Paper Reading– Diffusion
survey
Diffusion Model-Based Image Editing: A Survey
Diffusion Model-Based Image Editing: A Survey.
2024 arXiv.org
Huang, Y., Huang, J., Liu, Y., Yan, M., Lv, J., Liu, J., Xiong, W., Zhang, H., Chen, S., Cao, L., 2024. Diffusion Model-Based Image Editing: A Survey. https://doi.org/10.48550/arXiv.2402.17525
summary in the slide
https://docs.google.com/presentation/d/1PvwGrplcqXzUEV0LZ0NTbSAtgS1t2W8WAmM5Q9z92HU/edit?usp=sharing
Image Edit related to background change
Blended Latent Diffusion
Blended Latent Diffusion
2022 ACM Transactions on Graphics
Avrahami, O., Fried, O., Lischinski, D., 2023. Blended Latent Diffusion. ACM Trans. Graph. 42, 1–11. https://doi.org/10.1145/3592450

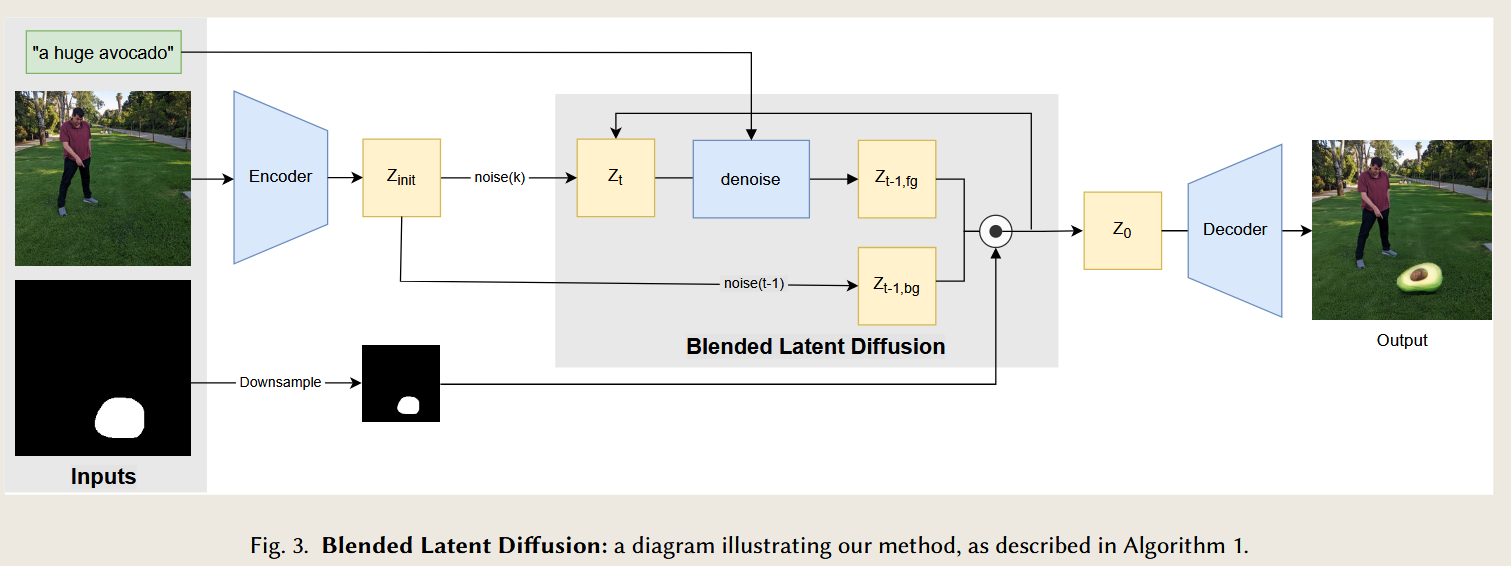
Blended Diffusion for Text-driven Editing of Natural Images
Blended Diffusion for Text-driven Editing of Natural Images
Avrahami, O., Lischinski, D., Fried, O., 2022. Blended Diffusion for Text-driven Editing of Natural Images, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, New Orleans, LA, USA, pp. 18187–18197. https://doi.org/10.1109/CVPR52688.2022.01767


GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M., 2022. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. https://doi.org/10.48550/arXiv.2112.10741

The Stable Artist: Steering Semantics in Diffusion Latent Space
The Stable Artist: Steering Semantics in Diffusion Latent Space
Brack, M., Schramowski, P., Friedrich, F., Hintersdorf, D., Kersting, K., 2023. The Stable Artist: Steering Semantics in Diffusion Latent Space. https://doi.org/10.48550/arXiv.2212.06013


InstructPix2Pix: Learning To Follow Image Editing Instructions
InstructPix2Pix: Learning To Follow Image Editing Instructions
2022 Computer Vision and Pattern Recognition
Brooks, T., Holynski, A., Efros, A.A., 2023. InstructPix2Pix: Learning To Follow Image Editing Instructions. Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18392–18402.


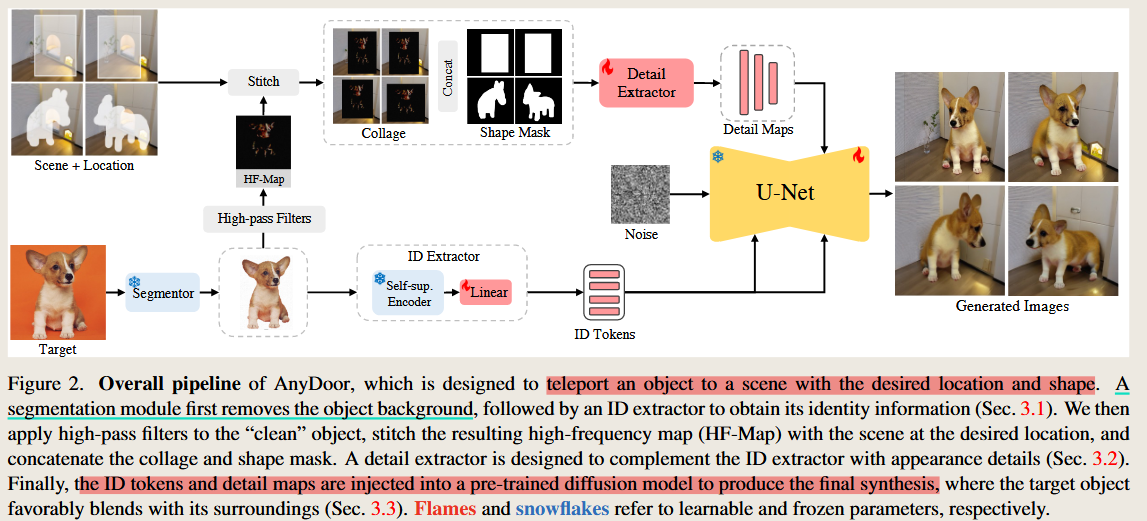
AnyDoor: Zero-shot Object-level Image Customization
AnyDoor: Zero-shot Object-level Image Customization
2023 Computer Vision and Pattern Recognition
Chen, X., Huang, L., Liu, Y., Shen, Y., Zhao, D., Zhao, H., 2024. AnyDoor: Zero-shot Object-level Image Customization. https://doi.org/10.48550/arXiv.2307.09481


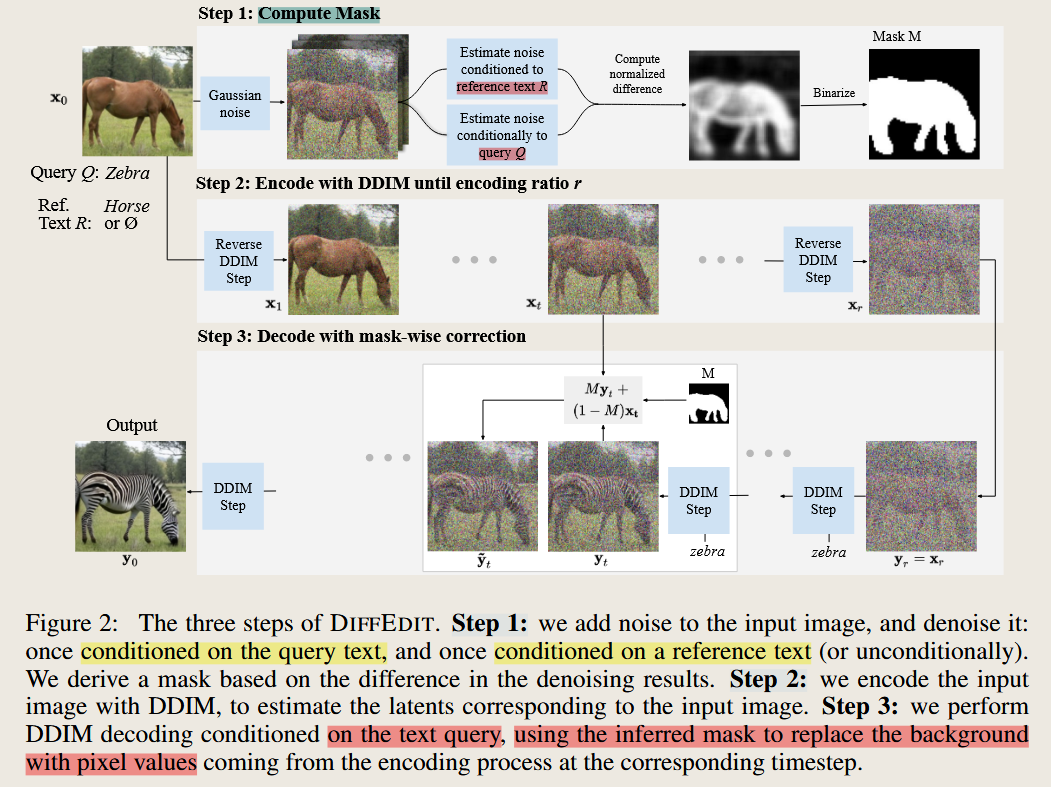
DiffEdit: Diffusion-based semantic image editing with mask guidance
DiffEdit: Diffusion-based semantic image editing with mask guidance
2022 International Conference on Learning Representations
Couairon, G., Verbeek, J., Schwenk, H., Cord, M., 2022. DiffEdit: Diffusion-based semantic image editing with mask guidance. https://doi.org/10.48550/arXiv.2210.11427

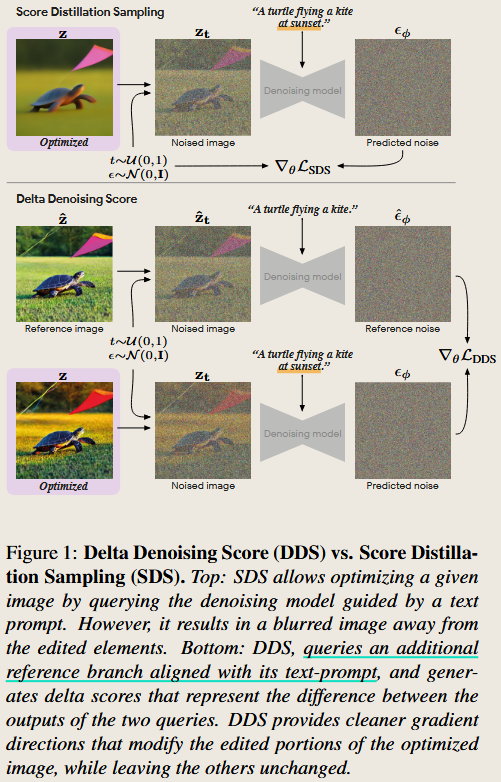
Delta Denoising Score.
Delta Denoising Score
2023 IEEE International Conference on Computer Vision
Hertz, A., Aberman, K., Cohen-Or, D., 2023. Delta Denoising Score. Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2328–2337.



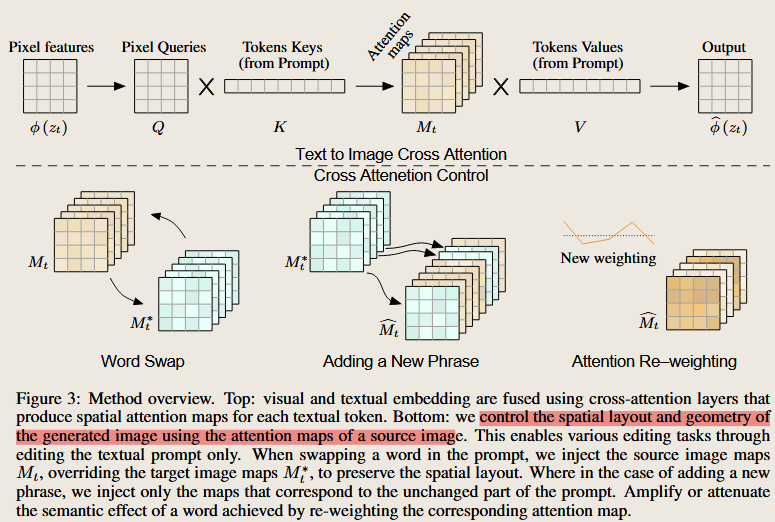
Prompt-to-Prompt Image Editing with Cross Attention Control
Prompt-to-Prompt Image Editing with Cross Attention Control
2022 International Conference on Learning Representations
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D., 2022. Prompt-to-Prompt Image Editing with Cross Attention Control. https://doi.org/10.48550/arXiv.2208.01626

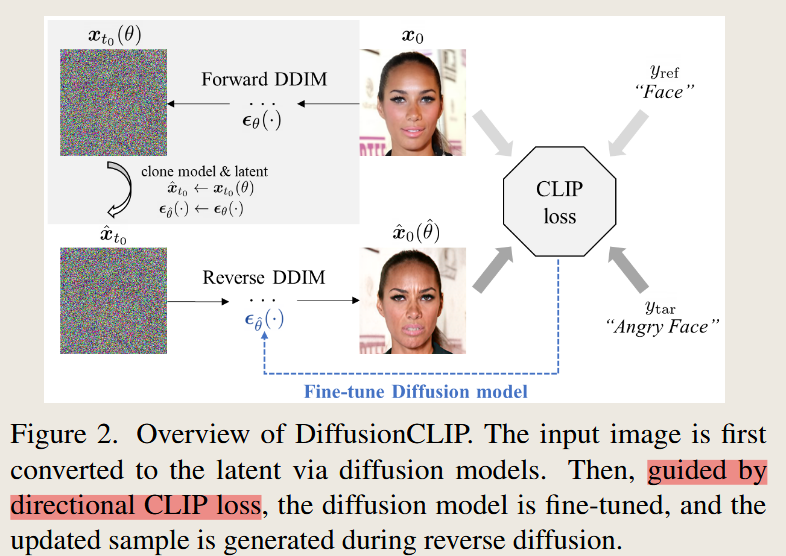
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
Kim, G., Kwon, T., Ye, J.C., 2022. DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, New Orleans, LA, USA, pp. 2416–2425. https://doi.org/10.1109/CVPR52688.2022.00246

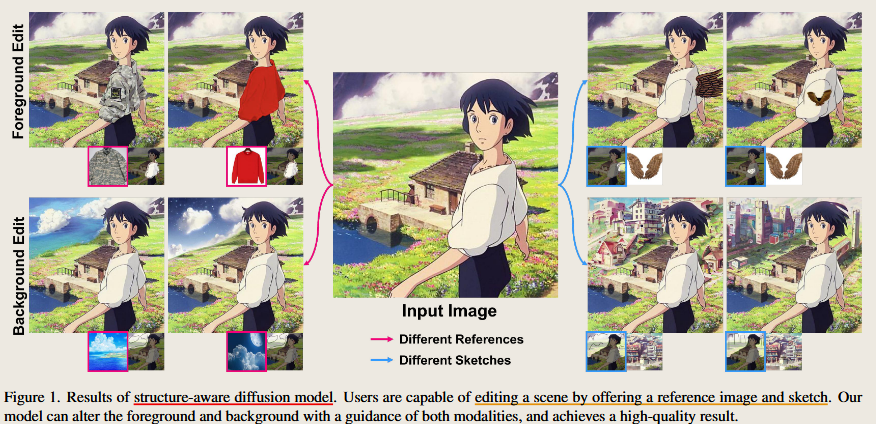
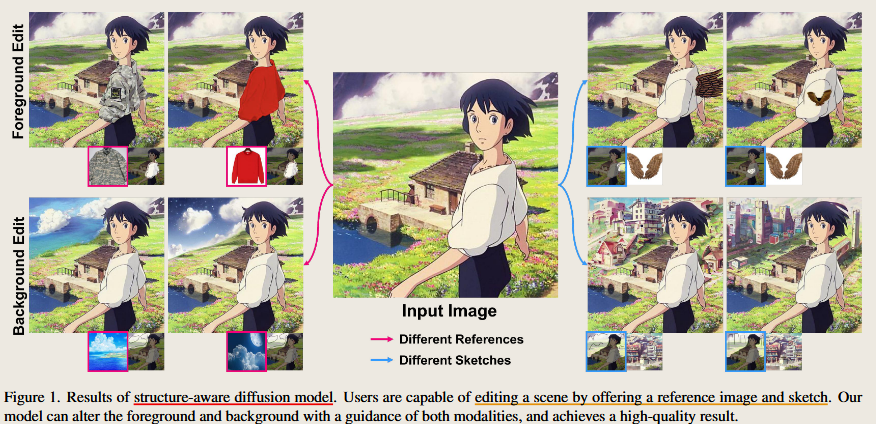
Reference-based Image Composition with Sketch via Structure-aware Diffusion Model
Reference-based Image Composition with Sketch via Structure-aware Diffusion Model
2023 arXiv.org
Kim, K., Park, S., Lee, J., Choo, J., 2023. Reference-based Image Composition with Sketch via Structure-aware Diffusion Model. https://doi.org/10.48550/arXiv.2304.09748



Diffusion-based Image Translation using Disentangled Style and Content Representation
Diffusion-based Image Translation using Disentangled Style and Content Representation
Kwon, G., Ye, J.C., 2023. Diffusion-based Image Translation using Disentangled Style and Content Representation. https://doi.org/10.48550/arXiv.2209.15264
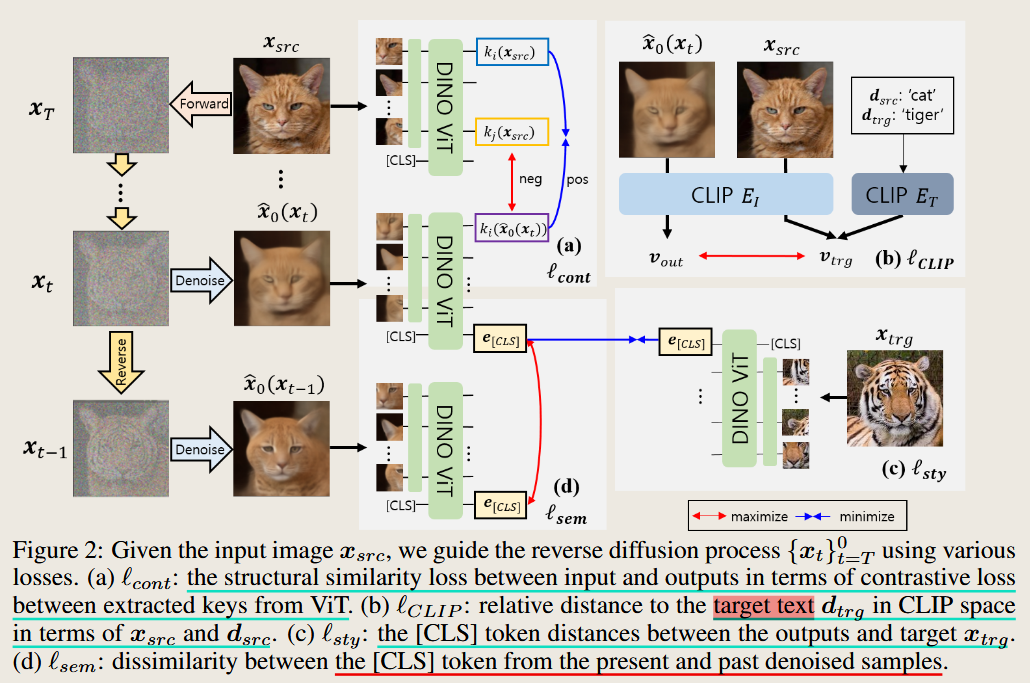


LayerDiffusion: Layered Controlled Image Editing with Diffusion Models
LayerDiffusion: Layered Controlled Image Editing with Diffusion Models
2023 SIGGRAPH Asia 2023 Technical Communications
Li, P., Huang, Q., Ding, Y., Li, Z., 2023. LayerDiffusion: Layered Controlled Image Editing with Diffusion Models, in: SIGGRAPH Asia 2023 Technical Communications. Presented at the SA ’23: SIGGRAPH Asia 2023, ACM, Sydney NSW Australia, pp. 1–4. https://doi.org/10.1145/3610543.3626172
MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers
MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers
2023 arXiv.org
Li, Sijia, Chen, C., Lu, H., 2024. MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers. https://doi.org/10.48550/arXiv.2309.04372


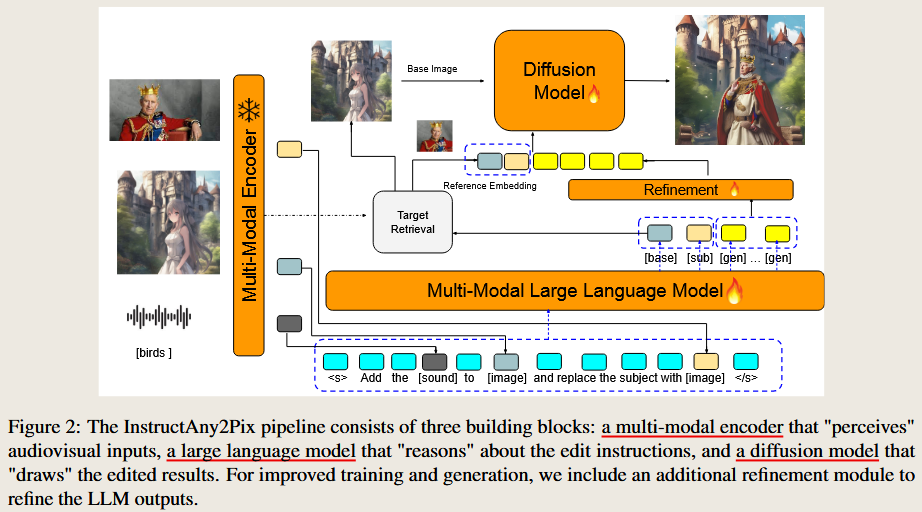
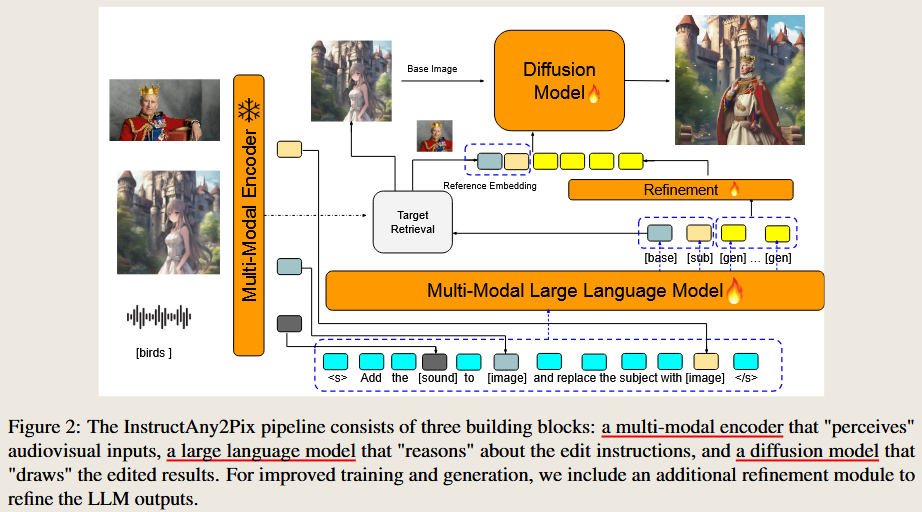
InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following
InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following
2023 arXiv.org
Li, Shufan, Singh, H., Grover, A., 2024. InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following. https://doi.org/10.48550/arXiv.2312.06738

Null-text Inversion for Editing Real Images using Guided Diffusion Models
Null-text Inversion for Editing Real Images using Guided Diffusion Models
2022 Computer Vision and Pattern Recognition
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D., 2023. Null-text Inversion for Editing Real Images using Guided Diffusion Models, in: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Vancouver, BC, Canada, pp. 6038–6047. https://doi.org/10.1109/CVPR52729.2023.00585


ObjectStitch: Object Compositing with Diffusion Model
ObjectStitch: Object Compositing with Diffusion Model
2023 Computer Vision and Pattern Recognition
Song, Y., Zhang, Z., Lin, Z., Cohen, S., Price, B., Zhang, J., Kim, S.Y., Aliaga, D., 2023. ObjectStitch: Object Compositing with Diffusion Model, in: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 18310–18319. https://doi.org/10.1109/CVPR52729.2023.01756


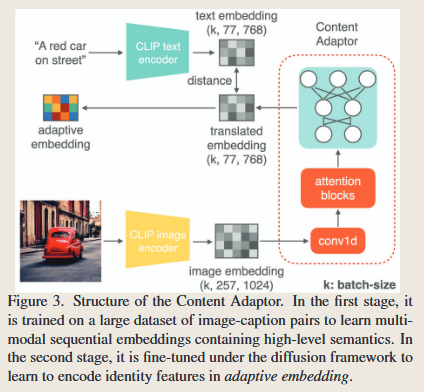
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models.
2023 arXiv.org
Starodubcev, N., Baranchuk, D., Khrulkov, V., Babenko, A., 2023. Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models. https://doi.org/10.48550/arXiv.2304.04344


ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation.
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation.
2023 Neural Information Processing Systems
Sun, Y., Yang, Yifan, Peng, H., Shen, Y., Yang, Yuqing, Hu, H., Qiu, L., Koike, H., n.d. ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation.
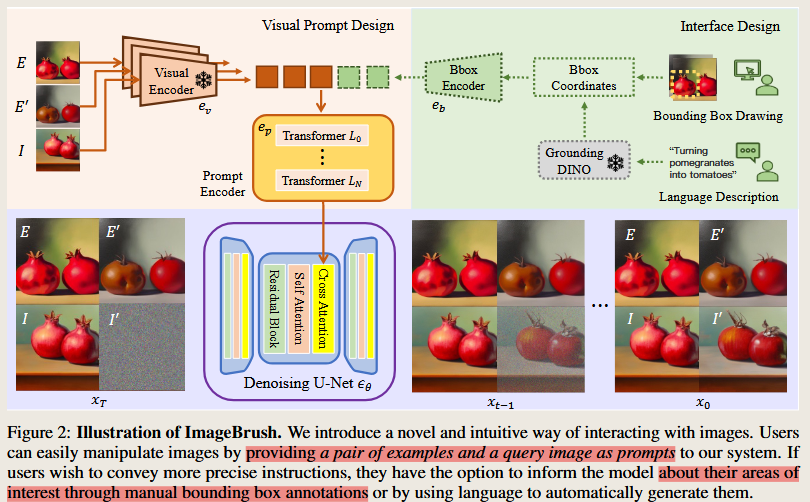
UniTune: Text-Driven Image Editing by Fine Tuning a Diffusion Model on a Single Image
UniTune: Text-Driven Image Editing by Fine Tuning a Diffusion Model on a Single Image.
2022 ACM Transactions on Graphics
Valevski, D., Kalman, M., Molad, E., Segalis, E., Matias, Y., Leviathan, Y., 2023. UniTune: Text-Driven Image Editing by Fine Tuning a Diffusion Model on a Single Image. ACM Trans. Graph. 42, 1–10. https://doi.org/10.1145/3592451
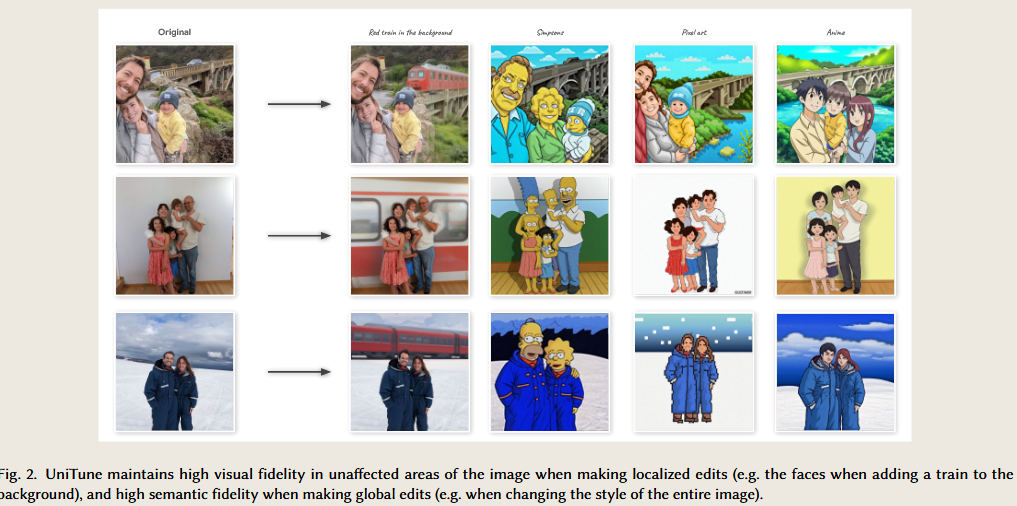
InstructEdit: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions.
InstructEdit: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions.
2023 arXiv.org
Wang, Q., Zhang, B., Birsak, M., Wonka, P., 2023. InstructEdit: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions. https://doi.org/10.48550/arXiv.2305.18047

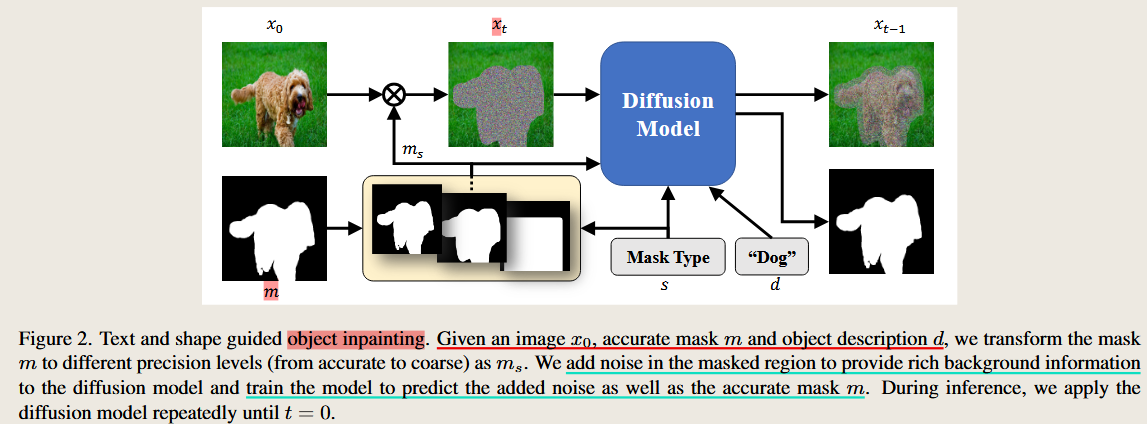
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model.
2022 Computer Vision and Pattern Recognition
Xie, S., Zhang, Z., Lin, Z., Hinz, T., Zhang, K., 2022. SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model. https://doi.org/10.48550/arXiv.2212.05034


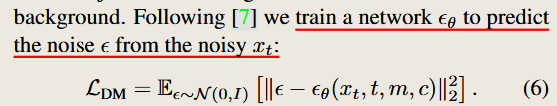
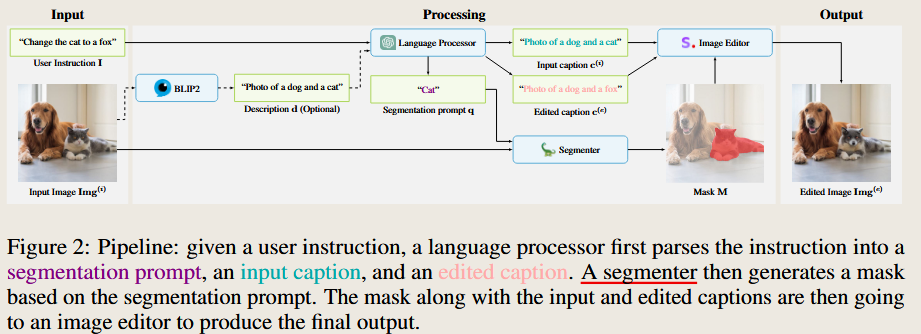
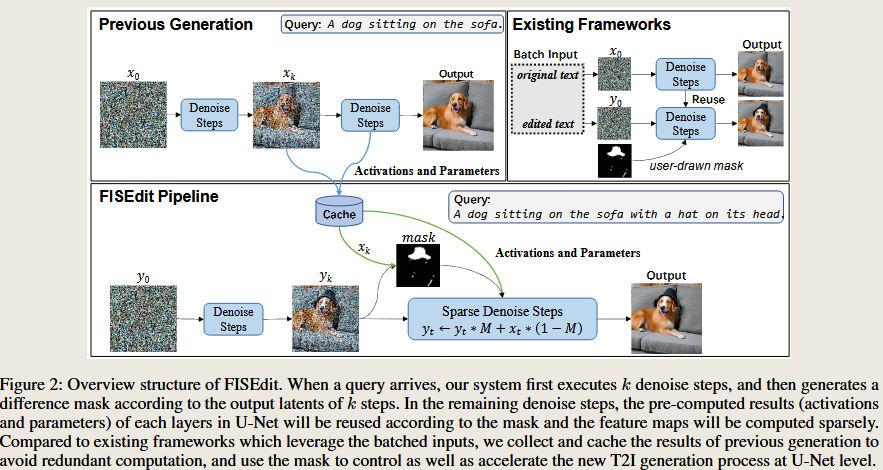
Accelerating Text-to-Image Editing via Cache-Enabled Sparse Diffusion Inference
Accelerating Text-to-Image Editing via Cache-Enabled Sparse Diffusion Inference.
2023 AAAI Conference on Artificial Intelligence
Yu, Z., Li, H., Fu, F., Miao, X., Cui, B., 2024. Accelerating Text-to-Image Editing via Cache-Enabled Sparse Diffusion Inference. Proceedings of the AAAI Conference on Artificial Intelligence 38, 16605–16613. https://doi.org/10.1609/aaai.v38i15.29599
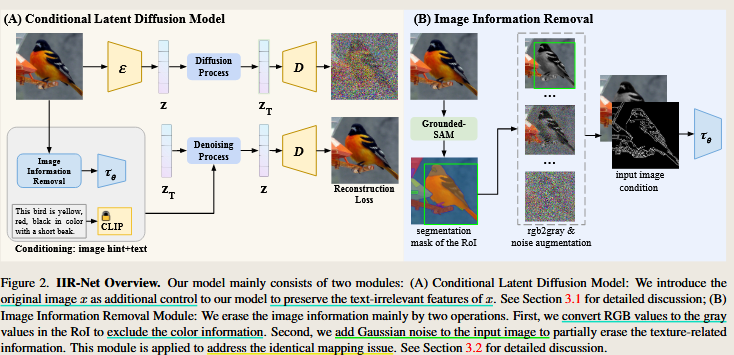
Text-to-image Editing by Image Information Removal
Text-to-image Editing by Image Information Removal
2023 IEEE Workshop/Winter Conference on Applications of Computer Vision
Zhang, Z., Zheng, J., Fang, J.Z., Plummer, B.A., 2024. Text-to-image Editing by Image Information Removal, in: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Presented at the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE, Waikoloa, HI, USA, pp. 5220–5229. https://doi.org/10.1109/WACV57701.2024.00515


文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/wiki/Paper%20Reading%20List-Diffusion/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)