优化
问题1 旅行商问题 TSP
经典的NP完全问题
有若干个城市,任何两个城市之间的距离都是确定的,现要求一旅行商从某城市出发必须经过每一个城市且只在一个城市逗留一次,最后回到出发的城市,问如何事先确定一条最短的线路已保证其旅行的费用最少?
问题2 车辆路径规划问题 VRP
车辆路径规划问题(VRP)是运筹学中经典,它是指对一系列发货点和收货点,组织调用一定的车辆,安排适当的行车路线,使车辆有序地通过它们,在满足指定的约束条件下(例如:车辆容量限制,行驶时间限制等),力争实现一定的目标。
问题3 带时间窗的车辆路径规划问题(Vehicle Routing Problem with Time Window,VRPTW)
带时间窗的车辆路径规划问题(Vehicle Routing Problem with Time Window,VRPTW)是在VRP基础上添加配送时间约束条件产生的一个新问题。在这类问题中,给定车辆到达目的地的最早时间和最晚时间,要求车辆必须在规定的时间窗内到达,这是一个硬性条件,但是在搜索过程中却可以适当无视此条件以扩大搜索范围。此时,决策如何规划调度车辆使得配送的总费用最小化。
方法:
解决带时间窗车辆路径问题(vehicle routing problems with time windows,VRPTW)的常用求解方法:
问题 01 背包问题
为什么叫0-1背包问题呢?显然,面对每个物品,我们只有选择拿取或者不拿两种选择,不能选择装入某物品的一部分,也不能装入同一物品多次。拿就是1,不拿就是0。因此,就叫0-1背包问题。So simple, so naive.
指派问题
图着色问题(graph coloring problem)
网络路由问题(network routing problem)
问题4 包材推荐
包材推荐 : 而包材推荐,则是运用智能化系统为需要运输的货品推荐类型大小合适的包装材料,比如选用纸箱包装还是泡沫盒包装?选择大纸箱包装还是小纸箱包装?
智能化包材推荐流程介绍
整个智能化包材推荐流程可以分为三个阶段。
阶段一:确定需要包装的货品的基本信息(体积,重量,是否需要冷冻等)、可选包装的基本信息(种类,体积等)
阶段二:在一定的匹配约束规则下为货品匹配一种合适的包装类型
阶段三:在包装类型确定的情况下,运用装箱算法为货品推荐最合适体积大小的包装,使得包裹装载率最高,从而减少包装浪费。
算法
1.精确解算法(Exact methods)
精确解算法解VRPTW问题主要有三个策略,拉格朗日松弛、列生成和动态规划,但是可以求解的算例规模非常小。
2.途程构建启发式算法(Route-building heuristics)
在问题中以某节点选择原则或是路线安排原则,将需求点一一纳入途程路线的解法。
**3.途程改善启发式算法(Route-improving heuristics)
先决定一个可行途程,也就是一个起始解,之后对这个起始解一直做改善,直到不能改善为止。
**4.通用启发式算法(Metaheuristics)
传统区域搜寻方法的最佳解常因起始解的特性或搜寻方法的限制,而只能获得局部最佳解,为了改善此一缺点,近年来在此领域有重大发展,是新一代的启发式解法,包含禁忌搜索算法(Tabu Search)、模拟退火法(Simulated Annealing)、遗传算法(Genetic Algorithm)和门坎接受法(Threshold Accepting)等,可以有效解决陷入局部最优的困扰。
动态规划算法
分治法
分治,即分而治之。分治,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)……直接说就是将一个难以直接解决的大问题,分割成一些规模比较小的相同的小问题,以便各个击破,分而治之。
启发式算法
算法 局部搜索
官方一点:局部搜索是解决优化问题的一种启发式算法。对于某些计算起来非常复杂的优化问题,比如各种NP-难问题,要找到最优解需要的时间随问题规模呈指数增长,因此诞生了各种启发式算法来退而求其次寻找次优解,是一种近似算法,以时间换精度的思想。局部搜索就是其中的一种方法。
通俗一点:局部搜索算法是对一类算法的统称,符合其框架的算法很多,比如之前公众号推文中介绍的爬山法、模拟退火算法和禁忌搜索算法都属于局部搜索算法。尽管各个算法在优化过程中的细节存在差异,但在优化流程上呈现出很大的共性。
它的基本原理是在邻近解中迭代,使目标函数逐步优化,直至不能再优化为止。
算法1 :模拟退火算法
模拟退火算法是一种通用概率演算法,用来在一个大的搜寻空间内找寻命题的最优解。它是基于Monte-Carlo迭代求解策略的一种随机寻优算法。模拟退火算法是解决TSP问题的有效方法之一。
爬山法是完完全全的贪心法(greedy algorithm),这种贪心是很鼠目寸光的,只把眼光放在局部最优解上,因此只能搜索到局部的最优值。模拟退火其实也是一种贪心算法,只不过与爬山法不同的是,模拟退火算法在搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。
由初始解 i 和控制参数初值 t 开始,对当前解重复“产生新解→计算目标函数差→接受或丢弃”的迭代,并逐步衰减 t 值,算法终止时的当前解即为所得近似最优解。
因此我们归结起来就是以下几点:
\1) 若f( Y(i+1) ) <= f( Y(i) ) (即移动后得到更优解),则总是接受该移动。
\2) 若f( Y(i+1) ) > f( Y(i) ) (即移动后的解比当前解要差),则以一定的概率接受移动,而且这个概率随着时间推移逐渐降低(逐渐降低才能趋向稳定)。
相当于上图中,从B移向BC之间的小波峰D时,每次右移(即接受一个更糟糕值)的概率在逐渐降低。如果这个坡特别长,那么很有可能最终我们并不会翻过这个坡。如果它不太长,这很有可能会翻过它,这取决于衰减 t 值的设定。
算法2 禁忌搜索算法
所谓禁忌搜索是Local Search(LS)的扩展,是一种全局逐步寻优的全局性邻域搜索算法。
传统的 LS 通过迭代,不断搜寻邻域中更优的解来替换当前解,实现优化,该方式十分容易陷入局部最优。
而 TS 则是模仿人类的记忆功能,在搜索过程中标记已经找到的局部最优解及求解过程,并于之后的搜索中避开它们。
算法流程
禁忌搜索的主要构成要素是
(1)评价函数(Evaluation Function)
(2)邻域移动(Move Operator)
(3)禁忌表(Tabu Table)
(4)邻居选择策略(Neighbor Selection Strategy)
(5)破禁准则(Aspiration Criterion)
(6)停止规则(Stop Criterion)
算法4 变邻域搜索算
变邻域搜索算法(VNS)就是一种改进型的局部搜索算法。它利用不同的动作构成的邻域结构进行交替搜索,在集中性和疏散性之间达到很好的平衡。其思想可以概括为“变则通”。
VNS算法本质上还是一种跳出局部最优解的算法。和禁忌搜索与模拟退火算法不同,其算法并不遵循一定的”轨迹”,而是通过shaking动作来跳出当前局部最优解,在不同的邻域中找到其他局部最优解,当且仅当该解优于当前解时进行移动。假如邻域结构可以覆盖整个可行解集,则算法可以找到全局最优解。
算法流程
VND其实就是一个算法框架,它的过程描述如下:
\1) 给定初始解S; 定义m个邻域,记为N_k(k = 1, 2, 3……m);i = 1。
\2) 使用邻域结构N_i(即 N_i(S))进行搜索,如果在N_i(S)里找到一个比S更优的解S′,则令S=S′, i=1 。
\3) 如果搜遍邻域结构N_i仍找不到比S更优的解,则令i++。
\4) 如果i≤m ,转步骤2。
\5) 输出最优解S。
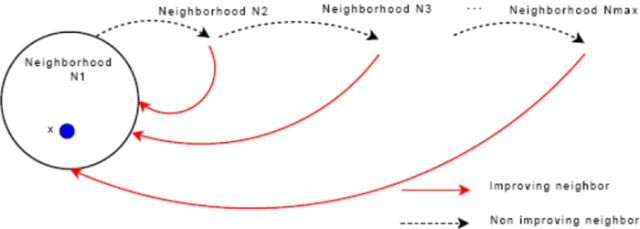
算法5 贪心随机自适应搜索
Greedy Randomized Adaptive Search,贪婪随机自适应搜索(GRAS),是组合优化问题中的多起点元启发式算法。
在算法的每次迭代中,主要由两个阶段组成:构造(construction)和局部搜索( local search)。
构造(construction)阶段主要用于生成一个可行解,而后该初始可行解会被放进局部搜索进行邻域搜索,直到找到一个局部最优解为止。
算法5 Large Neighborhood Serach,LNS
大多数邻域搜索算法都明确定义它们的邻域, 在LNS中,邻域是由destroy和repair方法隐式定义的。destroy方法会破坏当前解的一部分,而后repair方法会对被破坏的解进行重建。destroy方法通常包含随机性的元素,以便在每次调用destroy方法时破坏解的不同部分。 那么,解x的邻域N(x)就可以定义为:首先通过利用destroy方法破坏解x,然后利用repair方法重建解x,从而得到的一系列解的集合。
当一个邻域搜索算法搜索的邻域规模随着算例规模的增大而呈指数增长,或者邻域太大而不能在实际中明确搜索时,我们把这类邻域搜索算法归类为Very Large-Scale Neighborhood Search(VLSN)。
邻域搜索算法(或称为局部搜索算法)是一类非常常见的改进算法,其在每次迭代时通过搜索当前解的“邻域”找到更优的解。 邻域搜索算法设计中的关键是邻域结构的选择,即邻域定义的方式。 根据以往的经验,邻域越大,局部最优解就越好,这样获得的全局最优解就越好。 但是,与此同时,邻域越大,每次迭代搜索邻域所需的时间也越长。**出于这个原因,除非能够以非常有效的方式搜索较大的邻域,否则启发式搜索也得不到很好的效果。
正如前面所说的一样,对于一个邻域搜索算法,当其邻域大小随着输入数据的规模大小呈指数增长的时候,那么我们就可以称该邻域搜索算法为超大规模邻域搜索算法(Very Large Scale Neighborhood Search Algorithm,VLSNA )。
一些超大规模的邻域搜索方法已经运用于运筹学之中了,并且取得了不错的效果。 例如,如果将求解线性规划的单纯形算法看成邻域搜索算法的话,那么列生成算法就是一种超大规模的邻域搜索方法。 此外,用于解决许多网络流问题的方法也可以归类为超大规模的邻域搜索方法。 用于求解最小费用流问题的negative cost cycle canceling algorithm和用于求解分配问题的augmenting path algorithm就是两个例子。
算法流程
下面是LNS的伪代码:[1]

LNS算法中包含三个变量。变量x b记录目前为止获得的最优解,x则表示当前解,而x^t是临时解(便于回退到之前解的状态)。
函数d(·)是destroy方法,而r(·)是repair方法。详细点就是,d(x)表示破坏解x的部分,而r(x)则表示对破坏的解进行重新修复。
在第2行中,初始化了全局最优解。在第4行中,算法首先用destroy方法,然后再用repair方法来获得临时解x^t。在第5行中,评估临时解x^t的好坏,并以此确定该临时解x^t是否应该成为当前新的解x(第6行)。
评估的方式因具体程序而异,可以有很多种。最简单的评估方式就只接受那些变得更优的解。注:评估准则可以参考模拟退火的算法原理,设置一个接受的可能性,效果也许会更佳。
第8行检查新解x是否优于全局最优解x^b。此处 c(x)表示解x的目标函数值。如果新获得的解x更优,那么第9行将会更新全局最优解x^b。在第11行中,检查终止条件。在第12行中,返回找到的全局最优解x^b。
从伪代码可以注意到,LNS算法不会搜索解的整个邻域,而只是对该邻域进行采样搜索。也就是说,这么大的邻域是不可能一一遍历搜索的,只能采样,搜索其中的一些解而已。
算法6 自适应大领域搜索 Adaptive Large Neighborhood Search(ALNS)
ALNS在LSN的基础上,允许在同一个搜索中使用多个destroy和repair方法来获得当前解的邻域。
*ALNS*会为每个destroy和repair方法分配一个权重,通过该权重从而控制每个destroy和repair方法在搜索期间使用的频率。 在搜索的过程中,ALNS会对各个destroy和repair方法的权重进行动态调整,以便获得更好的邻域和解。简单点解释,ALNS和LNS不同的是,*ALNS*通过使用多种destroy和repair方法,然后再根据这些destroy和repair方法生成的解的质量,选择那些表现好的destroy和repair方法,再次生成邻域进行搜索。
ALNS对LNS进行了扩展,它允许在一次搜索中搜索多个邻域(使用多组不同的destroy和repair方法)。至于搜索哪个邻域呢,*ALNS*会根据邻域解的质量好坏,动态进行选择调整。好啦,来看伪代码:[1]
算法流程
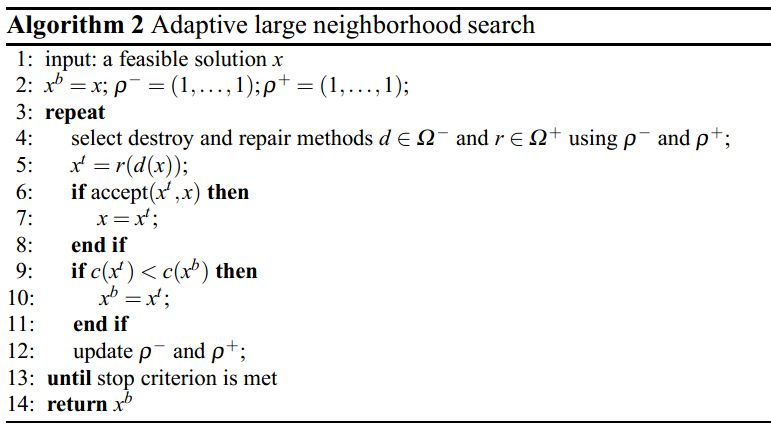
上面就是ALNS伪代码。相对于LNS来说,新增了第4行和第12行,修改了第2行。
Ω^−和Ω^+分别表示destroy和repair方法的集合。第2行中的ρ^−和ρ^+分别表示各个destroy和repair方法的权重集合。一开始时,所有的方法都设置相同的权重。
第4行根据ρ^−和ρ^+选择destroy和repair方法。至于选择哪个方法的可能性大小,是由下面公式算出的:[1]
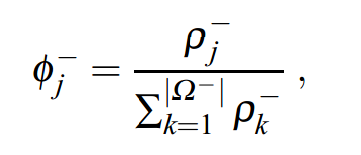
总的来说,权重越大,被选中的可能性越大。
群体仿生算法
算法1 遗传算法
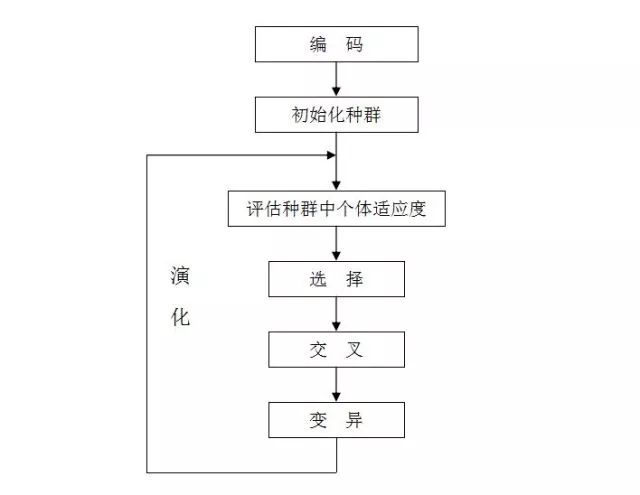
遗传算法(Genetic Algorithm,简称GA)起源于对生物系统所进行的计算机模拟研究,是一种随机全局搜索优化方法,它模拟了自然选择和遗传中发生的复制、交叉(crossover)和变异(mutation)等现象,从任一初始种群(Population)出发,通过随机选择、交叉和变异操作,产生一群更适合环境的个体,使群体进化到搜索空间中越来越好的区域,这样一代一代不断繁衍进化,最后收敛到一群最适应环境的个体(Individual),从而求得问题的优质解
算法流程图
算法2 蚁群算法
由上述蚂蚁找食物模式演变来的算法,即是蚁群算法。这种算法具有分布计算、信息正反馈和启发式搜索的特征,本质上是进化算法中的一种启发式全局优化算法。

算法3 粒子群算法
PSO模拟的是鸟群的捕食行为。设想这样一个场景:一群鸟在随机搜索食物,在这个区域里只有一块食物,所有的鸟都不知道食物在那里,但是它们知道当前位置的好坏(距离食物越近的位置就越好)。那么找到食物的最优策略是什么呢?最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
鸟群在整个搜寻的过程中,通过相互传递各自的信息,让其他的鸟知道自己的位置,通过这样的协作,来判断自己找到的是不是最优解,同时也将最优解的信息传递给整个鸟群,最终,整个鸟群都能聚集在食物源周围,即找到了最优解。
在PSO中,每只鸟的位置都是优化问题解空间中的一个解。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitness value),每个粒子还有一个速度决定它们飞翔的方向和速率。然后,粒子们就追随当前的最优粒子在解空间中搜索。
在初始化阶段,PSO生成一群随机粒子(即随机解),然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个”极值”来更新自己。第一个极值就是粒子本身所找到的历史最优解,这个解叫做个体极值pBest。另一个极值是整个种群找到的历史最优解,这个极值是全局极值gBest。
粒子群算法通过设计一种无质量的粒子来模拟鸟群中的鸟,粒子仅具有两个属性:速度和位置,速度代表移动的快慢和方向。
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次的迭代中,粒子通过跟踪两个“极值”(pbest,gbest)来更新自己。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。

对于公式(1):
公式(1)的第①部分称为【记忆项】,表示上次速度大小和方向的影响;
公式(1)的第②部分称为【自身认知项】,是从当前点指向粒子自身最好点的一个矢量,表示粒子的动作来源于自己经验的部分;
公式(1)的第③部分称为【群体认知项】,是一个从当前点指向种群最好点的矢量,反映了粒子间的协同合作和知识共享。粒子就是通过自己的经验和同伴中最好的经验来决定下一步的运动。
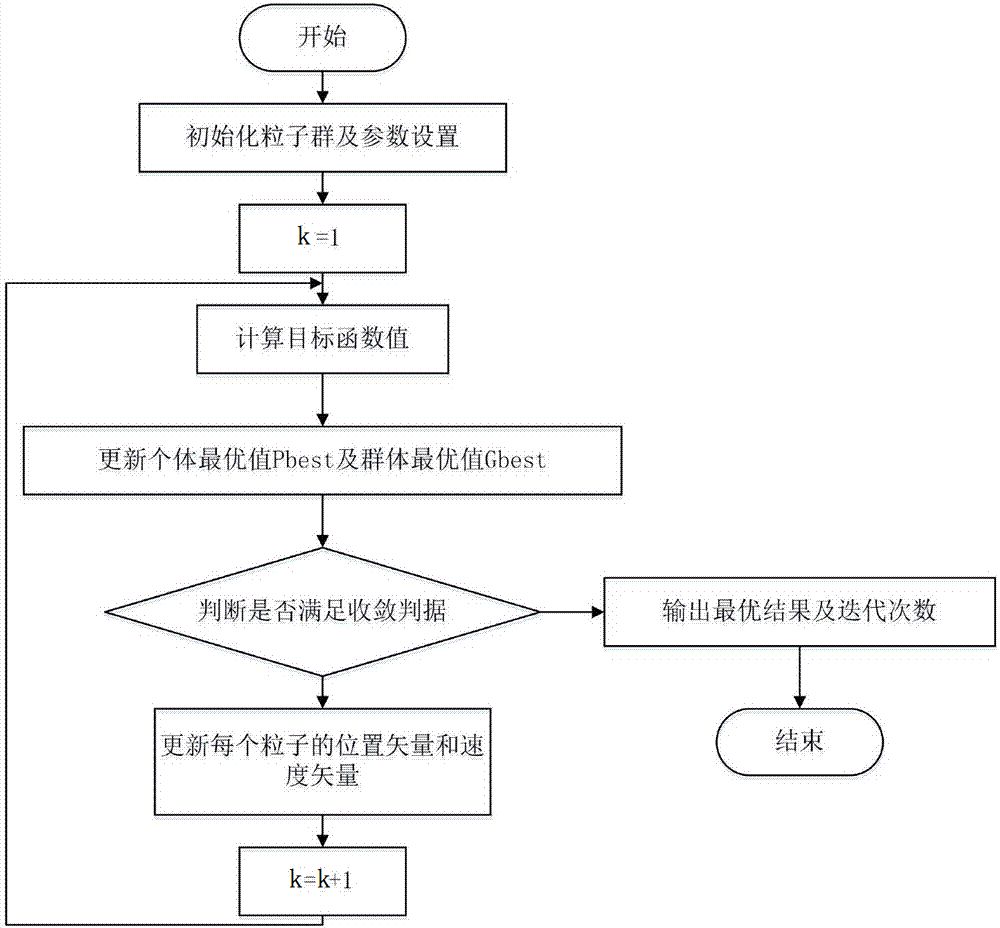
标准PSO算法的流程
1)初始化一群微粒(群体规模为N),包括随机位置和速度;
2)评价每个微粒的适应度;
3)对每个微粒,将其适应值与其经过的最好位置pbest作比较,如果较好,则将其作为当前的最好位置pbest;
4)对每个微粒,将其适应值与其经过的最好位置gbest作比较,如果较好,则将其作为当前的最好位置gbest;
5)根据公式(2)、(3)调整微粒速度和位置;
6)未达到结束条件则转第2)步。
迭代终止条件根据具体问题一般选为最大迭代次数Gk或(和)微粒群迄今为止搜索到的最优位置满足预定最小适应阈值。
算法流程图
算法4 人工鱼群算法
在一片水域中,鱼往往能自行或尾随其他鱼找到营养物质多的地方,因而鱼生存数目最多的地方一般就是本水域中营养物质最多的地方,人工鱼群算法就是根据这一特点,通过构造人工鱼来模仿鱼群的觅食、聚群及追尾行为,从而实现寻优。
人工鱼拥有以下几种典型行为:
(1)觅食行为:一般情况下鱼在水中随机地自由游动,当发现食物时,则会向食物逐渐增多的方向快速游去。
(2)聚群行为: 鱼在游动过程中为了保证自身的生存和躲避危害会自然地聚集成群,鱼聚群时所遵守的规则有三条:
分隔规则:尽量避免与临近伙伴过于拥挤;
对准规则:尽量与临近伙伴的平均方向一致;
内聚规则:尽量朝临近伙伴的中心移动。
(3)追尾行为:当鱼群中的一条或几条鱼发现食物时,其临近的伙伴会尾随其快速到达食物点。
(4)随机行为:单独的鱼在水中通常都是随机游动的,这是为了更大范围地寻找食物点或身边的伙伴。
算法流程
算法具体过程
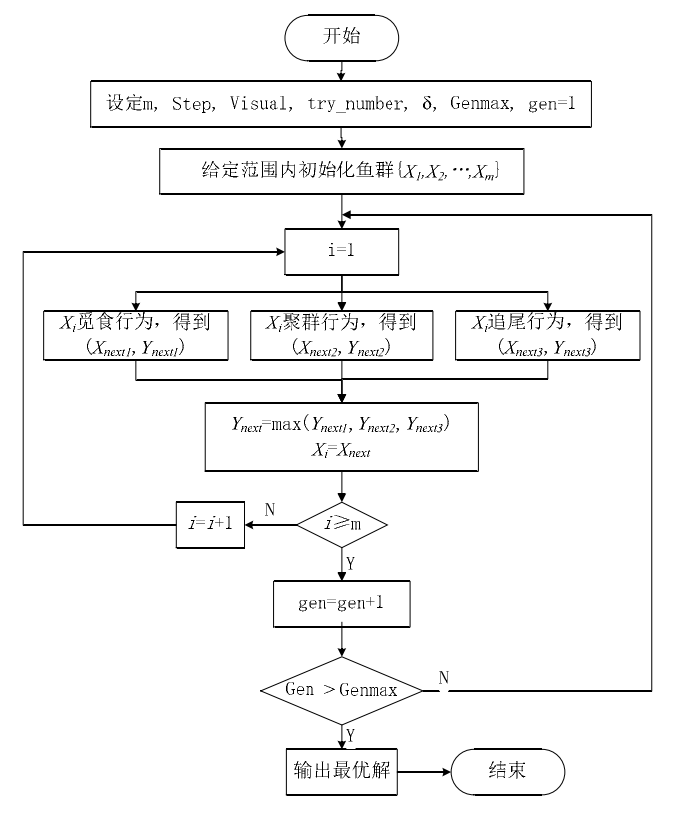
人工鱼群算法实现的步骤:
\1. 初始化设置,包括种群规模N、每条人工鱼的初始位置、人工鱼的视野Visual、步长step、拥挤度因子δ、重复次数Trynumber;
\2. 计算初始鱼群各个体的适应值,取最优人工鱼状态及其值赋予给公告牌;
\3. 对每个个体进行评价,对其要执行的行为进行选择,包括觅食Pray、聚群Swarm、追尾Follow和评价行为bulletin;
\4. 执行人工鱼的行为,更新自己,生成新鱼群;
\5. 评价所有个体。若某个体优于公告牌,则将公告牌更新为该个体;
\6. 当公告牌上最优解达到满意误差界内或者达到迭代次数上限时算法结束,否则转步骤3。
求解器 CPlex
参考链接
文档信息
- 本文作者:zuti666
- 本文链接:https://zuti666.github.io/2022/09/09/Introduction/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)