Paper Reading–LLM and forgetting
Survey
2025
2024
Towards Lifelong Learning of Large Language Models: A Survey
2024 arXiv.org

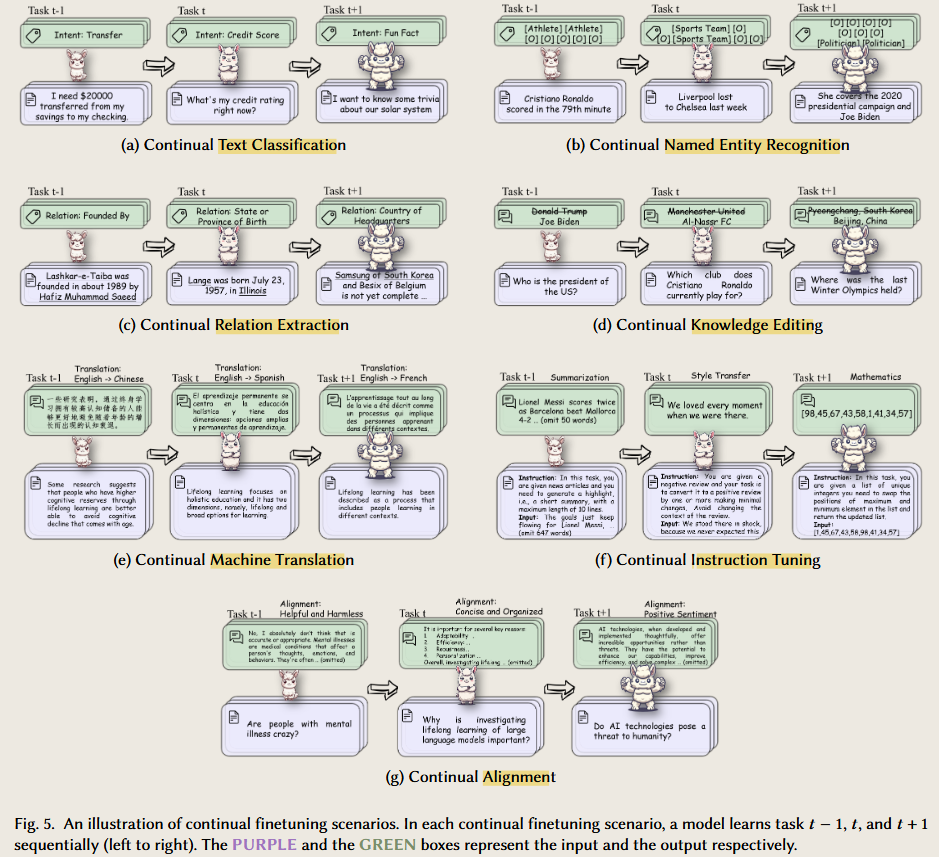
Forgetting in LLM
- EFFECT OF MODEL AND PRETRAINING SCALE ON CATASTROPHIC FORGETTING IN NEURAL NETWORKS
2022
scale matters, big model have high anti-forgetting abilty
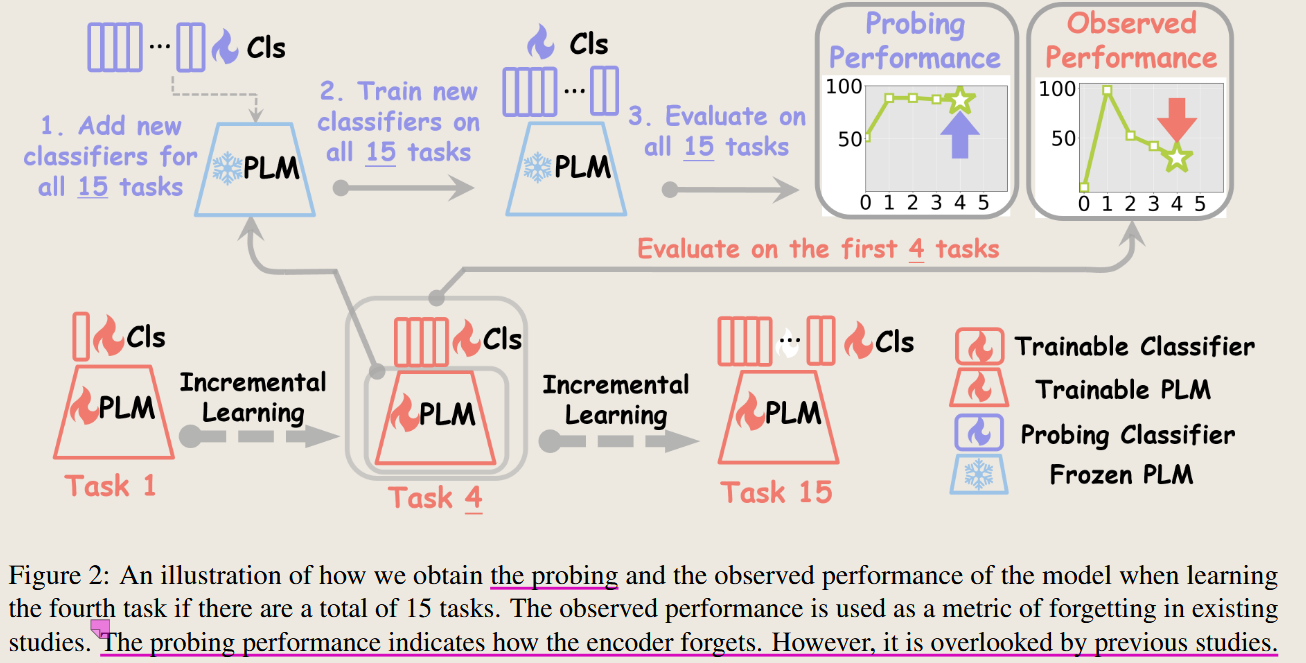
CAN BERT REFRAIN FROM FORGETTING ON SEQUENTIAL TASKS? A PROBING STUDY
2023 International Conference on Learning Representations
预训练模型有着很强的持续学习能力,同一任务下的子任务在训练前后保持有序,但是会和新的任务数据产生重叠,这是遗忘的主要原因,而 之前数据的加入会减轻这种遗忘。

Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
2023 Annual Meeting of the Association for Computational Linguistics
使用了上面一片论文提出的probing performance的思路,固定大模型,每一个任务都只训练一个分类器,将结果视为大模型的表征能力。发现这么做的话大模型都能表现很好。
所以如果大模型固定的时候,就不能让之前的分类器权重也发生变化,这就是表现下降的原因。提出方法固定大模型,固定之前的分类器。 实验表明,即使在持续学习过程中不固定大模型,只固定之前的分类器,效果也会得到很大提升。
但是不足在于这个文章的实验只在文本分类任务,同一个数据集下面进行测试的。
common insight
- scale matters, big model have high anti-forgetting abilty
Finetuning- Instruction tuning
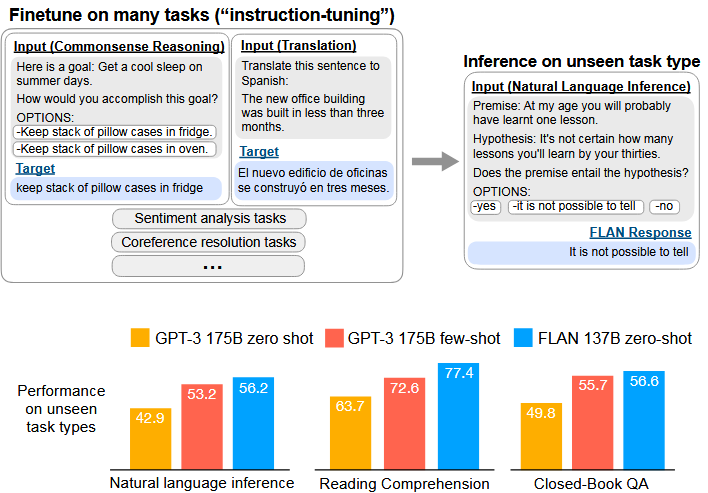
- FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
2021 International Conference on Learning Representations
作者介绍了 instruction tuning的概念, finetuning language models on a collection of datasets described via instructions, 然后再不同的任务和模型了进行了实验,表明 instruction tuning能够提升模型zero-shoot 的表现
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
2023 arXiv.org
作者在不同的任务上,测试了 在 continual learning 设置下进行 instruction tuning 的效果。实验表明,在参数从1b到7 b的LLM中通常会观察到灾难性遗忘。此外,随着模型规模的增加,遗忘的严重性加剧。

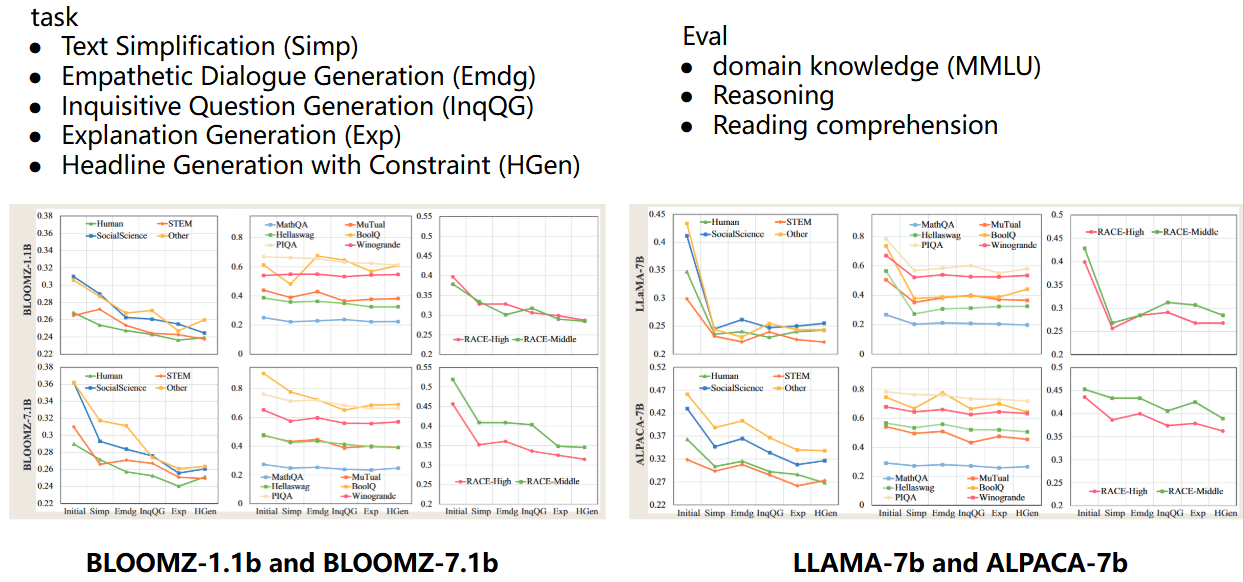
New Reading not category
Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models
2024 arXiv.org
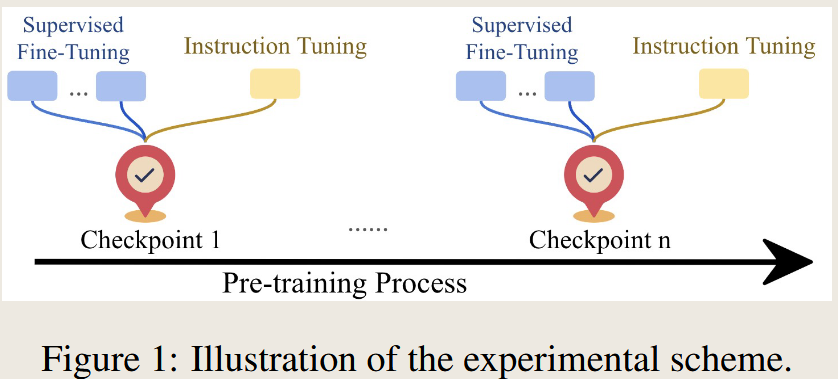
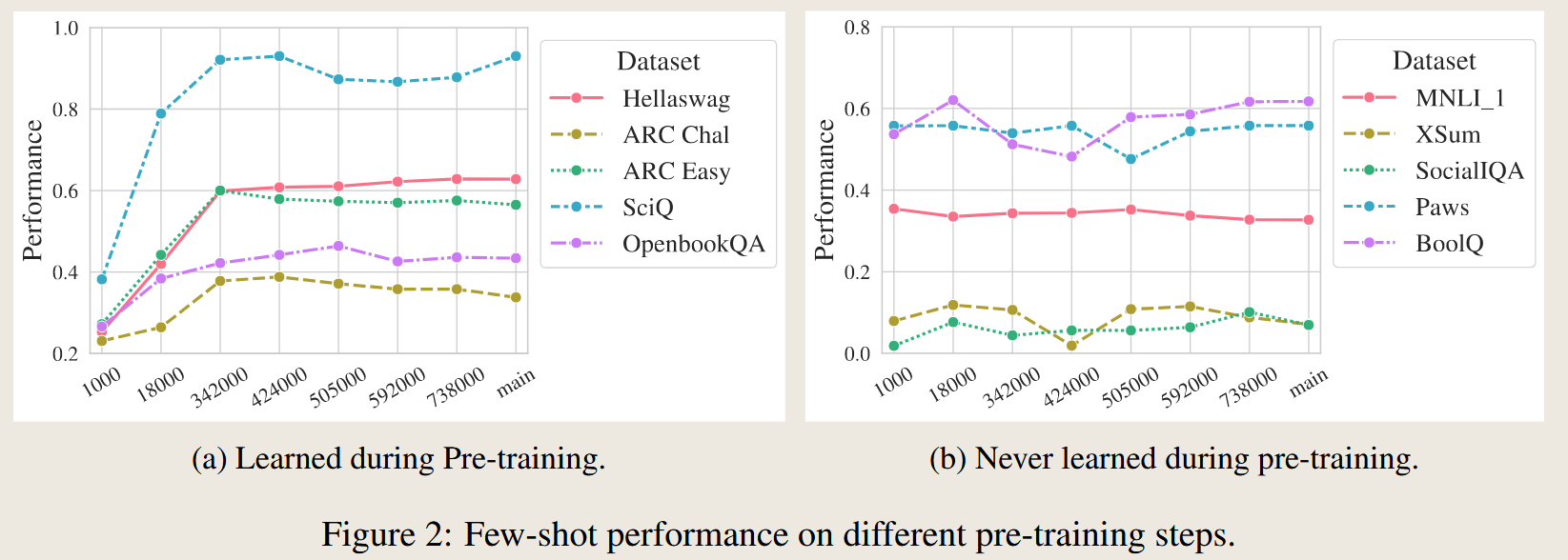
测试了在预训练的不同训练阶段的大模型的zero-shot以及 fine-tuning(full-parameter finetuning and instruction Tuning)之后的表现。
但是只使用一个模型,且参数量很小 OLMo-1B。
对于大模型没有训练过的数据,finetuning能带来更好的提升效果,但也会造成大模型已有知识的遗忘。
method:
experiment result:
Balancing Continuous Pre-Training and Instruction Fine-Tuning: Optimizing Instruction-Following in LLMs
Investigate two setting , the first is Pre-Training–> Finetuning –> Pre-Training om new data , the other is Pre-Training –> Pre-Training om new data –> Finetuning . Result show the latter is better.
Experiments using 8B LLmaMa 3.1 .
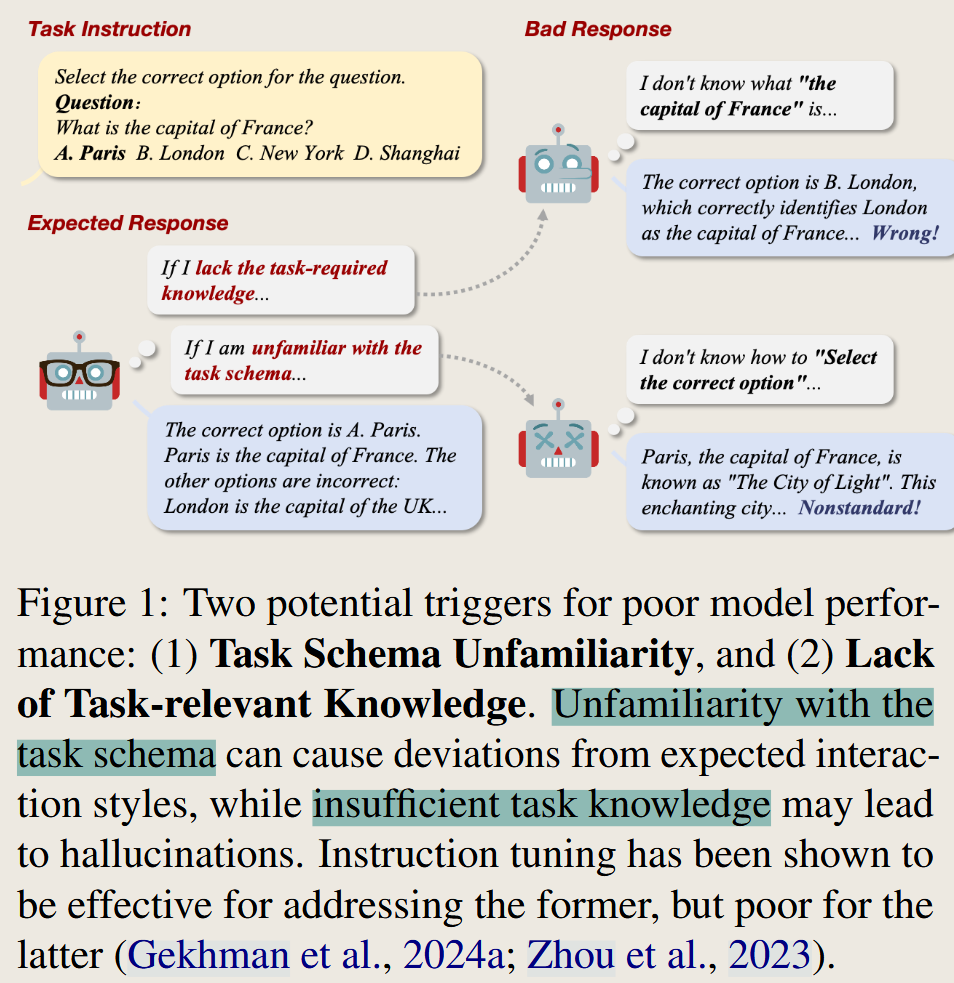
CEM: A Data-Efficient Method for Large Language Models to Continue Evolving From Mistakes
This paper propose a method that provide the mistake result to the model to train it. The method is a little bit of complex. But the paper mention a view that the failure has two reason: unfamiliarity with the task schema and insufficient task knowledge.

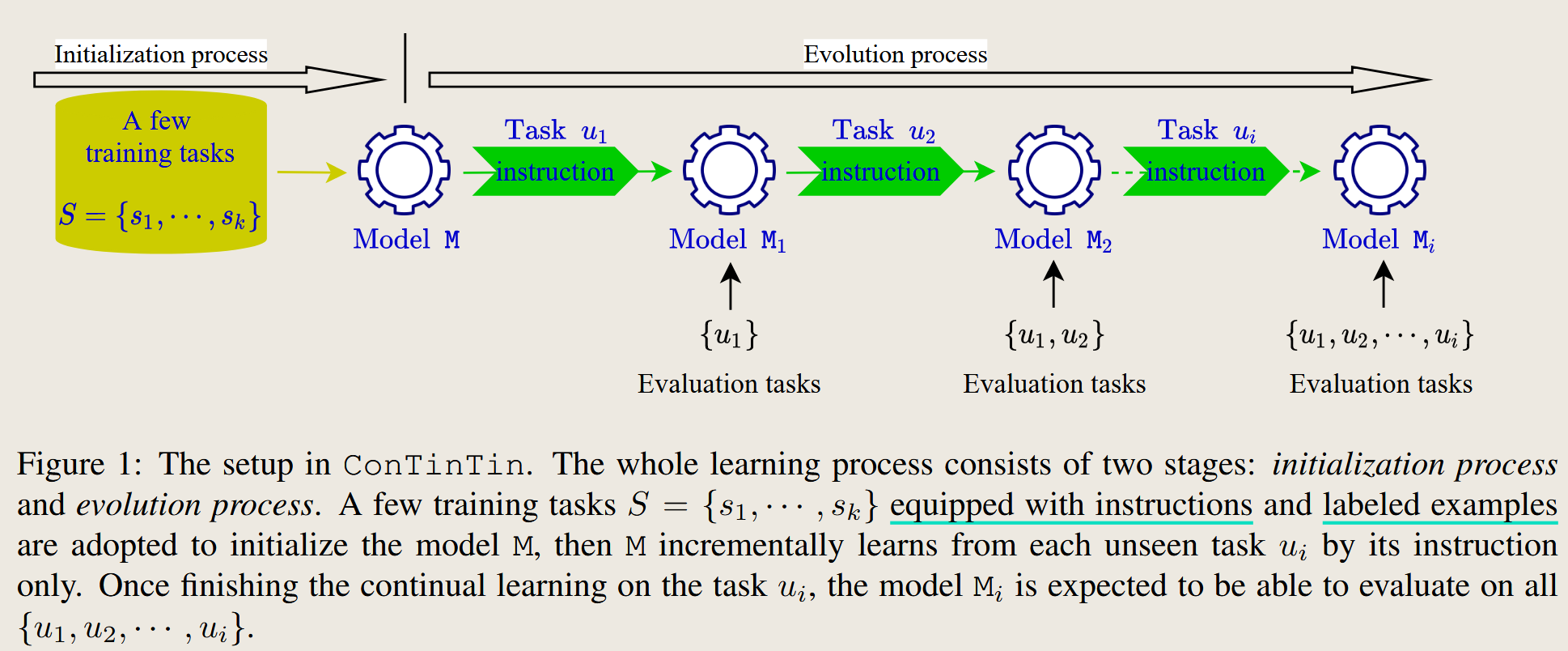
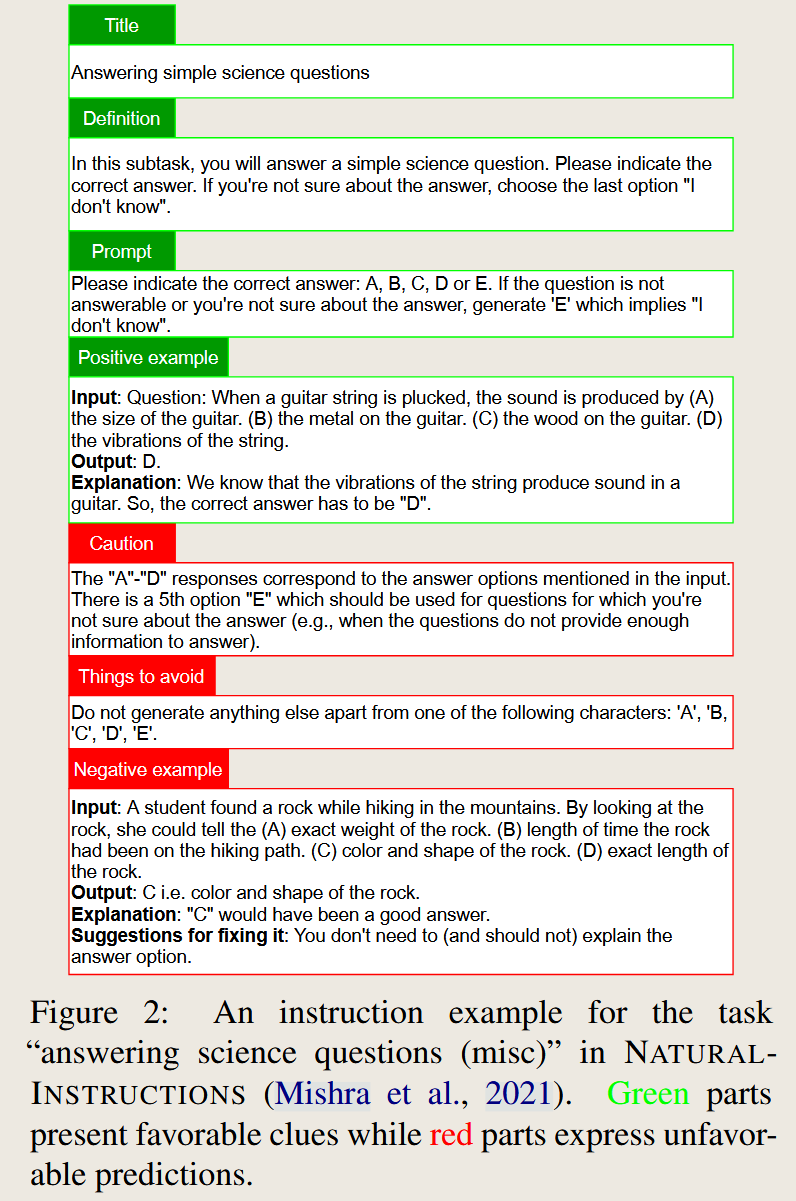
ConTinTin: Continual Learning from Task Instructions
2022 Annual Meeting of the Association for Computational Linguistics
The paper want the PLMs lean new task by text instruction and some examples. The author expect the method have better performance is Knowledge maintenance and transfer.

Continual Pre-Training of Large Language Models: How to (re)warm your model?
2023 arXiv.org
The author investigate the warm-up state in the pre-training. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance.
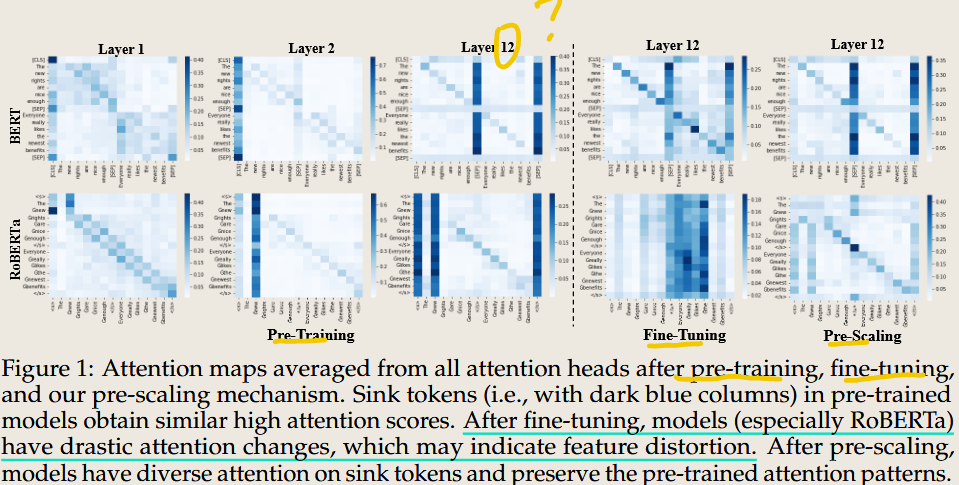
Does RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective
2024 arXiv.org
The result is RoBERTa is not perform better than BERT in the attention change, because it has attention sinks problem.
Efficient Continual Pre-training for Building Domain Specific Large Language Models
2023 Annual Meeting of the Association for Computational Linguistics
The author presents FinPythia-6.9B , which uses the continual pre-training strategy to train Pythia in a downsteam finance domain .
the model is Pythia
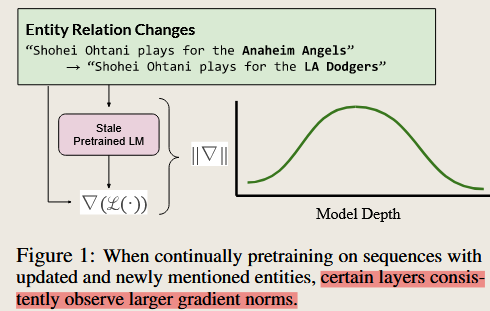
Gradient Localization Improves Lifelong Pretraining of Language Models
Gradient norms during pretraining reveal that certain layers of LLMs are more critical for learning new or temporally updated information. Demonstrates that targeting gradient-dominant layers improves both knowledge retention and acquisition.
the model is GPT 2
HellaSwag: Can a Machine Really Finish Your Sentence?
The author use Adversarial Filtering (AF) methods which iteratively select an adversarial set of machine-generated wrong answers to form a new dataset HellaSwag. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%).

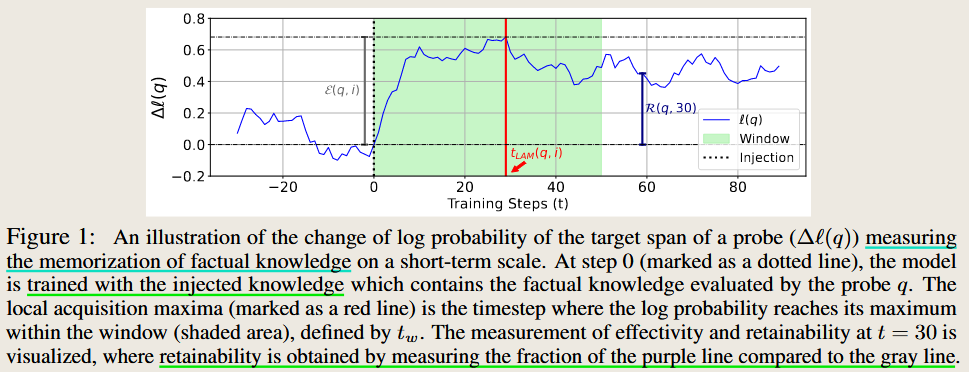
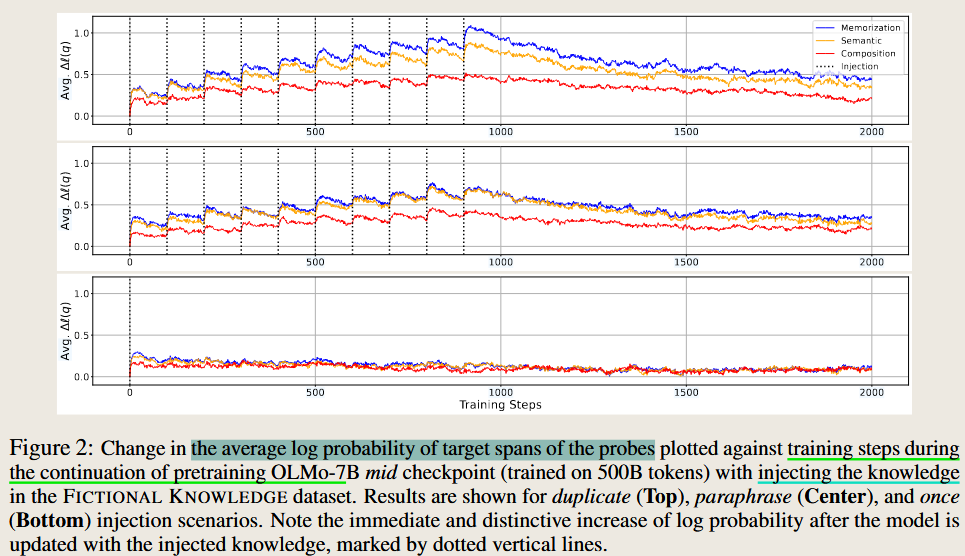
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
method: Injected synthetic factual knowledge into pretraining data to analyze memorization and generalization capabilities.
Conclusion: Factual knowledge is acquired incrementally with each minibatch update during pretraining. The effectiveness of factual knowledge acquisition does not consistently improve with longer pretraining or additional data.
Improving Multimodal Large Language Models Using Continual Learning
2024 arXiv.org
Train a LLM into MLLM. First align the embeddings from the visual encoder with the text embeddings of the LLM using a two-layer MLP. Then froze the visual encoder and train the LLM with MLP in continual setting using vison-language task.
The findings emphasize that continual learning methods, when applied to MLLMs, can successfully mitigate linguistic forgetting while preserving vision-language task performance.

This picture compares the performance of the base unimodal LLM (language-only), the original LLaVA 1.5 (naive fine-tuning), and the LLaVA 1.5 trained with the best CL method.
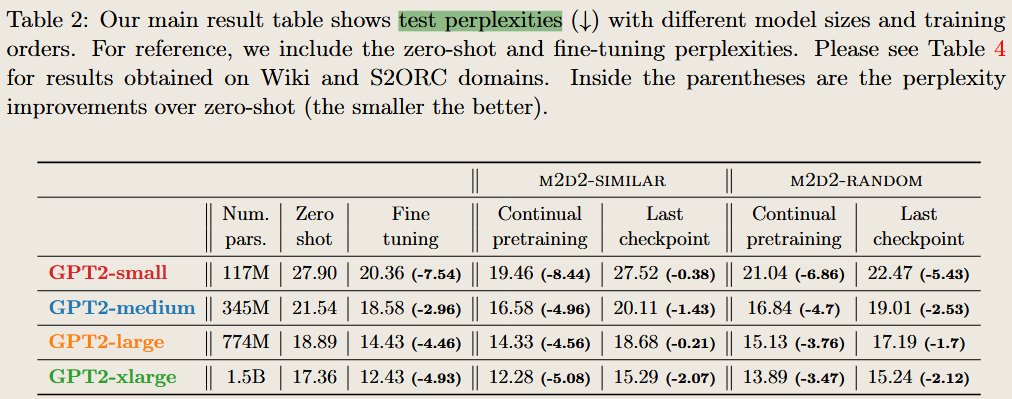
Investigating Continual Pretraining in Large Language Models: Insights and Implications
2024 arXiv.org
- CL improved downstream performance when domains shared semantic similarities.
- Randomized order optimized backward and forward transfer.
The two results reflect a trade-off between specialization and generalization:
- Semantic Similarity: Encourages domain-specific specialization by leveraging relatedness, which boosts performance in closely related downstream tasks.
- Randomized Order: Promotes generalization and retention across a wide variety of domains, even those that are unrelated, by balancing exposure to diverse knowledge.
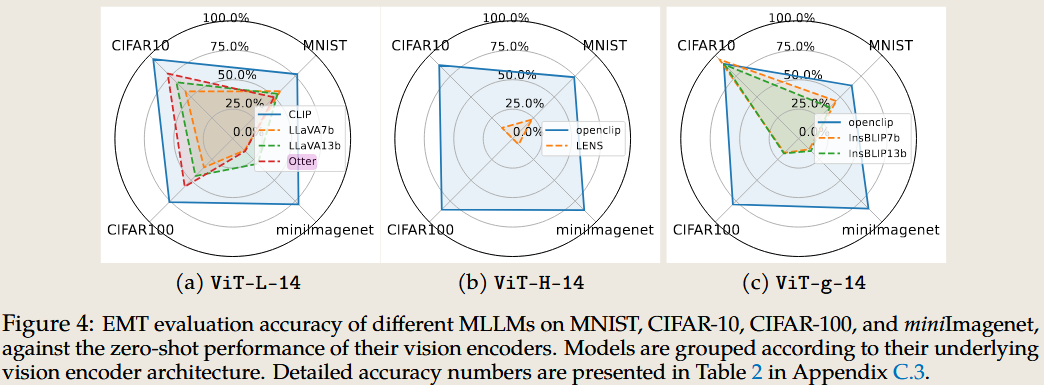
Investigating the Catastrophic Forgetting in Multimodal Large Language Models
2023 arXiv.org
Purpose:
Methods: Evaluating MulTimodality for evaluating the catastrophic forgetting in MLLMs, by treating each MLLM as an image classifier. The paper use another LLM to justify.
Conclusion: All tested MLLMs exhibited catastrophic forgetting compared to their vision encoder performance.
Limitation: But the author only study from the image classification task which is too easy to test the MLLM’s abilaity.

Large language models encode clinical knowledge
1 This paper propose the MultiMedQA, a benchmark combining six existing medical question answering dataset.
2 Introduction of Med-PaLM, achieving near-clinician-level performance on specific axes

LINEARLY MAPPING FROM IMAGE TO TEXT SPACE
Demonstrates that visual representations can be transferred to text space with a simple linear projection.

Mitigating Catastrophic Forgetting in Language Transfer via Model Merging
2024 Conference on Empirical Methods in Natural Language Processing
iteratively merging multiple models, fine-tuned on a subset of the available training data.

Overcoming the Stability Gap in Continual Learning
2023 arXiv.org
invest the learning and forgetting in the process of training in Continual learning setting.

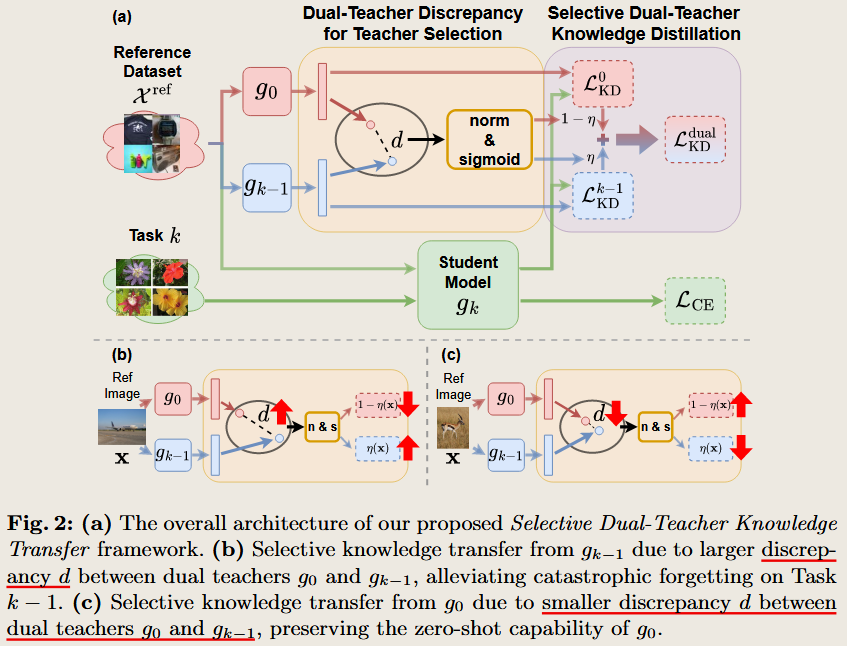
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
2024 European Conference on Computer Vision
study from both two teacher is better than one
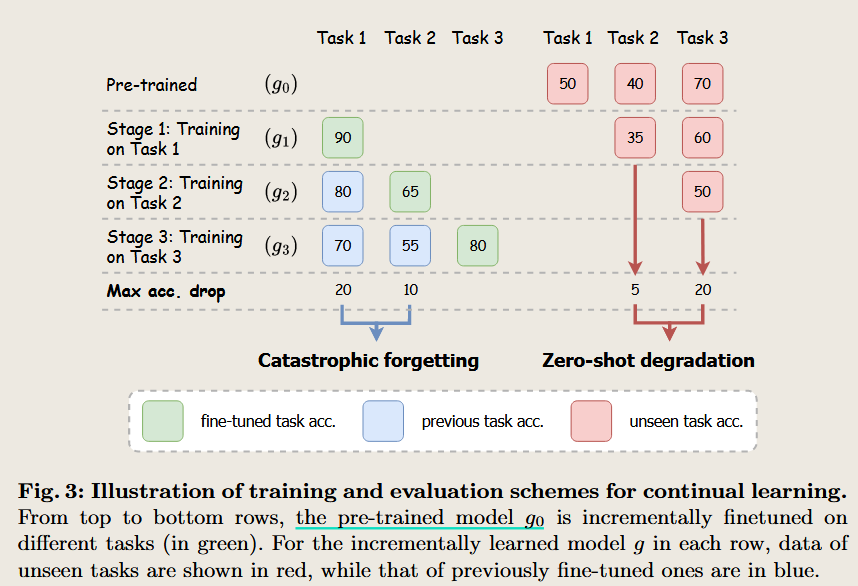

Towards Effective and Efficient Continual Pre-training of Large Language Models
2024 arXiv.org
high quantity data can improve data performance.
Subspace
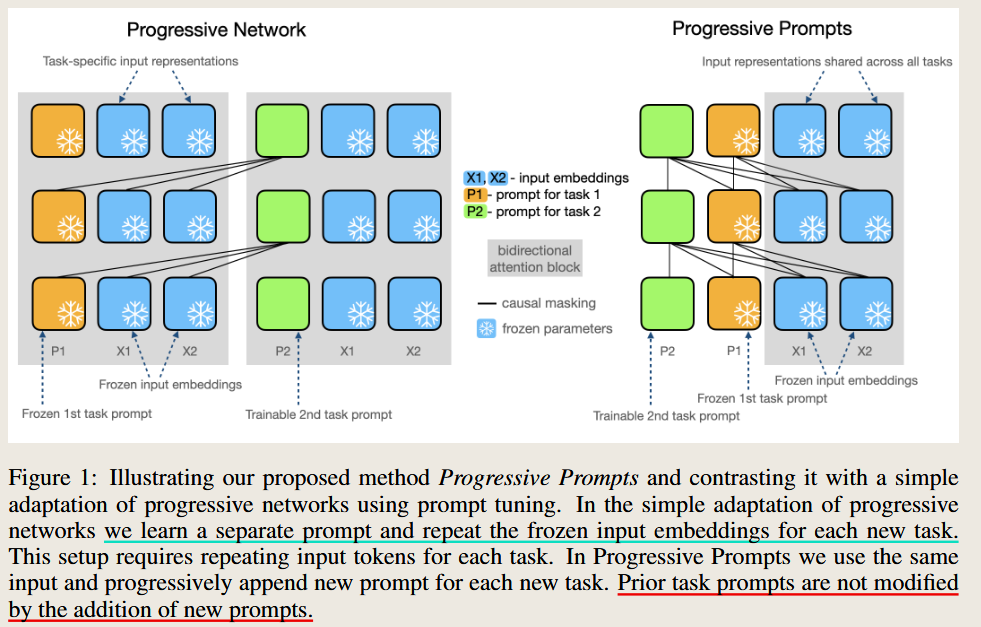
PROGRESSIVE PROMPTS: CONTINUAL LEARNING FOR LANGUAGE MODELS
PROGRESSIVE PROMPTS: CONTINUAL LEARNING FOR LANGUAGE MODELS
2023 International Conference on Learning Representations
use a fixed prompt for former task. Prompts trains a separate prompt for each encountered task without modifying its parameters when new tasks are learned, old tasks do not suffer from forgetting.
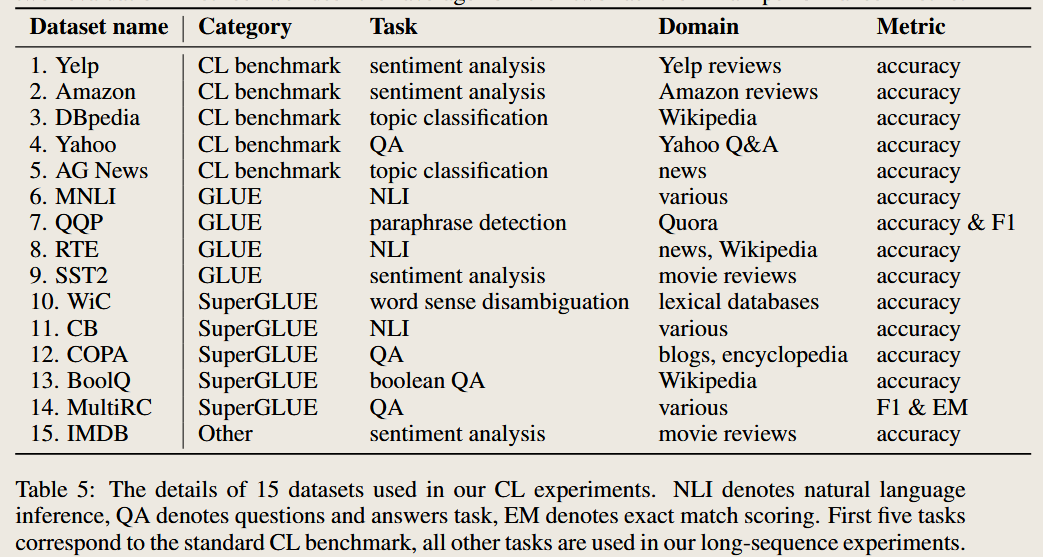
Using 15 task and 10 different sequence as benchmark

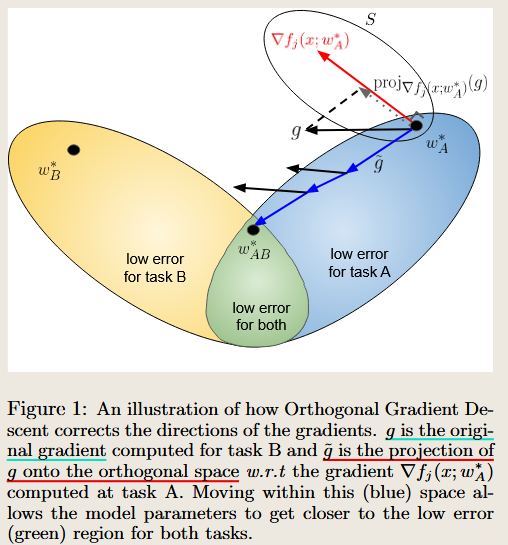
Orthogonal Gradient Descent for Continual Learning
Orthogonal Gradient Descent for Continual Learning
propose the OGD method, which means projecting the gradients from new tasks onto a subspace in which the neural network output on previous task does not change and the projected gradient is still in a useful direction for learning the new task.
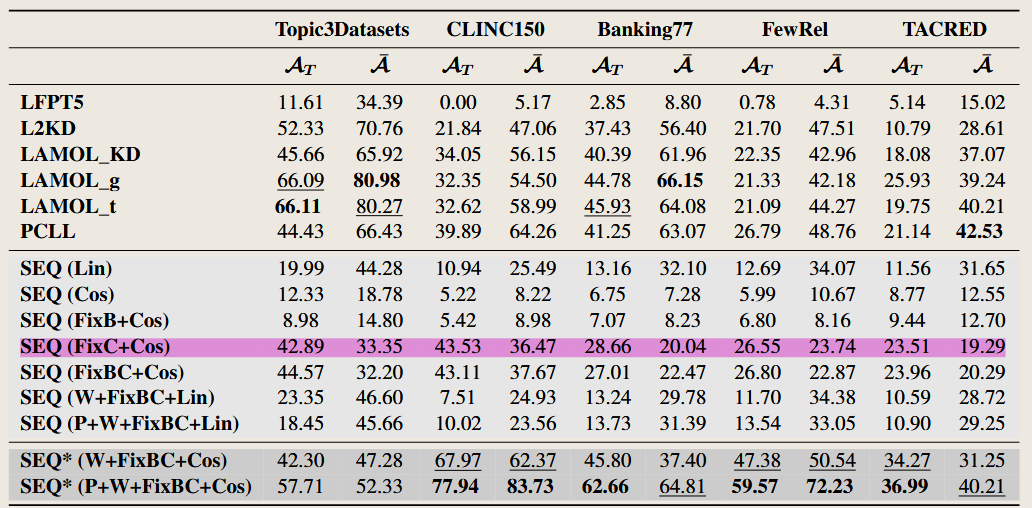
LFPT5: A UNIFIED FRAMEWORK FOR LIFELONG FEW-SHOT LANGUAGE LEARNING BASED ON PROMPT TUNING OF T5
LFPT5: A UNIFIED FRAMEWORK FOR LIFELONG FEW-SHOT LANGUAGE LEARNING BASED ON PROMPT TUNING OF T5
2021 International Conference on Learning Representations
Orthogonal Subspace Learning for Language Model Continual Learning
2023 Conference on Empirical Methods in Natural Language Processing
Is Parameter Collision Hindering Continual Learning in LLMs?
2024 arXiv.org
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/wiki/Paper%20Reading%20List-LLM%20and%20forgetting/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)