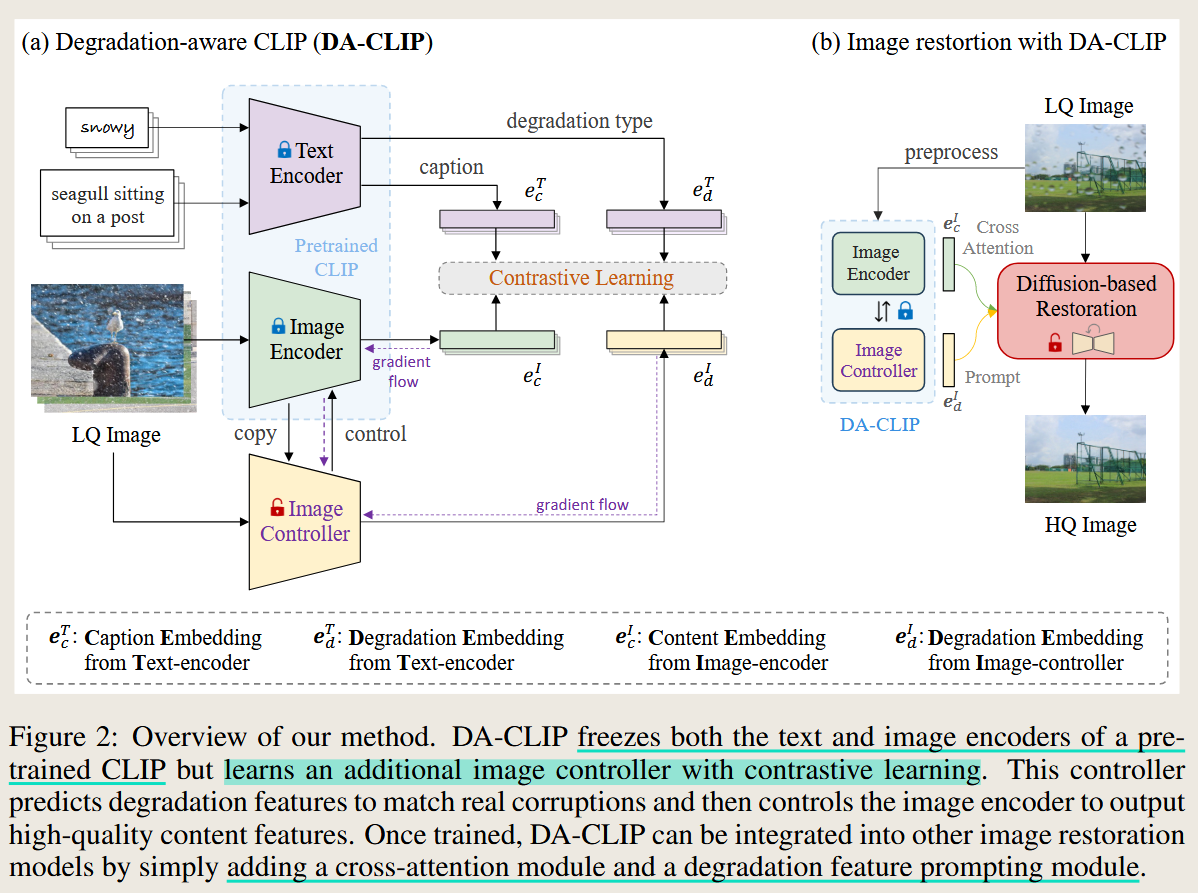
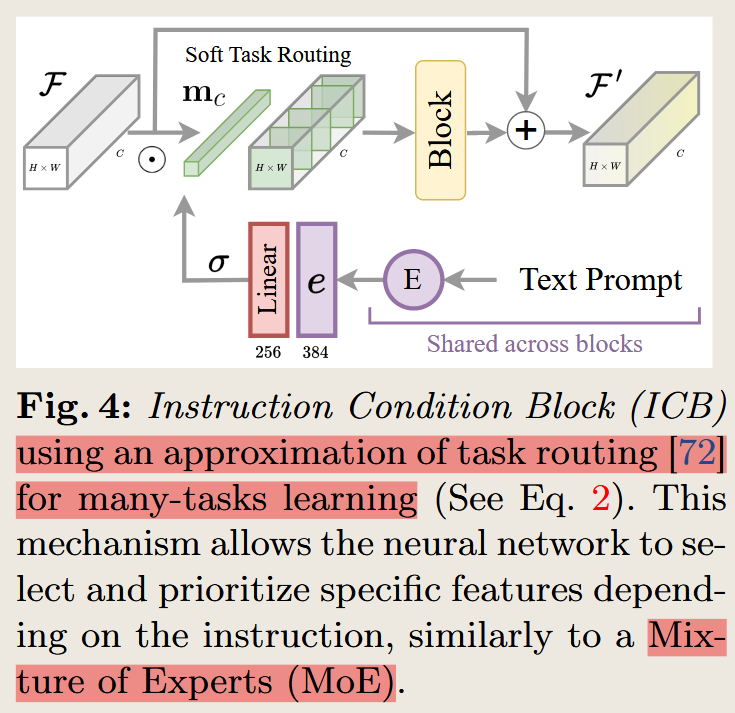
CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION
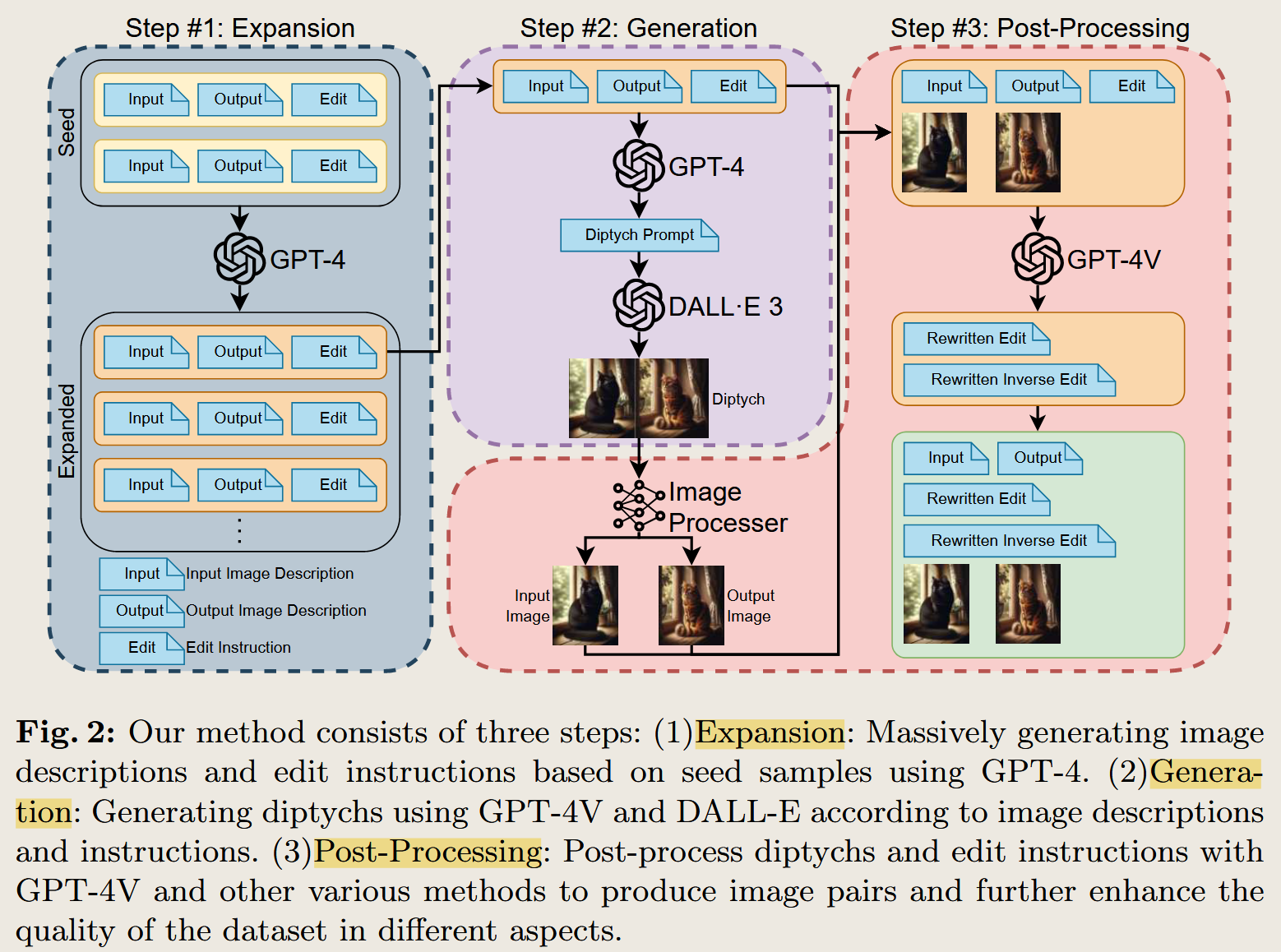
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
FastEdit: Fast Text-Guided Single-Image Editing via Semantic-Aware Diffusion Fine-Tuning
2024 arXiv.org

InstructIR: High-Quality Image Restoration Following Human Instructions
2024 European Conference on Computer Vision
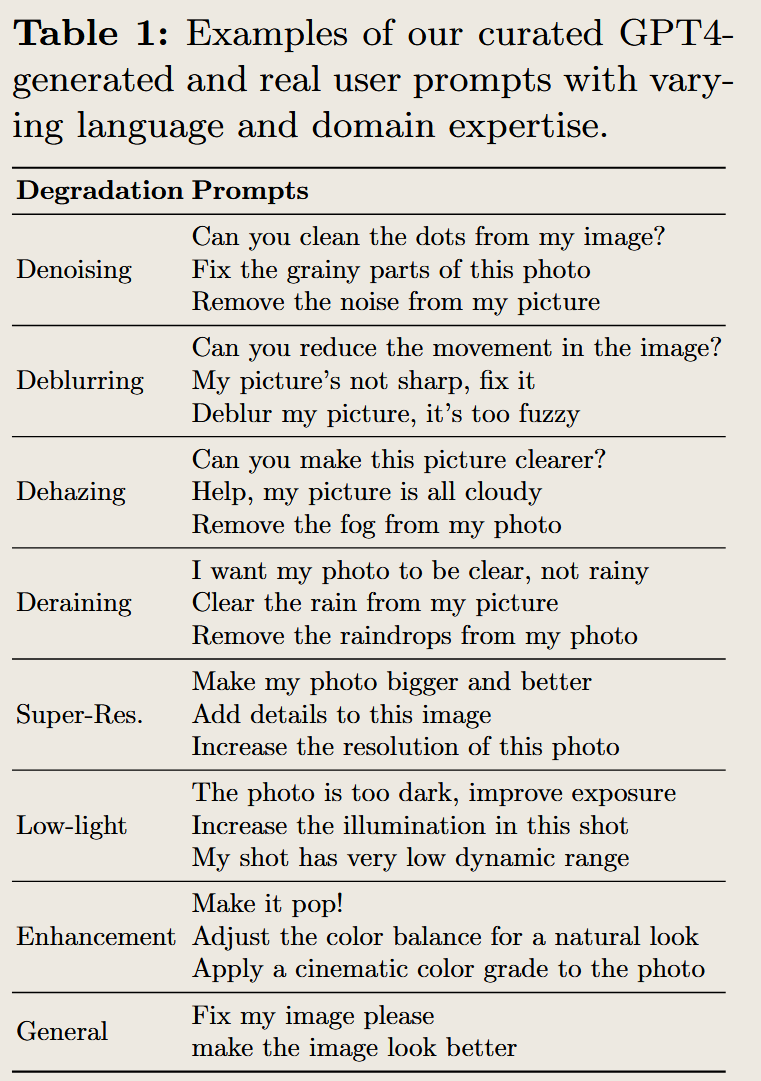



GG-Editor: Locally Editing 3D Avatars with Multimodal Large Language Model Guidance
2024 ACM Multimedia
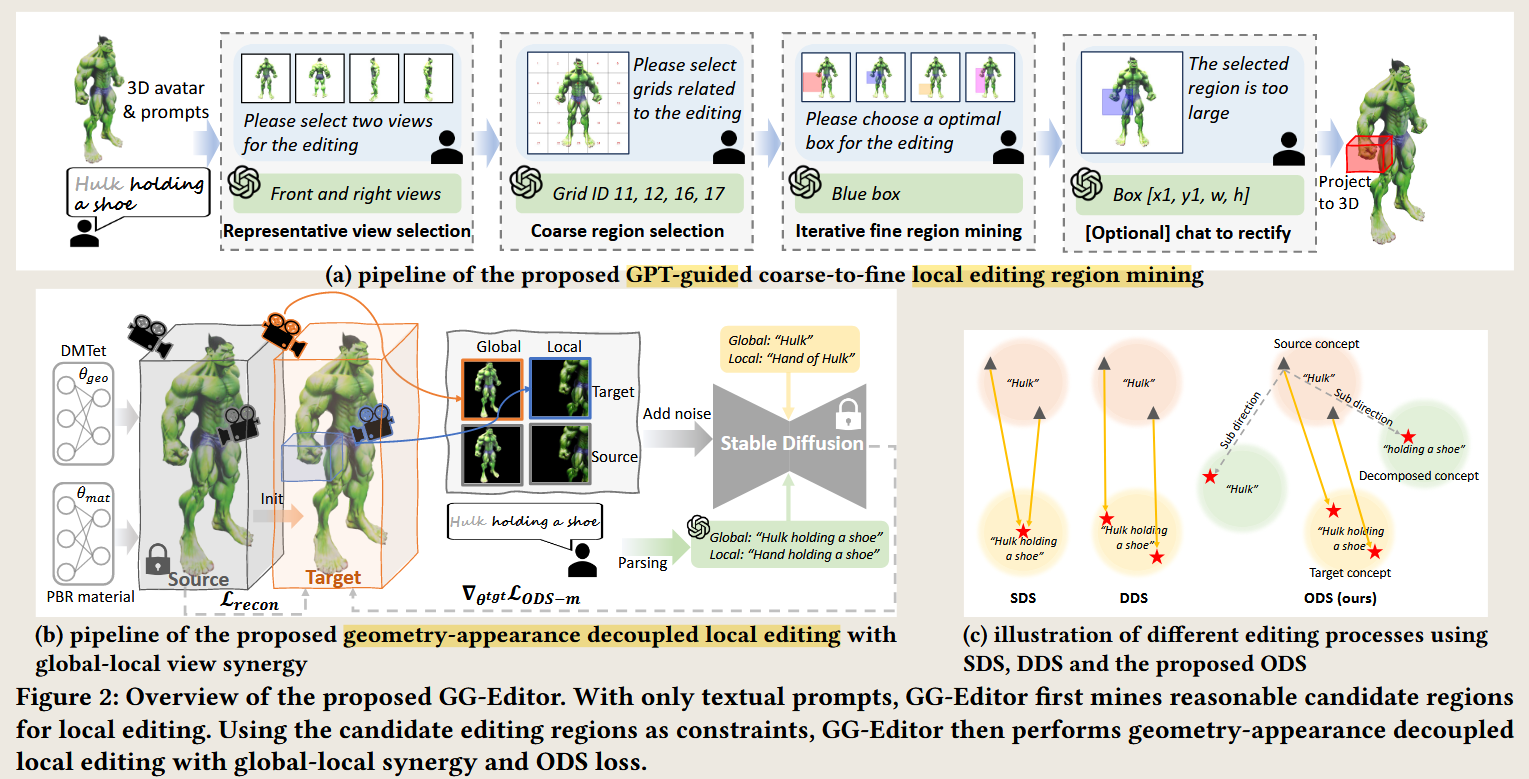
infer reasonable local editing regions.
CorrCLIP: Reconstructing Correlations in CLIP with Off-the-Shelf Foundation Models for Open-Vocabulary Semantic Segmentation
2024 arXiv.org

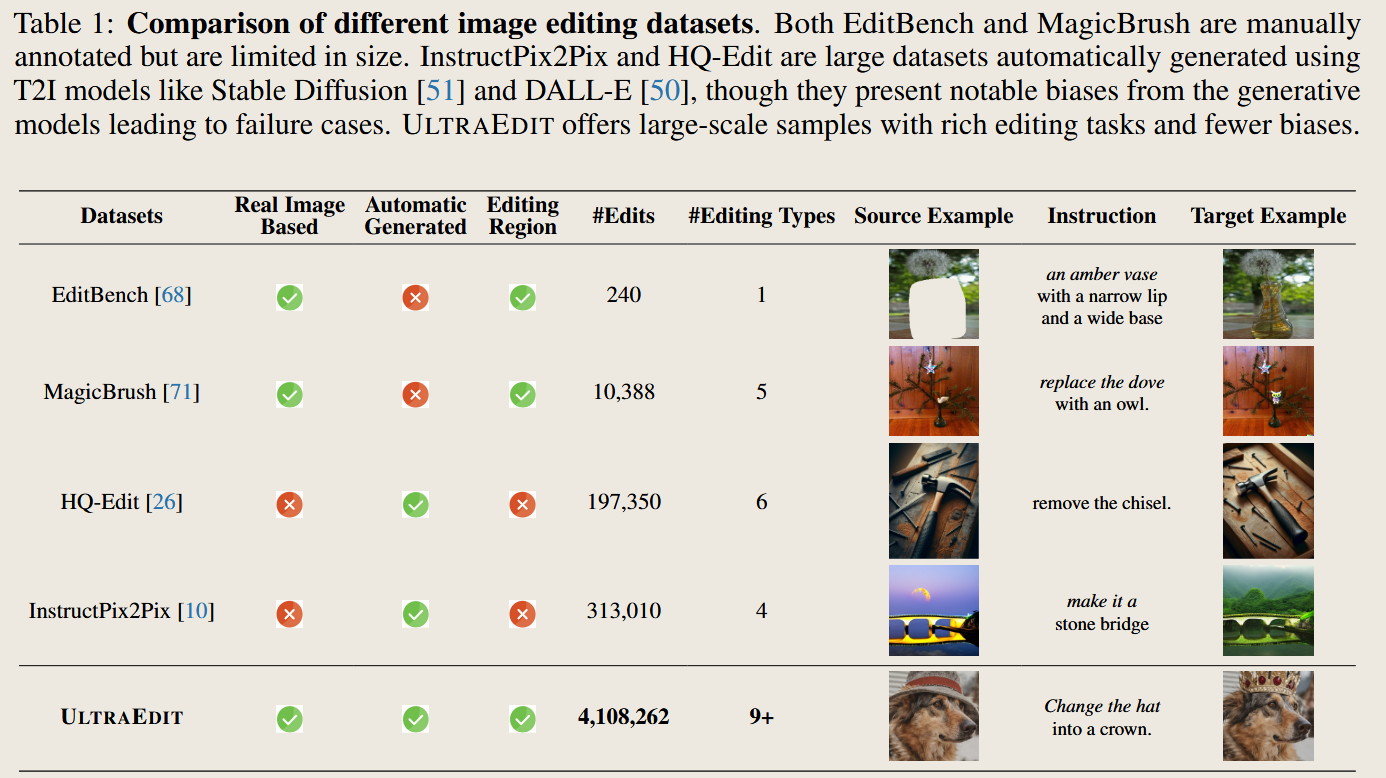
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale
2024 arXiv.org
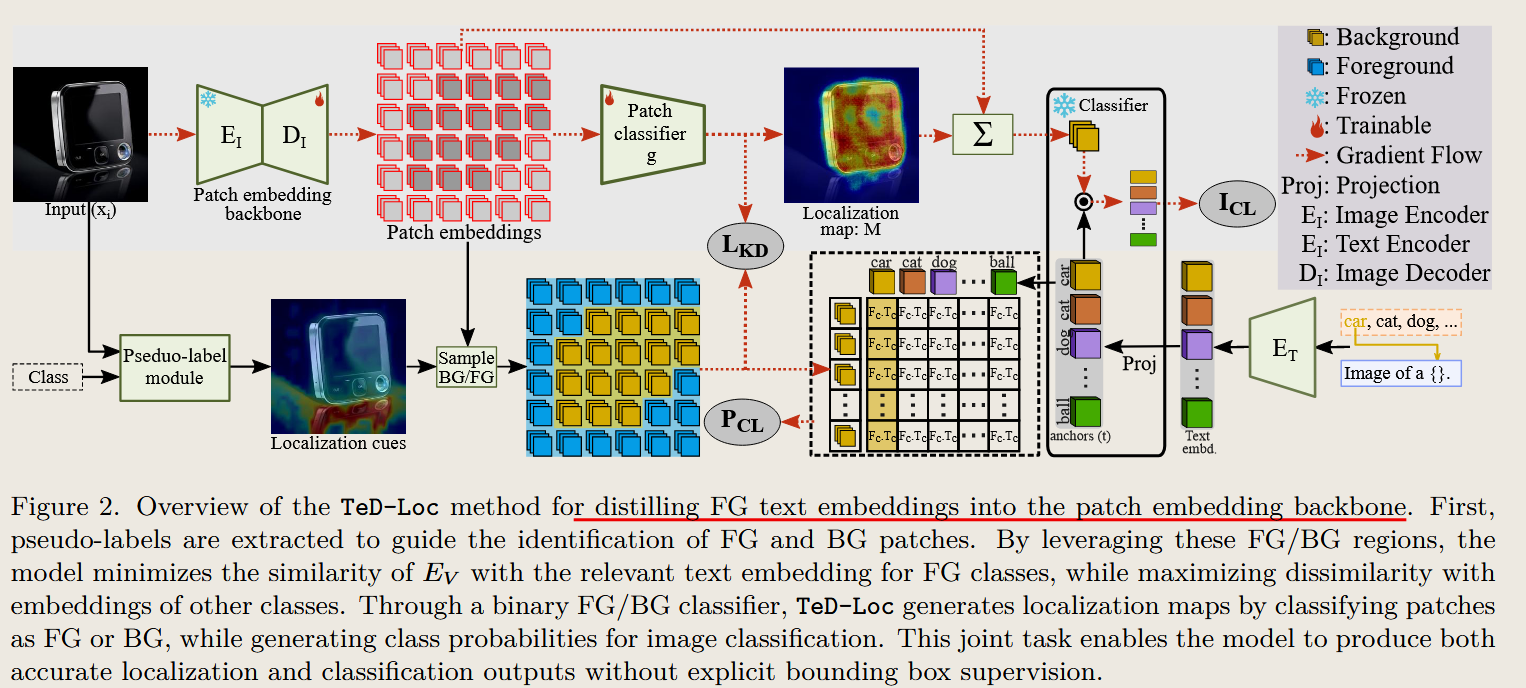
TeD-Loc: Text Distillation for Weakly Supervised Object Localization
2025
EchoLM: Accelerating LLM Serving with Real-time Knowledge Distillation
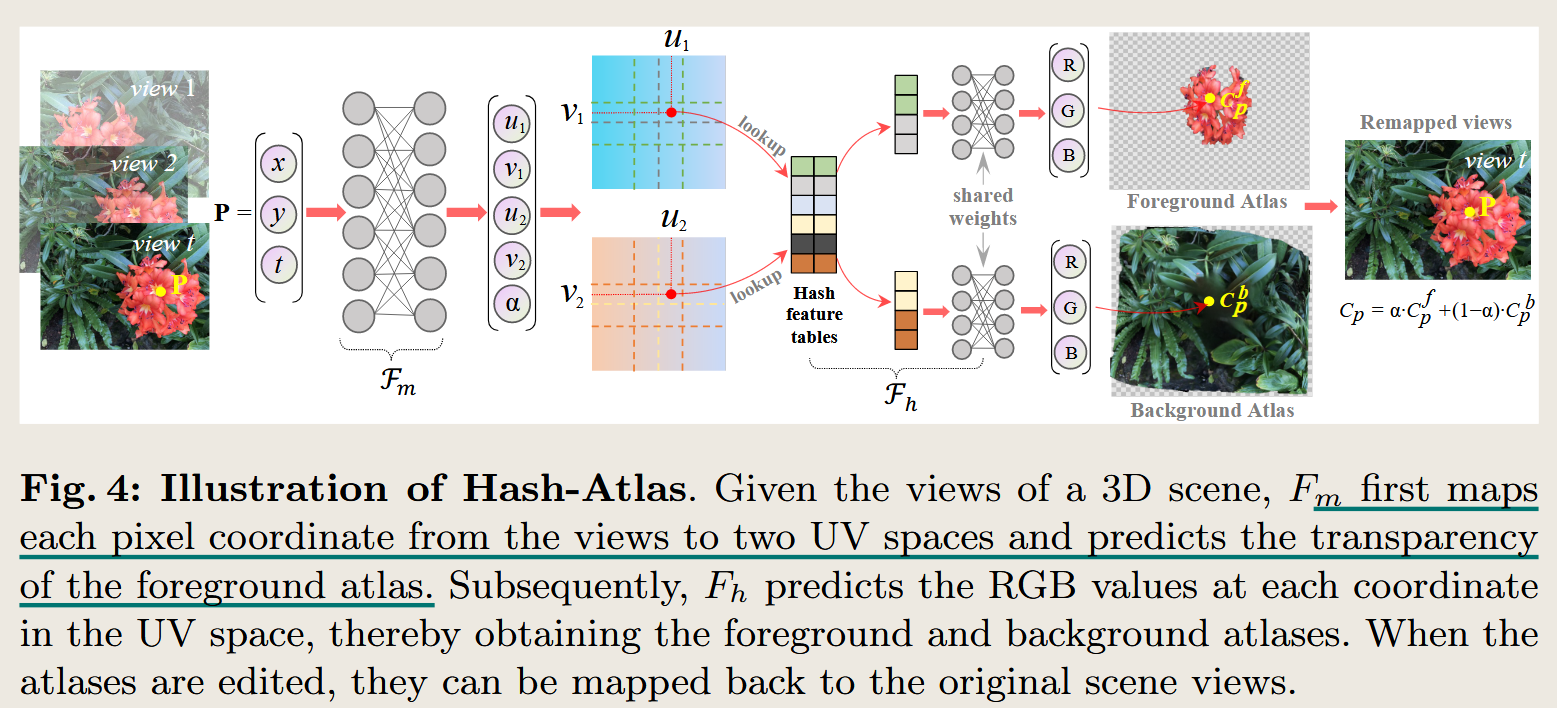
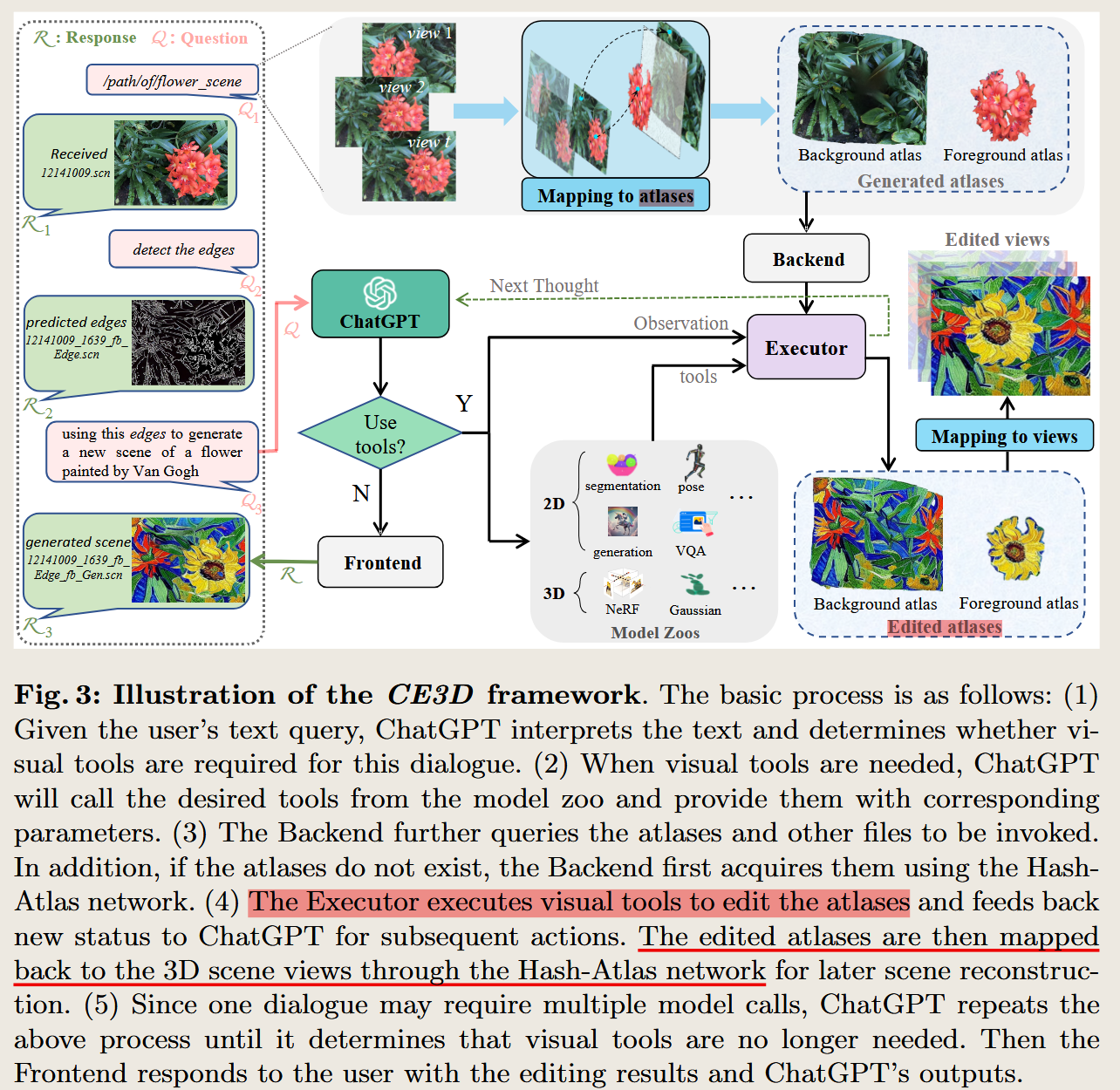
Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts
2024 European Conference on Computer Vision
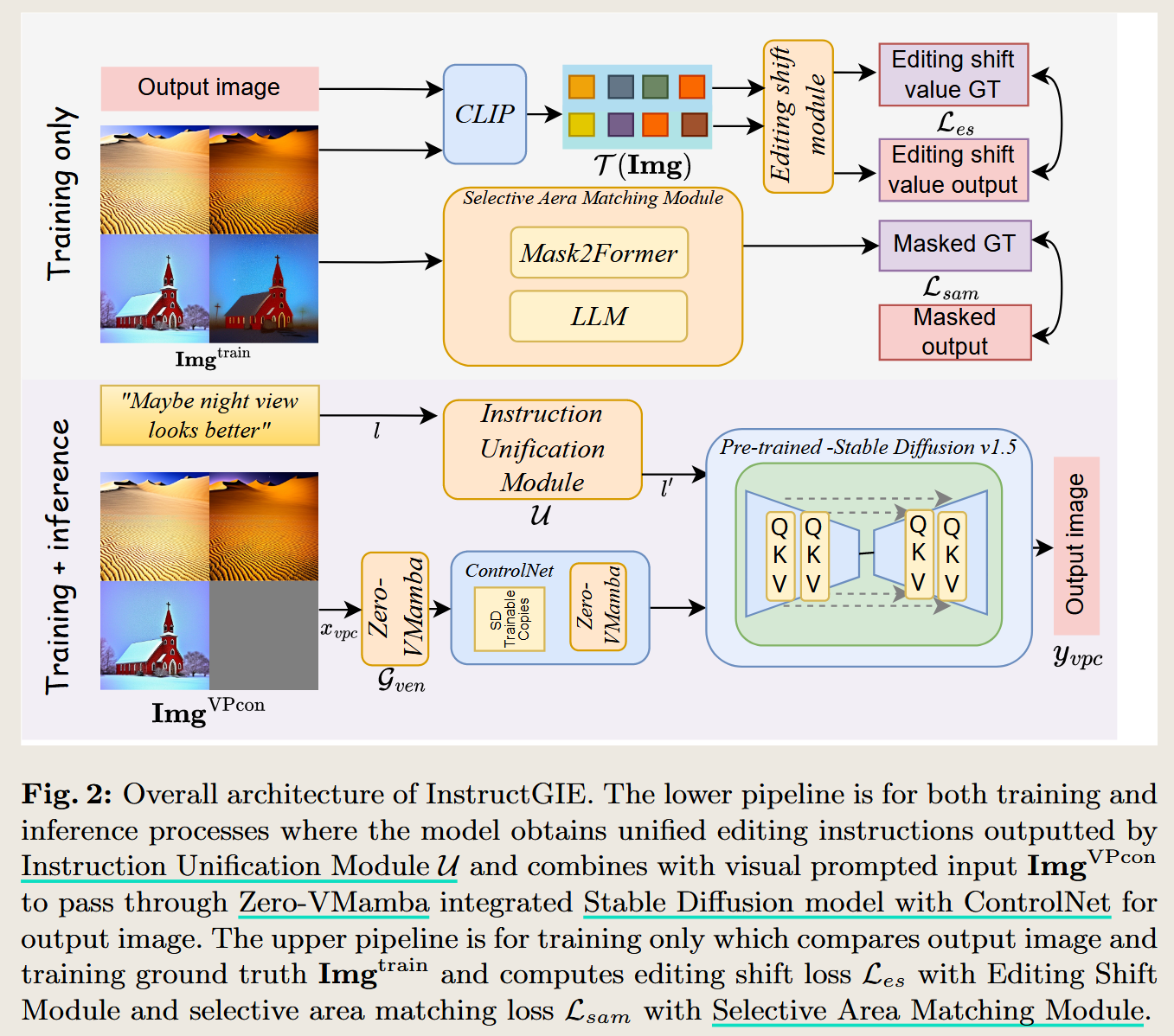
InstructGIE: Towards Generalizable Image Editing
2024 European Conference on Computer Vision
TurboEdit: Instant text-based image editing
2024 European Conference on Computer Vision

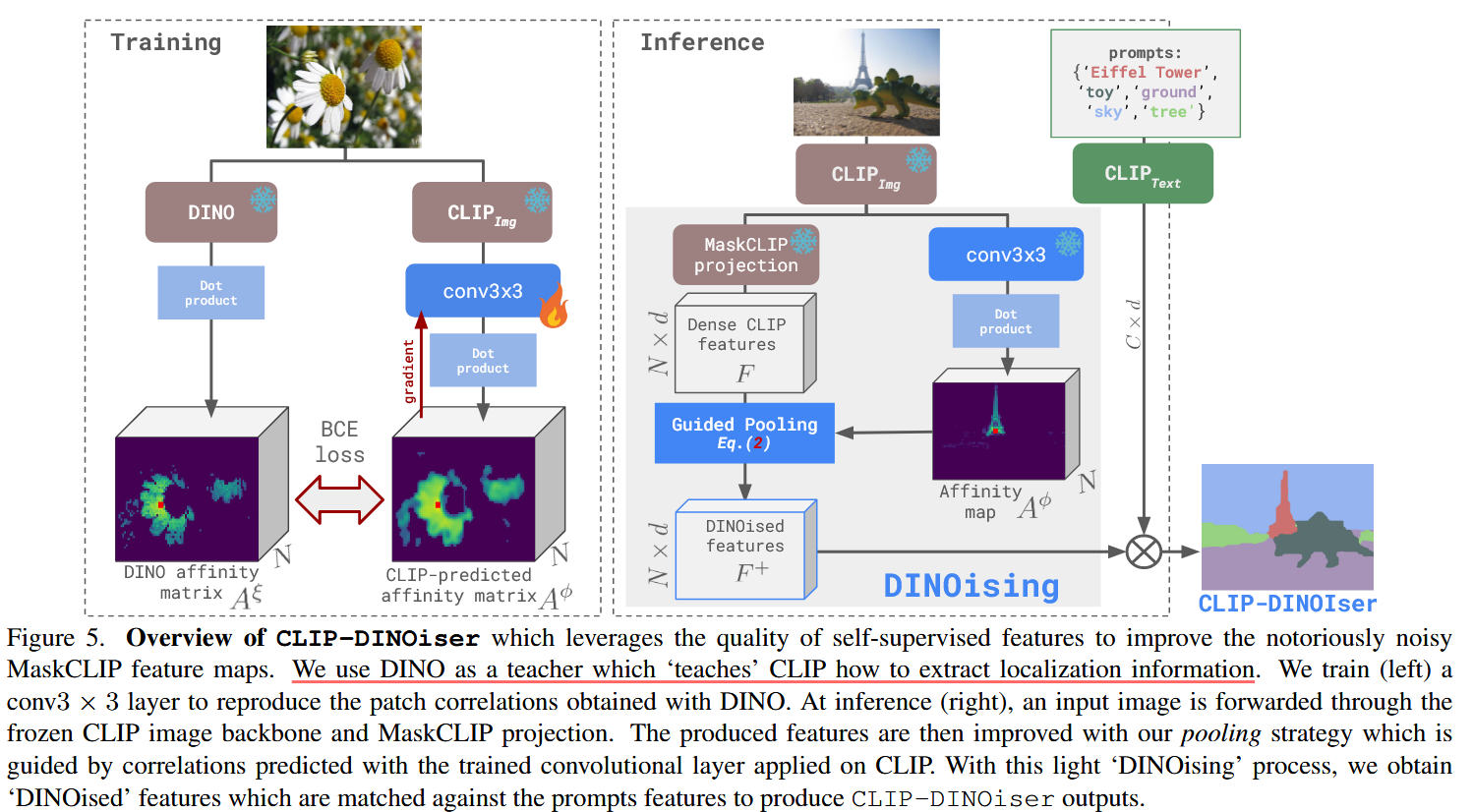
CLIP-DINOiser: Teaching CLIP a few DINO tricks for open-vocabulary semantic segmentation
2023 European Conference on Computer Vision
InstructPix2Pix: Learning to Follow Image Editing Instructions

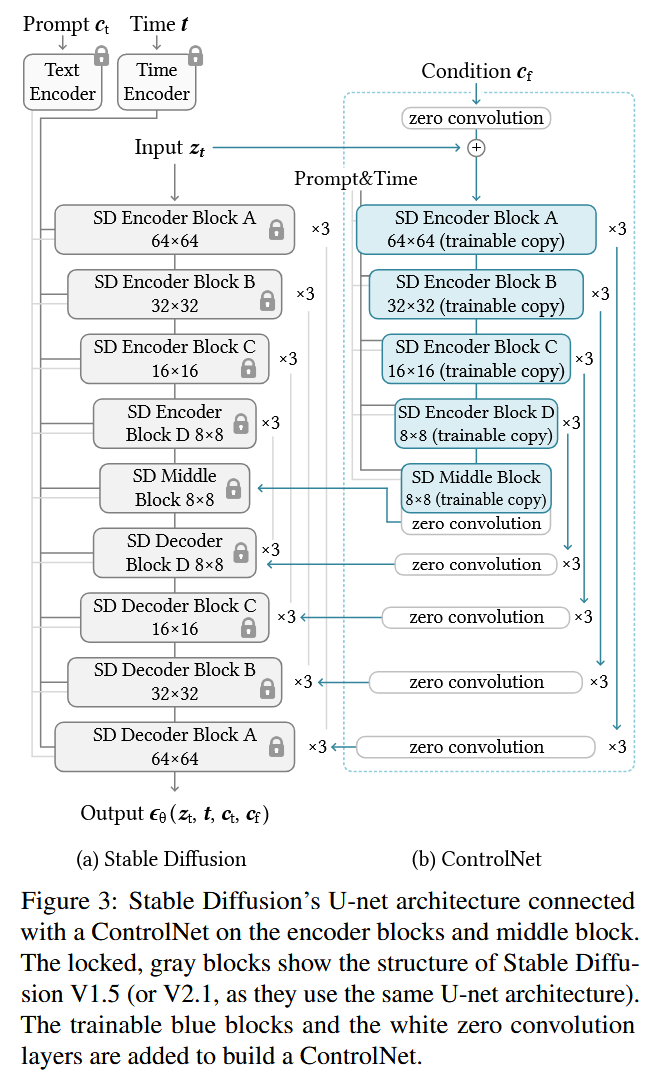
Adding Conditional Control to Text-to-Image Diffusion Models
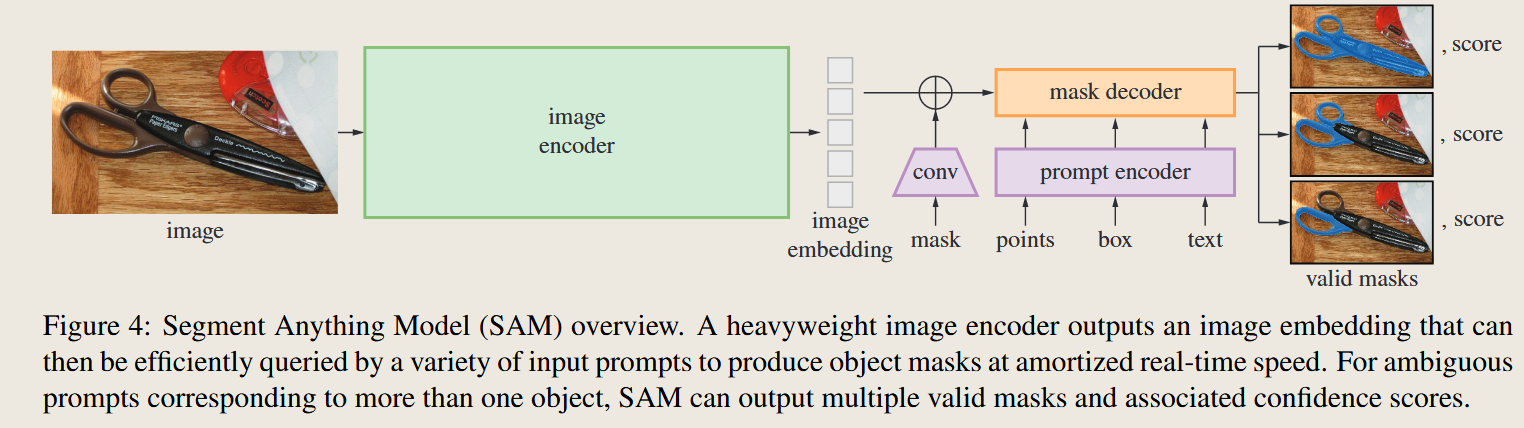
Segment Anything
2023 IEEE International Conference on Computer Vision
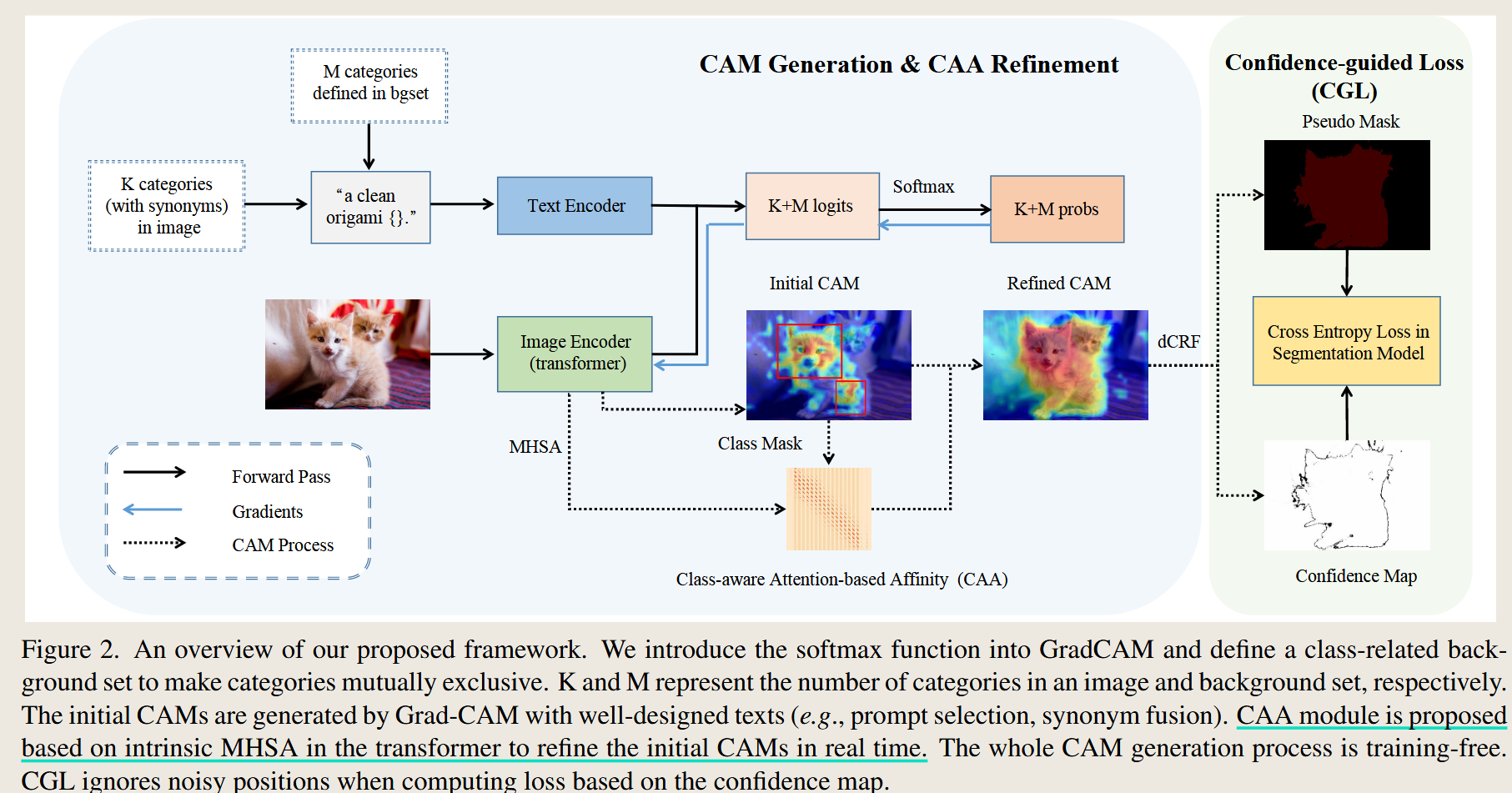
CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation
2022 Computer Vision and Pattern Recognition
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/wiki/Paper%20Reading%20List-CLIP/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)